mmclas中pytorch转onnx,onnxruntime推理
https://github.com/Microsoft/onnxruntime/blob/master/docs/Versioning.md https://github.com/Microsoft/onnxruntime/blob/master/docs/Versioning.mdAccelerate PyTorch Inference - onnxruntimeONNX Runtime: cross-platform, high performance ML inferencing and training accelerator
https://github.com/Microsoft/onnxruntime/blob/master/docs/Versioning.mdAccelerate PyTorch Inference - onnxruntimeONNX Runtime: cross-platform, high performance ML inferencing and training accelerator![]() https://onnxruntime.ai/docs/tutorials/accelerate-pytorch/pytorch.html
https://onnxruntime.ai/docs/tutorials/accelerate-pytorch/pytorch.html
Pytorch - 使用torch.onnx.export将Pytorch模型导出为ONNX模型 - StubbornHuang Bloghttps://www.stubbornhuang.com/1694/1.版本信息
python:3.6.5,cudnn:7.3.1,cuda:9.0.176,torch:1.5.1+cu92,torchvision:0.6.1+cu92,onnx:1.8.1,onnxruntime:1.7.0,opset_version:11,onnx-simplifer:0.3.4,onnxoptimizer:0.2.5,
转onnx其实没有什么问题,问题就是转完有可能没法用,onnx其实就是个json。onnx本身和python3.5-3.7兼容,此外torch1.5+cuda9.2在cuda9.0上跑也没有什么问题,向下兼容的。

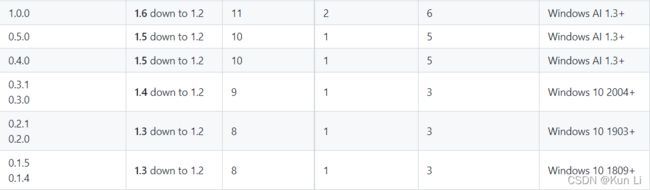
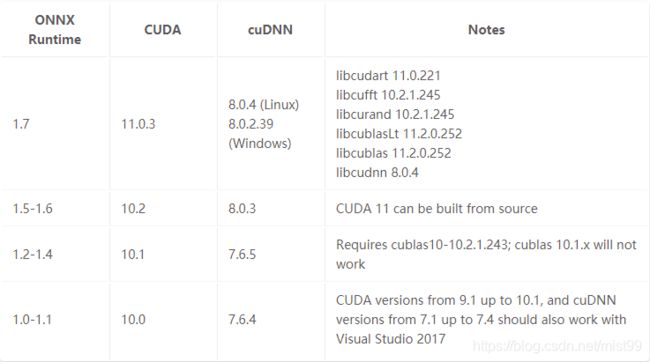
onnx runtime还有cpu和gpu两个版本,只要和gpu相关的,就和cuda相关,就有版本问题,onnxruntime-gpu默认用gpu版本,gpu版本cuda从10.x开始,目前为了保持tensorrt7.0和torch 1.5以及对应的cuda 9.0,cudnn 7.6,就不折腾了onnxruntime-gpu。
2.torch.onnc.export
在通过pytorch得到onnx的核心接口,
torch.onnx.export(model,
args,
f,
export_params=True,
verbose=False,
training= < TrainingMode.EVAL: 0 >,
input_names=None,
output_names=None,
operator_export_type=None,
opset_version=None,
_retain_param_name=None,
do_constant_folding=True,
example_outputs=None,
strip_doc_string=None,
dynamic_axes=None,
keep_initializers_as_inputs=None,
custom_opsets=None,
enable_onnx_checker=None,
use_external_data_format=None)model:要导出的模型。
args:模型的输入, 任何非Tensor参数都将硬编码到导出的模型中;任何Tensor参数都将成为导出的模型的输入,并按照他们在args中出现的顺序输入。因为export运行模型,所以需要提供一个输入张量x。只要是正确的类型和大小,其中的值就可以是随机的。如果不在后面做dynamic_axes的设置,这里的输入和onnx推理时的输入就是一致的,(bs,c,width,height)。可以对这个维度做指定,通常对bs做动态之后,就可以用batch输出了。
f:输出onnx文件名。
export_params:默认True,True:所有的模型参数都将被导出,False:导出一个未训练过的模型。参数顺序为model.state_dict().values()。
verbose:默认False,True:打印出一个导出轨迹的调试模式。
training:默认False,在训练模式下导出模型,目前,onnx导出的模型只是为了做推理,通常不需要将其设置为True。
input_names:按顺序分配名称到图中的输入节点。
output_names:按顺序分配名称到图中的输出节点。
opset_version:默认是9,在torch/onnx/symbolic_helper.py中定义,是onnx的开放版本。
do_constant_folding:默认是False,常量折叠优化,用预先计算的常量节点替换一些具有常量输入的操作。
keep_initializers_as_inputs:默认是None,True:则导出图中的所有初始化参数也将作为输入添加到图中,False:则初始化器不会作为输入添加到图中,并且仅将非参数输入添加为输入,这可能允许推理运行时进行更好的优化,例如常量折叠。
dynamix_axes:用于指定输入/输出的动态轴的字典,默认{}:导出模型的所有输入和输出张量的形状和args中的完全一致,不做动态的话,args中输出什么,将来推理时就输入什么是保持一致的。指定了动态输出的话,KEY:输入和/或输出名称 - VALUE:给定键的动态轴索引以及可能用于导出动态轴的名称。key的名称和input_names和output_names对应上。如果value是整数列表的话,会生成自动名称并将其应用于导出时提供的输入输出的动态轴上,value若是键值指定的则直接应用。mmclas中就是第二种,直接指定了。
if dynamic_export:
dynamic_axes = {
'input': {
0: 'batch',
2: 'width',
3: 'height'
},
'probs': {
0: 'batch'
}
}
else:
dynamic_axes = {}
with torch.no_grad():
torch.onnx.export(
model, (img_list, ),
output_file,
input_names=['input'],
output_names=['probs'],
export_params=True,
keep_initializers_as_inputs=True,
dynamic_axes=dynamic_axes,
verbose=show,
opset_version=opset_version)3.onnx simplifer
mmclas中对是否使用onnx simplifer提供了接口,这一步咋mmdeploy的torch2onnx中已经没有了,相信伴随着torch.onnx.export的发展,后面这个simplifer就不一定有用了。但是在onnx simplifer时dynamic_export时,后面的shape都乘了2,变成了448。这个操作可能是给动态输出找了个大范围吧。
model_opt, check_ok = onnxsim.simplify(
output_file,
input_shapes=input_shape_dic,
input_data=input_dic,
dynamic_input_shape=dynamic_export)4.onnxruntime 单图前向
mmclas中只提供了动态batch的输入和推理,如果是单图前向的话,其实不需要动态,更简单,只需要在转onnx的args中给出输入图的尺寸,后面的dynamic_export给False就可以。
import torch
import torchvision
dummy_input = torch.randn(10, 3, 224, 224, device="cuda")
model = torchvision.models.alexnet(pretrained=False).cuda()
model.load_state_dict(torch.load("alexnet-owt-4df8aa71.pth"))
# Providing input and output names sets the display names for values
# within the model's graph. Setting these does not change the semantics
# of the graph; it is only for readability.
#
# The inputs to the network consist of the flat list of inputs (i.e.
# the values you would pass to the forward() method) followed by the
# flat list of parameters. You can partially specify names, i.e. provide
# a list here shorter than the number of inputs to the model, and we will
# only set that subset of names, starting from the beginning.
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
torch.onnx.export(model, dummy_input, "alexnet.onnx", verbose=True, input_names=input_names, output_names=output_names)
import onnx
# Load the ONNX model
model = onnx.load("alexnet.onnx")
# Check that the model is well formed
onnx.checker.check_model(model)
# Print a human readable representation of the graph
print(onnx.helper.printable_graph(model.graph))
import onnxruntime as ort
import numpy as np
ort_session = ort.InferenceSession("alexnet.onnx")
outputs = ort_session.run(
None,
{"actual_input_1": np.random.randn(10, 3, 224, 224).astype(np.float32)},
)
print(outputs[0])
上面这个是官方给的一个示例,推理时输入就是(10,3,224,224)。
5.onnxruntime batch前向
dynamic export才能用batch前向推理,当然batch前向其实只需要将bs这一维设置为动态就可以,但是实际上的通常把batch,width,height这三个维度都变成动态的,不去固定,其实上面再args推理时把batch改成大于1的值也是batch推理,但是batch不能有变化,但是通常在做crnn对检测出来的框做前向时,就有问题了,而且当一次前向推理少于预定的bs时,还要想办法做填充,这就很麻烦了。
class ONNXRuntimeClassifier(BaseClassifier):
"""Wrapper for classifier's inference with ONNXRuntime."""
def __init__(self, onnx_file, class_names, device_id):
super(ONNXRuntimeClassifier, self).__init__()
sess = ort.InferenceSession(onnx_file)
providers = ['CPUExecutionProvider']
options = [{}]
is_cuda_available = ort.get_device() == 'GPU'
if is_cuda_available:
providers.insert(0, 'CUDAExecutionProvider')
options.insert(0, {'device_id': device_id})
sess.set_providers(providers, options)
self.sess = sess
self.CLASSES = class_names
self.device_id = device_id
self.io_binding = sess.io_binding()
self.output_names = [_.name for _ in sess.get_outputs()]
self.is_cuda_available = is_cuda_available
def simple_test(self, img, img_metas, **kwargs):
raise NotImplementedError('This method is not implemented.')
def extract_feat(self, imgs):
raise NotImplementedError('This method is not implemented.')
def forward_train(self, imgs, **kwargs):
raise NotImplementedError('This method is not implemented.')
def forward_test(self, imgs, img_metas, **kwargs):
input_data = imgs
# set io binding for inputs/outputs
device_type = 'cuda' if self.is_cuda_available else 'cpu'
if not self.is_cuda_available:
input_data = input_data.cpu()
self.io_binding.bind_input(
name='input',
device_type=device_type,
device_id=self.device_id,
element_type=np.float32,
shape=input_data.shape,
buffer_ptr=input_data.data_ptr())
for name in self.output_names:
self.io_binding.bind_output(name)
# run session to get outputs
self.sess.run_with_iobinding(self.io_binding)
results = self.io_binding.copy_outputs_to_cpu()[0]
return list(results)后续这块可以参照mmdeploy来进行改动。