Pytorch 并行训练(DP, DDP)的原理和应用
Pytorch 并行训练(DP, DDP)的原理和应用
1. 前言
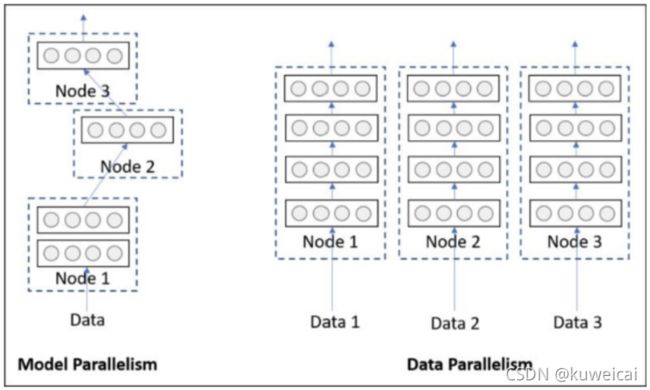
并行训练可以分为数据并行和模型并行。
-
模型并行
模型并行主要应用于模型相比显存来说更大,一块 device 无法加载的场景,通过把模型切割为几个部分,分别加载到不同的 device 上。比如早期的 AlexNet,当时限于显卡,模型就是分别加载在两块显卡上的。
-
数据并行
这个是日常会应用的比较多的情况。每一个 device 上会加载一份模型,然后把数据分发到每个 device 并行进行计算,加快训练速度。
如果要再细分,又可以分为单机多卡,多机多卡。这里主要讨论数据并行的单机多卡的情况。
2. Pytorch 并行训练
常用的 API 有两个:
- torch.nn.DataParallel(DP)
- torch.nn.DistributedDataParallel(DDP)
DP 相比 DDP 使用起来更友好(代码少),但是 DDP 支持多机多卡,训练速度更快,而且负载相对要均衡一些。所以优先选用 DDP 吧。
2.1 训练模型的过程
在开始怎么调用并行的接口之前,了解并行的过程是有必要的。首先来看下模型训练的过程。
2.2 DP
2.2.1 DP 的计算过程
DP 并行的具体过程可以参考下图两幅图。
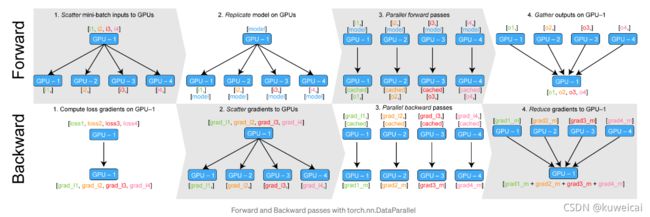
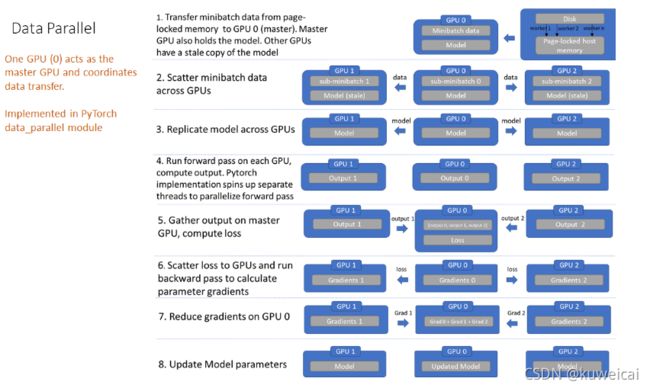
上图清晰的表达了 torch.nn.DataParallel 的计算过程。
- 将 inputs 从主 GPU 分发到所有 GPU 上
- 将 model 从主 GPU 分发到所有 GPU 上
- 每个 GPU 分别独立进行前向传播,得到 outputs
- 将每个 GPU 的 outputs 发回主 GPU
- 在主 GPU 上,通过 loss function 计算出 loss,对 loss function 求导,求出损失梯度
- 计算得到的梯度分发到所有 GPU 上
- 反向传播计算参数梯度
- 将所有梯度回传到主 GPU,通过梯度更新模型权重
- 不断重复上面的过程
2.2.2 应用
API 如下。
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
使用非常简单。一句代码就搞定。
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
2.3 DDP
2.3.1 DDP 的过程
大体上的过程和 DP 类似,具体可以参考下图。
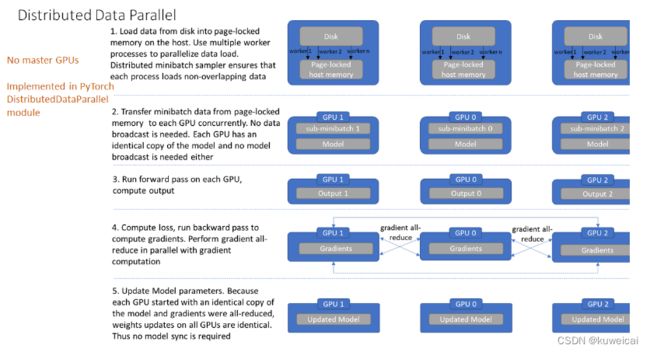
与 DataParallel 的单进程控制多 GPU 不同,在 distributed 的帮助下,我们只需要编写一份代码,torch 就会自动将其分配给n个进程,分别在 n 个 GPU 上运行。不再有主 GPU,每个 GPU 执行相同的任务。对每个 GPU 的训练都是在自己的进程中进行的。每个进程都从磁盘加载其自己的数据。分布式数据采样器可确保加载的数据在各个进程之间不重叠。损失函数的前向传播和计算在每个 GPU 上独立执行。因此,不需要收集网络输出。在反向传播期间,梯度下降在所有GPU上均被执行,从而确保每个 GPU 在反向传播结束时最终得到平均梯度的相同副本。
2.3.2 应用
开始之前需要先熟悉几个概念。
-
group
即进程组。默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。
当需要进行更加精细的通信时,可以通过 new_group 接口,使用 world 的子集,创建新组,用于集体通信等。
-
world size
表示全局进程个数。如果是多机多卡就表示机器数量,如果是单机多卡就表示 GPU 数量。
-
rank
表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。 如果是多机多卡就表示对应第几台机器,如果是单机多卡,由于一个进程内就只有一个 GPU,所以 rank 也就表示第几块 GPU。
-
local_rank
表示进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。例如,多机多卡中 rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
DDP 的应用流程如下:
- 在使用
distributed包的任何其他函数之前,需要使用init_process_group初始化进程组,同时初始化distributed包。 - 如果需要进行小组内集体通信,用
new_group创建子分组 - 创建分布式并行(
DistributedDataParallel)模型DDP(model, device_ids=device_ids) - 为数据集创建
Sampler - 使用启动工具
torch.distributed.launch在每个主机上执行一次脚本,开始训练 - 使用
destory_process_group()销毁进程组
1. 添加参数 --local_rank
# 每个进程分配一个 local_rank 参数,表示当前进程在当前主机上的编号。例如:rank=2, local_rank=0 表示第 3 个节点上的第 1 个进程。
# 这个参数是torch.distributed.launch传递过来的,我们设置位置参数来接受,local_rank代表当前程序进程使用的GPU标号
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
print(args.local_rank))
2.初始化使用nccl后端
dist.init_process_group(backend='nccl')
# When using a single GPU per process and per
# DistributedDataParallel, we need to divide the batch size
# ourselves based on the total number of GPUs we have
device_ids=[1,3]
ngpus_per_node=len(device_ids)
args.batch_size = int(args.batch_size / ngpus_per_node)
#ps 检查nccl是否可用
#torch.distributed.is_nccl_available ()
3.使用DistributedSampler
#别忘了设置pin_memory=true
#使用 DistributedSampler 对数据集进行划分。它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练
train_dataset = MyDataset(train_filelist, train_labellist, args.sentence_max_size, embedding, word2id)
train_sampler = t.utils.data.distributed.DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset,
pin_memory=true,
shuffle=(train_sampler is None),
batch_size=args.batch_size,
num_workers=args.workers,
sampler=train_sampler )
#DataLoader:num_workers这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程
#注意 testset不用sampler
4.分布式训练
#使用 DistributedDataParallel 包装模型,它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。
#all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值. 注意find_unused_parameters参数!
net = textCNN(args,vectors=t.FloatTensor(wvmodel.vectors))
if args.cuda:
# net.cuda(device_ids[0])
net.cuda()
if len(device_ids)>1:
net=torch.nn.parallel.DistributedDataParallel(net,find_unused_parameters=True)
5.最后,把数据和模型加载到当前进程使用的 GPU 中,正常进行正反向传播:
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
output = net(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
6.在使用时,命令行调用 torch.distributed.launch 启动器启动:
#pytorch 为我们提供了 torch.distributed.launch 启动器,用于在命令行分布式地执行 python 文件。
#--nproc_per_node参数指定为当前主机创建的进程数。一般设定为=NUM_GPUS_YOU_HAVE当前主机的 GPU 数量,每个进程独立执行训练脚本。
#这里是单机多卡,所以node=1,就是一台主机,一台主机上--nproc_per_node个进程
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
可以参考如下代码:
- DDP1
- [DDP2](
3. DP 与 DDP 的区别
3.1 DP 的优势
如果有的话就是简单,一行代码搞定。
3.2 DDP 的优势
1. 每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。
DDP 在每次迭代中,每个进程具有自己的 optimizer ,并独立完成所有的优化步骤,进程内与一般的训练无异。在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程。之后,各进程用该梯度来独立的更新参数。而 DP是梯度汇总到主 GPU,反向传播更新参数,再广播参数给其他的 GPU。
DDP 中由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
而在**DP** 中,全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU。
相较于**DP,DDP**传输的数据量更少,因此速度更快,效率更高。
2. 每个进程包含独立的解释器和 GIL。
一般使用的 Python 解释器 CPython:是用 C 语言实现 Pyhon,是目前应用最广泛的解释器。全局锁使 Python 在多线程效能上表现不佳,全局解释器锁(Global Interpreter Lock)是 Python 用于同步线程的工具,使得任何时刻仅有一个线程在执行。
由于每个进程拥有独立的解释器和 GIL,消除了来自单个 Python 进程中的多个执行线程,模型副本或 GPU 的额外解释器开销和 GIL-thrashing ,因此可以减少解释器和 GIL 使用冲突。这对于严重依赖 Python runtime 的 models 而言,比如说包含 RNN 层或大量小组件的 models 而言,这尤为重要。
参考
-
Pytorch模型并行
-
Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups