详解插帧算法DAIN论文和代码(Depth-Aware Video Frame Interpolation)
Project : https://sites.google.com/view/wenbobao/dain
Paper: https://arxiv.org/abs/1904.00830
Code: https://github.com/baowenbo/DAIN
2021年7月更新。之前写了一半,今天发现竟然一年过去了,赶紧补上。
这是一篇CVPR 2019的论文,经实验,效果非常好也比较稳定,并且经过优化,可以减少显存占用,因此可以用在4k视频的帧率提升上。很多up主使用此方法修复了很多老旧视频。但是和其他flow-based方法一样,效果比较依赖于光流预测的精度,在运动剧烈时会出现变形,在有字幕的素材上表现不佳(也算是一种遮挡),在重复纹理处表现不佳。
此方法另外的一个优势是其可以在两帧之间根据时间间隔插入任意数量的帧。
本文主要是结合代码讲解下论文的思想,首先看一下DAIN的整体框图:

DAIN延续了以往Flow-based视频插帧的基本框架,由5个sub-network和2个自定义的layer组成:首先计算出双向光流 (Flow estimation network + Depth estimation network + Depth-aware flow projection layer),然后根据光流对前后帧进行warp (Kernel estimation network + Adaptive warping layer),最后完成帧融合实现细节增强 (Frame Synthesis network)。
下面依次讲解以下各部分是怎么实现的。
1. 光流估计和深度图估计
DAIN分别使用PWC-NET和MegaDepth(hourglass结构)估计光流图和深度图,由于在DAIN的训练中是没有光流和深度真值监督的,因此作者直接使用前人的网络权重进行初始化,并在训练的时候给很小的学习率,分别为1e−6 and 1e−7,网络其他部分学习率为1e-4。
- depthnet
input shape: [N, C, H, W],output shape: [N, 1, H, W],即输入前后两帧的rgb, 输出两帧的depth map; - flownet:
input shape:[N, C*2, H, W],output shape: [N, 2, H, W],即输入前后两帧的rgb,输出flow map,有两个通道分别为x和y方向上的光流值;
2. Depth-Aware Flow Projection
2.1 有flow经过的位置估计光流值
2.1.1 原理
和其他flow-based方法一样,本方法也是基于均匀线性运动假设。
Flow projection layer通过reverse在时刻 t t t 经过 x x x 位置的flow来估计 t t t 时刻 x x x 位置的中间flow. 比如,如果 F 0 − > 1 ( y ) F_{0->1}(y) F0−>1(y)在 t t t 时刻经过了 x x x, 基于均匀线性运动假设,则 F t − > 0 ( x ) = − t F 0 − > 1 ( y ) F_{t->0}(x)=-t {F_{0->1}(y)} Ft−>0(x)=−tF0−>1(y),同理 F t − > 1 ( x ) = − ( 1 − t ) F 1 − > 0 ( y ) F_{t->1}(x)=-(1-t) {F_{1->0}(y)} Ft−>1(x)=−(1−t)F1−>0(y)。
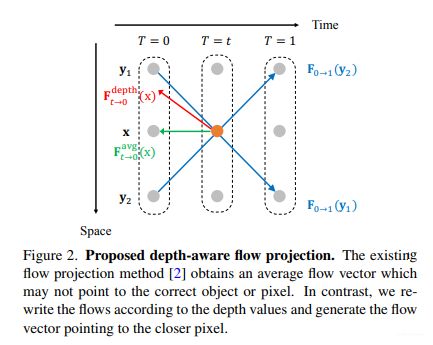
但是如上图所示,很多的flow vector可能会在 t t t 时刻同时经过同一个位置,在MEMC-NET[1]中采用的是直接平均的方法实现flow的聚合,这会导致无法找到正确的像素位置。因此,本文提出了基于深度图的flow聚合。
假定, D 0 D_0 D0 为 I 0 I_0 I0 的深度图, S ( x ) S(x) S(x) 表示在 t t t 时刻经过 x x x 的像素集合,则F_{t->0}(x)可以被定义为:

其中 w 0 w_0 w0 由深度图定义:

通过此方法,the projected flow倾向于从closer objects中采样像素,而减少被遮挡像素occluded pixels的贡献(occluded pixels有更大的深度值)。
2.1.2 代码
这部分代码主要围绕公式1展开
- (1)计算 t ⋅ F 0 − > 1 ( y ) t·F_{0->1}(y) t⋅F0−>1(y) 和 ( 1 − t ) ⋅ F 1 − > 0 ( y ) (1-t)·F_{1->0}(y) (1−t)⋅F1−>0(y)
由forward_flownets函数实现,当光流值temp算出来之后,有一个根据time_offsets发挥作用的地方temps = [self.div_flow * temp * time_offset for time_offset in time_offsets],time_offsets默认为[0.5]。
def forward_flownets(self, model, input, time_offsets = None):
if time_offsets == None :
time_offsets = [0.5]
elif type(time_offsets) == float:
time_offsets = [time_offsets]
elif type(time_offsets) == list:
pass
temp = model(input) # this is a single direction motion results, but not a bidirectional one
temps = [self.div_flow * temp * time_offset for time_offset in time_offsets]# single direction to bidirection should haven it.
temps = [nn.Upsample(scale_factor=4, mode='bilinear')(temp) for temp in temps]# nearest interpolation won't be better i think
return temps
分别计算双向的光流, t ⋅ F 0 − > 1 ( y ) t·F_{0->1}(y) t⋅F0−>1(y) 和 ( 1 − t ) ⋅ F 1 − > 0 ( y ) (1-t)·F_{1->0}(y) (1−t)⋅F1−>0(y)
cur_offset_outputs = [
self.forward_flownets(self.flownets, cur_offset_input, time_offsets=time_offsets),
self.forward_flownets(self.flownets, torch.cat((cur_offset_input[:, 3:, ...],
cur_offset_input[:, 0:3, ...]), dim=1),
time_offsets=time_offsets[::-1])
]
- (2) 根据(1)的结果完成公式1中分子分母的计算
此layer的实现主要的两个kernel函数,第一段主要是完成(1)公式中分子和分母的计算,重要的地方注释了一下:
//forward path of our layer
template <typename scalar_t>
__global__ void DepthFlowProjection_gpu_forward_kernelfunc(
const int nElement,
const int w,
const int h,
const int channel,
const int input1_b_stride, const int input1_c_stride, const int input1_h_stride, const int input1_w_stride,
const int input2_b_stride, const int input2_c_stride, const int input2_h_stride, const int input2_w_stride,
const int count_b_stride, const int count_c_stride, const int count_h_stride, const int count_w_stride,
// input1:光流图*t,即 t*F0->1(y) ,即F0->t(y)
// input2:深度图的倒数, 即1/D_0
const scalar_t* __restrict__ input1, const scalar_t* __restrict__ input2,
// count即公式(1)中的分母, output为公示(1)中的分子
scalar_t* count,
scalar_t* output
)
{
//blockIdx.z : batch index from 0~B-1
//blockIdx.y : height patch index from ceil(h/16)
//blockIdx.x : width patch index from ceil(w/32)
//threadidx.x: width index 0~31
//threadIdx.y: height index 0~15
//threadIdx.z: Not used
//only use one dimensioon of the grid and block
// 光流图的某位置y(h_i, w_i),一定注意这段代码是以光流图的位置为主体的
const int w_i = blockIdx.x * blockDim.x + threadIdx.x;
const int h_i = blockIdx.y * blockDim.y + threadIdx.y;
const bool withinXbounds = w_i < w;
const bool withinYbounds = h_i < h;
const int batch_i = blockIdx.z;
const int off = batch_i * input1_b_stride;
// __syncthreads();
// const float fillvalue =0.0f;
if( withinXbounds && withinYbounds) {
// 取出光流图y位置的vector
float fx = input1[ off + 0 * input1_c_stride + h_i * input1_h_stride + w_i ];
float fy = input1[ off + 1 * input1_c_stride + h_i * input1_h_stride + w_i ];
// 基于vector计算得中间位置x
float x2 = (float) (w_i) + fx;
float y2 = (float) (h_i) + fy;
if(x2>=0.0f && y2 >= 0.0f &&x2 <= (float) ( w-1) && y2 <= (float) (h -1 ) ){
// 因为算出来的中间位置肯定是浮点数,因为其周围4个点都进行同样的映射;
int ix2_L = (int) (x2);
int iy2_T = (int) (y2);
int ix2_R = min(ix2_L + 1, w - 1);
int iy2_B = min(iy2_T + 1, h - 1);
//取出y位置深度图的值,即D0(y)
float temp = input2[batch_i * input2_b_stride + 0 + h_i * input2_h_stride + w_i];
// 完成(1)公示中分子的计算
atomicAdd(&output[off + 0 * input1_c_stride + iy2_T * input1_h_stride + ix2_L ] ,- temp * fx);
atomicAdd(&output[off + 0 * input1_c_stride + iy2_T * input1_h_stride + ix2_R ],-temp * fx);
atomicAdd(&output[off + 0 * input1_c_stride + iy2_B * input1_h_stride + ix2_L ] ,-temp * fx);
atomicAdd(&output[off + 0 * input1_c_stride + iy2_B * input1_h_stride + ix2_R ],-temp * fx);
atomicAdd(&output[off + 1 * input1_c_stride + iy2_T * input1_h_stride + ix2_L] , -temp * fy);
atomicAdd(&output[off + 1 * input1_c_stride + iy2_T * input1_h_stride + ix2_R] , -temp * fy);
atomicAdd(&output[off + 1 * input1_c_stride + iy2_B * input1_h_stride + ix2_L] , -temp * fy);
atomicAdd(&output[off + 1 * input1_c_stride + iy2_B * input1_h_stride + ix2_R] , -temp * fy);
//完成(1)公式中分母的计算
atomicAdd(& count[batch_i * count_b_stride + 0 + iy2_T * count_h_stride + ix2_L], temp * 1);
atomicAdd(& count[batch_i * count_b_stride + 0 + iy2_T * count_h_stride + ix2_R] ,temp * 1);
atomicAdd(& count[batch_i * count_b_stride + 0 + iy2_B * count_h_stride + ix2_L] , temp * 1);
atomicAdd(& count[batch_i * count_b_stride + 0 + iy2_B * count_h_stride + ix2_R] ,temp * 1);
}
}
return ;
}
第二段完成的分子分母相除,这段没啥好说的:
template <typename scalar_t>
__global__ void DepthFlowProjectionAveraging_kernelfunc(
const int nElement,
const int w,
const int h,
const int channel,
const int input1_b_stride, const int input1_c_stride, const int input1_h_stride, const int input1_w_stride,
const int input2_b_stride, const int input2_c_stride, const int input2_h_stride, const int input2_w_stride,
const int count_b_stride, const int count_c_stride, const int count_h_stride, const int count_w_stride,
const scalar_t* __restrict__ input1, const scalar_t* __restrict__ input2,
scalar_t* count,
scalar_t* output
)
{
//blockIdx.z : batch index from 0~B-1
//blockIdx.y : height patch index from ceil(h/16)
//blockIdx.x : width patch index from ceil(w/32)
//threadidx.x: width index 0~31
//threadIdx.y: height index 0~15
//threadIdx.z: Not used
//only use one dimensioon of the grid and block
const int w_i = blockIdx.x * blockDim.x + threadIdx.x;
const int h_i = blockIdx.y * blockDim.y + threadIdx.y;
const bool withinXbounds = w_i < w;
const bool withinYbounds = h_i < h;
const int batch_i = blockIdx.z;
const int off = batch_i * input1_b_stride;
// __syncthreads();
// const float fillvalue =0.0f;
if( withinXbounds && withinYbounds) {
float temp =count[batch_i * count_b_stride + 0 + h_i * count_h_stride + w_i] ;
if(temp > 0.0f){
output[off + 0 * input1_c_stride + h_i * input1_h_stride + w_i ] /= temp;
output[off + 1 * input1_c_stride + h_i * input1_h_stride + w_i ] /= temp;
}
}
return ;
}
2.2 没有flow经过的位置填充光流值
经过上一小节的映射,有flow经过的位置,都获得了中间flow,没有flow经过的位置,就形成了holes。为了填充这些holes,此论文采用了outside-in策略,即拿周围的相邻像素进行填充。
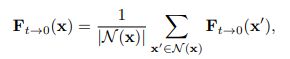
N ( x ) N(x) N(x) 是x的四邻域。
depth-aware flow projection layer是可微的,因此flow estimation和depth estimation可以在训练中联合优化(jointly optimized)
3. Kernel estimation and Adaptive warping layer

通过之前获得的光流值可以在输入帧中找到对应的位置,以此为中心,在local window中采样合成新的像素值。Adaptive warping layer 是作者之前的文章中MEMC-NET[1]提出的,首先通过kernel estimation network在图像的每一个像素位置预测出一个4x4的kernel,与bilinear kernel结合起来完成新像素值的计算。

k r k_r kr为learned kernel和bilinear kernel的结合, I I I为输入图像, f ( x ) f(x) f(x)为光流值。
结合代码看一下,加深理解,重点位置加了一些注释:
//forward path of our layer
template <typename scalar_t>
__global__ void FilterInterpolationLayer_gpu_forward_kernelfunc(
const int nElement,
const int w, const int h, const int channel, const int filter_size,
const int input1_b_stride, const int input1_c_stride, const int input1_h_stride, const int input1_w_stride,
const int input2_b_stride, const int input2_c_stride, const int input2_h_stride, const int input2_w_stride,
const int input3_b_stride, const int input3_c_stride, const int input3_h_stride, const int input3_w_stride,
const scalar_t* __restrict__ input1, const scalar_t* __restrict__ input2, const scalar_t* __restrict__ input3, scalar_t* output
)
{
//blockIdx.z : batch index from 0~B-1
//blockIdx.y : height patch index from ceil(h/16)
//blockIdx.x : width patch index from ceil(w/32)
//threadidx.x: width index 0~31
//threadIdx.y: height index 0~15
//threadIdx.z: Not used
//only use one dimensioon of the grid and block
const int w_i = blockIdx.x * blockDim.x + threadIdx.x;
const int h_i = blockIdx.y * blockDim.y + threadIdx.y;
const bool withinXbounds = w_i < w;
const bool withinYbounds = h_i < h;
const int batch_i = blockIdx.z;
const int off = batch_i * input1_b_stride;
// __syncthreads();
// const float fillvalue =0.0f;
if( withinXbounds && withinYbounds) {
// 取出x,y方向上的光流值
float fx = input2[batch_i * input2_b_stride + 0 * input2_c_stride + h_i * input2_h_stride + w_i ];
float fy = input2[batch_i * input2_b_stride + 1 * input2_c_stride + h_i * input2_h_stride + w_i ];
// 算出local window的中心位置
float x2 = (float)(w_i) + fx;
float y2 = (float)(h_i) + fy;
if(x2 >= 0.0f && y2 >=0.0f && x2 <= (float)(w -1) && y2 <= (float)(h-1)
&& fabs(fx) < (float)(w)/2.0f && fabs(fy) < (float)(h)/2.0f){
// 根据filter尺寸,计算local window上下左右边界
int ix2_L = int(x2) + 1 - (int)(filter_size / 2);
int iy2_T = int(y2) + 1 - (int)(filter_size / 2);
int ix2_R = ix2_L + filter_size;
int iy2_B = iy2_T + filter_size;
float alpha = x2 - (int)(x2);
float beta = y2 - (int)(y2);
//TODO: here is a bug that if the iy2_B or ix2_R gets out of the border, than there is no enough pixels to warp the target one.
for (int c_i = 0 ; c_i < channel ; c_i++){
// 将local window分成上左,上右,下左,下右四个部分,分别计算weighted sum,得到四个值
float TL = 0.0f;
for(int filter_j = iy2_T; filter_j <= (int)(y2); filter_j ++){
int _filter_j = min(max(0, filter_j), h - 1);
for( int filter_i = ix2_L; filter_i <= (int) ( x2) ; filter_i ++ ){
int _filter_i = min(max(0, filter_i ), w - 1);
TL += input1[off + c_i * input1_c_stride + _filter_j * input1_h_stride + _filter_i ] *
input3 [batch_i * input3_b_stride + ((filter_j - iy2_T) * filter_size + (filter_i - ix2_L)) * input3_c_stride + h_i * input3_h_stride + w_i] ;
}
}
float TR = 0.0f;
for (int filter_j = iy2_T; filter_j <= (int) (y2); filter_j ++ ){
int _filter_j = min(max(0, filter_j),h - 1); // only used for input1
for (int filter_i = (int) (x2) + 1 ; filter_i < ix2_R; filter_i ++ ){
int _filter_i = min(max(0, filter_i),w - 1);// only used for input1
TR += input1 [off + c_i * input1_c_stride + _filter_j * input1_h_stride + _filter_i] *
input3 [batch_i * input3_b_stride + ((filter_j - iy2_T) * filter_size + (filter_i - ix2_L)) * input3_c_stride + h_i * input3_h_stride + w_i];
}
}
float BL = 0.0f;
for (int filter_j = (int) (y2) + 1; filter_j < iy2_B; filter_j ++ ){
int _filter_j = min(max(0, filter_j),h - 1); // only used for input1
for (int filter_i = ix2_L; filter_i <= (int) (x2); filter_i ++ ){
int _filter_i = min(max(0, filter_i),w - 1);// only used for input1
BL += input1 [off + c_i * input1_c_stride + _filter_j * input1_h_stride + _filter_i] *
input3 [batch_i * input3_b_stride + ((filter_j - iy2_T) * filter_size + (filter_i - ix2_L)) * input3_c_stride + h_i * input3_h_stride + w_i];
}
}
float BR = 0.0f;
for (int filter_j = (int) (y2) + 1; filter_j < iy2_B; filter_j ++ ){
int _filter_j = min(max(0, filter_j),h - 1); // only used for input1
for (int filter_i = (int) (x2) + 1; filter_i < ix2_R; filter_i ++ ){
int _filter_i = min(max(0, filter_i),w - 1);// only used for input1
BR += input1 [off + c_i * input1_c_stride + _filter_j * input1_h_stride + _filter_i] *
input3 [batch_i * input3_b_stride + ((filter_j - iy2_T) * filter_size + (filter_i - ix2_L)) * input3_c_stride + h_i * input3_h_stride + w_i];
}
}
// 利用bilinear kernel将TL TR BL BR四个值合成一个值
output[off + c_i * input1_c_stride + h_i * input1_h_stride + w_i ] =
(1-alpha)*(1-beta)*TL +
alpha*(1-beta)*TR +
(1-alpha)*beta*BL +
alpha*beta*BR;
}
} else{
//the warping data is out of range, we fill it with zeros
for(int c_i = 0 ; c_i < channel; c_i ++){
output[off + c_i * input1_c_stride + h_i * input1_h_stride + w_i] = input1[off + c_i* input1_c_stride+ h_i * input1_h_stride + w_i];
}
}
}
return ;
}
input frames, depth maps, and contextual features都在此层完成warp.
4. Frame Synthesis Network
此网络作为post-process,完成帧合成,由3个residual blocks组成。将warped input frames, warped depth maps, warped contextual features, projected flows, and interpolation kernels五部分concat起来输入到网络中,并且将average warped frames作为skip connection引入到网络中,那么实际上该网络学习的是average warped frames和GT之间的残差。
其实,在经过warp后,warped frame已经aligned,此网络更多的是进行细节增强,使得生成的帧更sharp。
本篇文章就介绍到这里,最后作者也说了方法的问题:本方法比较依赖depth estimation的精度来检测遮挡,有些场景下depth预测的不准,会出现blurred results with unclear boundaries。
参考文献
[1] W. Bao, W.-S. Lai, X. Zhang, Z. Gao, and M.-H. Yang.
MEMC-Net: Motion Estimation and Motion Compensation Driven Neural Network for Video Interpolation and Enhancement. arXiv, 2018