Python神经网络模型--Sequential应用举例
本篇文章都是Sequential应用的例子
如果想要了解模型,可以先看一下这篇文章:
Sequential模型详解
下面是样例展示:
这里有几个可以帮助你开始的例子!
在 examples 目录 中,你可以找到真实数据集的示例模型:
- CIFAR10 小图片分类:具有实时数据增强的卷积神经网络 (CNN)
- IMDB 电影评论情感分类:基于词序列的 LSTM Reuters
- 新闻主题分类:多层感知器 (MLP) MNIST 手写数字分类:MLP 和 CNN
- 基于 LSTM 的字符级文本生成
基于多层感知器 (MLP) 的 softmax 多分类:
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# 生成虚拟数据
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# Dense(64) 是一个具有 64 个隐藏神经元的全连接层。
# 在第一层必须指定所期望的输入数据尺寸:
# 在这里,是一个 20 维的向量。
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
基于多层感知器的二分类:
思路:
输入数据:定义输入一个二维数组(x1,x2),数据通过numpy来随机产生,将输出定义为0或者1,如果x1+x2<1,则y为1,否则y为0.
隐藏层:定义两层隐藏层,隐藏层的参数为(2,3),两行三列的矩阵,输入数据通过隐藏层之后,输出的数据为(1,3),t通过矩阵之间的乘法运算可以获得输出数据。
损失函数:使用交叉熵作为神经网络的损失函数,常用的损失函数还有平方差。
优化函数:通过油画函数来使得损失函数最小化,这里采用的是Adadelta算法进行优化,常用的有梯度下降算法。
输出数据:将隐藏层的输出数据通过(3,1)的参数,输出一个一维向量,值的大小为0或者1.
import numpy as np
from keras.models import Sequential
from keras.layers import Dense,Dropout
# 生成数据,训练数据和测试数据
# x_train/x_test 生成随机的浮点数,x_train为1000行20列 x_test为100行20列
# 列数一定要一一对应,相当于特征个数要对应
# 此处的二元分类,可以不需要one_hot编译,np.random.randint可以直接生成0 1 编码
x_train = np.random.random((1000,20))
y_train = np.random.randint(2,size=(1000,1))
# print(x_train)
# print(y_train)
x_test = np.random.random((100,20))
y_test = np.random.randint(2,size=(100,1))
# 设计模型,通过add的方式叠起来
# 注意输入时,初始网络一定要给定输入的特征维度input_dim 或者input_shape数据类型
# activition激活函数既可以在Dense网络设置里,也可以单独添加
model = Sequential()
model.add(Dense(64,input_dim=20,activation='relu'))
# Drop防止过拟合的数据处理方式
model.add(Dropout(0.5))
model.add(Dense(64,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
# 编译模型,定义损失函数,优化函数,绩效评估函数
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 导入数据进行训练
model.fit(x_train,y_train,epochs=20,batch_size=128)
# 模型评估
score = model.evaluate(x_test,y_test,batch_size=128)
print(score)
类似VGG的卷积神经网络
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# 生成虚拟数据
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# 输入: 3 通道 100x100 像素图像 -> (100, 100, 3) 张量。
# 使用 32 个大小为 3x3 的卷积滤波器。
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)
基于LSTM的序列分类
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
基于 1D 卷积的序列分类:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
基于栈式 LSTM 的序列分类
在这个模型中,我们将 3 个 LSTM 层叠在一起,使模型能够学习更高层次的时间表示。
前两个 LSTM 返回完整的输出序列,但最后一个只返回输出序列的最后一步,从而降低了时间维度(即将输入序列转换成单个向量)。
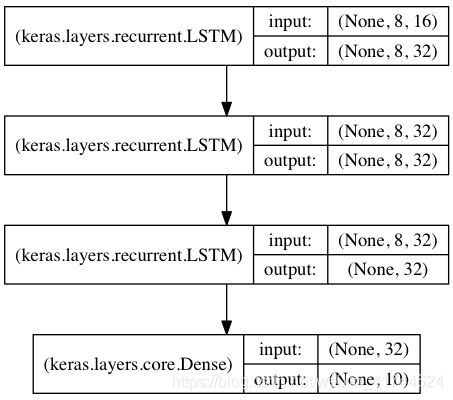
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# 期望输入数据尺寸: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # 返回维度为 32 的向量序列
model.add(LSTM(32, return_sequences=True)) # 返回维度为 32 的向量序列
model.add(LSTM(32)) # 返回维度为 32 的单个向量
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 生成虚拟训练数据
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# 生成虚拟验证数据
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))
带有状态 (stateful) 的 相同的栈式 LSTM 模型
有状态的循环神经网络模型中,在一个 batch 的样本处理完成后,其内部状态(记忆)会被记录并作为下一个 batch 的样本的初始状态。这允许处理更长的序列,同时保持计算复杂度的可控性。
你可以在 FAQ 中查找更多关于 stateful RNNs 的信息
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# 期望输入数据尺寸: (batch_size, timesteps, data_dim)
# 请注意,我们必须提供完整的 batch_input_shape,因为网络是有状态的。
# 第 k 批数据的第 i 个样本是第 k-1 批数据的第 i 个样本的后续。
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 生成虚拟训练数据
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# 生成虚拟验证数据
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))