P-R曲线的绘制
首先了解一下什么是pr曲线
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。
precision(精准率)和recall(召回率)
上述中介绍了PR曲线的实质代表为precision(精准率)和recall(召回率),但是这二者是什么呢?
首先,我们了解一下混淆矩阵,如下表。
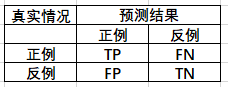
其中TP 表示正确分出正例的数量;FN 表示把正例错分为反例的数量;TN 表示正确分出反例的数量;FP表示把反例错分为正例的数量。
从混淆矩阵可以得出
精准率 precision = TP/(TP + FP)
召回率 recall = TP/(TP +FN)
举例如下:
假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示:

现在让系统进行识别

其中下面的四个被识别为飞机上面的六个被识别为大雁
那么TP=3,FP=1,TN=4,FN=2;
精准率 precision = TP/(TP + FP)=0.75 意味着在识别出的结果中,飞机的图片占75%。
召回率 recall = TP/(TP +FN)=0.6 意味着在所有的飞机图片中,60%的飞机被正确的识别成飞机.。
调整阈值
可以通过调整阈值,来选择让系统识别出多少图片,进而改变Precision 或 Recall 的值。
在某种阈值的前提下(虚线),系统识别出了四张图片,如下图中所示:

系统认为大于阈值0.6(虚线之上)的四个图片为飞机,虚线以下的为大雁。
此时,TP=3,FP=1,TN=4,FN=2;
精准率 precision=TP/(TP + FP)=3/(3+2)=0.75
召回率 recall = TP/(TP +FN)=3/(3+2)=0.6
改变阈值比如设置阈值分别为0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9就可以得到10组P和R的值,就可以由此绘画P-R曲线
绘制P-R曲线
使用python进行绘制
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import precision_recall_curve
plt.title('P-R Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
y_true = np.array([1,0,0,0,1,0,1,0,1,1])
y_scores = np.array([0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9])
# y_true为样本实际的类别1为正例0为反例,y_scores为阈值
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
plt.plot(recall, precision)
plt.show()
代码运行结果如下即为P-R曲线

例子来源:average precision (wordpress.com)
代码参考来源:(29条消息) python画PR曲线(precision-recall曲线)_Mr.Jcak的博客-CSDN博客_precision_recall_curve