基于SegNet的CamVid语义分割任务
基于SegNet的CamVid语义分割任务
-
- 摘要
- SegNet介绍
- 数据集
-
- 数据处理
- 实验设计
- 参数设置
- 实验结果
- 代码实现
- 参考文献
摘要
SegNet是一种典型的基于encoder-decoder结构的语义分割网络,本文介绍了SegNet的网络结构,以及在CamVid数据集上进行的实验,同时比较了SegNet与DeepLabV3、SegResNet在CamVid上的分割效果差异。
SegNet介绍
SegNet是一种有效的像素级语义分割架构,是一种典型的基于encoder-decoder结构的语义分割网络,如下图
SegNet的encoder部分是VGG16的前13层,decoder部分则是对应的上采样网络,不同于FCN的上采样方式,SegNet的上采样是在编码器网络的每一个最大池化过程中保存其池化索引,以便使用这些得到的索引来做非线性上采样。如图
数据集
采用SegNet论文中提出的数据集CamVid进行实验(对比就会有差距,还是太菜了,效果不行)。Camvid是第一个具有目标类别语义标签的视频集合。包括367个训练图像和233个测试的360×480分辨率的RGB图像(白天和黄昏场景)。挑战是划分11个类别,如道路、建筑、汽车、行人、标志、柱子、人行道等。
数据处理
由于没有充足的数据,进行了数据增强避免过拟合。通过图像旋转、左右翻转、随机裁剪、放大缩小等数据增强方法进行了数据集扩充,最后多了1k张图片。使用的是Augmentor库进行数据增强。代码如下:
import Augmentor
import os
def augment_data():
# 不需要读取图像,在管道中给定路径就行,增强的操作只需在管道添加
p = Augmentor.Pipeline('data/SegNet/CamVid/train') # 真实图像的路径
p.ground_truth('data/SegNet/CamVid/trainannot') # 掩码图像的路径 名字一定要相同,否则不能生成mask的增强
# 图像旋转,按照0.5的概率,最大左旋转角度20,右旋转角度10
# 左右的角度必须在25之内
p.rotate(probability=.5, max_left_rotation=20, max_right_rotation=10)
# 图像左右翻转
p.flip_left_right(probability=0.5)
# 图像放大缩小,按照概率为0.5,面积为原来的0.9倍
p.zoom_random(probability=.5, percentage_area=0.9)
# 裁剪
p.crop_random(probability=.5, percentage_area=0.8)
# 亮度
# p.random_brightness(probability=.2, min_factor=0.1, max_factor=0.9)
# 最终扩充的样本数量
p.sample(1000)
augment_data()
def split_image_mask():
# 原始图像的文件夹
orgin_dir = 'data/SegNet/CamVid/train_aug'
# mask图像的文件夹
mask_dir = 'data/SegNet/CamVid/trainannot_aug'
if not os.path.exists(orgin_dir):
os.makedirs(orgin_dir)
if not os.path.exists(mask_dir):
os.makedirs(mask_dir)
output_dir = 'data/SegNet/CamVid/train/output' # 上面生成的增强图像都在这个目录下
all_img_list = os.listdir(output_dir)
count = 1
for img_name in all_img_list:
"""找到对应的img和mask"""
# print(img_name)
if img_name.startswith('_groundtruth_'):
# 将掩码移到mask_dir文件夹下
img_path = img_name.split('_', maxsplit=4)[-1]
print(img_path)
os.rename(os.path.join(output_dir, img_name), os.path.join(mask_dir, str(count) + '.png'))
# # 图像移动到orgin_dir下
os.rename(os.path.join(output_dir, 'train_original_'+img_path), os.path.join(orgin_dir, str(count) + '.png'))
count += 1
split_image_mask()
实验设计
设计了SegNet,SegResNet,DeepLabV3,以及Dropout(贝叶斯SegNet),数据增强5组实验,比较了PA,MIoU这两种评价指标。
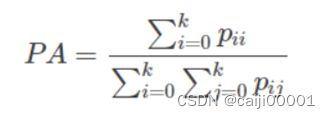

参数设置
学习率(learning rate):采用固定学习率0.001;
动量(momentum):0.9
优化器:SGD
Batch size:5
Dropout:0.5
Epochs:100
Output Stride(DeepLabV3):8
Backbone(DeepLabV3):ResNet18
实验结果
模型或方法 训练集PA 测试集PA 训练集MIoU 测试集MIoU
SegNet 93.02% 71.32% 58.23% 32.10%
SegNet(使用数据增强) 91.55% 74.30% 51.50% 37.20%
SegNet(添加dropout层) 90.22% 77.43% 47.91% 41.84%
Deeplabv3 92.91% 78.27% 58.75% 44.19%
SegResNet 92.11% 78.44% 52.32% 39.09%
代码实现
私我
参考文献
[1] V. Badrinarayanan, A. Kendall and R. Cipolla, “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 12, pp. 2481-2495, 1 Dec. 2017, doi: 10.1109/TPAMI.2016.2644615.
[2] G. Brostow, J. Fauqueur, and R. Cipolla, “Semantic object classes in video: A high-defifinition ground truth database,” PRL, vol. 30(2), pp. 88– 97, 2009.
[3] Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam: Rethinking Atrous Convolution for Semantic Image Segmentation.