Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction论文阅读笔记
我的博客链接
0. 前言
1. 作者试图解决什么问题?
作者想在KGE中对语义层级(semantic hierarchies)进行建模。
2. 这篇论文的关键元素是什么?
semantic hierarchy, polar coordinate system
3. 论文中有什内容可以“为你所用”?
- 两种可视化的展示方式,清晰明了的展示了作者方法的有效性;
- table1中展示的模型分数函数和参数;
- 在related work中分析自己模型和RotatE模型不同的论述;
4.有哪些参考文献你想继续研究?
- Sun, Z., Deng, Z.-H., Nie, J.-Y., & Tang, J. (2019). Rotate: Knowledge graph embedding by relational rotation in complex space. Paper presented at the 7th International Conference on Learning Representations, ICLR 2019, May 6, 2019 - May 9, 2019, New Orleans, LA, United states.
- Li, Y.; Zheng, R.; Tian, T.; Hu, Z.; Iyer, R.; and Sycara, K. 2016. Joint embedding of hierarchical categories and entities for concept categorization and dataless classification. In COLING.
- Zhang, Z.; Zhuang, F.; Qu, M.; Lin, F.; and He, Q. 2018. Knowledge graph embedding with hierarchical relation structure. In EMNLP.
- Xie, R.; Liu, Z.; and Sun, M. 2016. Representation learning of knowledge graphs with hierarchical types. In IJCAI.
5. 还存在什么问题
- 维度太高,都到了1000维。
- 论文中缺少术语字母表;Notation部分以表格形式可能更为清晰;
0.2 待学习知识
- 混合偏移量
- 采样温度
- self-adversarial training
- symmetry/antisymmetry, inversion, composition具体含义
0.3 总结
1. Introduction
论文链接:https://arxiv.org/pdf/1911.09419.pdf
github:https://github.com/MIRALab-USTC/KGE-HAKE
作者举了一个语义层级的例子,来证明语义层级在知识图谱中是普遍存在的。
语义层次结构是知识图中普遍存在的属性。 例如,WordNet包含三元组[乔木/决明子/棕榈,上调,树],其中“树”在层次结构中比“乔木/决明子/棕榈”更高。 Freebase包含三元组[英格兰,/ location / location /包含,Pontefract / Lancaster],其中“ Pontefract / Lancaster”在层次结构中的级别低于“英格兰”。 尽管存在一些将层次结构考虑在内的工作,但他们通常需要额外的数据或过程来获取层次结构信息。 因此,寻找一种能够自动有效地对语义层次进行建模的方法仍然具有挑战性。
2 related work
2.1 模型分类
- Translational distance models
- Bilinear models
- Neural network based models
我们提出的模型HAKE属于平移距离模型。 更具体地说,HAKE与RotatE(Sun et al.2019)有相似之处,其中作者声称他们同时使用了模数和相位信息。 但是,RotatE和HAKE之间存在两个主要区别。 详细的区别如下。
(a)目的不同。 RotatE旨在对包括对称/反对称,反演和合成的关系模式进行建模。 HAKE旨在建模语义层次结构,同时还可以建模上述所有关系模式。
(b)使用模数信息的方式不同。 RotatE将关系建模为复杂空间中的旋转,无论关系是什么,都鼓励两个链接的实体具有相同的模数。 RotatE中的不同模量来自训练的不准确性。 取而代之的是,HAKE显式地对模量信息进行建模,其明显优于RotatE。
2.2 The Ways to Model Hierarchy Structures
另一个相关问题是如何在知识图谱中对层级结构进行建模:
- Li et al. (2016):将实体和类别共同嵌入语义空间,并设计用于概念分类和无数据分层分类任务的模型;
- Zhang et al. (2018):使用聚类算法对层次关系结构建模;
- Xie, Liu, and Sun (2016):提出了TKRL,将类型信息嵌入知识图谱嵌入。(但TKRL额外引入了实体的分层类型信息)
作者的工作:
- 考虑链接预测任务,这是知识图嵌入中比较常见的任务;
- 无需使用聚类算法就可以自动学习知识图中的语义层次;
- 除了知识图中的三元组外,不需要任何其他信息。
3. HAKE模型
3.1 Two Categories of Entities 两类实体
为了给知识图谱中语义层级建模,知识图谱嵌入模型必须具有辨别以下两类实体的能力:
- (a)层次结构不同级别上的实体。例如,“哺乳动物”和“狗”,“跑”和“移动”。
- (b)层级结构相同级别上的实体。例如,“玫瑰”和“牡丹”,“货车”和“卡车”。
3.2 Hierarchy-Aware Knowledge Graph Embedding 层次感知知识图谱嵌入
HAKE由两个部分组成——模量部分和相位部分——分别为两个不同类型的实体建模。

**模量部分(modulus)**目的是为层次结构中不同级别的实体建模。受有层级属性的实体可以被看成一棵树的影响,我们可以使用一个节点(实体)的书读来对层级的不同级别建模。由此,定义一个距离函数:
d r , m ( h m , t m ) = ∥ h m ∘ r m − t m ∥ 2 d_{r, m}\left(\mathbf{h}_{m}, \mathbf{t}_{m}\right)=\left\|\mathbf{h}_{m} \circ \mathbf{r}_{m}-\mathbf{t}_{m}\right\|_{2} dr,m(hm,tm)=∥hm∘rm−tm∥2
- 其中 h m ∘ r m = t m , where h m , t m ∈ R k , and r m ∈ R + k \mathbf{h}_{m} \circ \mathbf{r}_{m}=\mathbf{t}_{m}, \text { where } \mathbf{h}_{m}, \mathbf{t}_{m} \in \mathbb{R}^{k}, \text { and } \mathbf{r}_{m} \in \mathbb{R}_{+}^{k} hm∘rm=tm, where hm,tm∈Rk, and rm∈R+k ,
在这里,作者允许实体嵌入的条目(entry)为负(作者这里用的negative,但是结合下述,这里应该是表示符号的正负),但是限制关系嵌入的条目为正。作者解释:这是因为实体嵌入的符号可以帮助我们来预测两个实体之间是否存在关系。具体解释:通过上面的距离函数,因为关系嵌入的每一项都是大于0的(这里应该是作者给予的限制条件),通过距离函数进行优化,对于正样例来说,为了使d尽量小,头尾实体的嵌入符号是偏向于符号一致的,而对于负样例,我们希望d尽量大,所以头尾实体的符号可能会有所不同。
此外,我们可以期望层次结构中更高级别的实体有着更小的模量,同时这些尸体会更靠近树的根节点。
如果我们只使用模量部分来嵌入知识图谱,那么属于(b)类的实体将具有相同的模量而不能区分开。此外,假设 r r r是反应相同语义层级的关系,那么 [ r ] i [\mathbf{r}]_{i} [r]i将趋于1,因为 h ∘ r ∘ r = h h \circ r \circ r=h h∘r∘r=h对于所有 h h h都成立。因此,类别(b)中的实体嵌入趋于相同,这使得很难区分这些实体。
**相位部分(phase)**目的是对层级结构中语义级别相同的实体建模。受在同一个圆上的点有着不同的相位的事实启发,我们是同相位信息来区分类别(b)中的实体。
相位距离函数如下:
d r , p ( h p , t p ) = ∥ sin ( ( h p + r p − t p ) / 2 ) ∥ 1 d_{r, p}\left(\mathbf{h}_{p}, \mathbf{t}_{p}\right)=\left\|\sin \left(\left(\mathbf{h}_{p}+\mathbf{r}_{p}-\mathbf{t}_{p}\right) / 2\right)\right\|_{1} dr,p(hp,tp)=∥sin((hp+rp−tp)/2)∥1
- ( h p + r p ) m o d 2 π = t p , where h p , r p , t p ∈ [ 0 , 2 π ) k \left(\mathbf{h}_{p}+\mathbf{r}_{p}\right) \bmod 2 \pi=\mathbf{t}_{p}, \text { where } \mathbf{h}_{p}, \mathbf{r}_{p}, \mathbf{t}_{p} \in[0,2 \pi)^{k} (hp+rp)mod2π=tp, where hp,rp,tp∈[0,2π)k
这里作者使用 sin ( ⋅ ) \sin (\cdot) sin(⋅)应用与输入的每一个元素,是因为相位具有周期性。这个函数与pRotatE (Sun et al. 2019)相同。
HAKE将模量部分和相位部分结合在一起,将实体映射到极坐标系,其中径向坐标和角坐标分别对应于模量部分和相位部分。
{ h m ∘ r m = t m , where h m , t m ∈ R k , r m ∈ R + k ( h p + r p ) m o d 2 π = t p , where h p , t p , r p ∈ [ 0 , 2 π ) k \left\{\begin{array}{l}\mathbf{h}_{m} \circ \mathbf{r}_{m}=\mathbf{t}_{m}, \text { where } \mathbf{h}_{m}, \mathbf{t}_{m} \in \mathbb{R}^{k}, \mathbf{r}_{m} \in \mathbb{R}_{+}^{k} \\ \left(\mathbf{h}_{p}+\mathbf{r}_{p}\right) \bmod 2 \pi=\mathbf{t}_{p}, \text { where } \mathbf{h}_{p}, \mathbf{t}_{p}, \mathbf{r}_{p} \in[0,2 \pi)^{k}\end{array}\right. {hm∘rm=tm, where hm,tm∈Rk,rm∈R+k(hp+rp)mod2π=tp, where hp,tp,rp∈[0,2π)k
距离函数:
d r ( h , t ) = d r , m ( h m , t m ) + λ d r , p ( h p , t p ) d_{r}(\mathbf{h}, \mathbf{t})=d_{r, m}\left(\mathbf{h}_{m}, \mathbf{t}_{m}\right)+\lambda d_{r, p}\left(\mathbf{h}_{p}, \mathbf{t}_{p}\right) dr(h,t)=dr,m(hm,tm)+λdr,p(hp,tp)
- 其中 λ ∈ R \lambda \in \mathbb{R} λ∈R是模型的可学习参数。
模型的分数函数定义为:
f r ( h , t ) = d r ( h , t ) = − d r , m ( h , t ) − λ d r , p ( h , t ) f_{r}(\mathbf{h}, \mathbf{t})=d_{r}(\mathbf{h}, \mathbf{t})=-d_{r, m}(\mathbf{h}, \mathbf{t})-\lambda d_{r, p}(\mathbf{h}, \mathbf{t}) fr(h,t)=dr(h,t)=−dr,m(h,t)−λdr,p(h,t)
当评估模型时,我们发现将一个混合偏差加入 d r , m ( h , t ) d_{r, m}(\mathbf{h}, \mathbf{t}) dr,m(h,t) 中可以帮助改善HAKE的模型表现,调整后的 d r , m ( h , t ) d_{r, m}(\mathbf{h}, \mathbf{t}) dr,m(h,t)模型被定义为:
d r , m ′ ( h , t ) = ∥ h m ∘ r m + ( h m + t m ) ∘ r m ′ − t m ∥ 2 d_{r, m}^{\prime}(\mathbf{h}, \mathbf{t})=\left\|\mathbf{h}_{m} \circ \mathbf{r}_{m}+\left(\mathbf{h}_{m}+\mathbf{t}_{m}\right) \circ \mathbf{r}_{m}^{\prime}-\mathbf{t}_{m}\right\|_{2} dr,m′(h,t)=∥hm∘rm+(hm+tm)∘rm′−tm∥2
- 其中 − r m < r m ′ < 1 -\mathbf{r}_{m}<\mathbf{r}_{m}^{\prime}<1 −rm<rm′<1是一个和 r m \mathbb{r}_m rm相同维度的向量,实际上,上式等同于:
d r , m ′ ( h , t ) = ∥ h m ∘ ( ( r m + r m ′ ) / ( 1 − r m ′ ) ) − t m ∥ 2 d_{r, m}^{\prime}(\mathbf{h}, \mathbf{t})=\left\|\mathbf{h}_{m} \circ\left(\left(\mathbf{r}_{m}+\mathbf{r}_{m}^{\prime}\right) /\left(1-\mathbf{r}_{m}^{\prime}\right)\right)-\mathbf{t}_{m}\right\|_{2} dr,m′(h,t)=∥hm∘((rm+rm′)/(1−rm′))−tm∥2
- 其中 / / /表示按元素除法。如果我们让 r m ← ( r m + r m ′ ) / ( 1 − r m ′ ) \mathbf{r}_{m} \leftarrow\left(\mathbf{r}_{m}+\mathbf{r}_{m}^{\prime}\right) /\left(1-\mathbf{r}_{m}^{\prime}\right) rm←(rm+rm′)/(1−rm′),则当比较不同实体对的距离时,修改后的距离函数与原始函数完全相同。
3.3 loss function
为了训练模型,作者使用了带有自对抗训练的负采样损失函数((Sun et al. 2019)
L = − log σ ( γ − d r ( h , t ) ) − ∑ i = 1 n p ( h i ′ , r , t i ′ ) log σ ( d r ( h i ′ , t i ′ ) − γ ) \begin{aligned} L=&-\log \sigma\left(\gamma-d_{r}(\mathbf{h}, \mathbf{t})\right) \\ &-\sum_{i=1}^{n} p\left(h_{i}^{\prime}, r, t_{i}^{\prime}\right) \log \sigma\left(d_{r}\left(\mathbf{h}_{i}^{\prime}, \mathbf{t}_{i}^{\prime}\right)-\gamma\right) \end{aligned} L=−logσ(γ−dr(h,t))−i=1∑np(hi′,r,ti′)logσ(dr(hi′,ti′)−γ)
- 其中 γ \gamma γ是一个固定margin, ( h i ′ , r , t i ′ ) \left(h_{i}^{\prime}, r, t_{i}^{\prime}\right) (hi′,r,ti′)是第i个负三元组。
p ( h j ′ , r , t j ′ ∣ { ( h i , r i , t i ) } ) = exp α f r ( h j ′ , t j ′ ) ∑ i exp α f r ( h i ′ , t i ′ ) p\left(h_{j}^{\prime}, r, t_{j}^{\prime} \mid\left\{\left(h_{i}, r_{i}, t_{i}\right)\right\}\right)=\frac{\exp \alpha f_{r}\left(\mathbf{h}_{j}^{\prime}, \mathbf{t}_{j}^{\prime}\right)}{\sum_{i} \exp \alpha f_{r}\left(\mathbf{h}_{i}^{\prime}, \mathbf{t}_{i}^{\prime}\right)} p(hj′,r,tj′∣{(hi,ri,ti)})=∑iexpαfr(hi′,ti′)expαfr(hj′,tj′)
是采样负三元组的概率分布,其中 α \alpha α是采样温度。
4 Experiments and Analysis
4.1 实验数据集

4.1.2 baseline
作者设计了以ModE模型,该模型的损失函数为: d r ( h , t ) = ∥ h ∘ r − t ∥ 2 , where h , r , t ∈ R k d_{r}(\mathbf{h}, \mathbf{t})=\|\mathbf{h} \circ \mathbf{r}-\mathbf{t}\|_{2}, \text { where } \mathbf{h}, \mathbf{r}, \mathbf{t} \in \mathbb{R}^{k} dr(h,t)=∥h∘r−t∥2, where h,r,t∈Rk。,但是允许其中关系 r r r取负数。
4.2 链接预测
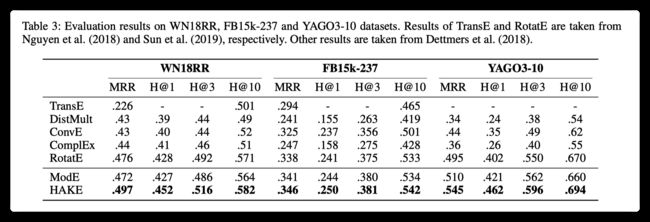
4.3 Analysis on Relation Embeddings
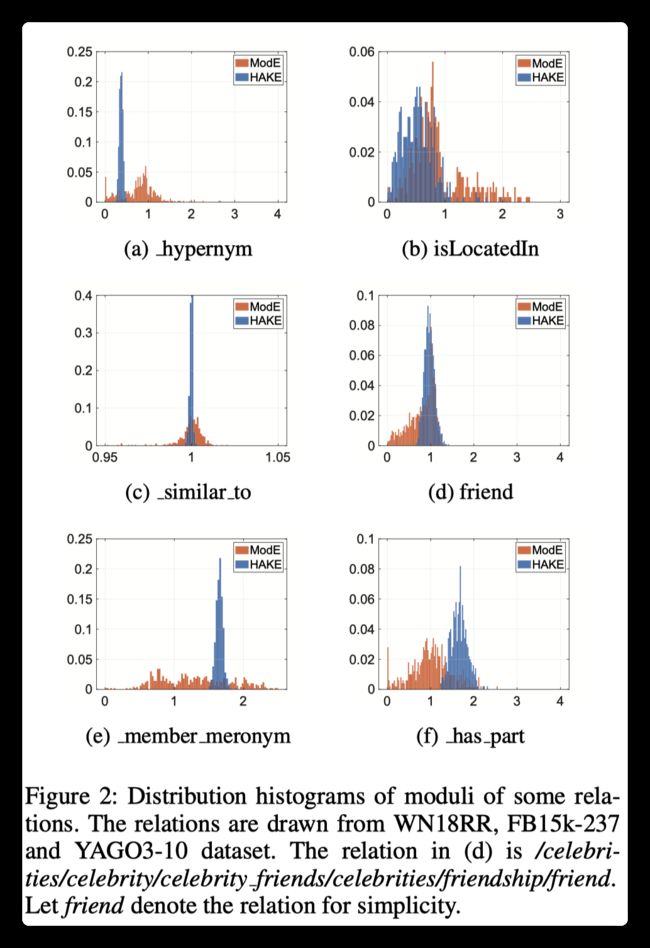
上图可以分成三组:
- (A)在图2c和2d中的关系连接着语义结构相同层级的实体;
- (B)在图2a和2b中的关系表示在语义层次中尾实体层次比头实体高;
- ©在图2e和2f中的关系表示在语义层次中尾实体层次比头实体低;
上图显示了作者期望的结果:在层次结构中具有更高级别层次的实体有着更小的模值。(这应该是指关系模向量中每一维度的模值分布情况)
Q: 一个关系不是应该只有一个模值吗?怎么还有分布?(这里不应该是指的是模值的距离函数所算出来的值吗?)
A: (这应该是指关系模向量中每一维度的模值分布情况)
(A)取大约1的值,这导致头实体和尾实体具有近似相同的模量。 在组(B)中,大多数关系条目的值小于1,这导致头部实体的模量小于尾部实体的模量。 (C)组的情况与(B)组的情况相反。
对于(A)组而言,很难通过模值来辨别这些关系。所以可以通过相位来辨别A组中的不同关系。下图展示了A组中不同关系的相位分布。

4.4 Analysis on Entity Embeddings
RotatE和作者的模型HAKE的比较可视化图:
请注意,我们使用对数刻度更好地显示实体嵌入之间的差异。 由于所有模量的值均小于1,因此在应用对数运算后,图中较大的半径实际上将表示较小的模量。
4.5 Ablation Studies

这里可以看到仅用模量部分的HAKE效果并不好,这是由于它不能区分位于相同层级的实体。当只使用相位部分,HAKE就退化为pRotatE模型。
4.6 Comparison with Other Related Work

参考链接
- 论文笔记:AAAI 2020 Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction