澜舟孟子轻量化预训练模型技术实践 | NLP 前沿实践
在上周发布的《一文看懂预训练最新进展》中,澜舟科技创始人兼 CEO 周明和澜舟科技大模型技术负责人王宇龙分享了大模型技术发展背景和近期百花齐放的大模型及新应用、新趋势。本文继续为大家深入介绍“大模型轻量化”趋势以及澜舟的 5 个实践路径。
以下内容根据澜舟科技算法研究员华菁云在「澜舟NLP分享会」演讲整理。全文约 4800 字,预计阅读时长 6 分钟。
为什么要训练轻量化模型?
人们普遍认为,在相同网络架构和训练方法下,模型层数增加、模型参数增加,能力就一定增强,实际上增强的幅度越来越小。大家都知道摩尔定律,硬件逐年价格下降 1.5 倍,运算能力提升 1.5 倍,但是实际上模型参数量每年增加至少 7 倍,硬件能力的提升显然赶不上模型规模的增长。
如图 1 右侧所示,训练一个大模型代价是巨大的,GPT-3 训练需要 460 万美金,此外,大模型落地部署的代价也极大,在工业界实际应用中不得不考虑部署的成本。所以在摩尔定律逐渐走向终结的今天,模型轻量化是必须要考虑的。
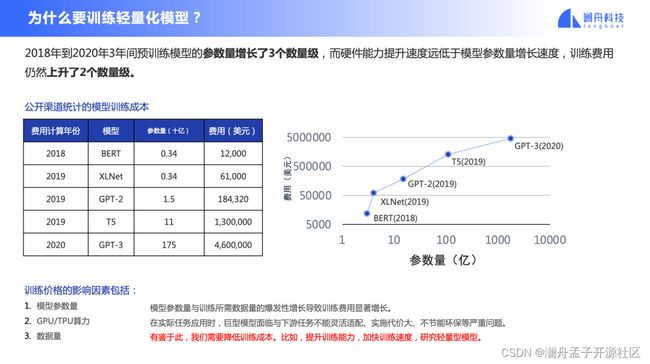
图 1
轻量化路径
1. 语言学知识增强
使用语言学知识作为显性的知识信号可以使得模型在预训练的过程中获取到更多的先验信息,在同等参数量下,融入更多的语言学知识。 我们使用 SpaCy 对语料进行词性标注(POS)和命名实体识别(NER),将识别的目标标签作为预测目标用于训练,让模型在语言建模的同时,去计算 POS 与 NER 的预测损失与原始语言建模损失相加得到的最终损失。这个方法可以在各数据集上带来一致的提升。
如图 2 下半部分表格,大家可以看到孟子 Mengzi 模型对应的分数的提升还是比较明显的。
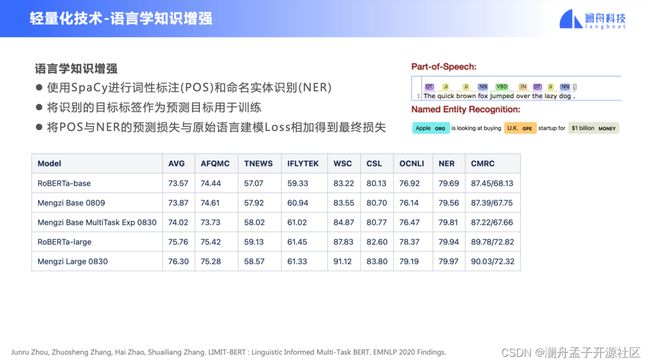
图 2
此外,为了建模句子间的关系,我们结合了 ALBERT 提出的句子顺序预测 SOP 任务,发现也能带来明显的性能提升。而类似的下一句预测 NSP 任务在各项中文任务上的提升不太明显(如图 3 表格所示)。

图 3
2. 训练优化技术
传统基于掩码的预训练方法(Mask Language Model, MLM) 首先通过 ennoising 的方法,例如通过 mask 来构建训练样本,然后训练语言模型去还原被破坏的句子。由于通常采用随机的破坏方法,样本预测的难易度不同,模型在 denoising 训练时的梯度更新强度与样本难度之间缺乏一致性,可能会造成训练不稳定的问题。
此外,也会带来一些假负例,即模型会还原出来与原始句子不同,而实际上也合法的句子。模型通常采用交叉熵训练,这类样本则都会被判断为错误预测,导致训练事实上是不准确的。

图4
那么针对以上两个问题,我们探索了一些训练校正策略。
第一个是评估 mask 对句子的破坏度。基本的假设是破坏程度越大,Loss 会越大,模型则要花更大的代价去更新梯度。
第二个是计算预测结果与原始句子之间句子级别的语义距离。尽管两个句子形式上差异很大,但语义越近,Loss 则会更小,对 Token 级别的交叉熵是一个补充。

图 5
我们在 BERT 和 ELECTRA 上分别进行了实验验证,发现这两个方法能有效提升模型性能,并且有利于模型应对同义词替换之类的对抗攻击,从而提升鲁棒性。图 6 表格是我们在英文权威测评榜单 GLUE 各项标准任务上进行了测评,可以看到,使用我们训练优化技术后模型可以在同等参数量下得到更高的均分。

图 6
3. 模型压缩
在预训练模型越做越大的时代, 通过压缩实现轻量化显得至关重要,压缩 pipeline 可以有效降低模型冗余度,压缩后模型参数规模显著降低,模型部署场景更加多元化。我们的轻量化技术结合了模型蒸馏、剪枝和量化,将大模型进行压缩得到轻量化模型,显著提升模型推理速度,改善用户体验。
3.1 蒸馏

图 7
不同的落地业务(如:在线业务,离线业务),对模型有不同尺寸需求。预训练蒸馏能够定制化出不同参数量的模型,满足各式各样的需求。

图 8
受 MiniLM 的启发,我们使用 attention transfer 的方式蒸馏 teacher model,distill loss设定为最后一层 attetion 的 query、key、value 矩阵的 KL 散度。另外,当 student model 的层数、维度都小很多时,先用一个维度小但层数和 teacher 一致的 assistant 蒸馏,之后再把 assistant 的知识传递给 student,这样可以获得更好的蒸馏效果。
实验表明,使用上述 attention transfer 的方式蒸馏 mengzi-bert-large,相对其他蒸馏方法如 TinyBERT 等同尺寸的蒸馏模型来说效果更好。attention transfer 蒸馏方案可根据下游任务需求、客户需求进行定制化蒸馏,满足特定的 inference 需求。详细的实验对比数据参见图 9,我们在中文权威测评榜单 CLUE 具有代表性的语义相似度、长文本分类、新闻(短文)分类、自然语言推理四个通用性的分类任务上,在同等模型规模下,孟子蒸馏模型的均分更高。

图 9
3.2 剪枝和量化
非结构化的剪枝技术虽能实现模型稀疏化,但因硬件等限制无法实现真正意义上的物理加速效果,**所以我们在模型剪枝与量化方面设计的模型压缩方案,有效地融合了结构化剪枝和量化技术,能够在兼顾模型效果的同时更进一步实现物理加速。
受 EarlyBERT 的启发,我们在模型的 pretrain 阶段进行了 head 裁剪,可以使得预训练总成本下降,且最终得到的预训练模型的 inference 速度更快。
另外参考 ROSITA 的思路,在 finetune 阶段可选择性的进行结构化剪枝,首先在深度上对层数进行裁剪,然后在宽度上对 head 和 hidden size、embedding size 进行裁剪,实现了模型参数量下降,inference 加速。
可以看到图 10 表格中的实验数据,我们考虑到深度宽度的结构化剪枝方案,对 bert-base 进行剪枝,可以在压缩比 61% 的情况下,加速比达到 1.75,sst-2 任务上 acc 达到 92.1,相较于同等 size 为 66M 的其他模型而言,效果更好。
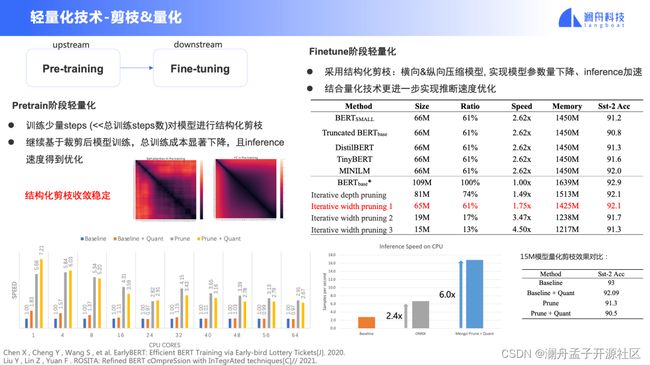
图 10
在结构化剪枝的同时,我们结合量化技术进一步实现推理速度的优化,结果显示在 4 核 CPU 设备上,结合量化+剪枝的方案可加速约 6 倍( 如图 10 右下角柱状图所示)。而且澜舟的剪枝量化相结合的方案可以提供更具适应性的落地方案,可根据用户的不同场景的需求快速构建部署符合需求的模型。
4. 检索增强
受 DeepMind 去年发布的 RETRO 启发,我们在预训练模型基础上增加了检索增强的技术。RETRO 的主要思路是,除了使用这一个大规模预训练语言模型掌握语料知识之外,还可以把知识从这个模型中解耦,独立成一个单独的检索模块,把这些知识放到一个数据库里面。这项技术使更小规模模型达到大规模模型同等效果成为可能。并且,这也使得外部知识组件可实时更新,单独优化,弥补了预训练模型语料总是滞后于真实世界的问题。
我们从 825G 的 pile 语料中采样了 43G 语料数据。经过 tokenizer 后得到 730w 个样本,再经过 chunk split,并通过模型得到 1.8亿 维度为 384 的 embedding,对齐 build faiss index。
我们在训练模型的过程中,通过已构建完成的索引库,来检索与当前语料相关的语料,然后训练模型的 chunk cross attention,我们是在总共 12 层模型的第 6、9、12 层中加入 chunk cross attention 结构。在使用模型进行 inference 时,我们实时使用 faiss 进行相关语料检索。

图 11
从图 11 的表格中可以看到,在 wikitext103 数据集上,使用了 retrieval 的 gpt-neo 的 ppl 更低,模型效果更好。当然由于加入了 retrieval 的模块,在 inference 时的耗时会相对更久,不过检索速度的优化空间还是比较大的。后续我们也会在检索增强方面,做更多的探索。
5. 多任务
目前多任务也是比较受业界人士关注的一个方向。Prompt 可以有效缓解预训练和微调两阶段任务鸿沟。通过多样化的 Prompt 设计和多任务训练,可以极大地提高在 few-shot、zero-shot 这些场景下的模型表现,从而提高模型的生产效率,快速适应新场景的需求。

图 12
我们基于孟子 Mengzi-T5-base 模型训练了多任务模型,共收集并整理 72 个开源数据集(不包括子集),目前在挑选出的 27 个任务上,构造了 301 个 Prompt,共计约 359w 个样本,任务类型包含了情感分类、新闻分类、摘要等任务,每个任务对应了十个左右的 Prompt。
下图展示了孟子 Mengzi 多任务模型的 zero-shot 能力。

图 13
在实体抽取、语义相似度、金融关系抽取、广告文案生成、医学领域意图分析、评论情感分类、评论对象抽取、新闻分类等任务上的效果,孟子Mengzi模型的 zero-shot 总体效果是不错,后续我们也将在多任务方向深入探索和实践。
开源孟子Mengzi模型
上面提到的部分成果,我们已经开源了给了社区,大家可以自由下载体验,项目地址:https://github.com/Langboat/Mengzi ,模型地址:https://huggingface.co/Langboat。
孟子轻量化模型研发的主要目标是“构建同等规模下性能更强的模型”。 目前已经开源的 4 个模型分别是:BERT-style 的语言理解模型、T5-style 文本生成模型、金融分析模型和多模态预训练模型。孟子 Mengzi 模型采用通用接口、功能齐全、覆盖任务广,不仅可用于常规的语言理解和生成任务,也可应用于金融垂直领域和多模态场景中。

图14
从上图可以看到,相对同等规模的模型,孟子 Mengzi 的 4 个模型针对下游任务的表现更加优秀。金融预训练模型比已有的通用模型,在若干金融 NLP 任务上有更好的效果。
这里重点讲一下孟子 Mengzi 多模态模型。其实用一套模型解决图片、文字的任务,本质上也是工业实践层面的“轻量化”,可以节省模型生产和部署成本。 具体来说,孟子 Mengzi 多模态模型可以处理如下几类任务:
- 图片生成描述任务:输入为图片,输出为对该图片的文字描述;
- 文到图的生成任务:输入为自然语言,输出该文字描述对应的图像;
- 人脸文字描述到人脸图片的生成任务:输入为人脸相关的文本描述,输出为对应描述的图片。

图 15
图 15 有一些示例,左边是模型根据图片输出对应的图片描述,比如输入一张办公室的图片,模型输出了“一张白色的桌子,上面放着一台笔记本电脑和一台电脑”,这个描述比较贴切,而且相对来说比较细致。左下角是我站在公司窗边随手拍一张照片,输出文本是“一条繁忙的城市街道,人们走在人行道上,汽车和摩托车在街道上”,也是一个相对比较细致的描述。
我们也可以通过文本让模型生成一张虚构的图片,比如图 15 中,输入“T 恤衫 M 号”,模型就会生成一张 T 恤衫的图片,或者说,这张图片是模型虚构的一些图片的融合。图 15 最右侧,大家能看到“一个黄色头发的亚洲女性”、“阳光帅气眼镜短发型男”这种文字到人脸的生成,也是比较贴切的。
轻量化预训练模型落地场景
孟子 Mengzi 不仅仅是追求模型本身的轻量化,也希望大家在具体场景中能够灵活高效地部署。这里也为大家介绍一下轻量化预训练模型具体落地场景。
1.垂直领域机器翻译
在国际权威公开的测试集 BLEU 上,澜舟机器翻译在金融领域、汽车领域、工程领域以及通用领域的分数比肩几个国际知名的机器翻译引擎。在孟子预训练模型基础上,针对垂直领域进行微调,大幅提升模型迭代速度,并且充分利用垂直领域中的知识,用少量双语数据达到更好的翻译效果。

图 16
2. 智能辅助写作
智能辅助写作是和文本生成强相关的场景,孟子轻量化预训练模型针对多种写作场景进行微调,可以让模型快速具备生成不同题材内容的能力,并能够通过 Prompt 方式控制生成内容,模型生产的周期大大下降。
AI 辅助撰写文案、文学报告等,相比于人工撰写可以节约人力成本和时间。假设人工撰写需要 10 ~100 元/篇,AI 辅助写作会让成本降低到 1.5~3 元/篇,耗时方面 AI 辅助文案生成一般可控制在 5 秒以内,大大缩减了人力和时间。

图 17
值得一提的是,在大模型技术诞生之前 AI 辅助写作是无法做到“可控”续写的,澜舟的智能辅助写作引擎支持可控的文本生成,用户自主选择标签,比如风格、场景设定、品类热词等,由模型自动生成一段符合要求的文案。在智能辅助写作场景,我们已经与数说故事子公司容徽建立了深度的合作,未来也会通过澜舟认知智能平台对公众提供标准的 SaaS 服务,届时大家可以在线上体验。
3. 智能文档的处理
预训练模型的一个优势在于对没有见过的样本有多个角度泛化的能力。 基于孟子轻量化预训练模型,我们可以快速实现多种针对文档内容的分析、处理算法,在一些新的领域只需要少量的标注数据进行微调即可适应新场景的需求。相较于规则引擎需要专业的工程师花大量的时间总结经验写规则,通过孟子轻量化模型预训练技术,用户可以有效降低时间和人力成本。
如果进一步与 OCR 等多模态处理能力结合,用户可以将进一步提升文档处理能力。下图右侧是一页房屋买卖合同。相比原规则系统,孟子模型在综合得分 F1 score 上更优。在实际应用场景中,用户体验更好(注:F1 = 2(precision · recall) / (precision + recall) )。

图 18
总结
本次演讲总结了澜舟轻量化技术实践的 5 种路径,包括语言学知识增强、训练优化技术、模型压缩(蒸馏、剪枝和量化)、检索增强、多任务,并分享了澜舟孟子轻量化预训练模型在垂直领域机器翻译、智能辅助写作、智能文档处理场景中的应用。未来我们将继续在轻量化技术各方向上持续探索,欢迎 NLP 领域相关学者、工程师提出建议,一起讨论。
澜舟NLP分享会(Langboat NLP Meetup)是由澜舟科技发起的面向自然语言处理(NLP)领域从业者的系列活动,期望为关注 NLP 技术的学者、工程师打造一个开放的技术分享平台,推动行业交流。
第一期分享会于2022 年 7 月 16 日举办,主题为《认知智能时代,大模型轻量化技术与应用》,邀请了来自微软研究院、清华大学、同花顺的专家一起探讨前沿技术和实践,累计近 1400 位观众收看了本期直播,错过直播的小伙伴可以通过 B 站“澜舟孟子开源社区”、微信视频号“澜舟科技”观看回放视频。