解读Mobilenet系列V1V2V3
目录
文章目录
-
- MobileNet 三个阶段的发展脉络
- 阶段1:深度可分离卷积
-
- 1. 遇到问题
- 2. 解决方案
- 3. 合理性分析:
- 阶段2:反转残差和线性瓶颈模块 (inverted residual with linear bottleneck)
-
- 1. 遇到问题
- 2 解决方案:
- 3 翻转残差结构
- 4 激活函数
- 阶段3:MobileNetV3
-
- 1. V3 在结构上的调整
- 2. Squeeze Excitation结构
-
- 挤出(Squeeze):
- 激励(Excitation):
- 缩放(scale)
- SE模块的优势
- 3. 基于强化学习的platform-aware NAS
-
- 搜索空间
- 迭代循环
- 采样
- 评估
- 更新
- 4. NetAdapt对层内优化
- 5. 全局均值池化来降维
- 6. 采用H-swish作为非线性激活函数
MobileNet 三个阶段的发展脉络
阶段1:深度可分离卷积
1. 遇到问题
由于深度神经网络的卷积层网络的计算量太大(每层卷积: w ∗ h ∗ ( k ∗ k ∗ c i n ) ∗ c o u t w*h*(k*k*c_{in})*c_{out} w∗h∗(k∗k∗cin)∗cout),在移动端和边缘计算场景中很难部署,所以必须要对其进行简化才能应用。
2. 解决方案
分解的思路:由于输入输出是外生变量,可以看做是常量,因此每个卷积层的计算量可表示为
f ( k , c o u t ) = η ( w , h , c i n ) ∗ k 2 ∗ c o u t f(k,c_{out})=\eta_{(w,h,c_{in})} *k^2*c_{out} f(k,cout)=η(w,h,cin)∗k2∗cout
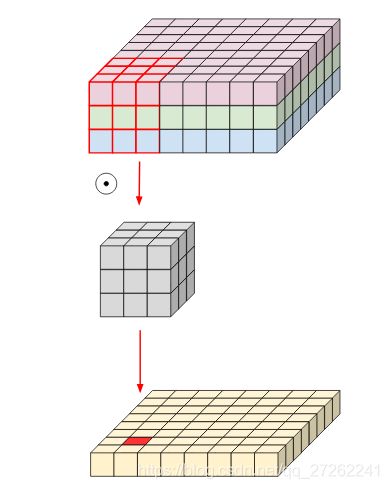
所以可选的优化策略有两个,降低卷积核的大小,或者降低输出的通道数。卷积核的大小一般为 1 ∗ 1 , 3 ∗ 3 , 5 ∗ 5 1*1,3*3,5*5 1∗1,3∗3,5∗5,如果选择最小的尺寸 1 ∗ 1 1*1 1∗1可以大幅度的提高速度,是3x3的9倍,5x5的25倍。

但卷积核的大小会对卷积层的学习性能有很大的影响,卷积核在单个通道内部是某一局部点与相邻周围点的脉冲响应函数。如果太小就无法表达出相邻像素的相关性,缩小卷积核提高了速度,却无法学习到相邻像素的响应关系。那能够先表达出像素之间的响应关系,然后再进行1x1的卷积。恰好在单个通道内部运行的卷积的作用的就是学习相邻像素点之间的响应关系的,所以顺着该思路,便自然的提出了,通过单通道内卷积+通道间点卷积 来替换原有的卷积。
计算量
把整体的卷积看作一个4维矩阵
A ( k ∗ k ∗ c i n ) ∗ c o u t A_{(k*k*c_{in}) *c_{out}} A(k∗k∗cin)∗cout
,这个4维矩阵可以通过两个矩阵相乘获得,
即
A ( k ∗ k ∗ c i n ) ∗ c o u t = B ( k ∗ k ∗ c i n ) ∙ C 1 ∗ 1 ∗ c i n ∗ c o u t A_{(k*k*c_{in}) *c_{out}} = B_{(k*k*c_{in}) } \bullet C_{1*1*c_{in}*c_out} A(k∗k∗cin)∗cout=B(k∗k∗cin)∙C1∗1∗cin∗cout
分解后,可分别对输入数据 I w ∗ h ∗ c i n I_{w*h*c_{in}} Iw∗h∗cin 做两次卷积操作,
I w ∗ h ∗ c i n ⊗ d B ⊗ p C = O w ∗ h ∗ c o u t I_{w*h*c_{in}} \otimes_{d} B \otimes_{p} C =O_{w*h*c_{out}} Iw∗h∗cin⊗dB⊗pC=Ow∗h∗cout
经过这样处理后,每层卷积操作的计算量变成了分解后两次卷积的计算量之和
w ∗ h ∗ ( k ∗ k ∗ c i n + 1 ∗ 1 ∗ c i n ∗ c o u t ) = w ∗ h ∗ c i n ∗ ( k ∗ k + 1 ∗ 1 ∗ c o u t ) w*h*(k*k*c_{in} + 1*1*c_{in}*c_{out}) = w*h*c_{in}*(k*k + 1*1*c_{out}) w∗h∗(k∗k∗cin+1∗1∗cin∗cout)=w∗h∗cin∗(k∗k+1∗1∗cout)
可以看到经过分解后,把之前运算量中的乘法部分变成了加法部分,分解后,计算量减小了 k ∗ k ∗ c o u t k ∗ k + c o u t \frac{k*k*c_{out}}{k*k + c_{out}} k∗k+coutk∗k∗cout 倍。
3. 合理性分析:
一个卷积层的目的是为了学习一个3维滤波器(通道的长宽方向和 通道层之间),因此一个卷积核的目的是为了同时映射长宽方向的关系和深度方向的关系。通过分解后,把卷积核在宽度和深度方向的映射功能显式的表达出来了。[1]
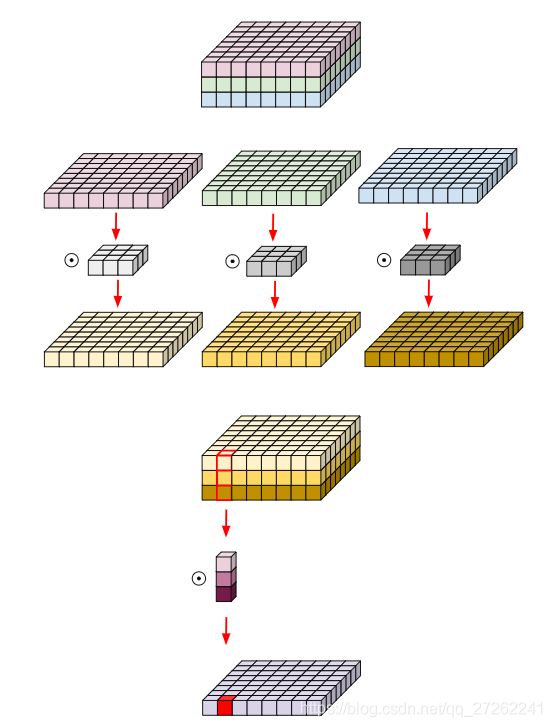
阶段2:反转残差和线性瓶颈模块 (inverted residual with linear bottleneck)
1. 遇到问题
- 深度层卷积没有改变输入通道的能力,如果输入层数很少,只能在很低维度上运算。
- 实际训练发现,某些卷积核在训练过程中是空值。
作者认为是ReLU存在问题。当把输入X映射到n维空间做ReLU运算后,变换回当前空间,会丢失掉很多信息,维度越低,丢失的信息越严重。所以V2中把ReLU转换成了线性激活函数ReLu6。
2 解决方案:
对于V1中深度分离层无法扩展通道的缺点:提出了线性瓶颈模块(Bottleneck),它采用1x1xC1xN的卷积核对输入的通道数进行压缩(N
例如:
[ w ∗ h ∗ 100 ] ⊙ ( [ 1 ∗ 1 ∗ 100 ] ∗ 50 ) [w*h*100]\odot([1*1*100] *50) [w∗h∗100]⊙([1∗1∗100]∗50)
可以实现把一个输入为100个通道的数据压缩成50个通道,在网络中就好像“瓶颈”一样,它首先被ResNet 网络提出,用于降低输入数据的通道数。
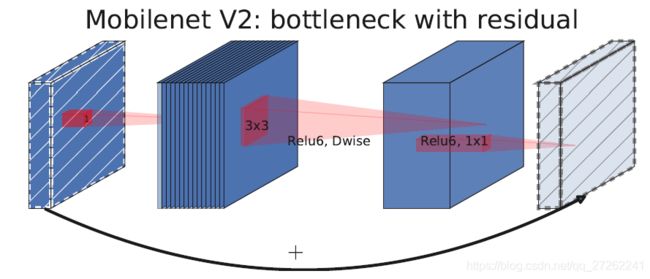
但Mobilenet V2中的“瓶颈”更像是个“橄榄球”,因为V2中用瓶颈层来扩展通道。
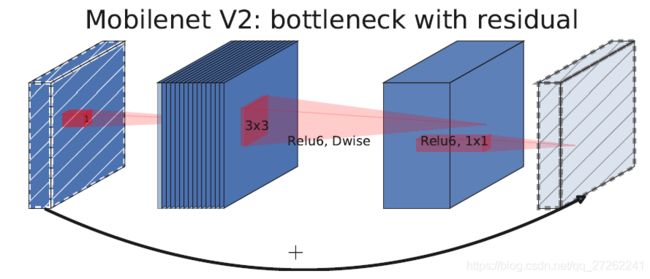
图中先用点卷积扩展通道,再做深度分离卷积,最后进行点卷积。
3 翻转残差结构
即用一条短连接,把算子的输入和输出相加。

残差块和翻转残差块的区别:残差块是的内部是压缩输入的通道,而翻转残差块的内部是扩张输入通道数。
残差结构的优势:残差结构能够保证在深度的情况下,神经网络能学习到更优的参数。
加入瓶颈网络和翻转残差后的计算量,即对输入数据 I w ∗ h ∗ c i n I_{w*h*c_{in}} Iw∗h∗cin 做【一次点卷积,一次深度分离卷积,再一次点卷积,最后做残差相加】,相当于把初始卷积分割成了三个部分
A ( k ∗ k ∗ c i n ) ∗ c o u t = D 1 ∗ 1 ∗ c i n ∗ c e ∙ B k ∗ k ∗ c e ∙ C 1 ∗ 1 ∗ c e ∗ c o u t A_{(k*k*c_{in}) *c_{out}}=D_{1*1*c_{in}*c_{e}} \bullet B_{k*k*c_e} \bullet C_{1*1*c_e*c_{out}} A(k∗k∗cin)∗cout=D1∗1∗cin∗ce∙Bk∗k∗ce∙C1∗1∗ce∗cout
一个翻转残差瓶颈块的计算内容为:
I w ∗ h ∗ c i n + I w ∗ h ∗ c i n ⊗ p D ⊗ d B ⊗ p C = O w ∗ h ∗ c o u t I_{w*h*c_{in}}+I_{w*h*c_{in}}\otimes_{p}D \otimes_{d} B \otimes_{p} C =O_{w*h*c_{out}} Iw∗h∗cin+Iw∗h∗cin⊗pD⊗dB⊗pC=Ow∗h∗cout
经过这样处理后,每层卷积操作的计算量变成了分解后两次卷积的计算量之和
w ∗ h ∗ c i n + w ∗ h ∗ 1 ∗ 1 ∗ c i n ∗ c e + w ∗ h ∗ k ∗ k ∗ c e + w ∗ h ∗ 1 ∗ 1 ∗ c e ∗ c o u t = w ∗ h ∗ ( c i n + c i n ∗ c e + k 2 ∗ c e + c e ∗ c o u t ) w*h*c_{in}+w*h*1*1*c_{in}*c_e+w*h*k*k*c_{e}+ w*h*1*1*c_e*c_{out}\\ = w*h*(c_{in}+c_{in}*c_e+k^2*c_e+c_e*c_{out}) w∗h∗cin+w∗h∗1∗1∗cin∗ce+w∗h∗k∗k∗ce+w∗h∗1∗1∗ce∗cout=w∗h∗(cin+cin∗ce+k2∗ce+ce∗cout)
对比V1和V2:
- V2中引入1*1升维,去掉了ReLU,替换为Linear。
- 步长为1时,先
1*1升维再,Dw提取特征最后,1*1降维,把输入和输出相加形成残差网络 - 步长=2,因为输入和输出维度不相等,所以不做残差。
4 激活函数
对于训练中发现深度卷积核中出现很多空值的问题,采用替换激活函数。
This is useful in making the networks ready for fixed-point inference. If you unbound the upper limit, you lose too many bits to the Q part of a Q.f number. Keeping the ReLUs bounded by 6 will let them take a max of 3 bits (upto 8) leaving 4/5 bits for .f

因此替换传统的 ReLu激活函数为ReLu6,当输入的值大于6的时候,返回6,relu6“具有一个边界”。作者认为ReLU6作为非线性激活函数,在低精度计算下具有更强的鲁棒性。(这里所说的“低精度”,是指的定点运算(fixed-point arithmetic))。

阶段3:MobileNetV3
1. V3 在结构上的调整
- 基于NAS和NetAdapt的强化学习方法自动优化调整网络结构
- 引入基于squeeze and excitation结构的轻量级注意力模型(SE)
- 引入MobileNetV1的深度可分离卷积
- 引入MobileNetV2的具有线性瓶颈的倒残差结构
- 使用了一种新的激活函数h-swish(x)

2. Squeeze Excitation结构

针对一个普通的卷积层,如图中的C2层,进行三个操作的改进:
挤出(Squeeze):
✍操作:把每个通道 C i C_{i} Ci的 ( h ∗ w ) (h*w) (h∗w)个数据变成一个数,最终 h ∗ w ∗ c h*w*c h∗w∗c 转换成 1 ∗ 1 ∗ c 1*1*c 1∗1∗c。[注释] 变成指global pooling操作。
目的:让挤出的 1 ∗ 1 ∗ c 1*1*c 1∗1∗c的每个元素具有整个通道 h ∗ w h*w h∗w的全局视野。解决了【传统卷积核只能具有局部视野】的问题,实现了【全局视野】的目的。
激励(Excitation):
✍操作:是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
目的:为了让不同的通道按照 特定的权重进行组合【加权】
缩放(scale)
✍操作:把通道与这个通道经过 挤出激励(SE)的权重进行重缩放。
目的:合并权重和原始数值。(疑问:挤出的全局视野参数 和 训练的激励权重之间会不会相互抵消,而使这个操作没有了意义了,如果意义不大,就可以去掉了)
SE模块的优势
通过【对整个通道挤出一个参数】的方式,实现【全局视野】的目的。
通过【训练各通道之间的权重参数(激励权重)】的方式,实现【构建通道之间的关系】的目的。
3. 基于强化学习的platform-aware NAS
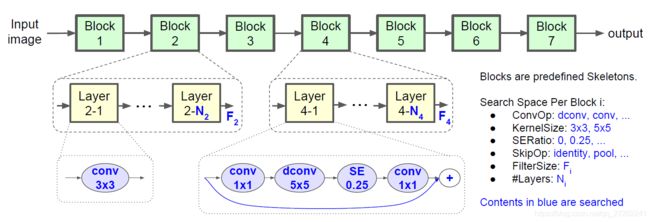
搜索空间
首先定义搜索空间和迭代方法,Mnas定义了一种模型的架构是由多个连续的模块组成,每个模块中可以包括多个相同的层结构,每层可由以下变量组成
卷积操作 = [Conv | Dcov|Pcov]
卷积核大小 = [1|3|5]
SE模块因子 = [0|0.25|...]
缩放操作 =[不缩放|池化]
层数 = [1|2|3...]
自变量空间是一个离散的空间,且不可求导,所以只能在自变量周围采样。
迭代循环
按照 采样-评估-更新的优化循环:
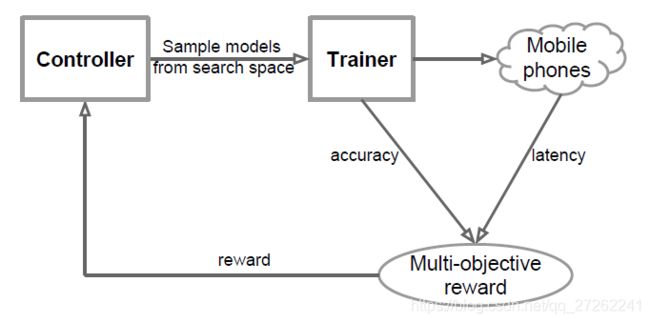
采样
首先基于当前的网络结构,控制器(Controller)会在搜索空间中进行采样,生成一些新的网络结构。对每一个新的网络结构进行训练,获得一个模型。
评估
计算模型的精度,并在对应的部署平台上计算模型的运行时间(因为模型考虑实际运行时的硬件情况)。
计算得分
S = A C C ( m ) ∗ [ L A T ( m ) T ] w S=ACC(m)*[\frac{LAT(m)}{T}]^w S=ACC(m)∗[TLAT(m)]w
更新
根据采样的得分和上一轮结果的得分,选择得分最高的模型,做为下一轮的初始模型。
4. NetAdapt对层内优化
NetAdapt是对NAS的一种补充,相比NAS在全局结构上进行优化,NetAdapt则在每一个层内部进行选择。
主要是由于资源受限的硬件上无法运行负责的模型,所以需要对每层的输出特征进行简化。

NetAdapt设定一个优化目标,比如时间。然后每次迭代都会尝试去减小或者删除一个卷积输出通道数。会逐层进行优化,它以NAS优化得到的结构作为输入,在每个迭代循环内:
- 对当前网络做出不同的修改以生成全新的网络,所谓修改指的是对每层的卷积核的输出通道数进行调整。
- 训练
- 然后在对应的平台上进行测试,选择结果最好的作为下一次迭代的初始网络。
5. 全局均值池化来降维

通过全局均值池化,实现在最后一个模块快速降维,从而避免了最后一模块的计算量太大的问题。
可优化的原因:仅仅是为了精简测试
结果:精度不变的情况下,速度提升非常明显。
6. 采用H-swish作为非线性激活函数
激活函数的目的是为了 **加入非线性因素,提高模型的表达能力。**在实验数据的验证下,V3采用swish作为激活函数,Swish 具备无上界有下界、平滑、非单调的特性。
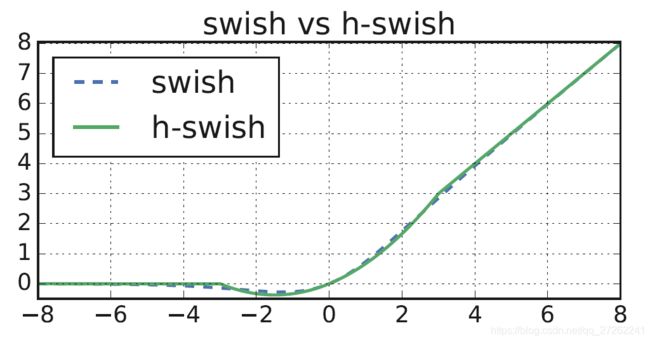
使用swish函数时,能明显网络的精度,但是由于 s w i s h ( x ) = x σ ( x ) swish(x)=x\sigma(x) swish(x)=xσ(x)需要计算指数,为了简化Sigmod的指数部分,采用ReLu对其进行近似就得到了hard-swish
s w i s h ( x ) = x σ ( x ) swish(x)=x\sigma(x) swish(x)=xσ(x)
h s w i s h ( x ) = x R e L U 6 ( x + 3 ) 6 hswish(x)= x\frac{ReLU6(x+3)}{6} hswish(x)=x6ReLU6(x+3)
其 中 σ ( z ) = 1 1 + e − z (sigmoid) 其中\sigma(z) ={1\over 1+e^{-z}} \text{(sigmoid)} 其中σ(z)=1+e−z1(sigmoid)
有效的降低了计算量。