详解YOLOv5中的Bottleneck
深度学习入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、背景知识 -- 残差结构
二、Bottleneck和building block
三、YOLOv5中的Bottleneck
1、结构分析
2.代码分析(内含注释分析)
一、背景知识 -- 残差结构
关于残差以及一些残差网络(eg: Resnet)的分析,可以看一下博主之前写的博客
深度学习之Resnet详解_tt丫的博客-CSDN博客
二、Bottleneck和building block
说到Bottleneck,就会想到他的“兄弟” -- building block。Bottleneck和building block其实都是在Resnet中提出的。如下图所示,左边是针对Resnet34提出的building block;右边是针对Resnet50提出的Bottleneck。
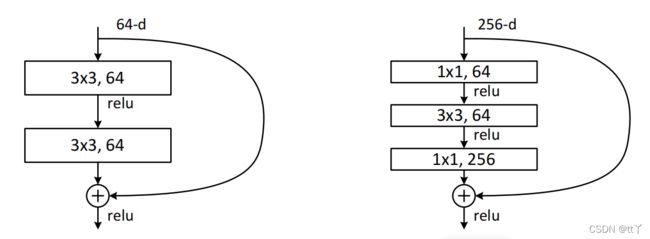
building block由两个3*3的卷积层组成,Bottleneck由两个1*1卷积层夹心一个3*3卷积层组成:其中1*1卷积层负责减少然后增加(实际上就是恢复)维数,让3*3卷积层成为输入/输出维数更小的瓶颈。Bottleneck既减少了参数量,又优化了计算,保持了原有的精度。
第一个1*1的卷积把256维channel降到64维,最后再通过1*1卷积恢复,整体上用的参数数目为:
1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632
如果不采取瓶颈结构的话(Building block),就是两个3x3x256的卷积,整体上用的参数数目为:
3x3x256x256x2 = 1179648
所以我们也能看出来,如果网络层数少(<=34 layer)的话,用building block好些;但是层数一旦多起来的话为了减少计算量,我们选择Bottleneck。
而且shortcut那里最后用的是add而非concat(通道数会增加)。使用add是使特征图相加,然后维持通道数不变。
三、YOLOv5中的Bottleneck
1、结构分析
YOLOv5中的Bottleneck跟Resnet中的Bottleneck有些不同。有以下两类:
(1)BottleneckTrue:
先是1x1的卷积层(conv+batch_norm+leaky relu(后期改为SiLU)),然后再是3x3的卷积层,最后通过残差结构与初始输入相加。

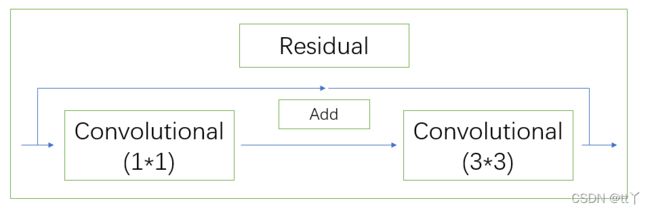 (2)BottleneckFalse
(2)BottleneckFalse
先是1x1的卷积层(conv+batch_norm+leaky relu(后期改为SiLU)),然后再是3x3的卷积层,没有再加入残差结构。

YOLOv5的Bottleneck相对于resnet来说少了一个1*1 的升维卷积,这里我觉得可能是因为YOLOv5中Bottleneck模块是在BottleneckCSP中使用的,BottleneckCSP由Bottleneck*N(此时维数为原先的1/2)和另外一个从原先变换来的同样维数也为原先的1/2的结构拼接(concat),最终就又实现了升维(恢复为原先的维数),这里可以理解为是Bottleneck*N操作后,再来一个大型的变式Bottleneck操作(虽然实际上是CSP,但我感觉他这里的思想跟Bottleneck好相似,这里不太确定,希望有朋友在评论里帮我分析一下,谢谢~)。再来一个类似Resnet的shortcut的操作,但是把其中的add变成了concat。(@志愿无倦,谢谢这位朋友的提醒啦)
这种True和False的结合使用巧妙地将Bottleneck和普通卷积联合在一起使用,减少了代码量,设计也更加清爽。
2.代码分析(内含注释分析)
class Bottleneck(nn.Module):#瓶颈层,由两个CBL组成,1个1*1,一个3*3,再横跨一个Residual
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))#这里对应判断:如果False就只有self.cv2(self.cv1(x)),True就x + self.cv2(self.cv1(x))