MV3D论文解析
MV3D论文解析
论文链接:
Multi-View 3D Object Detection Network for Autonomous Driving (thecvf.com)
原论文中的参考文献:
《FRACTALNET: ULTRA-DEEP NEURAL NETWORKS WITHOUT RESIDUALS》
1605.07648.pdf (arxiv.org)
《Deeply-Fused Nets》
1605.07716.pdf (arxiv.org)
《A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection》
A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection | SpringerLink (53yu.com)
MV3D代码链接:
github.com
1.前言
在3D物体检测中,基于相机的3D物体检测虽然能获得物体详细的语义信息,但是对于深度的估计有较大的误差;基于激光雷达的3D物体检测虽然能获取较为精确的深度信息,但是点云较为稀疏,信息量较少。因此,基于激光雷达与相机融合的方法进行3D物体检测在理论上可以弥补单个传感器各自的缺陷,从而到达更加优秀的性能。
MV3D就是融合了激光雷达点云和RGB图像数据从而在自动驾驶场景中进行3D物体的高精度检测,相比于仅用相机或者激光雷达的性能更好。
2.网络架构
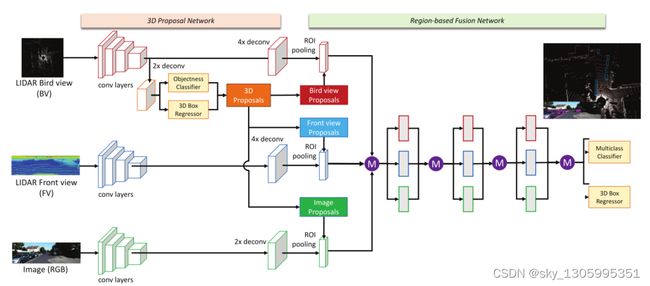
该网络主要由两个部分组成:3D Proposal Network(3D区域候选网络)和Region-based Fusion Network(区域融合网络)。
大致流程:分别提取激光雷达点云的俯视图特征、前视图特征以及相机图像特征,对点云的俯视图进行候选区域生成,然后分别与点云的俯视图、前视图以及相机图像进行融合,通过ROI pooling将不同的特征图大小整合成相同的大小,接着送入深度融合网络中。
2.1 点云数据处理
(1)点云俯视图
点云的俯视图是由点云的高度、点云的反射强度以及点云的密度这三种特征组成。
高度图:为了编码更详细的高度信息,将点云平均分为 M 个切片。为每个切片计算高度图,因此我们获得 M 个高度图。
强度图:每个单元格中具有最大高度的点的反射率值。其中,点云投影成二维网格时,每个网格的大小维0.1*0.1。
密度图:每个单元个中点云的数量。将每个格子中的点云数量转化成0~1之间的密度形式,即
m i n ( 1 , l o g ( N + 1 ) l o g ( 64 ) ) min(1,\frac{log(N+1)}{log(64)}) min(1,log(64)log(N+1))
因此,点云的俯视图特征由M个高度图、1个密度图以及1个强度图组成,(M+2,W,H)。
(2)点云前视图
将点云投影成圆柱形平面图像以生成密集的前视图,将点p=(x,y,z)转换成前视图中的坐标pfv=(r,c)
c = [ a t a n 2 ( y , x ) Δ θ ] r = [ a t a n 2 ( z , x 2 + y 2 ) Δ ϕ ] c=[\frac{atan2(y,x)}{\Delta\theta}] \\ r=[\frac{atan2(z,\sqrt{x^2+y^2})}{\Delta\phi}] c=[Δθatan2(y,x)]r=[Δϕatan2(z,x2+y2)]
其中,Δθ和ΔΦ分别表示激光束的水平和竖直方向的角度分辨率。
2.2 3D区域候选网络
3D候选区域网络是受到Faster R-CNN的启发而设计的,主要是在鸟瞰图上进行操作。鸟瞰图比前视图/图像平面有几个优势。首先,物体在投射到鸟瞰图时会保持物理尺寸,因此尺寸变化很小,而在前视图/图像平面中则不是这种情况。其次,鸟瞰视图中的物体占据不同的空间,从而避免了遮挡问题。第三,在道路场景中,由于物体通常位于地平面上并且垂直位置变化较小,因此鸟瞰图位置对于获得准确的 3D 边界框更为关键。因此,使用显式鸟瞰图作为输入使得 3D 位置预测更加可行。
类比2D的RPN网络,大致流程为先在鸟瞰图中生成物体的检测框(只判断前景与背景),然后通过NMS过滤掉一些候选框,接着进行3D候选框的位置回归。变化的参数是:
t = ( Δ x , Δ y , Δ z , Δ l , Δ w , Δ h ) t=(\Delta x, \Delta y, \Delta z, \Delta l, \Delta w,\Delta h) t=(Δx,Δy,Δz,Δl,Δw,Δh)
前三个点表示物体的中心偏移,后三个点表示
Δ s = l o g s G T s a n c h o r s ∈ ( l , w , h ) \Delta s=log\frac{s_{GT}}{s_{anchor}} \\ s\in(l,w,h) Δs=logsanchorsGTs∈(l,w,h)
同时设置了4个方向的锚框{0o,90o},在鸟瞰图下回归候选框后,可以通过(x,y)坐标转换到3D世界中,其中z方向的高度可以根据相机中的物体高度以及相机的安装高度获得。
候选生成中使用交叉熵进行分类损失计算,3D框回归使用smoothL1计算。
针对检测小物体较为困难的问题,在候选网络的最后一个卷积层使用2x bilinear upsampling。
在区域候选网络训练过程中,对正负样本分类的指标是IOU,大于0.7的归为正样本,小于0.5的归为负样本。
由于激光雷达点云较为稀疏,因此通过计算占用图上的积分图像来删除空锚点以减小计算量。
2.3 区域融合网络
在输入到区域融合网络前需要将每个视图的特征图大小通过ROI pooling调整到同一大小。
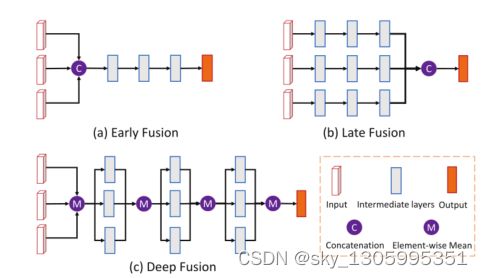

常见的融合方法大都为前融合与后融合。
前融合
![]()
后融合
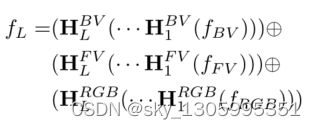
MV3D的深度融合受到《Deeply-fused nets》的启发,深度融合不仅对最终特征表示进行特征融合,而且对中间特征表示进行特征融合。该论文中表示深度融合网络在前向和后向传播过程的计算复杂度几乎等于所有基础网络的复杂度,元素添加成本可以忽略不计,因此不会引入额外的参数,也不会增加计算复杂度。
深度融合通常选择一个非常深的网络,以及一个较浅(也可能是深)的网络,其中每个块仅包含一个卷积层,具有几个块/融合(例如,每个块对应一个尺度)。因此,计算复杂度大约等于非常深的网络的计算复杂度。

深度融合网络的优点:
(1)结合多尺度表示的能力:因为深度融合网络可以由许多不同的基础网络组成,不同网络的感受野可以不同。
(2)改善信息流:因为融合网络中不同块的大小可能不同,这意味着更深的基础网络的中间层到输出层变得更短。从输入到中间层和从中间层到输出的信息流都得到了改善,有利于训练深度网络。

在MV3D的深度融合网络中使用了drop-path和auxiliary losses来进行网络正则化。
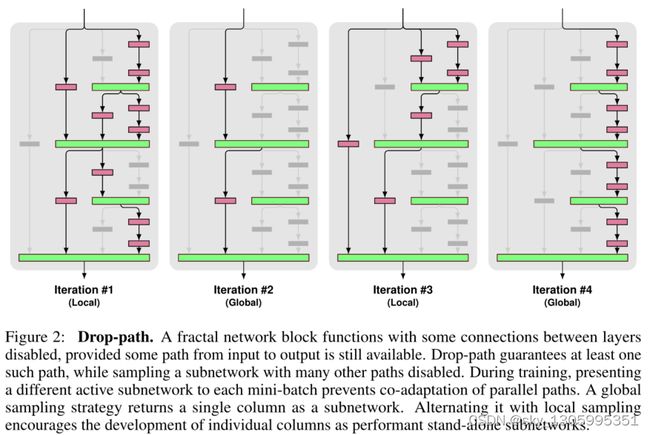
drop-path 通过随机丢弃连接层的操作数来阻止并行路径的协同适应。如果不加以阻止,则容易出现过度拟合。
局部丢弃:连接以固定概率丢弃每个输入,但我们确保至少有一个存活。
全局丢弃:整个网络选择一条路径。我们将此路径限制为单列,从而将各个列提升为独立的强预测因子。
同时信息可能需要适当的重新调整,使用element-wise means,仅仅计算每个连接的激活输入的均值。也就是MV3D中深度融合网络中的M。
MV3D的深度融合网络中还添加了auxiliary losses(辅助损失),它与主网络具有相同的层数,并且相应层共享权重。
2.4 网络结构细节
- 通道数减少到原始VGG-16的一半;
- 在输入到候选区域网络前对特征图进行2x billinear upsampling layer;
- 删除原始VGG-16的第4个池化层;
- 在BV/FV/RGB送入ROI pooling之前添加4X/4X/2X上采样层;
- 在多视图融合网络中,除了原始的 fc6 和 fc7 层之外,我们还添加了一个额外的全连接层 fc8。
刚接触3D目标检测不久,不足之处,请各位大佬指正。