NLP 论文领读| 面向机器翻译的多语言预训练技术哪家强?最新进展一睹为快!
本文作者:李上杰, 澜舟科技算法实习生,天津大学硕士一年级,研究方向为多语言机器翻译、无监督机器翻译,邮箱:[email protected]。纸上得来终觉浅,绝知此事要躬行。
欢迎关注「澜舟科技」公众号,一起探索NLP前沿技术!
写在前面
机器翻译作为最成熟的 NLP 应用方向之一,已经进入千家万户,小到同学们看论文写论文不可或缺的帮手,大到跨国商务合作、促进世界人民交流,机器翻译一直发挥着至关重要的作用。然而,全世界的 7000 多种语言中,绝大部分的语言没有充足的平行语料数据,没有数据,如何建模呢?多语言模型也许是一个选择,多语言模型利用具备丰富资源的语言对的数据,能够帮助低资源乃至无资源语言的机器翻译性能得到提升,使得建立覆盖庞大语言对的机器翻译系统成为可能。
而预训练技术作为 2018 年开始发展起来的重要技术,迅速席卷了整个 NLP 领域,在大量 NLP 任务上展现了令人振奋的性能提升。随着多语言预训练技术的进一步发展,多语言预训练为跨语言生成任务提供了优良的参数初始化,当多语言预训练之风吹向机器翻译领域,又将发生怎样有趣的化学反应?
下文会针对这个热点研究问题进行梳理,为大家带来这方面的最新进展,并分享一篇近期在 ACL2022 上发表的论文——《Universal Conditional Masked Language Pre-trainingfor Neural Machine Translation》,该论文提出了针对机器翻译的预训练模型 CeMAT,该模型的解码器基于双向掩码预训练,同时引入了两种掩码手段,相比 MRASP 和 MBART 而言性能更加优异。
论文标题
Universal Conditional Masked Language Pre-training for Neural Machine Translation
作者机构
华为诺亚方舟实验室、澳大利亚莫纳什大学
论文链接
https://arxiv.org/abs/2203.09210
多语言预训练的形式
这篇论文对于多语言预训练工作的特点做了一个简单的归纳,如下图所示:

图 1 与现有一些预训练方法的比较
从预训练模型的架构来看,由于机器翻译模型常常是基于 Encoder-Decoder 架构,因此可以分为基于编码器预训练和 Seq2Seq 的预训练。早期的预训练模型,如 mBERT[1]、XLM[2]、XLM-R[3] 等模型,往往是只在一个编码器结构下进行语言模型训练,这种预训练方式适合 NLU(Natural Language Understanding)任务,而对于 NLG(Natural Language Generation)任务,尤其是 Seq2Seq 形式的生成任务而言,无法对 Decoder 中的 Cross-Attention 层进行初始化。因此,近年来,如 MASS[4]、mBART[5]、mRASP[6] 等预训练模型都在预训练阶段就引入 Decoder 模块,希望通过这种方式为下游任务提供更好的参数初始化,这篇文章提出的 CeMAT[7] 同样是基于 Encoder-Decoder 架构。
从预训练使用的数据来看,针对机器翻译这种跨语言任务,利用双语数据进行预训练成为一个趋势。早期的预训练模型,除了 XLM 引入了 TLM(Translation Language Modeling),将双语数据拼接进行 MLM(Masked Language Modeling) 语言建模之外,利用单语数据进行预训练更为常见,这种基于自编码的训练目标和翻译的目标存在差别 [6],而且无法对高资源语言的翻译性能进行提升,以及在微调阶段存在的 Catastrophic Forgetting 问题 [8]。而 CeMAT 表示,不管是单语数据还是双语数据,我全都要。CeMAT 在 Encoder 端执行 MLM 训练任务,在 Decoder 端执行 CMLM(Conditional MLM)[9] 任务,从而得到更好的多语言表示。
最后,从解码器的预训练方式来看,以 GPT[10] 为代表的 CLM(Causal Language Model) 预训练模型能够使得解码器具备很强的生成能力,但在 XLM[2] 的论文实验中就发现,使用基于 MLM 目标训练的预训练模型初始化解码器,要比使用 CLM 的性能更强,使用 CLM 初始化有时甚至不如对解码器进行随机初始化。根据这个现象,CeMAT 的作者推断,在翻译中解码器的表示能力可能比生成能力更为重要。基于这个考虑,在预训练时使用 CMLM 对 Decoder 进行训练,从而增强 Decoder 的语义表示能力。
方法
CeMAT 预训练模型主要分为三个模块:条件掩码语言模型 CMLM、Aligned Code-Switching & Masking 与 Dynamic Dual-Masking,接下来我们逐一介绍这三个模块。
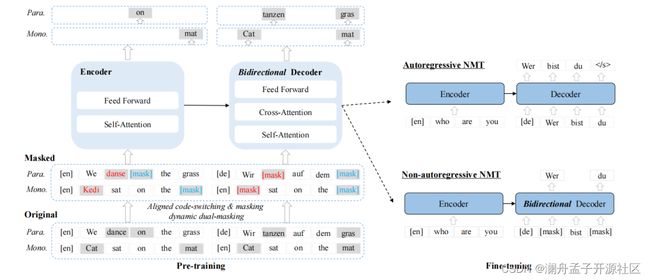
图 2 CeMAT 架构图
1. CMLM
条件掩码语言模型 CMLM 来自于非自回归论文 Mask-predict[9],主要思想是给定一对双语句子 ( X m X_m Xm, Y n Y_n Yn),遮盖 Y n Y_n Yn中一定比例的词语,被遮盖的词汇集记为 y n m a s k y_n^{mask} ynmask,训练时,在 Encoder 端输入 X m X_m Xm 句子,在 Decoder 端输入遮盖后的 Y n Y_n Yn 句子 (遮盖部分使用 [mask] token 代替),对于每一个被遮盖的位置,预测其真实词汇的概率:
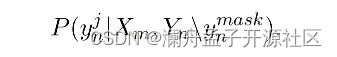
这与之前的 Seq2Seq 自编码式的语言建模任务不同,如 MBART,其在 Decoder 端依然是自回归式的,预测词汇时只能看到 Encoder 端和 Decoder 端已生成的词,即"上文",引入 CMLM,使得 Decoder 不止能看到"上文",还能看到"下文",提高 Decoder 的语义表示能力。
2. Aligned Code-Switching & Masking
这个模块的主要思想是在给定一组双语句子的情况下,首先确定双语句子中的对齐信息,即源端句子中的词汇与目标端句子词汇对齐的位置信息,然后通过词替换的方法,基于一份多语言词典,将源端词汇替换为任意一种语言中的同义词,将目标端相应位置的词汇进行掩码。如图2 所示,源端标红的词汇是指 Aligned Code-Switching & Masking 方法涉及的词汇,英文词汇 “dance” 被替换为法语中的同义词 “danse” ,而目标端德语句子中的相应词汇 “tanzen” 被掩码,训练目标就是预测真实词汇 “tanzen” 。对于单语数据,由于源端和目标端句子完全相同,只需要掩码相同位置的词汇即可。
词替换方法构造的 Code-Switching 句子,使得不同语言的词汇可以潜在地具备相似的上下文,由于单词的表示取决于上下文,因此不同语言中相似的词汇能够共享相似的表示,从而加强多语言空间的统一性。词替换方法也在之前的许多预训练工作中出现,如 CSP[11]、MRASP[6]、MRASP2[12],这种使用词级别的对齐信息,引导表示对齐的方法,在多语言预训练技术中也非常流行。
3. Dynamic Dual-Masking
由于词典的规模所限,作者发现词替换的比例仅占数据集中词汇的 6%。因此,作者进一步提出了 Dynamic Dual-Masking 方法,该方法有两个关键的特性,一个是 Dynamic,即动态,指的是掩码的比例是一个区间,而不像 BERT 等模型是一个固定的比例;另一个是对偶掩码,即同时掩码源端句子和目标端句子。
对于双语数据,作者设置了随机变量 v ∈ [ 0.2 , 0.5 ] v\in [0.2,0.5] v∈[0.2,0.5] ,用来对目标端句子进行动态的掩码,对于源端句子,设置了比例范围 μ ∈ [ 0.1 , 0.2 ] \mu\in[0.1,0.2] μ∈[0.1,0.2] ,作者严格控制 v ≥ μ v\geq\mu v≥μ ,是为了让 Decoder 端更加依赖 Encoder 的信息进行预测,强化了 Cross-Attention 的参数训练。
对于单语数据,由于单语数据的源端和目标端句子相同,为了防止模型"走捷径"直接复制,CeMAT 对源端和目标端进行相同的掩码。
Dynamic Dual-Masking 方法的示意图见上图标蓝的词汇,双语数据掩码位置无需严格相同,单语数据需要严格相同防止"窥屏"。作者同样设置了一个动态的掩码比例区间, v = μ ∈ [ 0.3 , 0.4 ] v=\mu\in[0.3,0.4] v=μ∈[0.3,0.4]。
注意到 Dynamic Dual-Masking 步骤的掩码可能会影响 Aligned Code-Switching & Masking 的结果,CeMAT 避免这种情况的发生,Dynamic Dual-Masking 不会选择已经进行过 Aligned Code-Switching & Masking 的词汇。
将上述三个模块结合起来,总的损失函数为:
L = − ∑ ( X ^ m , Y ^ m ) ∈ D ^ λ ∑ y n j ∈ y n m a s k l o g P ( y n j ∣ X ^ m , Y ^ n ) + ( 1 − λ ) ∑ x m i ∈ x m m a s k l o g P ( x m i ∣ X ^ m ) L=-\sum_{(\hat{X}_m,\hat{Y}_m)\in \hat{D}}\lambda \sum_{y^j_n\in y_n^{mask}}logP(y^j_n|\hat{X}_m,\hat{Y}_n) + (1-\lambda)\sum_{x^i_m\in x^{mask}_m}logP(x^i_m|\hat{X}_m) L=−(X^m,Y^m)∈D^∑λynj∈ynmask∑logP(ynj∣X^m,Y^n)+(1−λ)xmi∈xmmask∑logP(xmi∣X^m)
上式前半部分是解码端的 CMLM 损失, X ^ m \hat{X}_m X^m与 Y ^ m \hat{Y}_m Y^m 都经过了 Aligned Code-Switching & Masking 与 Dynamic Dual-Masking 的处理,后半部分是编码端 MLM 损失。论文中设置 λ \lambda λ 为 0.7,用来调节两个损失的权重。
实验结果
1. 翻译性能
CeMAT 使用了与 mRASP 相同的双语数据集 PC32,同时又从 common crawl 中收集了一批单语数据,共包含 21 种语言进行实验,主要的实验结果如下图所示:
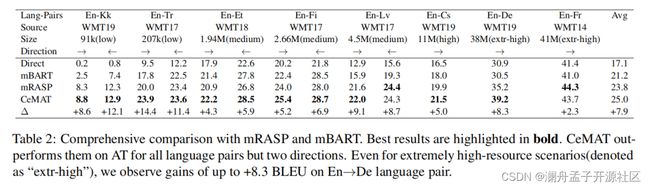
CeMAT 根据训练数据规模,将不同的语言分为 low、medium、high、extr-high 四个等级,从结果上看,CeMAT 相比 mRASP 存在全面的提升,相比于 Direct(直接训练),经过多语言预训练的模型能够为低资源语言提供很强的知识迁移,在 En-Tr 的低资源任务上提升达到了 14.4 的 BLEU。实验对比了 CeMAT 与 MBART 和 mRASP,与 MBART 相比,mRASP 和 CeMAT 由于使用了双语数据进行预训练,明显比仅基于单语数据预训练的 MBART 更适合翻译这种跨语言任务,即使在 extr-high 的设置下依然有明显的提升。CeMAT 的设计同样适合作为非自回归翻译的预训练模型,作者同样对非自回归翻译性能的提升做了详细的实验,这部分的内容感兴趣的小伙伴可以自行去了解~
2. 消融实验
看到 CeMAT 的优异性能,大家肯定想赶紧了解一下,CeMAT 中各个部分对最终的性能提升的重要性如何?

从作者进行的消融实验,Aligned CS masking 带来的提升平均为 0.5 个 BLEU,而动态掩码带来的提升达到了 2.1 个 BLEU。Aligned CS masking 由于只平均替换了 6%的词汇,因此带来的效果较动态掩码明显要低得多,如果能进行更多有效的词替换,以被替换的词作为锚点,可以想见对编码器的跨语言对齐会有更大的提升。这个表中的第三行表示不进行词替换、同时将动态掩码改为静态掩码、按照 15%的比例进行掩码。掩码的比例大小对性能的影响是非常大的,如 MBART 中的掩码比例设置为 35%,过低的掩码比例会使得模型更轻易地预测被掩盖的词,从而无法学到真正重要的东西。
总结
在最后,我想总结一下当前面向机器翻译的多语言预训练模型的特点:
使用双语数据预训练,提供充分的跨语言信息。 MBART 预训练对于低资源语言有比较明显的提升,而对于高资源语言的提升并不明显,这在之前的针对单语预训练的工作中就有所提及 [6],笔者认为,单语预训练任务通过促进了单语言内部的语言建模,有效提高了低资源语言表示的质量,但并没有直接的跨语言对齐信息 (存在隐式的编码器参数共享),在高资源的情况下对于跨语言任务没有明显帮助,我们可以看到在 En-De 的语言对上 mBART 初始化性能甚至稍弱于随机初始化 (Direct)。使用大量高资源双语数据进行预训练能够为后续的机器翻译任务提供有效的初始化。
使用词替换技术,为不同语言的句子提供相同的上下文,促进多语言空间的融合。 从 CSP 到 mRASP,再到 CeMAT,词替换技术在预训练中成为了一个低成本高效的选择,对于一个新语言而言,获取词典的难度会更小,无监督词典生成方面也有许多研究,如 VecMap[13],通过单语 Embedding 空间的映射对齐得到词典,相比于传统词典可以更灵活地获取子词级别的对齐。
使用 MLM-style 的预训练目标训练解码器。 早期的 XLM 使用 MLM 训练的预训练模型来初始化翻译模型的解码器,微软的 DeltaLM[14] 利用预训练的编码器,交错地初始化解码器,然后再进行统一的单语+双语预训练,还有该论文介绍的 CeMAT 使用的 CMLM 任务。近期的翻译预训练模型越来越注重解码器的语义表示能力,由于 MLM-style 的预训练目标与解码器生成时的自回归形式有所冲突,也许我们可以考虑选择使用非自回归的解码方式,因为 CeMAT 在非自回归翻译上性能的提升也非常显著。
参考文献
[1] Devlin, J. , Chang, M. W. , Lee, K. , & Toutanova, K. . (2018). Bert: pre-training of deep bidirectional transformers for language understanding…
[2] Lample, G. , & Conneau, A. . (2019). Cross-lingual language model pretraining.
[3] Conneau, A. , Khandelwal, K. , Goyal, N. , Chaudhary, V. , & Stoyanov, V. . (2020). Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
[4] Song, K. , Tan, X. , Qin, T. , Lu, J. , & Liu, T. Y. . (2019). Mass: masked sequence to sequence pre-training for language generation.
[5] Yinhan Liu, Jiatao Gu, Naman Goyal, X. Li, Sergey Edunov, Marjan Ghazvininejad, M. Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pretraining for neural machine translation. In TACL.
[6] Lin, Z. , Pan, X. , Wang, M. , Qiu, X. , & Li, L. . (2020). Pre-training multilingual neural machine translation by leveraging alignment information. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
[7] Pengfei Li, Liangyou Li, Meng Zhang, Minghao Wu, Qun Liu: Universal Conditional Masked Language Pre-training for Neural Machine Translation. ACL (1) 2022: 6379-6391
[8] Jiacheng Yang, Mingxuan Wang, Hao Zhou, Chengqi Zhao, Weinan Zhang, Yong Yu, Lei Li: Towards Making the Most of BERT in Neural Machine Translation. AAAI 2020: 9378-9385
[9] Marjan Ghazvininejad, Omer Levy, Yinhan Liu, Luke Zettlemoyer: Mask-Predict: Parallel Decoding of Conditional Masked Language Models. EMNLP/IJCNLP (1) 2019: 6111-6120
[10] Alec Radford and Karthik Narasimhan. 2018. Improving language understanding by generative pretraining.
[11] Zhen Yang, Bojie Hu, Ambyera Han, Shen Huang, Qi Ju: CSP: Code-Switching Pre-training for Neural Machine Translation. EMNLP (1) 2020: 2624-2636
[12] Xiao Pan, Mingxuan Wang, Liwei Wu, Lei Li: Contrastive Learning for Many-to-many Multilingual Neural Machine Translation. ACL/IJCNLP (1)
[13] Mikel Artetxe, Gorka Labaka, Eneko Agirre: A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. ACL (1) 2018: 789-798
[14] Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, Alexandre Muzio, Saksham Singhal, Hany Hassan Awadalla, Xia Song, Furu Wei:DeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders. CoRR abs/2106.13736 (2021)