论文翻译《Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds》

Abstract
Lidar based 3D object detection is inevitable for autonomous driving, because it directly links to environmental understanding and therefore builds the base for prediction and motion planning. The capacity of inferencing highly sparse 3D data in real-time is an ill-posed problem for lots of other application areas besides automated vehicles, e.g. augmented reality, personal robotics or industrial automation. We introduce Complex-YOLO, a state of the art real-time 3D object detection network on point clouds only. In this work, we describe a network that expands YOLOv2, a fast 2D standard object detector for RGB images, by a specific complex regression strategy to estimate multi-class 3D boxes in Cartesian space. Thus, we propose a specific Euler-RegionProposal Network (E-RPN) to estimate the pose of the object by adding an imaginary and a real fraction to the regression network. This ends up in a closed complex space and avoids singularities, which occur by single angle estimations. The E-RPN supports to generalize well during training. Our experiments on the KITTI benchmark suite show that we outperform current leading methods for 3D object detection specifically in terms of efficiency. We achieve state of the art results for cars, pedestrians and cyclists by being more than five times faster than the fastest competitor. Further, our model is capable of estimating all eight KITTIclasses, including Vans, Trucks or sitting pedestrians simultaneously with high accuracy.
基于激光雷达的 3D 物体检测对于自动驾驶来说是不可避免的,因为它与环境理解直接相关,因此为预测和运动规划奠定了基础。 实时推断高度稀疏的 3D 数据的能力对于除自动驾驶汽车之外的许多其他应用领域来说是一个不适定的问题,例如 增强现实、个人机器人或工业自动化。 我们介绍了 Complex-YOLO,这是一种仅在点云上进行的最先进的实时 3D 对象检测网络。 在这项工作中,我们描述了一个扩展 YOLOv2(一种用于 RGB 图像的快速 2D 标准对象检测器)的网络,通过特定的复杂回归策略来估计笛卡尔空间中的多类 3D 框。 因此,我们提出了一个特定的 Euler-RegionProposal Network (E-RPN),通过向回归网络添加虚部和实部来估计对象的姿态。 这最终会出现在一个封闭的复数空间中,并避免了单角度估计时出现的奇异点。 E-RPN 支持在训练期间很好地泛化。 我们在 KITTI 基准套件上的实验表明,我们在效率方面优于当前领先的 3D 对象检测方法。 通过比最快的竞争对手快五倍以上,我们为汽车、行人和骑自行车的人取得了最先进的成果。 此外,我们的模型能够同时高精度地估计所有八个 KITTI 类别,包括货车、卡车或坐着的行人。
1 Introduction
Point cloud processing is becoming more and more important for autonomous driving due to the strong improvement of automotive Lidar sensors in the recent years. The sensors of suppliers are capable to deliver 3D points of the surrounding environment in real-time. The advantage is a direct measurement of the distance of encompassing objects [1]. This allows us to develop object detection algorithms for autonomous driving that estimate the position and the heading of different objects accurately in 3D [2] [3] [4] [5] [6] [7] [8] [9]. Compared to images, Lidar point clouds are sparse with a varying density distributed all over the measurement area. Those points are unordered, they interact locally and could mainly be not analyzed isolated. Point cloud processing should always be invariant to basic transformations [10] [11].
由于近年来汽车激光雷达传感器的大力改进,点云处理对于自动驾驶变得越来越重要。 供应商的传感器能够实时提供周围环境的 3D 点。 优点是直接测量包围物体的距离[1]。 这使我们能够开发用于自动驾驶的物体检测算法,该算法可以在 3D [2] [3] [4] [5] [6] [7] [8] [9] 中准确估计不同物体的位置和方向。 与图像相比,激光雷达点云稀疏,分布在整个测量区域的密度各不相同。 这些点是无序的,它们在本地相互作用,主要不能孤立地分析。 点云处理应始终对基本变换保持不变 [10] [11]。

In general, object detection and classification based on deep learning is a well known task and widely established for 2D bounding box regression on images [12] [13] [14] [15] [16] [17] [18] [19] [20] [21]. Research focus was mainly a tradeoff between accuracy and efficiency. In regard to automated driving, efficiency is much more important. Therefore, the best object detectors are using region proposal networks (RPN) [3] [22] [15] or a similar grid based RPN-approach [13]. Those networks are extremely efficient, accurate and even capable of running on a dedicated hardware or embedded devices. Object detections on point clouds are still rarely, but more and more important. Those applications need to be capable of predicting 3D bounding boxes. Currently, there exist mainly three different approaches using deep learning [3 ]:
一般来说,基于深度学习的对象检测和分类是一项众所周知的任务,并广泛应用于图像上的 2D 边界框回归 [12] [13] [14] [15] [16] [17] [18] [19] [20] [21]。 研究重点主要是准确性和效率之间的权衡。 对于自动驾驶而言,效率更为重要。 因此,最好的物体检测器使用区域提议网络 (RPN) [3] [22] [15] 或类似的基于网格的 RPN 方法 [13]。 这些网络非常高效、准确,甚至能够在专用硬件或嵌入式设备上运行。 点云上的对象检测仍然很少,但越来越重要。 这些应用程序需要能够预测 3D 边界框。 目前,主要存在三种不同的深度学习方法 [3]:
- Direct point cloud processing using Multi-Layer-Perceptrons [5] [10] [11] [23] [24 使用多层感知器的直接点云处理
- Translation of Point-Clouds into voxels or image stacks by using Convolutional Neural Networks (CNN) [2] [3] [4] [6] [8] [9] [25] [26] 使用卷积神经网络 (CNN) 将点云转换为体素或图像堆栈
- Combined fusion approaches [2] [7] 组合融合方法
1.1 Related Work
Recently, Frustum-based Networks [5] have shown high performance on the KITTI Benchmark suite. The model is ranked1 on the second place either for 3D object detections, as for birds-eye-view detection based on cars, pedestrians and cyclists. This is the only approach, which directly deals with the point cloud using Point-Net [10] without using CNNs on Lidar data and voxel creation. However, it needs a pre-processing and therefore it has to use the camera sensor as well. Based on another CNN dealing with the calibrated camera image, it uses those detections to minimize the global point cloud to frustum-based reduced point cloud. This approach has two drawbacks: i). The models accuracy strongly depends on the camera image and its associated CNN. Hence, it is not possible to apply the approach to Lidar data only; ii). The overall pipeline has to run two deep learning approaches consecutive, which ends up in higher inference time with lower efficiency. The referenced model runs with a too low frame-rate at approximately 7fps on a NVIDIA GTX 1080i GPU [1].
最近,基于 Frustum 的网络 [5] 在 KITTI 基准套件上表现出高性能。 无论是 3D 物体检测,还是基于汽车、行人和骑自行车的人的鸟瞰图检测,该模型都排在第二位。 这是唯一的方法,它使用 Point-Net [10] 直接处理点云,而不在激光雷达数据和体素创建上使用 CNN。 但是,它需要预处理,因此也必须使用相机传感器。 基于另一个处理校准相机图像的 CNN,它使用这些检测将全局点云最小化为基于视锥体的减少点云。 这种方法有两个缺点:i)。 模型精度在很大程度上取决于相机图像及其相关的 CNN。 因此,不可能将该方法仅应用于激光雷达数据; ii). 整个管道必须连续运行两种深度学习方法,最终导致推理时间更长,效率更低。 参考模型在 NVIDIA GTX 1080i GPU [1] 上以大约 7fps 的过低帧率运行。
In contrast, Zhou et al. [3] proposed a model that operates only on Lidar data.
In regard to that, it is the best ranked model on KITTI for 3D and birds-eyeview detections using Lidar data only. The basic idea is an end-to-end learning that operates on grid cells without using hand crafted features. Grid cell inside features are learned during training using a Pointnet approach [10]. On top builds up a CNN that predicts the 3D bounding boxes. Despite the high accuracy, the model ends up in a low inference time of 4fps on a TitanX GPU [3].
相比之下,周等人。 [3] 提出了一个仅对激光雷达数据进行操作的模型。
在这方面,它是 KITTI 上排名最高的模型,用于仅使用激光雷达数据进行 3D 和鸟瞰检测。 基本思想是一种端到端的学习,它在不使用手工制作的特征的情况下对网格单元进行操作。 在训练期间使用 Pointnet 方法学习网格单元内部的特征 [10]。 在顶部构建一个预测 3D 边界框的 CNN。 尽管精度很高,但该模型在 TitanX GPU [3] 上以 4fps 的低推理时间结束。
Another highly ranked approach is reported by Chen et al. [5]. The basic idea is the projection of Lidar point clouds into voxel based RGB-maps using handcrafted features, like points density, maximum height and a representative point intensity [9]. To achieve highly accurate results, they use a multi-view approach based on a Lidar birds-eye-view map, a Lidar based front-view map and a camera based front-view image. This fusion ends up in a high processing time resulting in only 4fps on a NVIDIA GTX 1080i GPU. Another drawback is the need of the secondary sensor input (camera).
Chen 等人报道了另一种排名靠前的方法。 [5]。 基本思想是使用手工制作的特征将激光雷达点云投影到基于体素的 RGB 地图中,例如点密度、最大高度和代表性点强度 [9]。 为了获得高度准确的结果,他们使用了基于激光雷达鸟瞰图、基于激光雷达的前视图和基于摄像头的前视图图像的多视图方法。 这种融合最终需要很长的处理时间,导致在 NVIDIA GTX 1080i GPU 上只有 4fps。 另一个缺点是需要辅助传感器输入(相机)。
1.2 Contribution
To our surprise, no one is achieving real-time efficiency in terms of autonomous driving so far. Hence, we introduce the first slim and accurate model that is capable of running faster than 50fps on a NVIDIA TitanX GPU. We use the multi-view idea (MV3D) [5] for point cloud pre-processing and feature extraction. However, we neglect the multi-view fusion and generate one single birds-eye-view RGB-map (see Fig. 1) that is based on Lidar only, to ensure efficiency.
令我们惊讶的是,到目前为止,没有人在自动驾驶方面实现实时效率。 因此,我们推出了第一个能够在 NVIDIA TitanX GPU 上以超过 50fps 的速度运行的纤薄而准确的模型。 我们使用多视图思想 (MV3D) [5] 进行点云预处理和特征提取。 然而,我们忽略了多视图融合并生成一个仅基于激光雷达的单一鸟瞰图 RGB 地图(见图 1),以确保效率。
On top, we present Complex-YOLO, a 3D version of YOLOv2, which is one of the fastest state-of-the-art image object detectors [13]. Complex-YOLO is supported by our specific E-RPN that estimates the orientation of objects coded by an imaginary and real part for each box. The idea is to have a closed mathematical space without singularities for accurate angle generalization. Our model is capable to predict exact 3D boxes with localization and an exact heading of the objects in real-time, even if the object is based on a few points (e.g. pedestrians).
Therefore, we designed special anchor-boxes. Further, it is capable to predict all eight KITTI classes by using only Lidar input data. We evaluated our model on the KITTI benchmark suite. In terms of accuracy, we achieved on par results for cars, pedestrians and cyclists, in terms of efficiency we outperform current leaders by minimum factor of 5. The main contributions of this paper are:
最重要的是,我们展示了 YOLOv2 的 3D 版本 Complex-YOLO,它是最快的最先进的图像对象检测器之一 [13]。 Complex-YOLO 由我们特定的 E-RPN 支持,该 E-RPN 估计由每个框的虚部和实部编码的对象的方向。 这个想法是拥有一个没有奇点的封闭数学空间,以实现精确的角度泛化。 我们的模型能够实时预测具有定位的精确 3D 框和物体的精确方向,即使物体基于几个点(例如行人)。
因此,我们设计了特殊的锚盒。 此外,它能够仅使用激光雷达输入数据来预测所有八个 KITTI 类别。 我们在 KITTI 基准套件上评估了我们的模型。 在准确性方面,我们对汽车、行人和骑自行车的人取得了可比的结果,在效率方面,我们以最小的 5 倍领先当前领先者。 本文的主要贡献是:
- This work introduces Complex-YOLO by using a new E-RPN for reliable angle regression for 3D box estimation.
- We present real-time performance with high accuracy evaluated on the KITTI benchmark suite by being more than five times faster than the current leading models.
- We estimate an exact heading of each 3D box supported by the E-RPN that enables the prediction of the trajectory of surrounding objects.
- Compared to other Lidar based methods (e.g. [3]) our model efficiently estimates all classes simultaneously in one forward path.
1. 这项工作通过使用新的 E-RPN 来引入 Complex-YOLO,用于 3D 框估计的可靠角度回归。
2. 我们在 KITTI 基准套件上评估的高精度实时性能比当前领先模型快五倍以上。
3. 我们估计 E-RPN 支持的每个 3D 框的精确航向,从而能够预测周围物体的轨迹。
4. 与其他基于激光雷达的方法(例如 [3])相比,我们的模型在一个前向路径中同时有效地估计所有类别。
2 Complex-YOLO
This section describes the grid based pre-processing of the point clouds, the specific network architecture, the derived loss function for training and our efficiency design to ensure real-time performance.
本节描述了基于网格的点云预处理、特定的网络架构、用于训练的派生损失函数以及我们确保实时性能的效率设计。
2.1 Point Cloud Preprocessing

由 Velodyne HDL64 激光扫描仪 [1] 获取的单帧 3D 点云转换为单个鸟瞰图 RGB 地图,覆盖区域正前方 80m x 40m(见图 4) 传感器的起源。 受陈等人的启发。 (MV3D) [5],RGB-map 由高度、强度和密度编码。
网格图的大小定义为 n = 1024 和 m = 512。因此,我们将 3D 点云投影并离散化为分辨率约为 g = 8cm 的 2D 网格。 与 MV3D 相比,我们略微减小了单元格大小以实现更少的量化误差,同时具有更高的输入分辨率。
由于效率和性能原因,我们只使用一个而不是多个高度图。 因此,针对覆盖区域Ω内的整个点云P∈R3计算所有三个特征通道(zr,zg,zb,zr,g,b∈Rm×n)。 我们考虑 PΩ 原点内的 Velodyne 并定义:
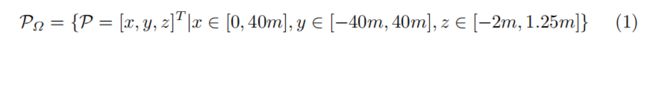

2.2 Architecture
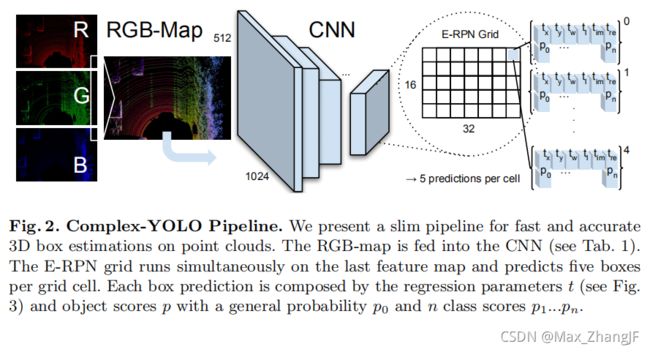
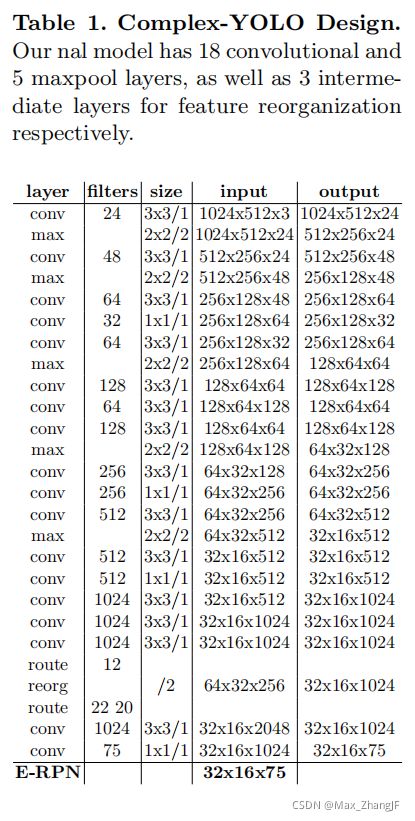
The Complex-YOLO network takes a birds-eye-view RGB-map (see section 2.1) as input. It uses a simplified YOLOv2 [13] CNN architecture (see Tab. 1), extended by a complex angle regression and E-RPN, to detect accurate multi-class oriented 3D objects while still operating in real-time.
Complex-YOLO 网络以鸟瞰图 RGB-map(见 2.1 节)作为输入。 它使用简化的 YOLOv2 [13] CNN 架构(见表 1),通过复杂的角度回归和 E-RPN 进行扩展,以检测准确的面向多类的 3D 对象,同时仍然实时运行。
Euler-Region-Proposal. Our E-RPN parses the 3D position bx,y, object dimensions (width bw and length bl) as well as a probability p0, class scores p1…pn
and finally its orientation bφ from the incoming feature map. In order to proper orientation, we have modified the commonly used Grid-RPN approach, by adding a complex angle arg(|z|e ibφ ) to it:
Euler-Region-Proposal。我们的E-RPN解析3D位置bx,y,对象di mentions(宽度bw和长度bl)以及概率p0,类得分p1…pn
最后根据进入的特征图确定其方位bφ。为了正确的定位,我们对常用的Grid-RPN方法进行了修改,添加了一个复角arg(|z|e ibφ):
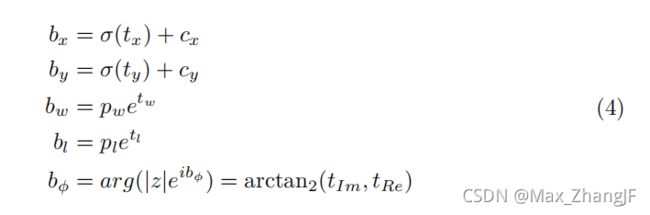
With the help of this extension the E-RPN estimates accurate object orientations based on an imaginary and real fraction directly embedded into the network. For each grid cell (32x16 see Tab. 1) we predict five objects including a probability score and class scores resulting in 75 features each, visualized in Fig. 2.
在此扩展的帮助下,E-RPN 基于直接嵌入网络的虚部和实部来估计准确的对象方向。 对于每个网格单元(32x16 见表 1),我们预测五个对象,包括概率分数和类别分数,每个对象有 75 个特征,如图 2 所示。
Anchor Box Design. The YOLOv2 object detector [13] predicts five boxes per grid cell. All were initialized with beneficial priors, i.e. anchor boxes, for better convergence during training. Due to the angle regression, the degrees of freedom, i.e. the number of possible priors increased, but we did not enlarge the number of predictions for efficiency reasons.
Hence, we defined only three different sizes and two angle directions as priors, based on the distribution of boxes within the KITTI dataset: i) vehicle size (heading up); ii) vehicle size (heading down); iii) cyclist size (heading up); iv) cyclist size (heading down); v) pedestrian size (heading left).
锚盒设计。 YOLOv2 对象检测器 [13] 预测每个网格单元有五个框。 所有都用有益的先验初始化,即锚框,以便在训练期间更好地收敛。 由于角度回归,自由度,即可能的先验数量增加,但出于效率原因,我们没有扩大预测数量。
因此,我们根据 KITTI 数据集中的框的分布,仅将三种不同的尺寸和两个角度方向定义为先验:i) 车辆尺寸(朝上); ii) 车辆尺寸(朝下); iii) 骑车人的体型(抬头); iv) 骑自行车者的体型(低头); v) 行人尺寸(向左行驶)。
Complex Angle Regression. The orientation angle for each object bφ can be computed from the responsible regression parameters tim and tre, which correspond to the phase of a complex number, similar to [27]. The angle is given simply by using arctan2(tim, tre). On one hand, this avoids singularities, on the other hand this results in a closed mathematical space, which consequently has an advantageous impact on generalization of the model.
We can link our regression parameters directly into the loss function (7).
复角回归。 每个对象的方向角 bφ 可以根据相关的回归参数 tim 和 tre 计算,它们对应于复数的相位,类似于 [27]。 使用 arctan2(tim, tre) 可以简单地给出角度。 一方面,这避免了奇点,另一方面,这导致封闭的数学空间,因此对模型的泛化具有有利影响。
我们可以将回归参数直接链接到损失函数 (7) 中。
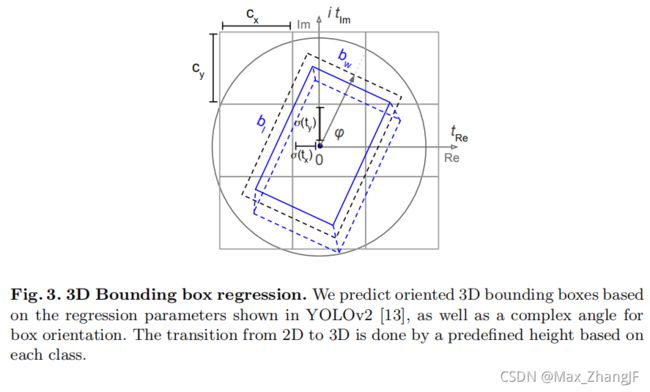
2.3 Loss Function
Our network optimization loss function L is based on the the concepts from YOLO [12] and YOLOv2 [13], who defined LYolo as the sum of squared errors using the introduced multi-part loss. We extend this approach by an Euler regression part LEuler to get use of the complex numbers, which have a closed mathematical space for angle comparisons. This neglect singularities, which are common for single angle estimations:
我们的网络优化损失函数 L 基于 YOLO [12] 和 YOLOv2 [13] 的概念,他们使用引入的多部分损失将 LYolo 定义为平方误差的总和。 我们通过欧拉回归部分 LEuler 扩展了这种方法,以使用复数,这些复数具有用于角度比较的封闭数学空间。 这忽略了奇异点,这在单角度估计中很常见:
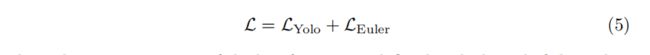
The Euler regression part of the loss function is defined with the aid of the Euler-Region-Proposal (see Fig. 3). Assuming that the difference between the complex numbers of prediction and ground truth, i.e. |z|eibφ and |zˆ|eiˆbφ is always located on the unit circle with |z| = 1 and |zˆ| = 1, we minimize the absolute value of the squared error to get a real loss:
损失函数的 Euler 回归部分是在 Euler-Region-Proposal 的帮助下定义的(见图 3)。 假设预测的复数和ground truth的差值,即|z|eibφ和|zˆ|eiˆbφ总是位于|z|的单位圆上。 = 1 和 |zˆ| = 1,我们最小化平方误差的绝对值以获得真正的损失:
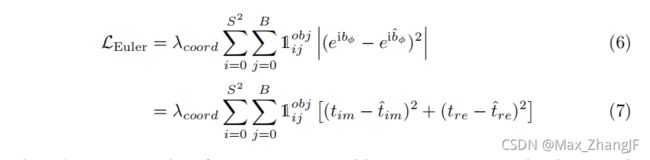

2.4 Efficiency Design
The main advantage of the used network design is the prediction of all bounding boxes in one inference pass. The E-RPN is part of the network and uses the output of the last convolutional layer to predict all bounding boxes. Hence, we only have one network, which can be trained in an end-to-end manner without specific training approaches. Due to this, our model has a lower runtime than other models that generate region proposals in a sliding window manner [22] with prediction of offsets and the class for every proposal (e.g. Faster R-CNN [15]).
In Fig. 5 we compare our architecture with some of the leading models on the KITTI benchmark. Our approach achieves a way higher frame rate while still keeping a comparable mAP (mean Average Precision). The frame rates were directly taken from the respective papers and all were tested on a Titan X or Titan Xp. We tested our model on a Titan X and an NVIDIA TX2 board to emphasize the real-time capability (see Fig. 5).
所用网络设计的主要优点是在一次推理过程中预测所有边界框。 E-RPN 是网络的一部分,它使用最后一个卷积层的输出来预测所有边界框。 因此,我们只有一个网络,可以在没有特定训练方法的情况下以端到端的方式进行训练。 因此,我们的模型比以滑动窗口方式生成区域提议的其他模型具有更低的运行时间 [22],并预测每个提议的偏移量和类别(例如 Faster R-CNN [15])。
在图 5 中,我们将我们的架构与 KITTI 基准测试中的一些领先模型进行了比较。 我们的方法实现了更高的帧速率,同时仍保持可比的 mAP(平均平均精度)。 帧速率直接取自各自的论文,并且都在 Titan X 或 Titan Xp 上进行了测试。 我们在 Titan X 和 NVIDIA TX2 板上测试了我们的模型,以强调实时能力(见图 5)。