Alexnet 学习笔记
Alexnet
放在开头:对特征工程、机器学习、计算机视觉感兴趣的同学可以加个关注,一起学习、一起交流、一起进步
图像分类问题上的经典之作,包含了很多重要的概念及网络训练的技巧
(ImageNet Classification with Deep Convilutional Neural Network–Alex Krizhevsky–加拿大多伦多大学)
发布在2012年的NIPS会议,机器学习领域的顶级会议,属于人工智能的A类会议,很受CV界的学者们关注。
1、论文研究背景、成果及意义
研究背景
神经网络的火爆离不开两个重要的条件(必要条件):
一个是大量的数据:LabelMe,ImageNet 等大的标注数据集的出现
因为神经网络包含大量的权重参数,如果训练数据不够大的话,会存在过拟合的问题
另一个是高性能的硬件:算力较强的 GPU 等
由于神经网络包含了大量的权重参数
如果硬件计算方面不够强
算法的训练会变得很漫长
2012 年的成果
LSVRC-2012分类大赛上取得冠军,错误率远低于当时最好的学习算法SIFT+FVS
意义
神经网络在图像上的研究优势
在现实生活中物体是具有多样性的,一个球在不同光照下及不同角度呈现中的状态,想要识别率更精准,那就需要更加庞大的训练数据以及更加复杂的拟合参数,神经网络相对于机器学习来说有更多的隐藏层并且包含了非线性变化,所以他有更强的拟合能力。
图像分类应用及神经网络训练流程
图像物体分类属于计算机视觉范畴非常重要的基础问题,也是图像分割、物体跟踪、行为分析等其他高层视觉任务的基础,所以想要入门计算机视觉,就必须要牢牢掌握图像分类的基础,把其中的原理吃透
简单的把深度学习分为两个阶段
第一个阶段为训练阶段
第二个阶段是测试阶段
训练阶段
就是使用大量的有标签图像数据来训练网络,通过优化算法不断迭代优化网络,使网络达到收敛。
测试阶段
就是使用测试数据测试一下训练出来的网络性能的好坏
如图:简单展示一下图像分类问题预测阶段的流程
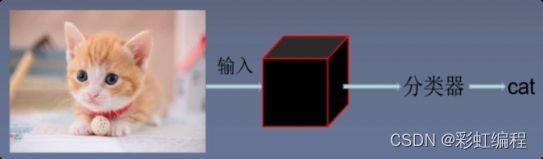
将图片输入到训练好的神经网络中,经过一系列的卷机池化层来提取图像的特征,然后将提取出来的特征输入到分类器中来匹配属于哪种类别
图像分类在我们生活中有哪些应用
活跃领域:
计算机视觉、模式识别与机器学习领域等
应用领域:
安防领域的人脸识别、行人检测、智能视频分析、行人跟踪等,
交通领域的交通场景物体识别、车辆计数、逆行检测、车牌检测与识别,
以及互联网领域的基于内容的图像检索、相册自动归类等
机器学习算法与深度学习算法在处理图像分类问题中处理流程有哪些区别

而且机器学习算法特征提取是人为提取很需要经验
深度学习算法使用的特征是通过自主学习获得,所以使用深度学习算法,可以节省大量人力
网络应用在图像分类的发展趋势
分类相关的技术发展趋势

在深度学习火爆之前:
- 一般使用机器学习方法来处理图像分类问题,经常使用到的特征为HOG特征、SIFT的特征等
2012年AlexNet出现之后:
- 使用神经网络处理图像分类问题开始流行之后并且尝试不断改进网络结构
2014年出现VGG、GoogLeNet等一系列的优秀网络结构
- 这些网络结构的特点是使用小卷积核并且结构变得更深更复杂,当然效果也更好,其中VGG网络表明网络深度可以提高网络性能,但是网络太深就会存在一些问题,就是当深度达到一定程度,会存在梯度难以传播的问题
2015年 何凯明大佬提出Resnet
- 成功解决了当深度达到一定程度,会存在梯度难以传播的问题,通过实践证明神经网络处理图像问题效果显著
2017 年 为了方便在嵌入式设备上使用神经网络
- 一些轻量级网络诞生,比如Mobilnet、ShuffleNet等,这些网络不仅计算参数少,而且效果也很好。具体改变的地方,可以查找相关论文阅读
自动搜索学习技术Auto ML
- 上边我们提到的网络都是大神设计出来的,设计一个网络很耗费人力物力,需要大量的专业知识,对于我们大部分人来说,设计一个网络是一个非常困难的问题,该如何解决?
- 网络参数及结构可以通过学习算法来得到,这样就不需要我们人为去设计网络结构和参数
每个人都能成为网络设计大师
- 网络参数及结构可以通过学习算法来得到,这样就不需要我们人为去设计网络结构和参数
总结:图像分类发展趋势
自动化趋势和轻量化趋势
自动化:使用网络算法自主设计网络结构
轻量化:网络所含的权重参数越来越少好
2、前期知识储备
- TensorFlow的基本使用方法及语法特点
- CNN、RELU、Pooling 的结构,掌握 CNN 的基本工作原理
- 神经网络处理图像分类的概念及流程
- softmax 函数及交叉熵的概念,从数学原理上理解为什么神经网络可以做图像分类
3、论文整体框架介绍
论文主要包括摘要、介绍、数据、网络结构,减少过拟合训练细节、结果、结果定量分析等部分
摘要部分:
- 主要介绍了论文的成果及贡献,也就是paper的创新点。拿到一篇paper的时候,如果你想快速了解他的中心内容,读摘要(会介绍主要创新点和成果)就可以
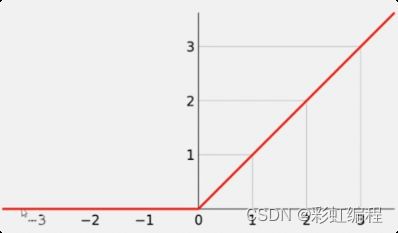
非线性单元 Relu
数学形式:
f(x)= max(0,x)
TensorFlow 例子:
tf.nn.relu(features,name=None)
# 定义恒定值的 tensor a
a = tf.constant([-1.0,2.0])
# 创建会话
with tf.Session() as sess:
# 进行 relu 操作
b = tf.nn.relu(a,name='relu')
# 输出结果
print sess.run(b)
Relu优点:
1.可以使网络训练更快
2.增加网络的非线性
3.防止梯度消失(弥散)
4.使网络具有稀疏性
考虑到梯度下降的训练时间,这些饱和的非线性激活函数比非饱和非线性激活函数f(x):max(0,x)训练更慢。
什么是饱和的非线性激活函数、非饱和的非线性激活函数
采用ReLU的深度卷积神经网络训练时间比等价的tanh单元要快几倍。
非线性单元Relu优点详解
-
可以使网络训练更快(激活函数求导简单,可以减少反向传播的时间)
相比于tanh,sigmod而言,relu的导数更好求,反向传播会涉及到激活函数的求导,
tanh,sigmod包含指数且表达式复杂,他们的函数的导数求取慢一些。
-
增加网络 非线性
relu为非线性函数,加入到神经网络中可以使网络拟合非线性的映射,因此增加了网络的非线性。 -
防止梯度消失(弥散)
当数值过大或者过小时,sigmoid, tanh导数接近0,会导致反向传播时候梯度消失的问题,relu为非饱和激活函数不存在此问题。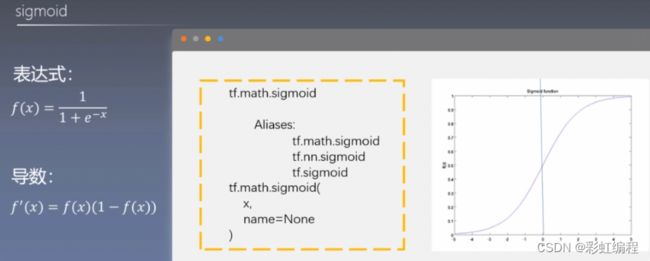
-
使网络具有稀疏性
relu可以使一些神经元输出为0,因此可以增加网络的稀疏性。
Dropout 层
作用:随机将一定比例的神经元置为0
实质就是
随机的断掉了一些神经元之间的连接,Dropout经常用在全连接层之后,对于一个有N个节点的神经网络,有了dropout后,就可以看做是2n个模型的集合了相当于机器学习中的模型融合ensemble,相当于机器学习中的特征融合的作用可以提高网络精度和泛化能力
introduction部分
- 主要介绍了图像分类问题的背景
The Dataset
- 主要介绍了ILSVRC与Imagenet数据集合
The Architecture
- 主要介绍了网络的组成并且详细介绍了论文的创新点,比如使用了RELU、LRN与多卡训练等方法
Reduce overfiting部分
- 主要介绍了防过拟合技术,这部分比较重要,防过拟合技术需要大家掌握
Details of learning部分
- 主要给出了网络超参数的设置及权重、初始化方式
Results的部分
- 主要介绍了paper的成果
最后是实验部分与讨论部分
- 关注实验部分就可以,学习一下做实验的思路和方法,以后可以用在自己的研究上
4、神经网络处理图像分类问题流程
主要是从原理的角度来讲解图像分类具体流程
数据集
训练集、测试集、验证集合
训练集:来让网络进行参数学习
验证集:来测试网络训练的效果看看有没有过拟合或者欠拟合。可以根据验证集合的表现来调整网络参数和结构
测试集:主要是测试一下精确度和泛化能力
训练阶段:

网络的优化方式可以选sgd或adam的
softmax 和 loss function
softmax 层将 FC 层的输出转化为概率。loss function 衡量预测值和真实值之间的差距。
模型衡量标准
- 准确率
- 召回率
- top-1error
- 取概率向量里面最大的那一个作为预测结果,如果结果分类正确,则预测正确,否则预测错误
- top-5error
- 取概率向量里面前五个大的作为预测结果,预测结果中只要出现了正确类别,即为预测正确否则预测错误
5、网络及部分参数计算
主要讲解Alexnet的具体结构,计算的参数包括可训练的参数数量及结构中的连接数量
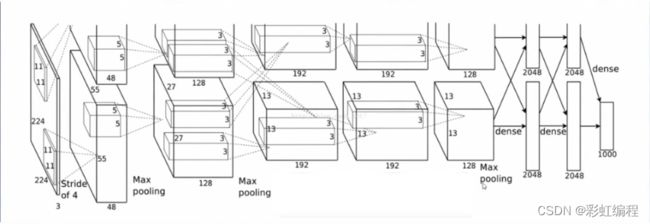
论文中的结构图
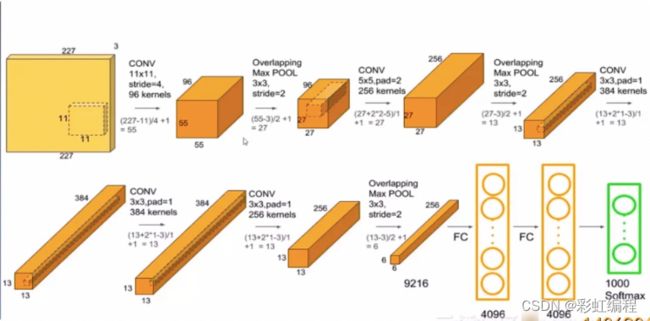
拆解之后的图
网络结构:
conv1 relu1 norm1–> pooll–> conv2 relu2 norm2–> pool2–> conv3 relu3 -->conv4 relu4 -->conv5 relu5 -->pool5 -->fc6 relu6 droupout6–> fc7 relu7 droupout7–> fc8 (logits,即没有经过归一化的概率分布,也即最终的特征分布) -->softmax
卷积细节:
1.输入特征map的通道数是多少,卷积核的通道就是多少,这个数值一般情况是相等的。
2.有多少个卷积核就有多少个输出特征map
卷积特征图通用计算方式:
F o = ⌊ F i n + 2 p − k s ⌋ + 1 F_o = \lfloor \frac {F_{in} + 2p - k}{s} \rfloor+1 Fo=⌊sFin+2p−k⌋+1
-
卷积方式
- SAME:
F o = ⌈ F i n − k + 1 s ⌉ F_o=\lceil \frac {F_{in} - k + 1}{s} \rceil Fo=⌈sFin−k+1⌉
- VALID:
F o = ⌈ F i n s ⌉ F_o = \lceil \frac{F_{in}}{s} \rceil Fo=⌈sFin⌉
- SAME:
连接数量计算公式:
F o 2 ∗ ( K 2 ∗ K c + 1 ) ∗ F o c F_o^2*(K^2*K_c+1)*F_{oc} Fo2∗(K2∗Kc+1)∗Foc
- 输出特征图尺寸X(卷积核大小X卷积核通道+1)X输出特征图通道数
池化层也相当于卷积(但是没有参数),池化只改变特征图的大小,不改变特征图的通道数
6、网络超参数及训练
主要为网络超参数的具体数据介绍及AlexNet采取了哪些训练策略
训练时数据的处理技巧
1.随机地从256 X 256的原始图像中截取224 X 224大小的区域(以及水平翻转及镜像),相当于增加了2*(256-224)^2=2048倍的数据量。
如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用数据增强后可以大大减轻过拟合,提升泛化能力。
2.对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
3.在测试的时候,取图片的四个角加中间五个位置,并且进行左右翻转,也就是一共获得了10张图片,分别对他们进行预测,并对得到了10次结果求平均值作为最后的预测结果
| 名称 | 函数 |
|---|---|
| datas numbers 数据量 |
训练使用的总数据量,比如数据一共包含64万图片那么总数据量就是64万 |
| batchsize 批量大小 |
每次输入到网络的数据量,比如一次输入到网络64张图片batchsize=64 |
| steps 迭代次数 |
网络学习完所有数据需要的次数,比如batchsize=64,那么过完所有数据需要网络迭代一万次,steps=10000。即 数据量/批量大小=迭代次数 |
| epoch 轮数 |
网络学习一遍所有数据为一个epoch |
7、Alexnet 网络的特点
- 成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了 Sigmoid在网络较深时的梯度弥散问题。
- 训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet 将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
- 在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。(后来的vgg证明这个作用不大)
- 使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX 580 GPU进行训练,同时AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
- 数据增强,随机地从256*256的原始图像中截取224-224大小的区域(以及水平翻转的镜像)对图像数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
重点代码详解
功能:
使用alxnet进行微调
工程名称:
finetune_alexnet_with_tensorflow
代码结构:
- finetune.py
- 主程序,包含了整个工程的完整流程
- datagenerator.py
- 数据产生程序,包含了数据的读取与去均值过程
- alexnet.py
- 定义了网络结构
- validate_alexnet_on_imagenet.ipynb
- 测试alxnet效果
- images文件夹
- 包含三张测试图片(来源于imagenet数据集合的测试集合)
网络结构
alexnet.py
- 定义了网络结构
命名空间的作用 命名空间可以使我们更好的管理变量,在tensorboard的显示时,网络结构也更加一目了然
def create(self):
# 网络结构定义
"""Create the network graph."""
# 1st Layer: Conv (w ReLu) -> Lrn -> Pool
conv1 = conv(self.X, 11, 11, 96, 4, 4, padding='VALID', name='conv1')
norm1 = lrn(conv1, 2, 2e-05, 0.75, name='norm1')
pool1 = max_pool(norm1, 3, 3, 2, 2, padding='VALID', name='pool1')
# 2nd Layer: Conv (w ReLu) -> Lrn -> Pool with 2 groups
conv2 = conv(pool1, 5, 5, 256, 1, 1, groups=2, name='conv2')
norm2 = lrn(conv2, 2, 2e-05, 0.75, name='norm2')
pool2 = max_pool(norm2, 3, 3, 2, 2, padding='VALID', name='pool2')
# 3rd Layer: Conv (w ReLu)
conv3 = conv(pool2, 3, 3, 384, 1, 1, name='conv3')
# 4th Layer: Conv (w ReLu) splitted into two groups
conv4 = conv(conv3, 3, 3, 384, 1, 1, groups=2, name='conv4')
# 5th Layer: Conv (w ReLu) -> Pool splitted into two groups
conv5 = conv(conv4, 3, 3, 256, 1, 1, groups=2, name='conv5')
pool5 = max_pool(conv5, 3, 3, 2, 2, padding='VALID', name='pool5')
# 6th Layer: Flatten -> FC (w ReLu) -> Dropout
flattened = tf.reshape(pool5, [-1, 6*6*256])
fc6 = fc(flattened, 6*6*256, 4096, name='fc6')
dropout6 = dropout(fc6, self.KEEP_PROB)
# 7th Layer: FC (w ReLu) -> Dropout
fc7 = fc(dropout6, 4096, 4096, name='fc7')
dropout7 = dropout(fc7, self.KEEP_PROB)
# 8th Layer: FC and return unscaled activations
self.fc8 = fc(dropout7, 4096, self.NUM_CLASSES, relu=False, name='fc8')
卷积层
def conv(x, filter_height, filter_width, num_filters, stride_y, stride_x, name,
padding='SAME', groups=1):
"""Create a convolution layer.
Adapted from: https://github.com/ethereon/caffe-tensorflow
"""
# Get number of input channels
input_channels = int(x.get_shape()[-1])
# Create lambda function for the convolution
convolve = lambda i, k: tf.nn.conv2d(i, k,
strides=[1, stride_y, stride_x, 1],
padding=padding)
with tf.variable_scope(name) as scope:
# Create tf variables for the weights and biases of the conv layer
weights = tf.get_variable('weights', shape=[filter_height,
filter_width,
input_channels/groups,
num_filters])
biases = tf.get_variable('biases', shape=[num_filters])
# 判断是否进行分组卷积操作,两个 GPU 上进行,分组判断
if groups == 1:
conv = convolve(x, weights)
# In the cases of multiple groups, split inputs & weights and
else:
# Split input and weights and convolve them separately
input_groups = tf.split(axis=3, num_or_size_splits=groups, value=x)
weight_groups = tf.split(axis=3, num_or_size_splits=groups,
value=weights)
output_groups = [convolve(i, k) for i, k in zip(input_groups, weight_groups)]
# Concat the convolved output together again
conv = tf.concat(axis=3, values=output_groups)
# Add biases
bias = tf.reshape(tf.nn.bias_add(conv, biases), tf.shape(conv))
# Apply relu function
relu = tf.nn.relu(bias, name=scope.name)
return relu
Dataset
Dataset APl:
tf.data APl 可以帮助我们构建灵活高效的输入流水线。将数据直接放在graph中进行处理,整体对数据集进行数据操作,使代码更加简洁。
# create dataset
# 根据输入的 tensors 创建数据集
data = Dataset.from_tensor_slices((self.img_paths, self.labels))
# distinguish between train/infer. when calling the parsing functions
# map 使用方式
# data = data.map(function,num_ parallel_calls=4)
# function对数据进行操作的西数 num. parallel.calls指定并行处理级别(根据cpu性能设置)
# prefetch:使数据处理过程更高效
# 可以合并使用
if mode == 'training':
data = data.map(self._parse_function_train, num_parallel_calls=4)
data = data.prefetch(buffer_size=batch_size * 100)
elif mode == 'inference':
data = data.map(self._parse_function_inference, num_parallel_calls=4)
data = data.prefetch(buffer_size=batch_size * 100)
else:
raise ValueError("Invalid mode '%s'." % (mode))
# shuffle the first `buffer_size` elements of the dataset
# buffer_size越大,数据就会越混乱
if shuffle:
data = data.shuffle(buffer_size=buffer_size)
# create a new dataset with batches of images
# 创建data 包含 batchsize 个 images
data = data.batch(batch_size)
self.data = data
TensorFlow.data iterator
# create an reinitializable iterator given the dataset structure
# 创建一个按照给定数据结构未初始化的迭代器
iterator = Iterator.from_structure(tr_data.data.output_types,
tr_data.data.output_shapes)
# 获取下一个batchsize的数据
next_batch = iterator.get_next()
# Ops for initializing the two different iterators
# 初始化数据迭代器
training_init_op = iterator.make_initializer(tr_data.data)
validation_init_op = iterator.make_initializer(val_data.data)
训练数据
测试模型
总结
Alexnet 相对于往常的模型的训练不同之处
| 问题 | 解决 |
|---|---|
| 网络过拟合 | 数据增强,dropout |
| Tanth,sigmoid 梯度消失训练速度慢 | 使用非饱和神经元 relu 等 |
| GPU 计算能力不够 | 多卡训练 |
实际工程中可能存在的问题
如何计算 modelsize()
loss 不变化或者为 nan
- loss 不变化,可以增大学习率。 nan减小学习率
出于实际的考虑
- 使用卷积代替 FC,FC 参数太多,容易过拟合,并且可能导致模型尺寸过大