编译原理(1)---c语言分词器
概述
环境:linux&win
语言:标准C
解析对象:c89
工程工具:vs2008,codeblocks
参考书籍:《K&R C Language》《编译原理(紫龙书)》
工程下载地址:我的新浪共享,http://ishare.iask.sina.com.cn/f/11837686.html
其他:供学习参考交流
要识别的C语言Ascii字符表
| 回车 |
13 |
? |
63 |
a |
97 |
| ESC |
27 |
@ |
64 |
b |
98 |
| 空格 |
32 |
A |
65 |
c |
99 |
| ! |
33 |
B |
66 |
d |
100 |
| " |
34 |
C |
67 |
e |
101 |
| # |
35 |
D |
68 |
f |
102 |
| $ |
36 |
E |
69 |
g |
103 |
| % |
37 |
F |
70 |
h |
104 |
| & |
38 |
G |
71 |
i |
105 |
| , |
39 |
H |
72 |
j |
106 |
| ( |
40 |
I |
73 |
k |
107 |
| ) |
41 |
J |
74 |
l |
108 |
| * |
42 |
K |
75 |
m |
109 |
| + |
43 |
L |
76 |
n |
110 |
| , |
44 |
M |
77 |
o |
111 |
| - |
45 |
N |
78 |
p |
112 |
| . |
46 |
O |
79 |
q |
113 |
| / |
47 |
P |
80 |
r |
114 |
| 0 |
48 |
Q |
81 |
s |
115 |
| 1 |
49 |
R |
82 |
t |
116 |
| 2 |
50 |
S |
83 |
u |
117 |
| 3 |
51 |
T |
84 |
v |
118 |
| 4 |
52 |
U |
85 |
w |
119 |
| 5 |
53 |
V |
86 |
x |
120 |
| 6 |
54 |
W |
87 |
y |
121 |
| 7 |
55 |
X |
88 |
z |
122 |
| 8 |
56 |
Y |
89 |
|
|
| 9 |
57 |
Z |
90 |
{ |
123 |
| : |
58 |
[ |
91 |
| |
124 |
| ; |
59 |
\ |
92 |
} |
125 |
| < |
60 |
] |
93 |
~ |
126 |
| = |
61 |
^ |
94 |
|
|
| > |
62 |
- |
95 |
|
|
Token
分词器解析的C语言token有六种:
- Identity
首字母必需是字母,后可接数字、字母或者连接符’_’
- Keywords
关键字暂定32个,c89新加的const,volatile,signed等不加入解析范围。
- Constants
常量包括一些整型常量,字符常量,浮点常量,枚举常量四种。
整型:int,long,unsigned int,unsigned long int等等
字符常量:”\n”,”\t”,”\v”,”\b”,”\r”,”\f”,”\a”,”\\”,\”\?”,”\’”,”\””,”\ooo”,”\xhh”
浮点数如:
float f = 12.96;
long m_long =1200000000L;
unsigned intuint = 45u;
(上面两个不是浮点...)
- String
即识别“content”中的内容,并指定为串类。
- Operators
基本的操作符号,包括2个三元操作符。
- Other separate token
分隔符,如‘,’‘{’‘(’等。
产物
- Token表
生成识别单词表,我使用的是链表形式存储。
| words(单词本身) |
token种类 |
|
|
|
|
|
|
2、符号表
作为词法分析器的产出物将用于下一阶段的语法分析。
编译过程中需要不断地汇集和反复查证在源码中出现的名字的属性和特征等有关信息,这些信息将放在符号表中,这些可以在词法分析或者语法分析过程中做。
| NAME |
token |
|||
| 单词本身 |
单词长度 |
type |
subtype |
Value |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3、Error表
指出错误发生的行列,错误原因。
实现过程
实现过程中使用了两个自动机,一个是单个char为判断元素分析的自动机(有10个状态,stat_loop()中实现);另一个是为了方便处理//和/**/注释的自动机(这个自动机很小,只有三个状态,scanner()中实现)。详细的转移过程如下图所示:
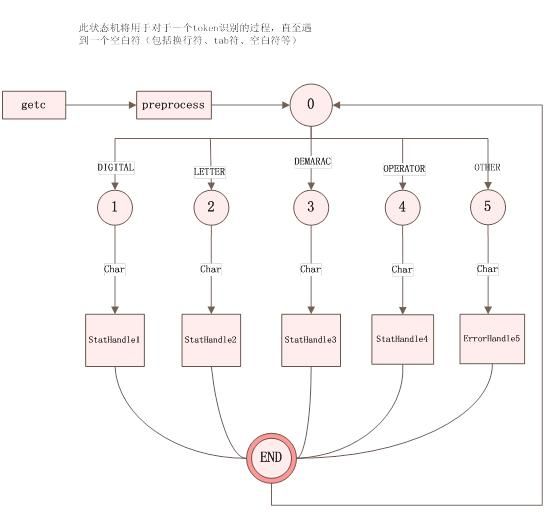
图1、主要状态转换
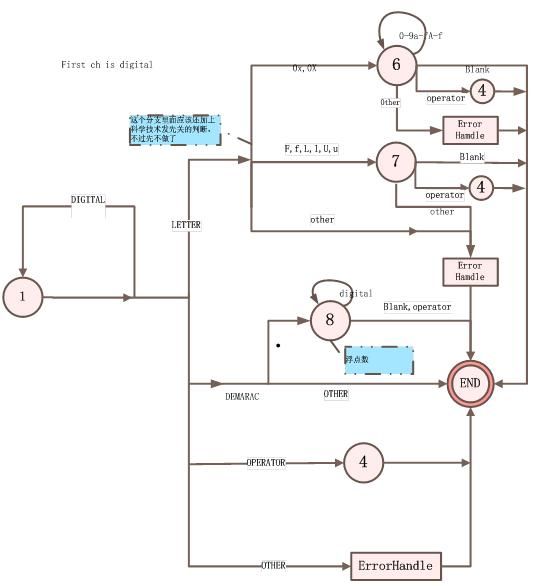
图2、StatHandle2状态处理
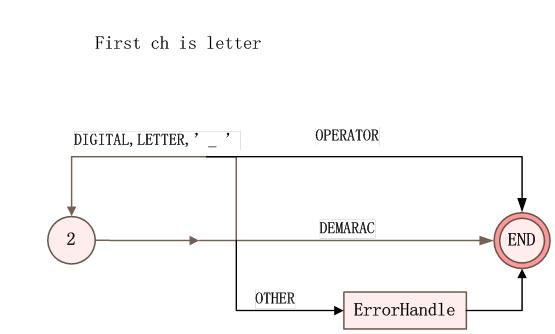
图3、StatHandle3处理
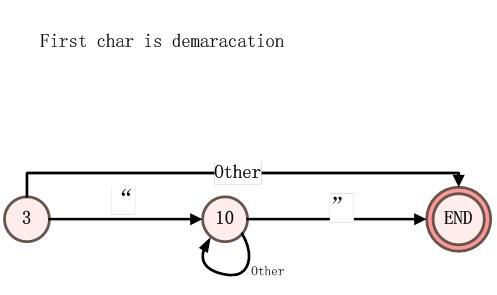
图4、StatHandle4处理
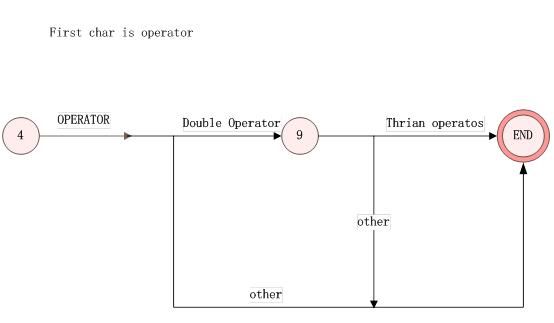
图5、StatHandle5处理
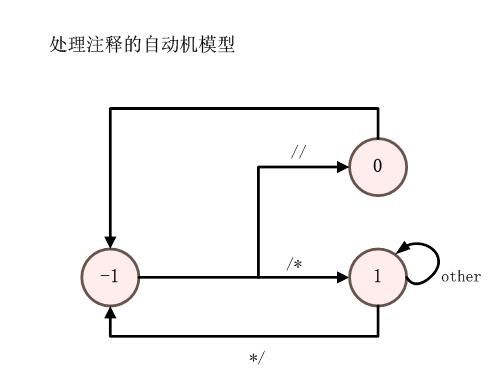
图6、注释处理自动机切换
考虑到效率和简洁性的问题本分词器只使用了一个缓冲区,用来存放一行代码处理。
整个处理过程对文件一次遍历访问。
状态说明
0:初始状态,读入了第一个char
1:已经读入一个数字。
2:已经读入一个字母。
3:已经读入一个分隔符。
4:已经读入一个操作符。
5:读入一个未识别字符
6:第一个读入0,第二个读入x或者X,即十六进制的情况
7:从1状态读入一个f,F,l,F,U,u都将进入这个状态。
8:读入“数字.”的情况,浮点数识别。
9:读入了两个操作符。进行双元操作符和三元操作符的识别。
10:已经读入了一个“,准备读入下一个”的状态。
END:结束状态,字符出理完成或者出错对以后的字符有连带效果的在这一个状态。
重要结构和函数
pos 这个变量指示了当前的位置信息,行列等。在切换状态的时候,pos中lex_begin和lex_end的调整就要小心了。
Stat 全局状态变量(10状态的那个)。
Comment_stat全局状态机状态(解析注释的那个)。
ascii:字符码映射表,可快速查到字符的类别。
Scanner():扫描文件主程序,里面调用了状态机切换函数stat_loop,实现注释匹配的状态机切换。
Stat_loop():主状态机。
结果截图:
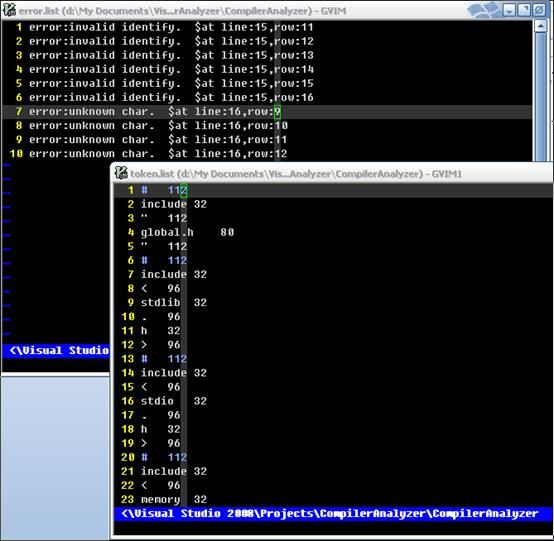
未完成
本实验还未完成符号表的更新。
还未识别正负数的表达。如+1220,-2200等。这个我认为也可以在语法分析中做,-号在某些模式下可以当做取反操作,这里做的话太麻烦。
代码量900+,还可精简。但是----------
不想动了。O(╯□╰)o