【机器学习】特征工程概述
特征工程
“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。”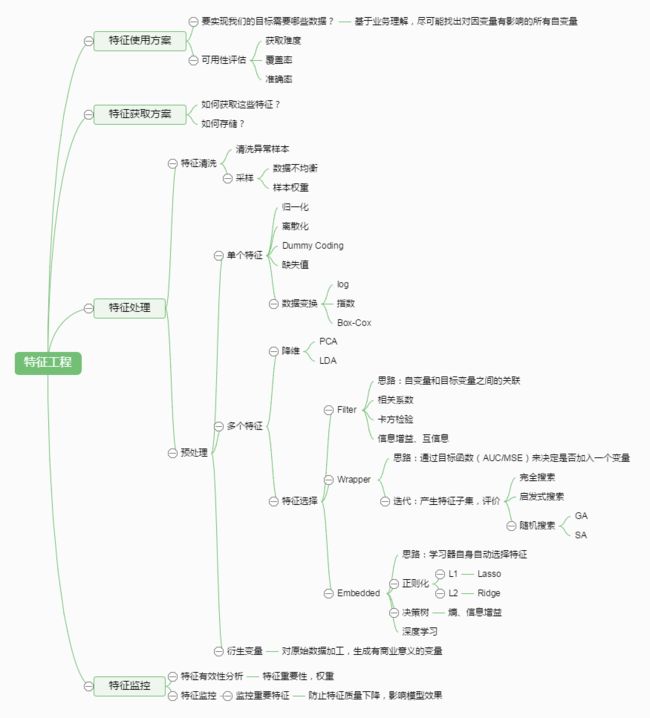
1.概念
维基百科:特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
通俗的说,就是尽可能的从原始数据中获取更多信息,从而使得预测模型达到最佳。
简而言之,特征工程是一个把原始数据变成特征的过程,这些特征可以很好的描述数据,并且利用它们建立的模型在未知数据上表现性能可以达到最优。
2.重要性
实验结果取决于获取的数据、使用的特征以及选择的模型,甚至问题的形式和评估精度的客观方法也扮演了一部分。我们需要的是能够很好地描述数据内部结构的好特征。
(1) 特征越好,灵活性越强
只要特征选得好,即使是一般的模型(或算法)也能获得很好的性能,因为大多数模型(或算法)在好的数据特征下表现的性能都还不错。好特征的灵活性在于它允许你选择不复杂的模型,同时运行速度也更快,也更容易理解和维护。
(2) 特征越好,构建的模型越简单
有了好的特征,即便你的参数不是最优的,你的模型性能也能仍然会表现的很nice,所以你就不需要花太多的时间去寻找最有参数,这大大的降低了模型的复杂度,使模型趋于简单。
(3) 特征越好,模型的性能越出色
特征工程的最终目的就是提升模型的性能。
3.子问题
3.1 特征构建
特征构建指的是从原始数据中人工的构建新的特征。这需要我们花大量的时间去研究真实的数据样本,思考问题的潜在形式和数据结构,同时能够更好地应用到预测模型中。人工的创建特征。
特征构建需要很强的洞察力和分析能力,要求我们能够从原始数据中找出一些具有物理意义的特征。假设原始数据是表格数据,一般你可以使用混合属性或者组合属性来创建新的特征,或是分解或切分原有的特征来创建新的特征。
3.2 特征提取
特征提取的对象是原始数据,目的是自动地构建新的特征,将原始特征转换为一组具有明显物理意义(Gabor、几何特征[角点、不变量]、纹理[LBP HOG])或者统计意义或核的特征。比如通过变换特征取值来减少原始数据中某个特征的取值个数等。对于表格数据,你可以在你设计的特征矩阵上使用主要成分分析(Principal Component Analysis,PCA)来进行特征提取从而创建新的特征。对于图像数据,可能还包括了线或边缘检测。 常用的方法有:
- PCA (Principal component analysis,主成分分析)
- ICA (Independent component analysis,独立成分分析)
- LDA (Linear Discriminant Analysis,线性判别分析)
- 图像识别中,还有SIFT方法
3.3 特征选择
数据特征中,有的特征携带的信息量丰富,有的(或许很少)则属于无关数据(irrelevant data),我们可以通过特征项和类别项之间的相关性(特征重要性)来衡量。
在实际应用中,常用的方法就是使用一些评价指标单独地计算出单个特征跟类别变量之间的关系。如,Pearson相关系数,Gini-index(基尼指数),IG(信息增益)等,下面举Pearson指数为例,它的计算方式如下:Pearson相关系数,Gini-index(基尼指数),IG(信息增益)等,下面举Pearson指数为例,它的计算方式如下:
r2xy=(con(x,y)var(x)var(y)−−−−−−−−−−√)rxy2=(con(x,y)var(x)var(y))
其中,x属于X,X表一个特征的多个观测值,y表示这个特征观测值对应的类别列表。Pearson指数取值0到1之间。
通过上述公式计算各特征与类别之间的相关性,并对这些相关性由高到低排名,然后选择排名高的子集作为特征(比如前10%),用这些特征进行训练,验证效果。此外,你还可以画出不同子集的一个精度图,根据绘制的图形来找出性能最好的一组特征。
通过例子,总结出特征选择的目的,就是从特征集合中挑选一组最具统计意义的特征子集,从而达到降维的效果。做特征选择的原因是,因为这些特征对于目标类别的作用并不是相等的,一些无关的数据需要删掉。
做特征选择的方法有多种,上面提到的选特征子集的方法属于filter(刷选器)方法,它主要侧重于单个特征跟目标变量的相关性。优点是计算时间上较高效,对于过拟合问题也具有较高的鲁棒性。缺点就是倾向于选择冗余的特征,因为他们不考虑特征之间的相关性,有可能某一个特征的分类能力很差,但是它和某些其它特征组合起来会得到不错的效果。
另外做特征子集选取的方法还有wrapper(封装器)和Embeded(集成方法)。wrapper方法实质上是一个分类器,封装器用选取的特征子集对样本集进行分类,分类的精度作为衡量特征子集好坏的标准,经过比较选出最好的特征子集。常用的有逐步回归(Stepwise regression)、向前选择(Forward selection)和向后选择(Backward selection)。它的优点是考虑了特征与特征之间的关联性,缺点是:当观测数据较少时容易过拟合,而当特征数量较多时,计算时间又会增长。对于Embeded集成方法,它是学习器自身自主选择特征,如使用Regularization做特征选择,或者使用决策树思想,细节这里就不做介绍了。这里还提一下,在做实验的时候,我们有时候会用Random Forest和Gradient boosting做特征选择,本质上都是基于决策树来做的特征选择,只是细节上有些区别。
综上所述,特征选择过程一般包括产生过程,评价函数,停止准则,验证过程,这4个部分。如下图所示: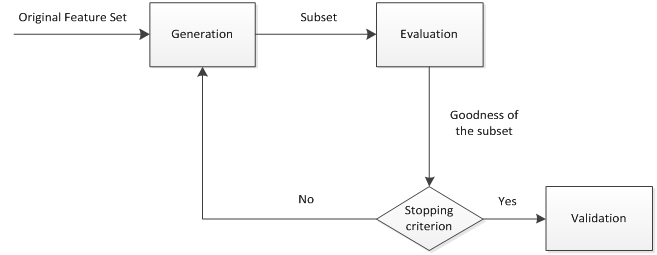
- (1) 产生过程( Generation Procedure ):产生过程是搜索特征子集的过程,负责为评价函数提供特征子集。
- (2) 评价函数( Evaluation Function ):评价函数是评价一个特征子集好坏程度的一个准则。
- (3) 停止准则( Stopping Criterion ):停止准则是与评价函数相关的,一般是一个阈值,当评价函数值达到这个阈值后就可停止搜索。
- (4) 验证过程( Validation Procedure ) :在测试数据集上验证选出来的特征子集的有效性。
4.处理过程
特征工程具体是在哪个步骤做呢?具体的机器学习过程是这样的一个过程:
- (Task before here)
- 1) 选择数据(select data):整合数据,将数据规范化成一个数据集,收集起来
- 2) 数据预处理(preprocess data):数据格式化,数据清理、采样等
- 3) 数据转换(transform data):这个阶段做特征工程
- 4) 数据建模(model data):建立模型,评估模型并逐步优化
-
(task after here)
我们发现,特征工程和数据转换其实是等价的。事实上,特征工程是一个迭代过程,我们需要不断的设计特征、选择特征、建立模型、评估模型,然后才能得到最终的model。下面是特征工程的一个迭代过程:
- 1.头脑风暴式特征:意思就是进你可能的从原始数据中提取特征,暂时不考虑其重要性,对应于特征构建;
- 2.设计特征:根据你的问题,你可以使用自动地特征提取,或者是手工构造特征,或者两者混合使用;
- 3.选择特征:使用不同的特征重要性评分和特征选择方法进行特征选择;
- 4.评估模型:使用你选择的特征进行建模,同时使用未知的数据来评估你的模型精度。
下面举个例子来简单了解下特征工程的处理。
首先是来说下特征提取,假设你的数据里现在有一个颜色类别的属性,比如是“item_Color”,它的取值有三个,分别是:red,blue,unknown。从特征提取的角度来看,你可以将其转化成一个二值特征“has_color”,取值为1或0。其中1表示有颜色,0表示没颜色。你还可以将其转换成三个二值属性:Is_Red, Is_Blue and Is_Unknown。这样构建特征之后,你就可以使用简单的线性模型进行训练了。
另外再举一个例子,假设你有一个日期时间 (i.e. 2014-09-20T20:45:40Z),这个该如何转换呢?
对于这种时间的数据,我们可以根据需求提取出多种属性。比如,如果你想知道某一天的时间段跟其它属性的关系,你可以创建一个数字特征“Hour_Of_Day”来帮你建立一个回归模型,或者你可以建立一个序数特征,“Part_Of_Day”,取值“Morning,Midday,Afternoon,Night”来关联你的数据。
此外,你还可以按星期或季度来构建属性,等等等等……
关于特征构建,主要是尽可能的从原始数据中构建特征,而特征选择,经过上面的分析,想必大家也知道了,其实就是达到一个降维的效果。
只要分析能力和实践能力够强,那么特征构建和特征提取对你而言就会显得相对比较简单,所以抓紧时间好好实践吧!
5.总结
下面来简单的做个总结,首先来说说这几个术语:
- 特征工程:利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
- 特征构建:是原始数据中人工的构建新的特征。
- 特征提取:自动地构建新的特征,将原始特征转换为一组具有明显物理意义或者统计意义或核的特征。
- 特征选择:从特征集合中挑选一组最具统计意义的特征子集,从而达到降维的效果
特征工程是一个超集,它包括特征提取、特征构建和特征选择这三个子模块。在实践当中,每一个子模块都非常重要,忽略不得。根据答主的经验,他将这三个子模块的重要性进行了一个排名,即:特征构建>特征提取>特征选择。
事实上,真的是这样,如果特征构建做的不好,那么它会直接影响特征提取,进而影响了特征选择,最终影响模型的性能。
参考:机器学习之特征工程
相关阅读:
使用sklearn做单机特征工程
七种常用特征工程
--------------------- 本文来自 evillist 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/evillist/article/details/73245431?utm_source=copy