AI TALK | 神经网络计算加速:模型量化与低功耗IOT设备部署
神经网络由于参数量大,运算量大,往往在部署到IOT设备时会碰到储存空间不够,运算时长过长或者量化精度不够的问题。
针对这些问题,本文介绍了神经网络模型在轻量级设备的部署技巧,具体内容包括神经网络模型量化的基本原理和主要方法,以及部分低功耗IOT设备上模型部署的实例与技巧。
量化基本原理
量化本质上是数值范围的一种调整,目前主流的神经网络的量化主要是将fp32的一组数据映射到int8的范围内(也有研究int6 int4甚至int2的 本文不做讨论),(如下图数据所示)。且由下表格可知,int8的表示范围和步长均不如fp32,会造成精度损失,而如何降低精度损失,正是本文想要说明的主要问题之一。
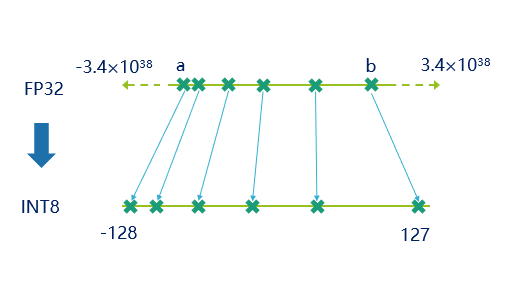

其次我们需要了解的是为什么要进行量化,它的优势是什么。
由于神经网络对于噪声是不敏感的,因此可以对其进行量化,好的量化并不会造成精度的损失,而且可以实现相比于浮点模型大约1/4的内存占用。此外,由于量化后的模型大部分是整数类型的,在使用NPU进行推理的时候往往会比浮点类型快很多。此外,相较于浮点运算,定点int8每次计算的能量消耗少很多,而这对于低功耗嵌入式设备来说是非常关键的。

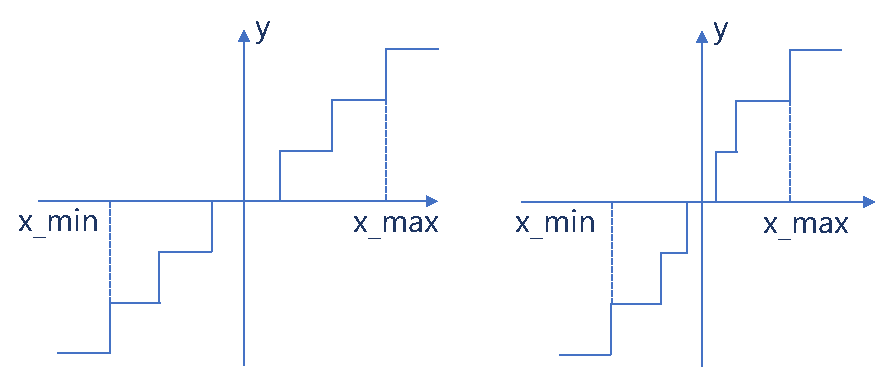
量化原理可以分为两大类,分别是非均匀量化和均匀量化,非均匀量化主要指的是,量化的步长不是均匀的,而均匀量化指的是量化的步长是均匀的。两种量化对比如下图所示。
对于均匀量化,主要可以用以下的公式1来表示。式中x表示浮点的输入, x_int表示量化的输出,可以看到对于的每个输入,我们需要一组参数s与z来表示量化之后的数值。由于取整操作的存在,量化之后的数值与量化之前的数值会有误差(如公式2),因此如何根据实际情况选取s与z就至关重要。公式3表示的是将公式1代入公式2得到的量化反量化公式,在量化后训练中会经常用到。

非均匀量化目前主流的有两类,一类是VPU和DSP中经常使用的,将FP32转成FP16进行计算的量化,另一类就是指数量化。

这一类VPU和DSP中经常使用的,将FP32转成FP16进行计算的量化方式,可以表示的精度和范围,优点是可以表示的精度和范围比int8要大。然而,我们可以从下图中看出FP32与FP16的数据表示形式比一般整形复杂,因此需要如下图所示较为复杂的计算步骤,也就导致了硬件设计较为复杂,芯片成本较高。

另一类指数量化,将浮点数表示为2的幂次。如公式所示,我们可以先来分析常用网络,如mobilenetV2的某一层卷积层的权重分布,发现大部分权重都集中于-0.1到0.1之间,而数值较大的权重数量较少。

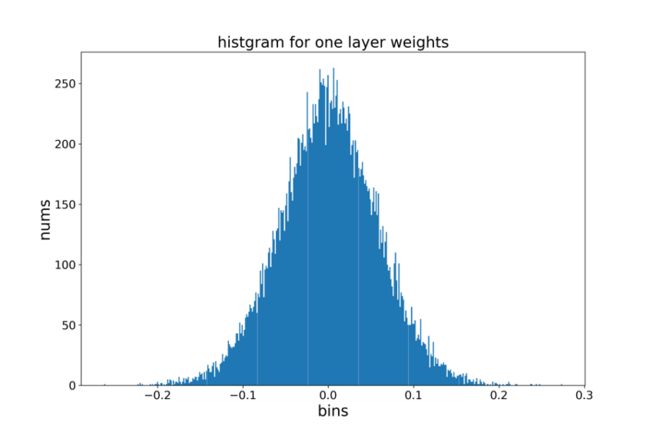
这种数据分布非常适合指数量化这种使用较多的比特来表示数值较小的数据,使用较少的比特来表示数值较大数据的量化方式。
因此指数量化在int8推理的时候精度表现较好,此外由于指数量化将浮点数表示为2的幂次,因此浮点数的相乘就可以转化为幂次的相加,这样推理的速度会变快。不过,由于每次量化反量化都需要计算log函数,因此这种量化方式需要特定的硬件来实现。

均匀量化主要分为3类,其中非常著名的一类是以tensorrt为代表的,目前许多开源框架在使用的一种量化方式。这种量化方式将下图公式1中z=0,只通过选取不同的量化上下界来求取s。量化的上下界可以使用KL散度,分位点等方法来求取。
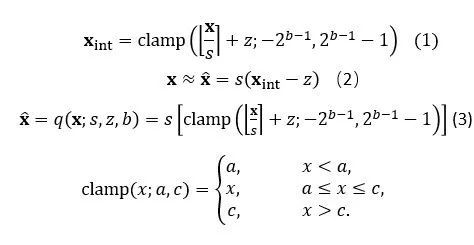
下图表中所示的是tensorRT这套量化方式在不同模型上面达到的效果(图引自NVIDIA GTC文档),可以看到使用这种办法在量化resnet50,resnet101等模型时都取得不错的效果。唯一美中不足的是没有测评比较适合移动端使用的网络比如mobilenet系列。

均匀量化的另一类是令前文图1中公式1中的z=0,并且将s设置为2的幂次的量化方式。这种量化的好处就是在进行量化计算的时候,直接使用移位即可以得到量化后的数值,计算速度快,不需要复杂的硬件支持。缺点是由于s只能选择2的幂次,导致精度较低。该量化方法常常需要使用量化后训练来调整模型精度。
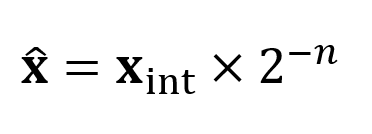
均匀量化的第三类就是以tensorflow-lite为代表的s与z都使用的量化方式。

目前pytorch也支持使用类似的方式。国内的IP供应商verisilicon所设计的IP也使用这种量化方式,支持tflite模型直接部署,精度与速度都不错。

量化主要方法
量化的主要的方法分为两类,一类是训练后量化,一类是量化训练。

在进行训练后量化时,主要考虑的有下列问题:
①量化粒度
有些读者可能会产生疑问,将一个FP32的数用int8来表示,还要再带上一个s以及一个z,数据量岂不是变多了?这就涉及到了量化粒度的概念。
实际上,我们进行量化操作的时候,一般的会使用同一组s与z对一个卷积核,甚至是一个通道或者一层进行量化,这样大量的数据都表示成为了int8,而只需要较少的参数就可以恢复fp32的精度,但是量化粒度越大,就会导致恢复的fp32数值与原数值差距越大,从而导致模型精度下降。

②合并BN
batchnorm层的计算如下图公式所示。可以看到BN层的操作基本上都是线性操作,可以将其等效的合入临近的卷积层来减少推理时候的运算量。
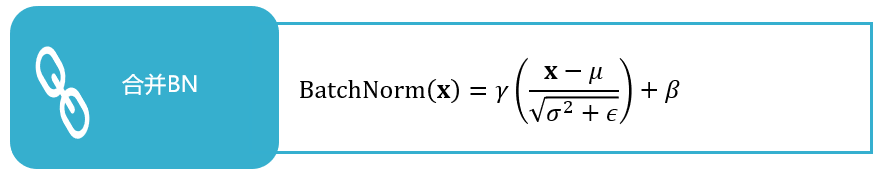
③对称量化以及非对称量化
假设使用非对称量化也就是z≠0的情况如公式所示,展开后可以看到有4项。蓝色的第三项和第四项为量化之后的参数和权重的组合,在推理时保持不变,可以提前计算出来,绿色的第二项与输入以及权重的z相关,黑色的第一项为对称量化z=0时候的公式。由此可见,假如我们令zw=0,则可以消去第二项这个计算量很大的项。由于实际中的权重基本上是0点对称的(即使不对称zw也很小),因此我们建议对于权重使用对称量化,对于激活x使用非对称量化。

在进行训练后量化的时候,另外一个需要权衡的问题是量化范围的选取。量化范围选取过大,精度就会略有不足,量化范围选取过小,就会导致量化后不能很好地表示浮点数的范围。进行量化范围的选择有三种较为常见的办法。

①最大最小值方法
直观的使用最大最小值来确定量化的范围,根据量化的范围到int8的映射来得到s参数。这种量化方法可以保证量化的范围不变,缺点是如果输入中有离群点的话会导致精度下降。
②最小均方误差方法
找到一组量化范围的上下界,使得量化之后数据的与原始数据之间的最小均方误差最小。
③交叉熵方法
找到一组量化范围的上下界,使得量化之后数据的与原始数据之间的交叉熵最小。
使用MSE方法通常可以得到较好的精度,但是对于分类网络的最后一层全连接层来说,由于我们只关心众多分类输出中的某一项输出,而我们使用MSE方法计算误差的时候所有通道都会算入,此时MSE方法的精度表现不如交叉熵好。
在训练后量化中,对于含有depthwise卷积的模型来说,如果使用按层量化的方式,会造成不小的精度损失,原因是因为depthwise卷积的组内卷积核与其他组的卷积核数值范围相差较大,如图所示。


使用按通道量化的方式可以解决这个问题,但是相对于按层量化,按通道量化会增加很多参数。
一个常用的办法是使用跨层均衡来均衡,原理如图所示。由于relu函数具有sf(x)=f(sx)的特性,所以可以在相邻的两层卷积之间分别乘以两个积为1的系数s和1/s,这样可以均衡同层之间的权重且输出结果不变,从而减小量化误差。
综上,我们推荐训练后量化的pipeline如下图所示。

量化训练QAT的主要原理是利用FP32的数据来表示NPU推理过程中的经过量化之后的数据,利用浮点对定点推理进行仿真,把量化误差加入到loss中来反向传播,从而提升模型精度。
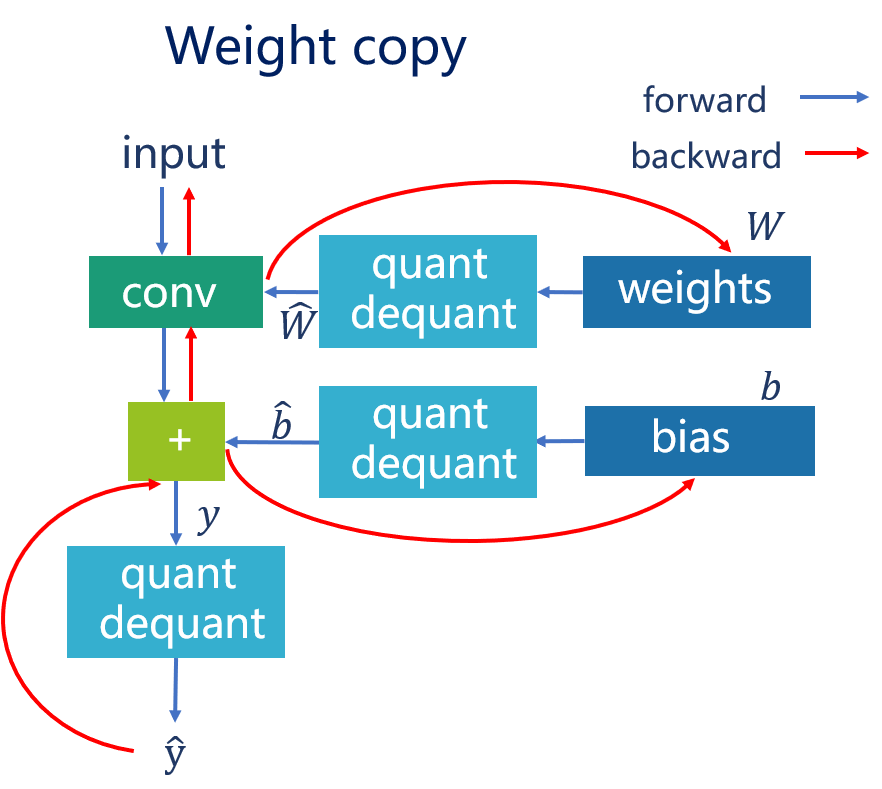
下面两图中,左图是一个卷积层在NPU中推理的过程的表示,右图是使用float32仿真NPU中的推理过程,可以看到右图中使用了quant dequant的层来仿真NPU中的权重和偏置值。

在使用QAT的时候有两个问题需要考虑,因为使用了量化反量化层,所以在反向传播的时候,需要对量化层进行建模来求取其梯度。一个常用的办法是使用STE(直通估计)来模拟反向传播,也就是在反向传播的时候将量化反量化层的梯度设置为1。
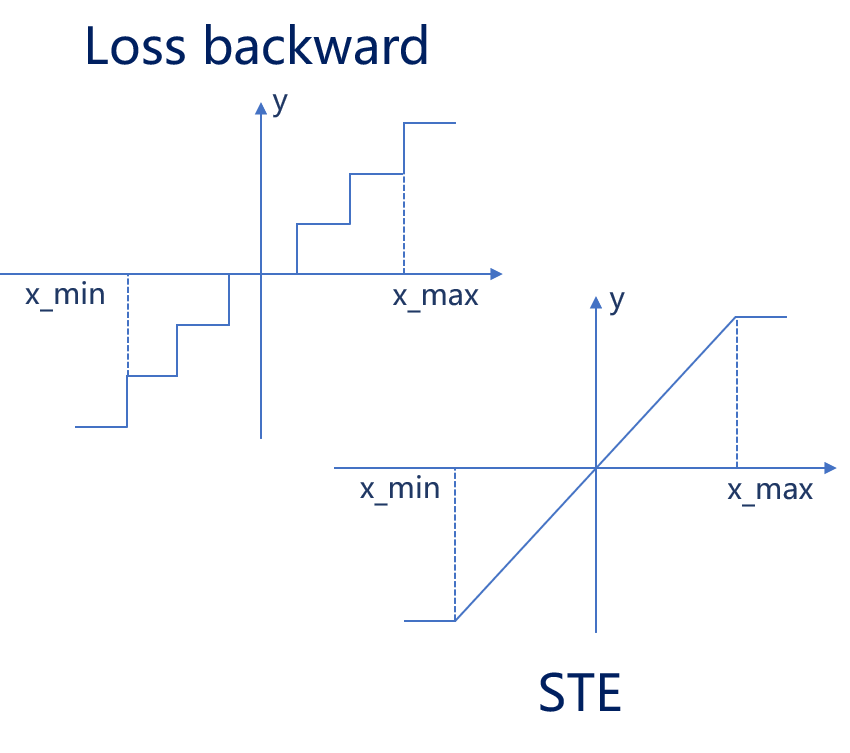
另一个需要考虑的问题是需要使用权重复制,因为反向传播的梯度累加值往往都比较小,量化操作会使得这个累加值不起作用,因此在前向传播的时候要使用复制后的权重进行量化,这样可以保证权重和偏置一直更新。
在进行量化训练时还有以下几个主要技巧:

①注意初始化
建议使用PTQ对模型进行初始化,好的初始化可以使模型在训练的时候更快地收敛。
②使用合并BN的办法
要注意是训练之前合并还是之后并,一般的建议是在初始化的时候合BN,但是如果模型在训练的过程中不收敛,建议不合并BN。需要注意的是如果不合并BN,必须使用按通道量化的方式,因为推理的时候一般会把BN合并去,如果使用的是按层量化,则会改变训练的权重分布。
③预处理
在进行QAT的时候,有些工具将预处理会变成一个BN层加入到网络中,这个时候要注意在训练中冻结这个BN层的参数,否则预处理参数错误会导致推理结果错误。
部分实例与技巧
下文将介绍部分低功耗IOT设备上模型部署的实例与技巧,主要涵盖系统优化,模型优化,模型调试三个方面。
模块1:系统优化
在部署模型的时候,首先要考虑的是系统优化,一个好的系统设计往往会对整体性能的优化带来较大的提升。

我们在设计使用模型的时候,一般会使用一些普通的cv操作如缩放,放射变换等进行前处理操作。
对于这些操作,一般的优化方法有两种:针对计算密集的操作,可以使用SIMD的指令来获取计算的加速,或者使用IOT芯片中自带的cv加速器进行操作。针对访存密集的操作,可以使用DMA操作来加速大块内存的读写。
此外,还可以使用内存复用来减少模型的内存使用。内存复用主要分为两个层级,一个是层级别复用,比如resize输出的内存地址可以直接设置成为模型输入的地址,省去一遍访存拷贝的操作,第二个就是模型间的内存复用。实际在运行多个模型的时候,如果模型是串行运行的,可以复用NPU在推理模型时使用的featuremap内存。
模块2:模型优化
模型优化的技巧主要有:
①合并BN
如前文所述相关内容。
②层适配
模型使用的层需要和工具所提供的层相匹配。
③并行度匹配
NPU的乘法器基本上都是16的倍数或者是32的倍数,因此模型的卷积核通道数或者输出通道数最好与NPU的并行度匹配以最大程度利用NPU。
④使用特殊层加速
有些NPU支持特殊层加速比如分通道卷积,如果使用普通卷积去实现可能没有使用通道可分离卷积实现的效率高。

模块3:调试技巧
调试技巧主要有如图所示的几个方面,在碰到问题的时候可以尝试在这几个方向上去定位问题。

总结
综上,本文讨论了量化的原理以及量化方式的分类,在使用量化操作的时候又着重介绍了PTQ和QAT两种量化方式。最后介绍了主要的模型优化技巧以及系统优化和调试技巧,希望能对大家的工作起到帮助作用。
欢迎关注“腾讯云AI平台”公众号
获取《2021年中国计算机视觉市场报告》
回复【入群】可添加云AI小助手,加入云AI产品、技术、认证等相关社群
回复【云梯计划】可了解更多TCA腾讯云人工智能从业者认证限时免费相关信息
回复【产品手册】可获得最新腾讯云AI产品及解决方案手册