KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
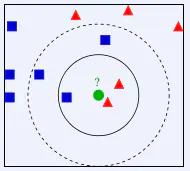
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
优缺点
1、优点
简单,易于理解,易于实现,无需估计参数,无需训练
适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
2、缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
可解释性较差,无法给出决策树那样的规则。
常见问题
1、k值设定为多大?
k太小,分类结果易受噪声点影响;k太大,近邻中又可能包含太多的其它类别的点。(对距离加权,可以降低k值设定的影响)
k值通常是采用交叉检验来确定(以k=1为基准)
经验规则:k一般低于训练样本数的平方根
2、类别如何判定最合适?
投票法没有考虑近邻的距离的远近,距离更近的近邻也许更应该决定最终的分类,所以加权投票法更恰当一些。
3、如何选择合适的距离衡量?
高维度对距离衡量的影响:众所周知当变量数越多,欧式距离的区分能力就越差。
变量值域对距离的影响:值域越大的变量常常会在距离计算中占据主导作用,因此应先对变量进行标准化。
4、训练样本是否要一视同仁?
在训练集中,有些样本可能是更值得依赖的。
可以给不同的样本施加不同的权重,加强依赖样本的权重,降低不可信赖样本的影响。
5、性能问题?
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
已经有一些方法提高计算的效率,例如压缩训练样本量等。
6、能否大幅减少训练样本量,同时又保持分类精度?
浓缩技术(condensing)
编辑技术(editing)
python3实现
from numpy import * import operator def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return (group,labels) def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize,1))-dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 # change itemgetter to item sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] if __name__=='__main__': print ('dataset - labels') print(createDataSet()) group,labels = createDataSet() label = classify0([1,1.3],group,labels,3) print (label)