CNN (吴恩达 2021
week1-2
02_边缘检测例子_哔哩哔哩_bilibili
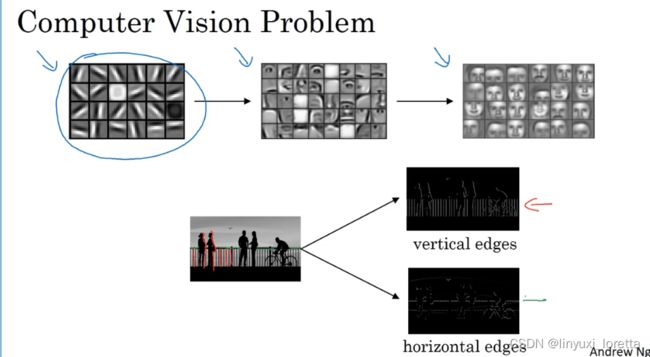
我们之前在说面部识别介绍过,要识别面部,都是从细微的边缘入手,一层一层聚类,最终实现人脸的识别。神经网络由浅层到深层,分别可以检测出图片的边缘特征 、局部特征(例如眼睛、鼻子等)、整体面部轮廓。
我们就以边缘检测为例子,介绍卷积运算。
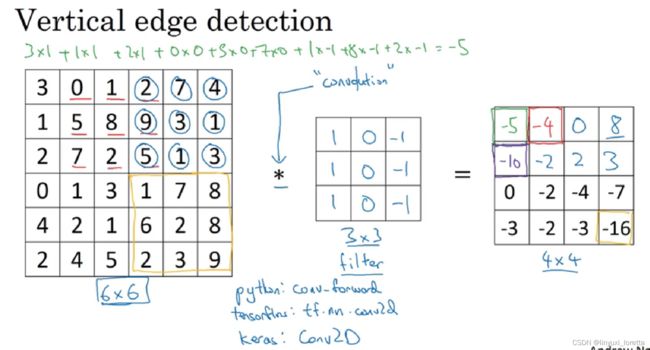

一个垂直边缘是一个3x3的区域, 左边有亮像素,中间无所谓,右边是暗像素
图片边缘有两种渐变方式,一种是由明变暗,另一种是由暗变明。以垂直边缘检测为例,下图展示了两种方式的区别。实际应用中,这两种渐变方式并不影响边缘检测结果,可以对输出图片取绝对值操作,得到同样的结果。
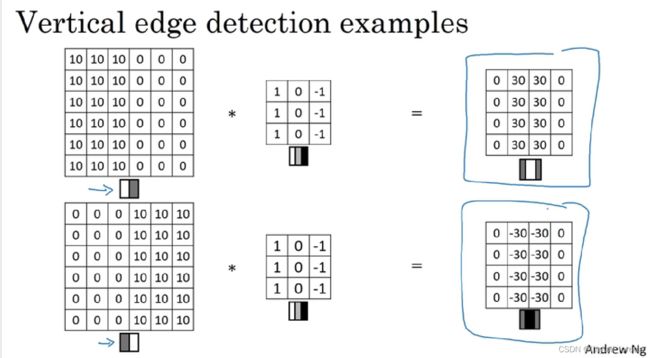
positive edge v.s. negative edge
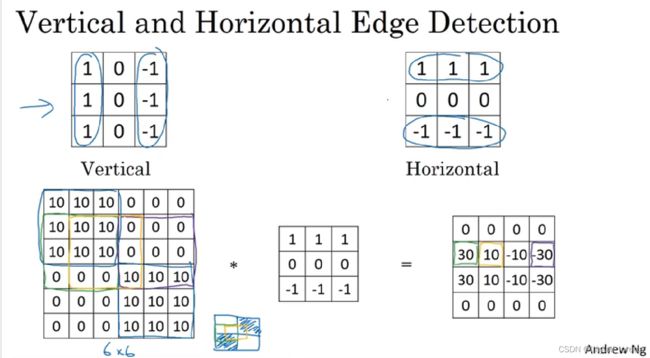
除了上面提到的这种简单的Vertical、Horizontal滤波器之外,还有其它常用的filters,
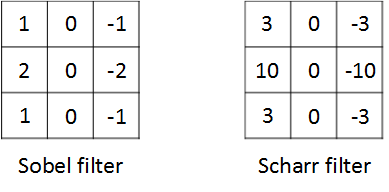
sobel过滤器,它增加了中间一行的权重,使得结果的鲁棒性更强。还可以将权重再提高一些,scharr过滤器:
在深度学习中,如果我们想检测图片的各种边缘特征,而不仅限于垂直边缘和水平边缘,那么filter的数值一般需要通过模型训练得到,类似于标准神经网络中的权重W一样由梯度下降算法反复迭代求得。CNN的主要目的就是计算出这些filter的数值。确定得到了这些filter后,CNN浅层网络也就实现了对图片所有边缘特征的检测。
padding
两个问题:
-
卷积运算后,输出图片尺寸缩小
-
原始图片边缘信息对输出贡献得少,输出图片丢失边缘信息
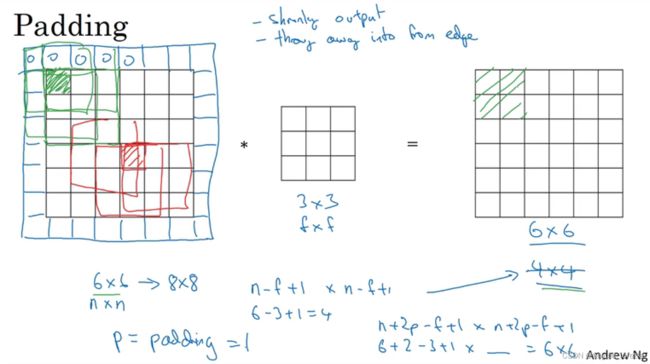

根据是否进行填充,卷积方法可以分为两种,一种是valid convolution(不进行填充),另一种是same convolution(也就是保证图片在卷积前后的维度相同)。在后一种卷积方式中,为了保证卷积前后的维度不变,p值应该等于(f-1)/2,(filter尺寸为f x f,注意f一般为奇数,若为偶数,则会产生不对称填充。)
(另外一个原因,奇数维度的过滤器有一个中心点,便于指出过滤器的位置,会很方便。)
(这是计算机视觉的传统)
4、卷积神经网络-步长(strid)
前面的例子,卷积的步长为1,也就是过滤器在原始输入图片中,每一次移动一个方格。我们也可以设置不同的步长进行卷积。
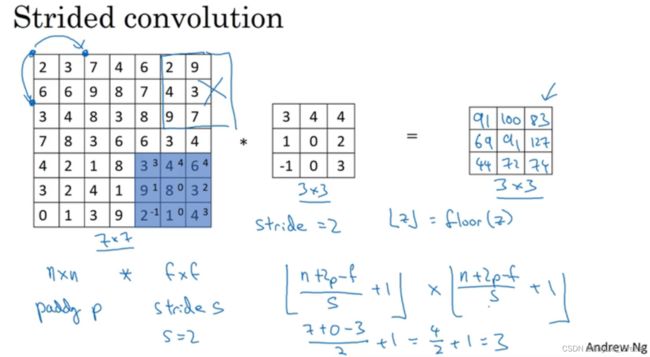
⌊ ⋯ ⌋表示向下取整。若[(n+2p-f)/s + 1] 不为整数,则向下取整,这么处理的实际意义就在于,只有当过滤器完全覆盖了输入图片的像素点时,卷积才是有效的。
卷积和互相关:
在数学定义上,矩阵的卷积(convolution)操作为首先将卷积核同时在水平和垂直方向上进行翻转(沿对角线翻转),构成一个卷积核的镜像,然后使用该镜像再和前面的矩阵进行移动相乘求和操作。如下面例子所示:
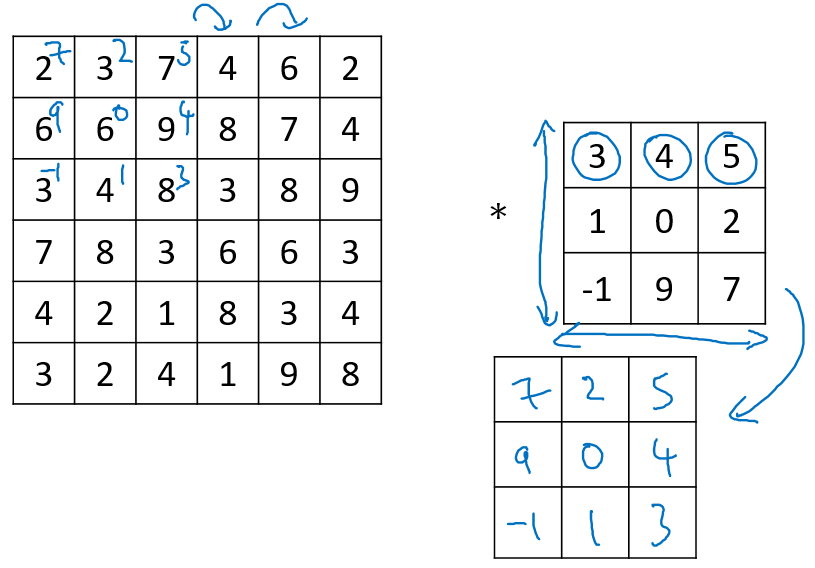
在深度学习中,我们称为的卷积运算实则没有卷积核变换为镜像的这一步操作,因为 对卷积核翻转,会使卷积核保持结合率 A*(B*C)=(A*B)*C,这一性质对deep NN并不重要。深度学习的卷积操作在数学上准确度来说称为互相关(cross-correlation)。
在信号处理或其他数学分支领域 做翻转(flipping)
三维卷积
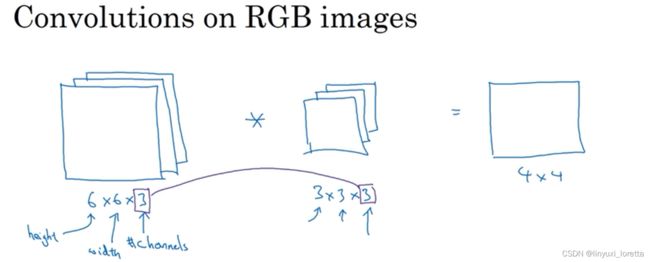
输入图像的通道数量与过滤器的通道数量必须相同,
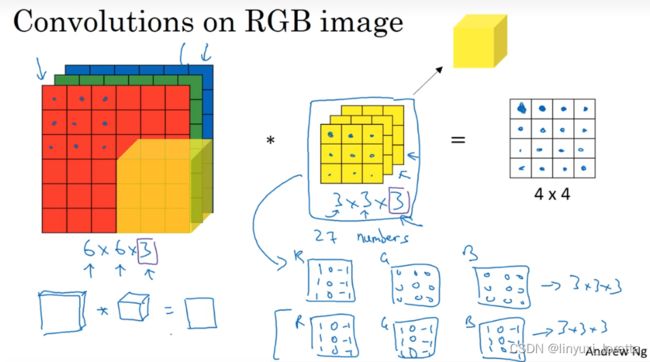
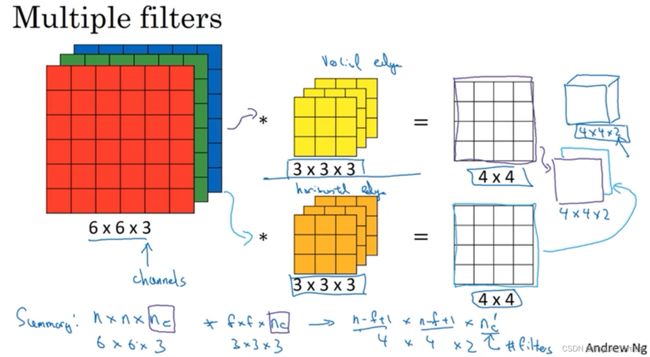
结果的通道数则由过滤器的个数决定,
单层卷积网络
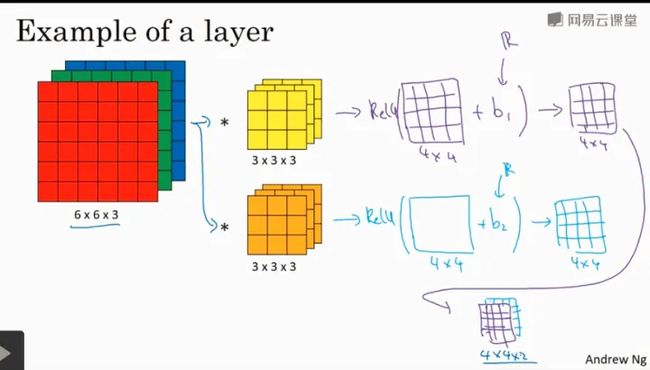
输入的图片经过两个过滤器,得到两个4*4的矩阵,相当于对输入图片的像素点做了线性操作(像素点的值和过滤器的权重进行点乘),然后对于4*4的矩阵的每个元素加上一个bias,再对结果进行非线性变化(Relu),经过堆叠之后,得到最终的4*4*2的结果。
整个过程与标准的神经网络单层结构非常类似:
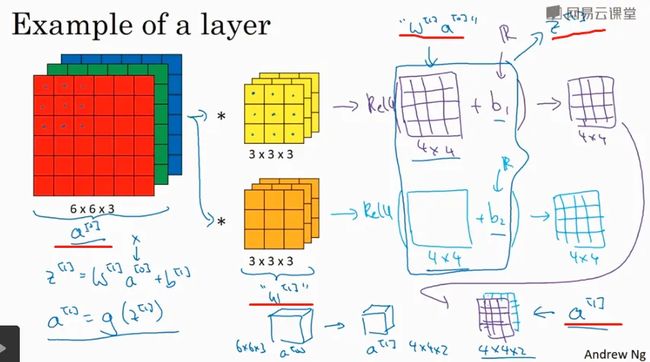
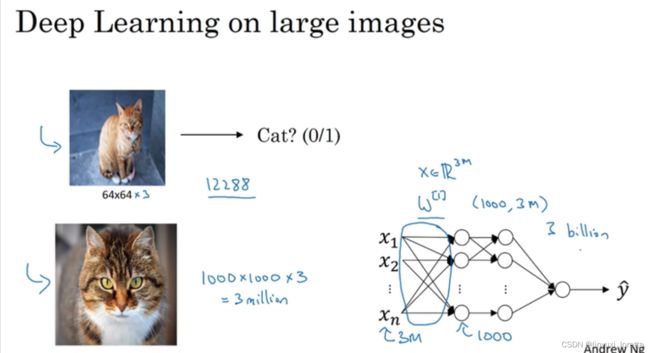
我们发现,选定滤波器组后,参数数目与输入图片尺寸无关。所以,就不存在由于图片尺寸过大,造成参数过多的情况。
 activations:激活值的维度也就是本层神经网络输出的图片的维度
activations:激活值的维度也就是本层神经网络输出的图片的维度
A[i]:如果应用的是向量化实现vectorized implementation,或批量梯度下降
batch gradient descent进行训练的话,每次训练的样本有m个,则激活值要乘上m。
简单的深度卷积神经网络
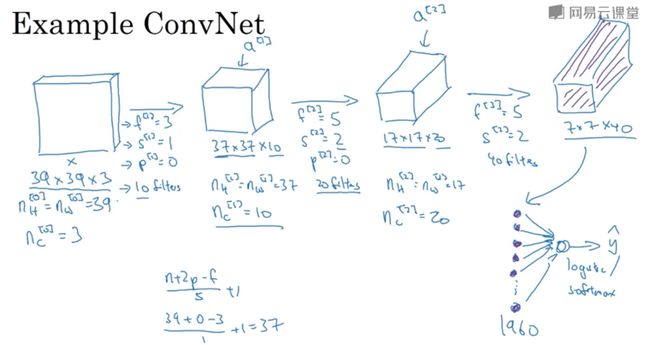
到第三层,你把39x39x3的输入图像,计算出此图像的7x7x40 features
hyperparameter:filters size?stride?padding?filters数量?
多层卷积神经网络的趋势就是,随着层数的加深,图片的长和宽会减小,而channel数目会不断增加。
CNN通常有三种类型的layer:
-
Convolution层(CONV),CONV最为常见也最重要,
-
Pooling层(POOL)
-
Fully connected层(FC)
pooling
09_池化层_哔哩哔哩_bilibili
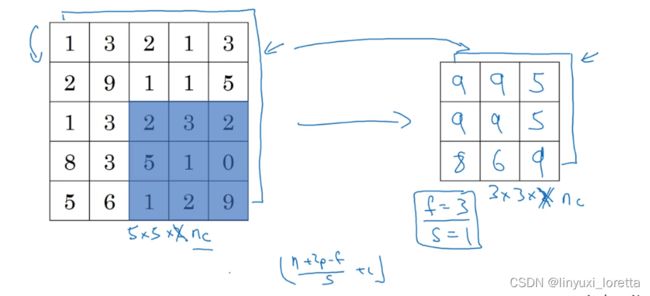
max pooling所做的其实是,如果在filter中任何地方检测到了这些特征、就保留最大的数值;但是 如果这个特征没有被检测到、于是 那些数值的最大值仍然相当小,这就是max pooling在卷积网络中效果很好的根本原因。

若输入的信道数量大于1,那么对每一层的输入分别做相同的操作即可,输出的结果具有相同的信道数。
average pooling(平均池化):没有很常用
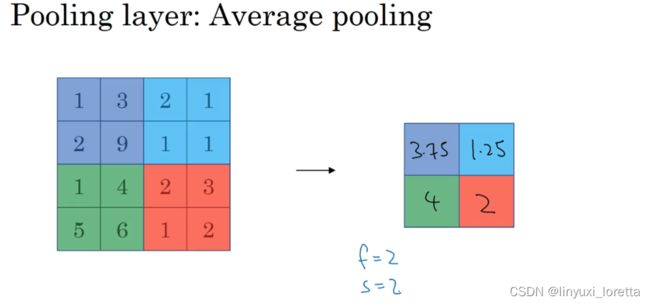
目前,使用 max pooling 通常比average pooling 多得多,唯一的例外,是有时候在深度非常大的神经网络,你也许可以使用均值采样来合并your representation from see 7x7x1000 ,将它们整体取一个均值,得到1x1x1000

池化的过程中,没有需要学习的参数,只需要定义过滤器的大小以及步长即可。
这里只有这些超参需要你设定一次,或许是人工设定或者使用交叉检验across validation
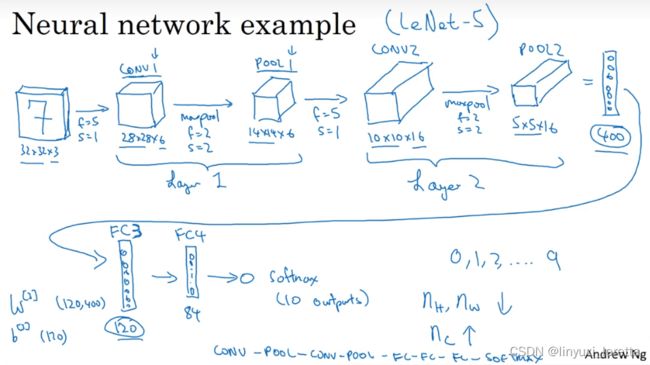
经典的卷积神经网络(conv+pooling+full connection)
经典的神经网络中,将pooling和卷积层结合在一个,一般来说都是一层卷积配上一层pooling,由于pooling部分没有需要训练的参数,因此通常将一层conv和一层pooling合并作为神经网络中的一层。
卷积神经网络的最后一部分就是全连接层,如下图:
LeNet-5多年前由Yann LeCun创建,其中许多参数的选择是受到它启发的
神经网络中当人们说到网络层数的时候,通常指那些有权重,有参数的网络层数量
这其中似乎有许多超参数、稍后我们将会给出一些更具体的建议、也许一个常用的法则实际上是、不要试着创造你自己的超参数组、而是查看文献,看看其他人使用的超参数、从中选一组适用于其他人的超参数、很可能它也适用于你的应用
比较常见的卷积神经网络是一个或者多个卷积层之后,接上一个pooling层,然后是几个全连接层,最后是softmax层。上图网络各层的参数数量以及激活值数量如下表所示。

如表,pooling层是没有参数的,卷积层的参数较少,而全连接层的参数是相对较多的。而激活值activation size数量是在逐渐减少的,但如果激活值较少速度太快的话,通常也不利于网络性能。
你会发现许多CNN有着与此相似的特性和模式
为什么使用卷积神经网络?
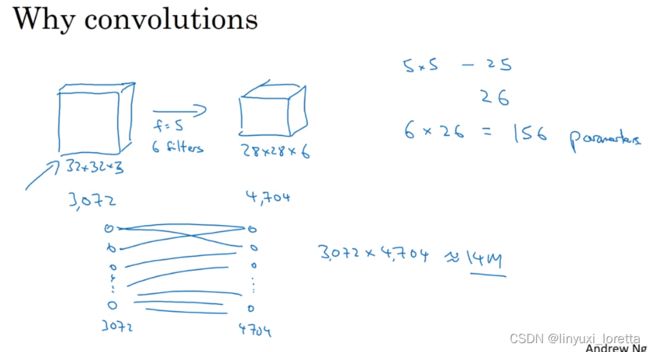
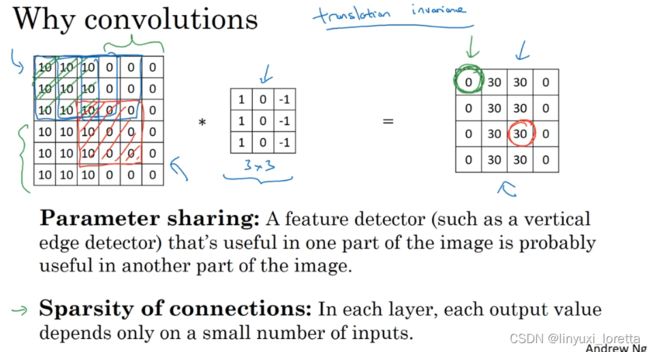
和全连接相比较,全连接的参数数量较多(两层之间的神经元需要两两相连),卷积神经网络的参数较少,主要是由于:
权值共享(同一个过滤器在输入矩阵中进行扫描,可以在input图上用同一组参数提取同一个特征)
稀疏连接(输出矩阵中的每一个数值只由输入数据的一部分计算得来)。
平移不变性
如何训练一个卷积神经网络?
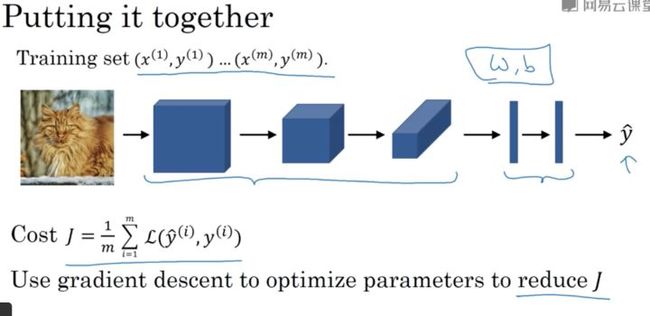
简单来说,就是定义一个损失函数,随机初始化参数w和b,然后用梯度下降法进行参数训练,使得损失函数最小
梯度下降法、梯度下降动量、RMSProp,Adam,或者别的
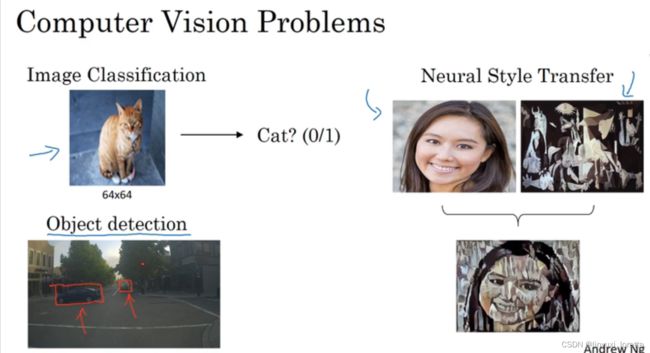
a variety of other computer vision applications such as,
object detection, and neural store transfer.
How they create new forms of artwork using these set of algorithms.
价值连城 图灵奖得主Yann LeCun 杨立昆的采访 给AI从业者的建议_AI架构师易筋的博客-CSDN博客
the perceptron model感知器,大部分的文章是50年代的, 而且到60年代就中断了 找到一本由Seymour Papert一起合著的书 ,1980年
标题是最佳知觉推论 这是第一份玻尔兹曼机的论文,作者是Geoff Hinton 和Terry Sejnowski 它是讨论隐藏单元的 也就是学习的一部分 多层神经网络比仅有的分类器更有效
,我们意识到 整个链式法则Chain Rule的想法或者最佳化控制 optimal control,人们称之为连接状态joint state 实际是反向传播发明的真正主旨 这种最佳化控制的主旨要回到60年代早期 这种观念,使用梯度下降,并且基本上使用在多个层次 是反向传播真正的特点,
,当我在博士后时, 在多伦多大学,跟着Geoffery Hinton
我做的第一项实验表明 如果你有一个非常小的数据集
我比较了全连接网络 没有共用权重的局部连接网络 然后是共享权重的网络 那基本上是ConvNet的雏形 而这对相对小的数据效果很好,可以显示你得到了 最佳的效果,没有在传统架构下有过度训练
他们有巨大的数据集叫做USDS,包含了5000个训练样本
我加入贝尔实验室三个月内发生的 所以这是第一版本的卷积网络 我们的卷积网络有跨步,但我们没有单独的降采样 和池化层 所以每个卷积实际上 很直接 这个的原因是 我们负担不起在每一个区域都做卷积 这包含了太多的计算 所以第二个版本是 有单独的卷积,池化层和降采样
我觉得这个才应该称为LeNet-1
characterization systems.字母识别
CRFs(Conditional Random Field) for interpreting sequences of characters not just individual address.
it's about sort of sequence level, discriminative running判别运算, and basically structure prediction with that normalization.
因特网刚刚开始的时候,也就是1995年
我开始了一个项目,叫DjVu 这个项目主要是想要压缩扫描的文档 这样一来他们就可以传播到全世界的各个地点
卷积网络 从您早期的工作开始, 到现在 几乎覆盖了计算机视觉的所有领域 并且甚至开始去进入其他领域 所以能告诉我你是如何看待整个过程的吗 —
[笑] 我可以告诉你为什么我早先就觉得这些会在未来发生 首先, 我一直相信这是会成功 深度学习这个方向需要快速的计算机 和大量的数据, 并且我一直相信 这会是以后会发生的事情 当我在贝尔实验室的时候, 我想这会是一个 持续进展的过程, 随着计算机越来越强大。 我们在贝尔实验室的时候,甚至自己设计芯片运行卷积神经网络 那时候实际上是在两个不同芯片上运行整个计算图 使得卷积网络更加高效 我当时想这应该会开始流行 而且会逐渐被重视, 然后能持续的发展下去 但是实际上, 因为大家对神经网络的兴趣 在90年代中期几乎中断, 这些并没有发生 这段6,7年的时间, 从大概1995到2002, 是神经网络的低潮期 当时,几乎没人对这个领域进行研究 事实上, 还是有一丢丢进展的 在2000年初, 有些微软的研究人员 用卷积神经网络去做汉字的识别
嗯, 就是这样的 还有些其他的少量工作, 像在法国有用这个技术做人脸识别 还有一些其他地方的,但都是很小的工作 我发现最近有一些团队 提出一些和卷积神经网络很像的想法 但是却没有发表出来, 像一些对医学图像的分析 那些人更多是在商业系统下进行 所以那些人没有把成果公之于众 我的意思是当我们有了第一个卷积神经网络的成果的时候 他们并没有意识到, 所以有一点大家在并行开发 所以这些人在这段时间内都有差不多的想法
但是我非常惊讶于从ImageNet开始 大家兴趣转变的速度之快 那是在2012年, 应该说是2012年底 在ECCV有一个很有趣的事件 在佛罗伦萨,有一个ImageNet的研讨会 大家都知道Geoffrey Hinton, Alex Krizhevsky和Ilya Sutskever大幅度领先 所以大家都在等着这个演讲 计算机视觉领域的绝大部分人完全不知道 卷积神经网络是什么东西 事实上他们听我谈过这个东西 我在2000年的CVPR上被邀请去做一个关于这个的演讲 但是大部分人没有给予很大的关注 资深的人员知道, 但是 这个领域的年轻人就不太知道这是什么了 所以当Alex Krizhevsky做演讲的时候, 他并没有解释什么是卷积网络 因为他认为每个人都知道 因为他从机器学习领域来, 所以当他说这些东西是如何连接 它是如何转换数据, 并且得到了什么结果的时候 它还是觉得每个人都知道这是什么 大量的人都觉得很震惊 并且你能看到当他在做演讲的时候,台下的人观念的转变 特别是资深的研究人员。 —
所以你觉得那场研讨会 对于计算机视觉领域是一个决定的时刻
是的 当然 是的 这就是它如何发生的
现在,你依然在纽约大学做教授 并且带领Facebook的人工智能研究院(FAIR) 我知道你一定对如何让学术研究和工业界合作 有独特的方法 你能跟我们分享下这方面的想法吗
是的, 这其中最美妙的事情在于 在我过去4年中领导Facebook人工智能研究院的过程中 我有很大的自由度,去把他建构成我觉得合适的样子 因为这是在Facebook内部第一个研究机构 Facebook是一个以工程为导向的公司 到现在为止, 他都在专注于生存和短期的事情 Facebook已经10岁了, 也有了成功的上市 并且正在思考未来的10年 我的意思是Mark在思考未来10年中 什么是最重要的事情 公司的生死已经不是一个问题了 所以这是一个转变发生的时候,一家大公司开始思考 应该说当时也不是特别大 Facebook那时候有5000人, 但是他们有这个资格去 思考未来10年, 思考什么对科技发展更加重要。。 Mark和他的团队觉得人工智能是 很重要的一环,对于Facebook要 “链接所有人”的这个使命来说 所有他们探索了很多方式, 去赋能人工智能 他们有一个小的内部工程团队 对卷积网络很有经验 也在人脸识别和其他方向得到了很好的结果, 这激起了他们的兴趣 所以他们探索着雇佣了一批年轻的研究人员, 也收购了公司,或者类似的事情 最终他们定下来要去雇佣在这个领域有资深经验的人 并且建立一个研究机构
刚开始确实有一点文化冲击 因为做研究的方法是与在公司中做工程完全不同的 你会思考更长的时间和更广的空间 研究人员倾向于 保守地选择所要研究的方向 我在开始就很明确的一点是,研究人员应该保持开放的态度 研究人员不仅需要鼓励将成果发表 更需要将发表作为一种要求 并且需要能被类似我们衡量学术研究的评估方式 去衡量研究成果 所以Mark和公司的CTO, Mike Schiroepfer, 也是我现在的上司 他们说,Facebook是一个开放的公司 我们贡献了很多的开源产品。
你知道,Mike Schiroepfer,我们的CTO 就是来自开源社区 他之前在Mozilla工作, 也有很多人都从那边过来。 所以这种开放是根植在公司的DNA中的,这也使得我 对于建立这个开放的研究院感到自信 另外事实上Facebook也不会 像其他公司一样对专利太过痴迷和强迫 这也使公司更利于和大学间进行合作 可以安排一些人一边身在工业界工作, 另一边也和学术界保持联系。
你对那些想要进入人工智能这个领域的人有什么建议?
哈哈 现在和我当时刚开始的时候已经大不相同了 但是我觉得现在非常棒的事情是: 人们一定程度上可以更容易的参与进来 工具现在已经变得很容易使用,像TensorFlow,PyTorch 你可以用卧室的廉价电脑运行这些软件 并且可以训练你的卷积神经网络,循环神经网络等等 也有很多工具 你可以通过线上材料学到很多,这不会太繁重 所以你会看到高中学生现在开始学习这个 这真的很棒,我觉得这确实在 学生群体中引起了学习机器学习和人工智能的兴趣 对年轻人来说这很令人兴奋,我觉得很棒 所以我的建议是,如果你想进入这个领域, 就要让自己变得有用 比如,贡献自己的力量给开源社区 或者去实现一些网上找不到的标准算法 并把他们贡献出来让别人去使用 拿一篇你觉得很重要的文章 并去重新实现里面的算法,把他放到开源社区中去 或者去贡献某些开源项目 如果你写的东西很有趣,也有用,你就会被关注到 也许你会在一个你心仪的公司有一个好的工作 或者你会被你心水的PhD项目录取 我觉得这是一个好的开始
嗯 给开源社区做贡献是一个进入社区的好的方式, 把学到的知识回馈给别人
week2 经典案例
It turns out that a neural network architecture that works well on one computer vision tasks
often works well on other tasks as well, such as maybe on your task.
classic networks:
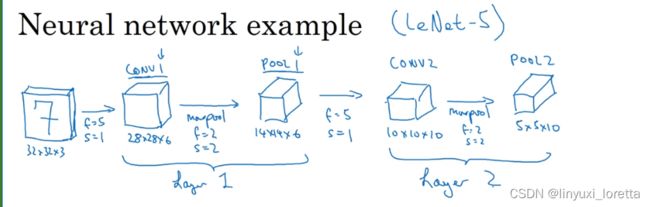
- LeNet-5 1980s,
在这篇论文写成的那个年代,人们更喜欢使用平均池化,而现在我们可能用最大池化更多一些。
LeNet-5的论文是在1998年撰写的,当时人们并不使用padding,这就是为什么每进行一次卷积,图像的高度和宽度都会缩小,
在现在的版本中则使用softmax函数输出10种分类结果,而在当时,LeNet-5网络在输出层使用了另外一种,现在已经很少用到的分类器。
相比现代版本,这里得到的神经网络会小一些,只有约6万个参数。而现在,我们经常看到含有一千万到一亿个参数的神经网络,比这大1000倍的神经网络也不在少数。
对于那些想尝试阅读论文的同学,我再补充几点。
过去,人们使用sigmod函数和tanh函数,而不是ReLu函数。
另外,这种网络结构的特别之处还在于,各网络层之间是有关联的,这在今天看来显得很有趣。
由于在当时,计算机的运行速度非常慢,为了减少计算量和参数,经典的LeNet-5网络使用了非常疯狂的计算方式,不同滤波器会处理输入块的不同通道。论文中提到的这些复杂细节,现在一般都不用了。
最后一件以前做现在没有再做的事是,原始LeNet-5在池化后有非线性处理,在这个例子中,池化层之后使用了sigmod函数。
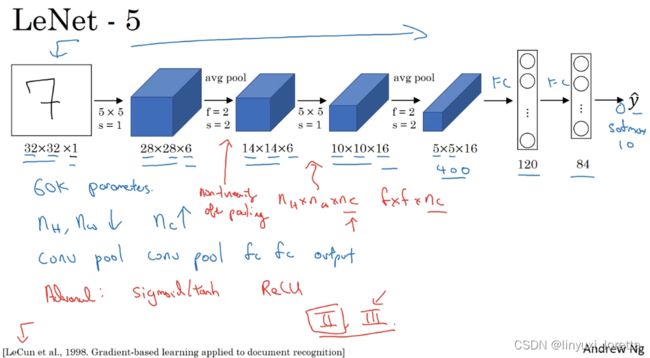
原文的后几段介绍了另外一种思路。文中提到的这种图形变形网络(GTN)如今并没有广泛应用,所以在读这篇论文的时候,我建议精读第二段,这段重点介绍了这种网络结构。泛读第三段,这里面主要是一些有趣的实验结果。
- AlexNet is often cited in VGG
AlexNet,是以论文的第一作者Alex Krizhevsky的名字命名的,另外两位合著者是ilya Sutskever和Geoffery Hinton。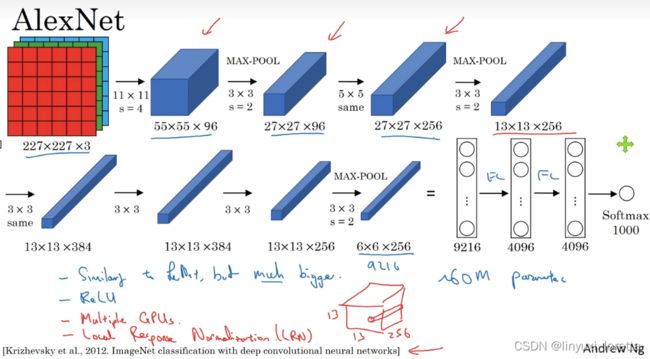
实际上,这种神经网络与LeNet有很多相似之处,不过AlexNet要大得多。正如前面讲到的LeNet或LeNet-5大约有6万个参数,而AlexNet包含约6000万个参数。
AlexNet有非常相似的基本构造模块,但是AlexNet比LeNet表现更为出色,因为:
- 参数量大、有更多隐藏单元
- 在更多数据上训练,AlexNet在ImageNet数据库上训练
- 使用了ReLu激活函数
如果你对深度学习的历史感兴趣的话,我认为在AlexNet之前,深度学习已经在语音识别和其它几个领域获得了一些关注,但正是通过这篇论文,计算机视觉群体开始重视深度学习,并确信深度学习可以应用于计算机视觉领域。此后,深度学习在计算机视觉及其它领域的影响力与日俱增。
AlexNet网络结构看起来相对复杂,包含大量超参数,这些数字(55×55×96、27×27×96、27×27×256……)都是Alex Krizhevsky及其合著者不得不给出的。
- VGG -16
值得注意的一点是,VGG-16网络没有那么多超参数,conv层和max pooling层超参数固定。
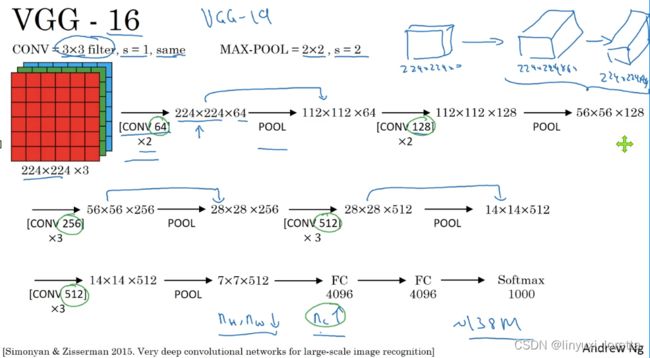
VGG-16的这个数字16,指该网络有16层带权重的层
总共包含约1.38亿个参数,即便以现在的标准来看都算是很大的网络。但VGG-16结构的简洁性也非常吸引人,看得出结构相当统一,都是几个卷积层后面跟着可以压缩图像大小的池化层,池化层缩小图像的高度和宽度。同时,卷积层的过滤器数量变化存在一定的规律,由64翻倍变成128,再到256和512。作者可能认为512已经足够大了,所以后面的层就不再翻倍了。
有些文章还提到了VGG-19网络,甚至比VGG-16还要大,更多细节可以参考幻灯片下方的注文,阅读由Karen Simonyan和Andrew Zisserman 2015撰写的论文。由于VGG-16的表现几乎和VGG-19不分高下,所以很多人还是会使用VGG-16。我最喜欢它的一点是,文中揭示了,随着网络的加深,图像的高度和宽度都在以一定的规律不断缩小,每次池化后刚好缩小一半,而通道数量在不断增加,而且刚好也是在每组卷积操作后增加一倍。也就是说,图像缩小的比例和通道数增加的比例是有规律的。从这个角度来看,这篇论文很吸引人。
ResNet
太深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。这节课我们学习跳跃连接(skip connection/ shorcut),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。利用这个技巧,我们可以训练深度网络的ResNets,有时深度能够超过100层,让我们开始吧。
ResNets是由残差块(Residual block)构建的,首先我解释一下什么是残差块。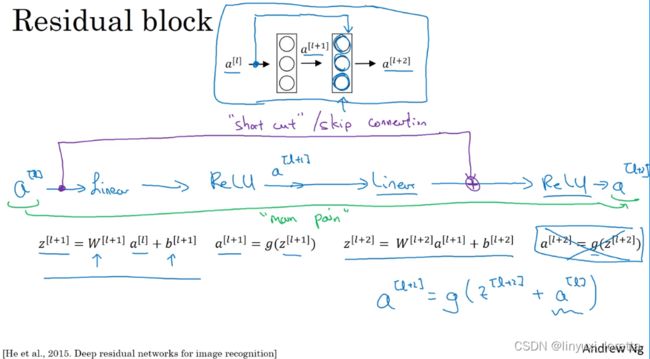
这里的每个节点,都应用一个线性方程和一个ReLU。
ResNet的发明者是何凯明(Kaiming He)、张翔宇(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jiangxi Sun),他们发现使用残差块能够训练更深的神经网络。所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起,形成一个深层网络,我们来看看这个网络。
这是一个普通网络(Plain network),这个术语来自ResNet论文。
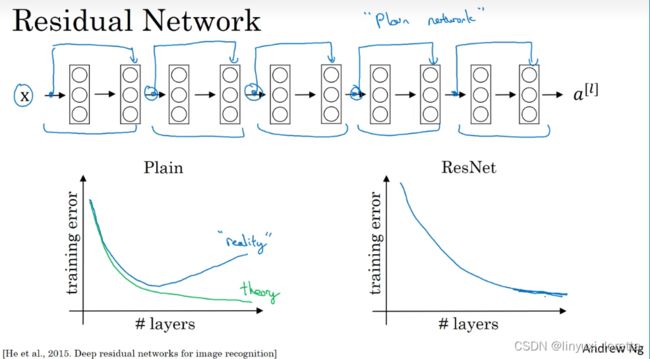
如果我们使用标准优化算法训练一个普通网络,比如说梯度下降法,或者其它热门的优化算法。如果没有残差,没有这些捷径或者跳跃连接,凭经验你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对。也就是说,理论上网络深度越深越好。
in reality,对于一个普通网络来说,深度越深意味着用优化算法越难训练。
但有了ResNets就不一样了,即使网络再深,训练的表现还不错,就算是训练超过100层的网络也不例外。有人甚至在1000多层的神经网络中做过实验,尽管目前我还没有看到太多实际应用。但是对 x 的激活,或者这些中间的激活能够到达网络的更深层。这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们训练更深网络,而不会看到性能倒退的现象。
尽管可能在某一个点会达到平原阶段,这时候就算再加层也不会有帮助。
why resnet work ?
在训练集上的出色表现通常来是,你出色地控制你在训练集上的深度为前提条件。
注意如果使用L2正则化或权重衰减,会压缩W^[l+2]的值,这里W是关键项(key term)
结果表明,残差块学习这个恒等式函数并不难,跳跃连接(skip connection)使我们很容易得出a^[l+2]=a^[l]。这意味着,将这两层加入到你的神经网络,it doesn't really hurt your neural network's ability to do as well as this simpler network without these two extra layers,
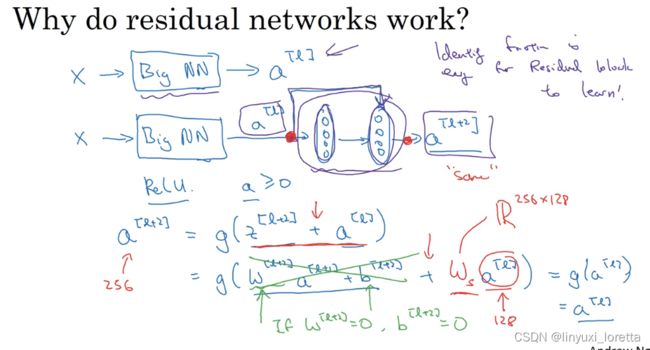
Andrew认为残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,至少不会降低网络的性能,因此创建类似残差网络可以提升网络性能。
另一个值得探讨的细节是,我们是假定z^[l+2]和a^[l]具有相同纬度,所以ResNets使用了许多same卷积(same convolutions)。(如上图红色标记)如果输入和输出有不同纬度,例如输入是128,输出是256,需要进行padding,使用0填充。
你需要做的是增加一个额外的矩阵 Ws,Ws could be a matrix of parameters we learned, 或者 a fixed matrix that just implements zero paddings that takes a[l] and then zero pads it to be 256 dimensional , either of those versions I guess could work.
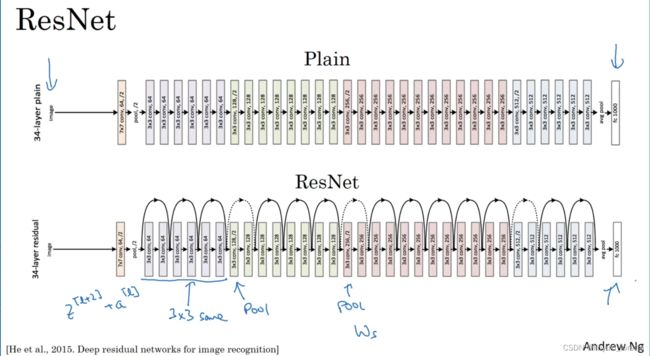
ResNets网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复。直到最后,有一个通过softmax进行预测的全连接层。以上就是ResNets的内容。
1×1 卷积
在架构内容设计(designing content architectures)方面,其中一个比较有帮助的想法是使用1×1卷积。
1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。
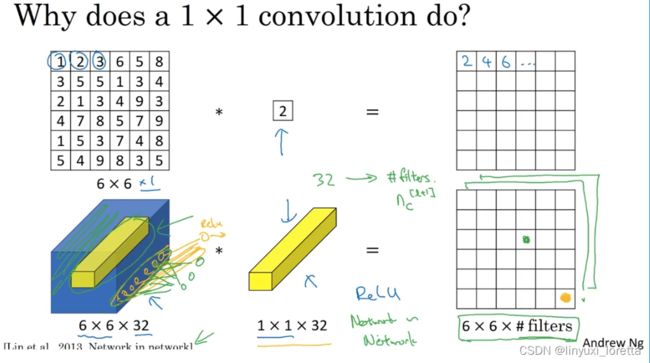
所以1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,输入32个数字 ,输出 #filters(过滤器数量),以便在输入层上实施一个非平凡计算(non-trivial computation)。
这种方法通常称为1×1卷积,有时也被称为Network in Network,在林敏、陈强和颜水成的论文中有详细描述。虽然论文中关于架构的详细内容并没有得到广泛应用,但是1×1卷积或Network in Network这种理念却很有影响力,很多神经网络架构都受到它的影响,包括下节课要讲的Inception网络。
下面介绍1×1卷积的一个应用:
If you want to shrink the height and width,you can use a pooling layer,
当你想shrink the channel的时候,

当然你也可以保持输出channel数不变,如上图红色标记。1×1卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数。1×1卷积的思想对构建Inception网络很有帮助。
Inception
构建卷积层时,你要决定过滤器的大小究竟是1×1,3×3还是5×5,或者要不要添加池化层。而Inception网络的作用就是代替你来决定,虽然网络架构因此变得更加复杂,但网络表现却非常好。
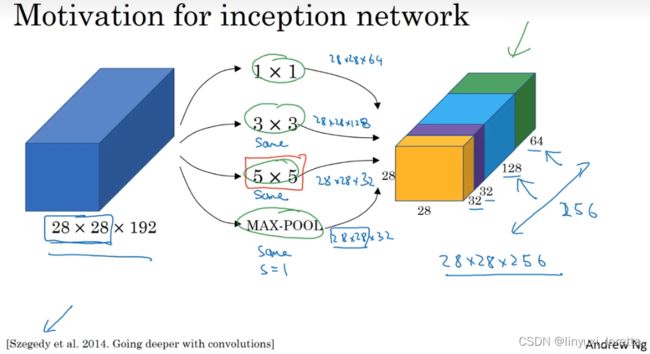
为了匹配所有维度,我们需要对最大池化使用padding,它是一种特殊的池化形式,因为如果输入的高度和宽度为28×28,则输出的相应维度也是28×28。然后再进行池化,padding不变,步幅为1。
这就是Inception网络的核心内容,提出者包括Christian Szegedy、刘伟、贾扬清、Pierre Sermanet、Scott Reed、Dragomir Anguelov、Dumitru Erhan、Vincent Vanhoucke和Andrew Rabinovich。
基本思想是Inception网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
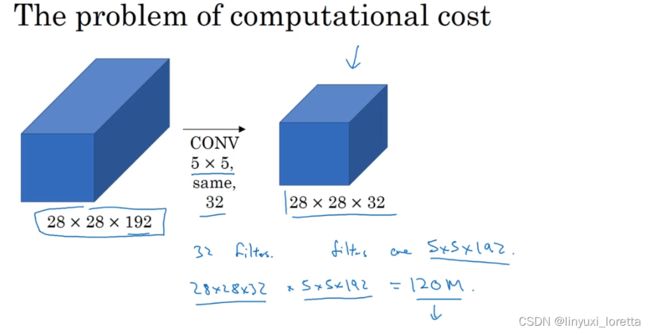
不难发现,我所描述的Inception层有一个问题,就是计算成本,下一张幻灯片,我们就来计算这个5×5过滤器在该模块中的计算成本。
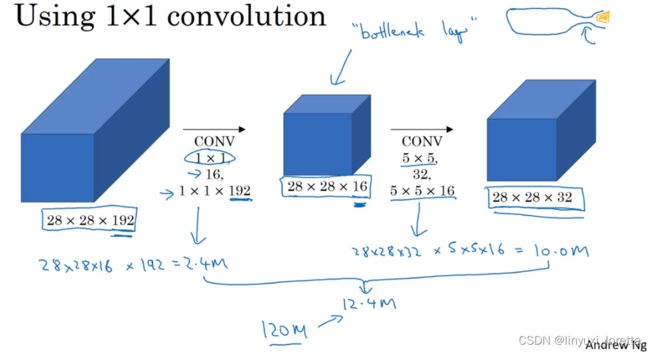
你可能会问,仅仅大幅缩小表示层规模会不会影响神经网络的性能?
事实证明,只要合理构建瓶颈层,你既可以显著缩小表示层规模,又不会降低网络性能,从而节省了计算。
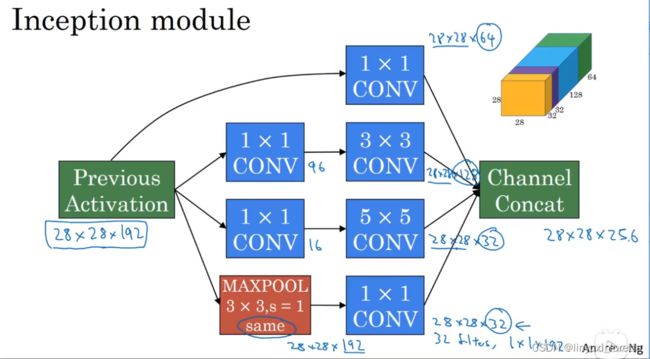
这就是一个Inception模块,而Inception网络所做的就是将这些模块都组合到一起。

这是一张取自Szegety et al的论文中关于Inception网络的图片,你会发现图中有许多重复的模块,可能整张图看上去很复杂,
有的前面加了一个额外的最大池化层 来修改高和宽的维度。(红色小箭头)

事实上,如果你读过论文的原文,你就会发现,这里其实还有一些分支,我现在把它们加上去。所以这些分支有什么用呢?
在网络的最后几层,通常称为全连接层,在它之后是一个softmax层 来做出预测。这些分支 所做的就是 it takes some hidden layer and it tries to use that to make a prediction. 所以这其实是一个softmax输出。
你应该把它看做Inception网络的一个细节,它的作用是用来保证所计算的特征值,即使他们是在最头部的单元里 或者在中间层里,他们对于预测结果来说不算太差。它在Inception网络中,起到一种调整的效果,并且能防止网络发生过拟合。
还有这个特别的Inception网络是由Google公司的作者所研发的,它被叫做GoogleLeNet,这个名字是为了向LeNet网络致敬。
最后,有个有趣的事实,Inception网络这个名字又是缘何而来呢?

Inception的论文特地提到了这个meme(网络用语即“梗”),就是“我们需要走的更深”(We need to go deeper),论文还引用了这个网址(http://knowyourmeme.com/memes/we-need-to-go-deeper),连接到这幅图片上,如果你看过Inception(盗梦空间)这个电影,你应该能看懂这个由来。作者其实是通过它来表明了建立更深的神经网络的决心,他们正是这样构建了Inception。我想一般研究论文,通常不会引用网络流行模因(梗),但这里显然很合适。
Inception模块已经衍生了许多新的版本。所以在你们看一些比较新的Inception算法的论文时,会发现人们使用这些新版本的算法效果也一样很好,比如Inception V2、V3以及V4,还有一个版本引入了跳跃连接ResNet的方法,有时也会有特别好的效果。
MobileNet
顾名思义,这是一种适用于移动(mobile)设备的神经网络。移动设备的计算资源通常十分紧缺,因此,MobileNet对网络的计算量进行了极致的压缩。
减少卷积运算量
再回顾一遍,一次卷积操作中主要的计算量如下:
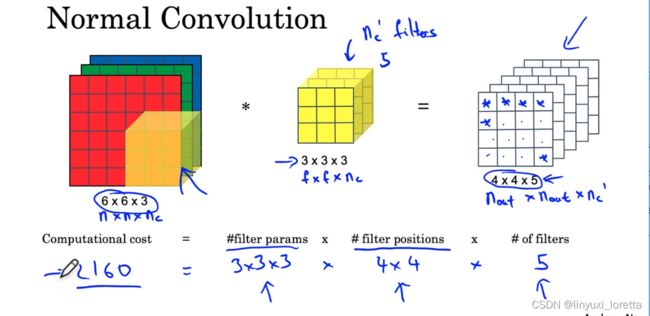
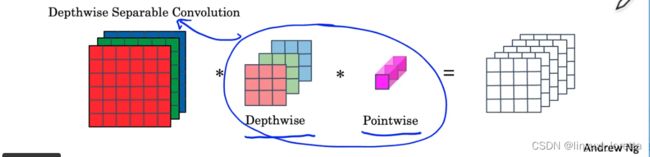
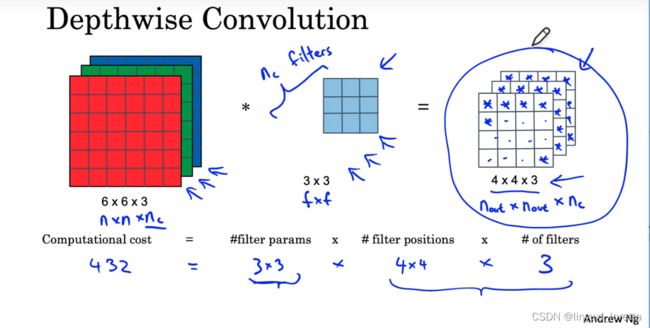
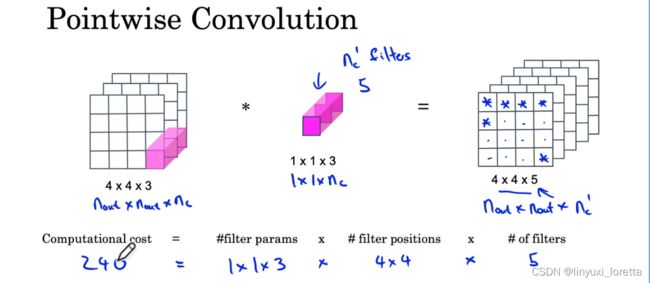

一般来说计算量都会少10倍。
网络结构 MobileNet Architecture
知道了MobileNet的基本思想,我们来看几个不同版本的MobileNet。
MobileNet v1、MobileNet v2
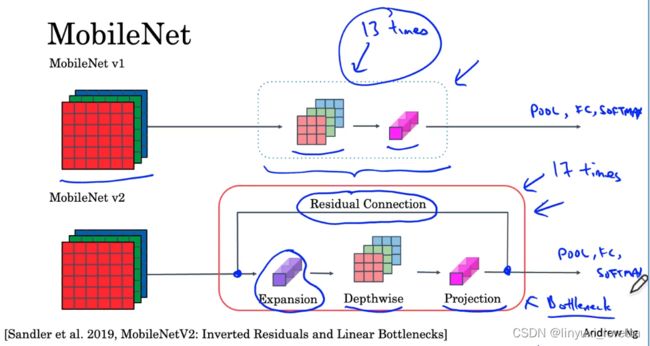
两个改进:
- 残差连接
- 扩张(expansion)操作
残差连接和ResNet一样。这里我们关注一下第二个改进。

扩展因子 6 (A factor of expansion of 6 )在 MobileNet v2 中非常典型 ,它将维度增加了六倍,
在 MobileNet v2 瓶颈块中,最后一步操作也叫做投影,because you're projecting down from nxnx18 down to nxnx3.
这种架构很好地解决了性能和效果之间的矛盾:在模块之间,数据的通道数只有3,占用内存少;在模块之内,更高通道的数据能拟合更复杂的函数。
在移动设备上部署时,在edge device上,往往会受到沉重的内存限制。瓶颈块使用逐点卷积或投影操作将其投影回来,缩小到一组较小的值,以便当您将其传递给下一个block时,存储这些值所需的内存量减少了。
EfficientNet
EfficientNet能根据设备的计算能力,自动调整网络占用的资源。
让我们想想,哪些因素决定了一个网络占用的运算资源?我们很快能想到下面这些因素:
- 图像分辨率 high resolution image
- 网络深度 deeper
- 特征的长度(即卷积核数量或神经元数量) make the layers wider
compound scaling复合缩放
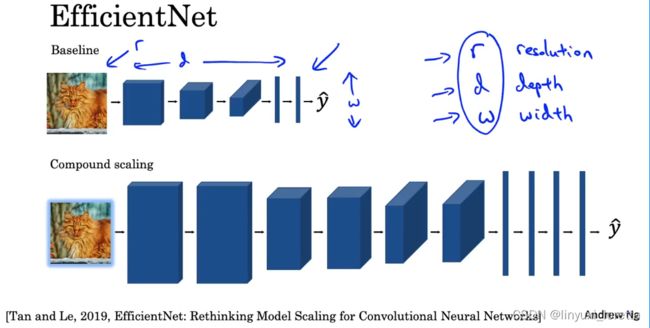
在EfficientNet中,我们可以在这三个维度上缩放网络,动态改变网络的计算量。EfficientNet的开源实现中,一般会提供各设备下的最优参数。
Practical Advice for using ConvNets
using open-source implementations
事实证明许多神经网络都很难复现,因为许多关于调整hyperparameters的细节。最好的学习方法是找到别人的开源代码,在现有代码的基础上学习。
深度学习的开源代码一般在GitHub上都能找到。如果是想看PyTorch实现,可以直接去GitHub上搜索OpenMMLab。
这个代码是按照MIT 开源许可协议开发的,MIT 开发许可协议是最宽松的开源协议之一。
你只需要输入 git clone 然后粘贴刚才复制的链接
Transfer learning 使用迁移学习
导入别人训练好的模型里的权重为初始权重,加速我们自己模型的训练。
还是以多分类任务的迁移学习为例(比如把一个1000分类的分类器迁移到一个猫、狗、其他的三分类模型上)。
方法1:你能做的是去掉其softmax层 然后创造自己softmax层来输出Tigger/Misty/其他。in terms of the network,我建议你考虑冻结(前面)这些层,因此可以只训练与你自己softmax层有关的参数。用别人的pretrained weight,即使在很小的数据库上也可能得到很好的性能。你可以把前面某些层这样设置(可训练参数为零)
方法2:(预计算)训练集所有样本(激活结果)并存到硬盘上,然后训练右边的softmax类别。(图中紫色的标注)。预计算的好处是,你不需要 在训练集上每次迭代 都重新计算这些激活结果
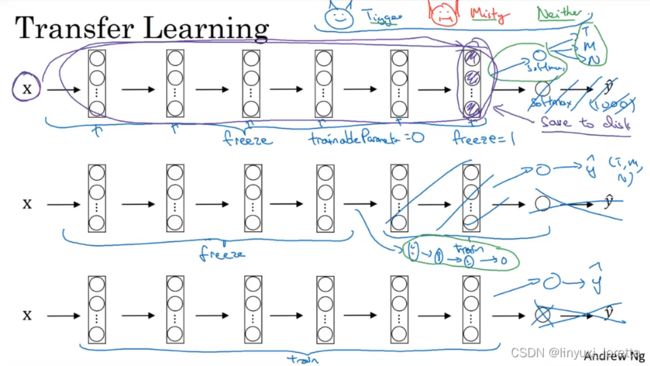
你数据越多、所冻结的层数可以越少
当然,可以多删除几个较深的层,也可以尝试加自己的网络结构。
在所有深度学习应用的领域中,我认为计算机视觉是一个你应该always尝试 迁移学习的领域。 除非你有海量的数据集和运算资源。
数据增强
由于CV任务总是缺少数据,数据增强是一种常见的提升网络性能的手段。
但是我认为如今, 计算机视觉的状态是 对于绝大多数的问题,我们总是不能获得足够的数据,这点对机器学习应用来说并不总是成立, 但对计算机视觉来说是成立的
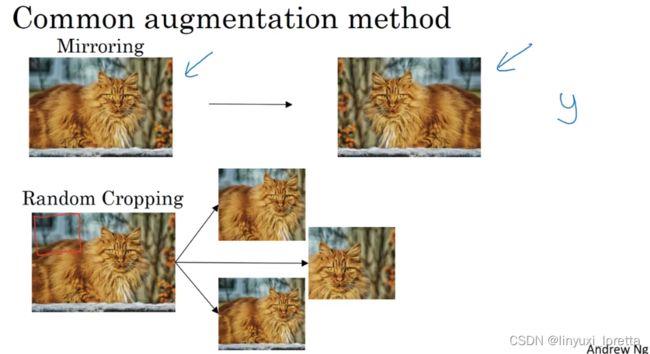
常见的数据增强手段有:.
- 垂直镜像
- 随机裁剪。但是随机裁剪并不是一种完美的数据增强方式.,假如你随机裁剪下那块看起来不像猫的一片,but in practise,it works well,只要随机裁剪的部分占原图片的相当大一部分.
理论上,还可以。实践中这些方法不那么常用,:

第二类常用的数据增强方式是色彩变化. 比如对三个颜色通道都随机加一个扰动。
在实践中, 红绿蓝的数值是通过些概率分布来获得的.
这样做的出发点是有时候日光有点偏黄,
使得学习算法在应对图像色彩变化时健壮性更好.

有不同的方式来采样红绿蓝通道值. 其中一种色彩干扰的算法被称为PCA.
数据增强有一些实现上的细节:
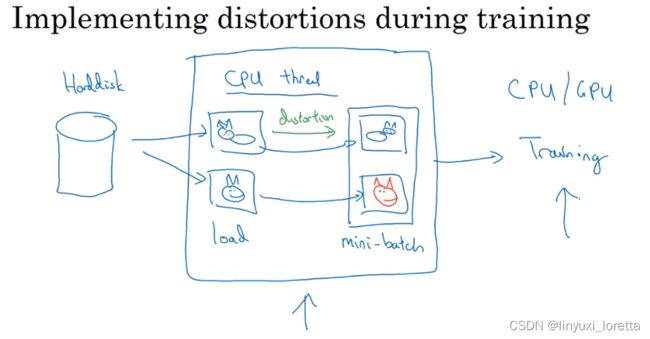
数据的读取及增强是放在CPU上运行的,训练是放在CPU或GPU上运行的。这两步其实是独立的,可以并行完成。最常见的做法是,在CPU上用多进程(发挥多核的优势)读取数据并进行数据增强,之后把数据搬到GPU上训练。
计算机视觉的现状与相关建议
深度学习已经成功地应用于计算机视觉、自然语言处理、语音识别、在线广告、物流还有其他许多问题。对于深度学习在计算机视觉中的应用及现状 有几个独特的方面。
在这个视频中,我将和你们分享一些我对深度学习在计算机视觉方面应用的认识,希望能帮助你们更好地理解计算机视觉作品(此处指计算机视觉或者数据竞赛中的模型)以及其中的想法,以及如何自己构建这些计算机视觉系统。
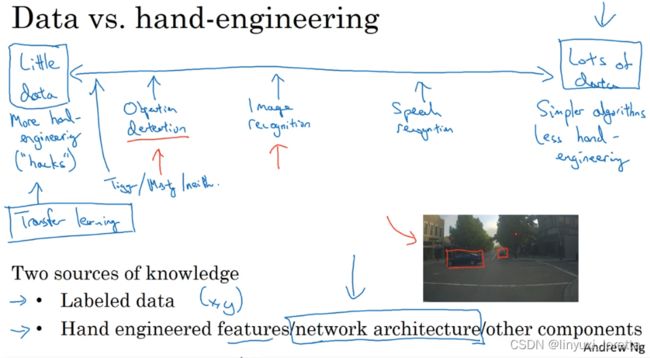
你可以认为大部分机器学习问题是介于少量数据和大量数据范围之间的。举个例子,我认为今天我们有相当数量的语音识别数据,至少相对于这个问题的复杂性而言。虽然现在图像识别或图像分类方面有相当大的数据集,因为图像识别是一个复杂的问题,通过分析像素并识别出它是什么,感觉即使在线数据集非常大,如超过一百万张图片,我们仍然希望我们能有更多的数据。还有一些问题,比如目标检测,我们拥有的数据更少。提醒一下,图像识别告诉你这张图是不是猫,而对象检测则是看一幅图,你画一个框,告诉你图片里的物体,比如汽车等等。因为获取边框的成本比标记对象的成本更高,所以我们进行对象检测的数据往往比图像识别数据要少,对象检测是我们下周要讨论的内容。
如果纵观机器学习问题的谱系,你会发现 一般情况下 当你有很多数据时候 你往往会发现人们、差不多使用比较简单的算法 以及更少的人工设计也就可以了,因为 不太需要针对问题来仔细地设计特征。当你有大量的数据时,只要有一个大型的神经网络,甚至一个更简单的架构,就让神经网络可以去学习。
相反当你没有那么多的数据时,那时你会看到人们做更多的“人工设计",也就是你有很多小技巧可用(在机器学习或者深度学习中,一般更崇尚更少的人工处理,而手工工程更多依赖人工处理)。但我认为你没有太多数据时,手工工程实际上是获得良好表现的最佳方式。
所以当我看机器学习应用时,通常我们的学习算法有两种知识来源:1.标记的数据,就像( x,y )应用在监督学习。2.手工工程,有很多方法去建立一个手工工程系统,它可以是源于精心设计的特征、精心设计的网络体系结构、或是系统的其他组件。所以当你没有太多标签数据时,你只需要更多地考虑手工工程。
所以我认为 计算机视觉正试图学习一个非常复杂的函数,我们经常感觉我们没有足够的数据,尽管数据集正在变得越来越大 ,通常 我们还是没有满足需要的那么多的数据。这就是为什么计算机视觉,从过去甚至到现在都更多地依赖于手工工程。我认为这也是计算机视觉领域,开发了相当复杂的网络结构的原因。
我并不是在贬低手工工程,当你没有足够的数据时,手工工程是一项非常困难,非常需要技巧的任务,它需要很好的洞察力,那些对手工工程有深刻见解的人将会得到更好的表现。当你没有足够的数据时,手工工程对一个项目来说贡献就很大。当你有很多数据的时候我就不会花时间去做手工工程,我会花时间去建立学习系统。但我认为从历史而言,计算机视觉领域还只是使用了非常小的数据集,因此从历史上来看计算机视觉还是依赖于大量的手工工程。甚至在过去的几年里,计算机视觉任务的数据量急剧增加,我认为这导致了手工工程量大幅减少,但是在计算机视觉上仍然有很多的网络架构使用手工工程,这就是为什么你会在计算机视觉中看到非常复杂的超参数选择,比你在其他领域中要复杂的多。实际上,因为你通常有比图像识别数据集更小的对象检测数据集,当我们谈论对象检测时,其实这是下周的任务,你会看到算法变得更加复杂,而且有更多特定化的组件。
所幸的是 当只有很少量数据时 有一个能提供很大帮助的东西 就是迁移学习。这是另一套技术,被大量使用于只有相对很少数据的情况
对于计算机视觉的研究者来说 如果你在基准数据上做得很好,那就更容易发表论文。积极的一面是,它有助于整个社区找出最有效得算法。但是你在论文上也看到,人们所做的事情让你在数据基准上表现出色,但你不会真正部署在一个实际得应用程序用在生产或一个系统上。
下面是一些有助于在基准测试中表现出色的小技巧,但 如果我要将一个系统放到实际服务客户的产品中、这些东西我自己基本上是不曾也不会用的
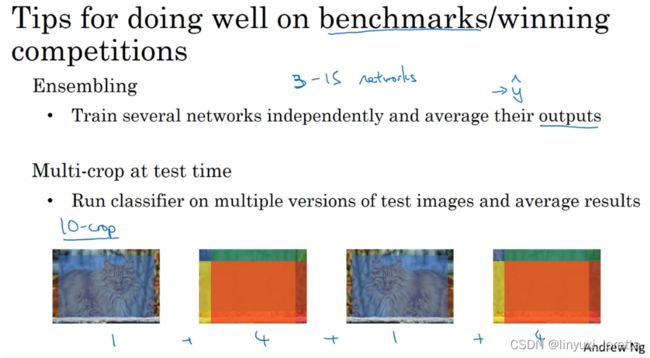
其中一个是集成,这就意味着在你想好了你想要的神经网络之后,可以独立训练几个神经网络,并平均它们的输出。比如说随机初始化三个、五个或者七个神经网络,然后训练所有这些网络,然后平均它们的输出。不要平均他们的权重,这是行不通的。看看你的7个神经网络,它们有7个不同的预测,然后平均他们,这可能会让你在基准上提高1%,2%或者更好。但因为集成意味着要对每张图片进行测试,你可能需要在从3到15个不同的网络中运行一个图像,这是很典型的,因为这3到15个网络可能会让你的运行时间变慢,甚至更多时间,所以技巧之一的集成是人们在基准测试中表现出色和赢得比赛的利器,但我认为这几乎不用于生产服务于客户的,我想除非你有一个巨大的计算预算而且不介意为每一幅客户的图像烧掉更多的钱
另外一个你在文章中看到 真正有助于基准数据测试的东西, Multi-crop at test time 测试时使用多重剪切(multi-crop),Multi-crop是一种将数据扩充应用到你的测试图像中的一种形式。
你要做的就是,通过你的分类器来运行这十张图片,然后对结果进行平均。如果你有足够的计算预算,你可以这么做,或许你并不需要10次剪切那么多,你可以使用若干次剪切,这也许能为一个产品化的系统带来些许性能提升. 但这是另一种技术,它在基准测试上的应用,要比实际生产系统中好得多。
集成的一个大问题是你需要保持所有这些不同的神经网络,这就占用了更多的计算机内存。对于multi-crop,我想你只保留一个网络,所以它不会占用太多的内存,但它仍然会让你的运行时间变慢。
因为很多计算机视觉问题是在拥有少量数据的范畴,前人已经对网络结构做了大量的人工处理. 一个神经网络在某个计算机视觉问题上很有效,但令人惊讶的是它通常也会解决其他计算机视觉问题。

由于计算机视觉问题建立在小数据集之上,其他人已经完成了大量的网络架构的手工工程。一个神经网络在某个计算机视觉问题上很有效,但令人惊讶的是它通常也会解决其他计算机视觉问题。
所以,要想建立一个实用的系统,你最好先从其他人的神经网络架构入手。如果可能的话,你可以使用开源的一些应用,因为开放的源码实现可能已经找到了所有繁琐的细节,比如学习率衰减方式或者超参数。
最后,其他人可能已经在几路GPU上花了几个星期的时间来训练一个模型,训练超过一百万张图片,所以通过使用其他人的预先训练得模型,然后在数据集上进行微调,你可以在应用程序上运行得更快。当然如果你有电脑资源并且有意愿,我不会阻止你从头开始训练你自己的网络。事实上,如果你想发明你自己的计算机视觉算法,这可能是你必须要做的。
这就是本周的学习,我希望通过了解一定数量的计算机视觉架构 能够有助于你对什么网络能奏效的的感觉有一些帮助