预训练模型 PLOME
公众号 系统之神与我同在
预先训练的蒙面语言错误知识(PLOME):预先训练的错误知识中文拼写更正
摘要
中文拼写纠正(CSC)是检测和纠正文本中拼写错误的一项任务。汉语拼写改正(CSC)在本质上是一个语言问题,使模型具有语言理解能力是这一任务的关键。本文提出了一种用于汉语拼写改正(CSC)的预训练掩蔽语言MLOdel(PLOME),它联合学习如何理解语言和纠正拼写错误这两项任务。为此,模型根据混淆集而不是BERT中的固定Token“[MASK]”。除字符预测外,预训练掩蔽语言MOdel(PLOME)还引入了语音预测,以学习语音级别的拼写错误。此外,语音和视觉相似性知识对于这项任务很重要。PLOME利用GRU网络来对这种基于字符的发音和笔划的知识进行建模。实验是在广泛使用的基准上进行的。我们的方法比最先进的方法取得了卓越的性能。我们发布源代码和预先训练的模型,供社区进一步使用。
1.介绍
中文拼写纠正(CSC)旨在检测和纠正文本中的拼写错误(Yu和Li,2014)。在自然语言处理中,这是一个具有挑战性但重要的任务,其在各种NLP应用中,例如搜索引擎(Martins and Silva,2004)和光学字符识别(Afli等,2016)中发挥着重要作用。汉语拼写错误主要分为语音错误和视觉错误两类,分别由语音相似字符和视觉相似字符的误用引起。据Liu et ai(2010)称,

其中语音错误占48%,视觉错误占48%。图1说明了这些错误的示例。第一种情况是滥用同音,第二种情况是滥用同形,即字符之间形状非常相似。
中文拼写改正是一项具有挑战性的任务,因为它需要人类水平的语言理解能力来完全解决这个问题(Zhang等,2020)。因此,语言模型在汉语拼写改正中起着重要的作用。事实上,这项任务的主流解决方案之一是基于语言模型(Chen等人,2013年;Yu和Li,2014年;Tseng等人,2015年)。目前,最新的方法(Zhang et ai.,2020;Cheng et ai.,2020)基于BERT(Devlin et ai.,2019),BERT是掩蔽语言模型。在这些方法中,(掩蔽)语言模型不同于中文拼写校正(CSC)任务进行预处理。因此,他们在训练前没有学到任何任务方面的知识。因此,这些方法中的语言模型对于汉语拼写校正(CSC)都不是最优的。
汉语拼写错误主要是由语音或视觉上相似的字符误用造成的。因此,字符之间的相似性知识对于这项任务至关重要。一些工作利用混淆集,即一组类似的字符,来融合这些信息(Wang et ai.,2018,2019;Zhang et ai.,2020)。然而,混淆集通常由启发式规则或手动注释产生,因此其覆盖范围有限。为了避免这个问题,Hong et ai.(2019)根据字符的笔划和语音计算相似度。相似性通过规则来衡量,而不是通过模型来学习,因此没有充分利用这种知识。
2991
计算语言学协会第五十九届年会记录
第11次自然语言处理国际联合会议,第2991-3000页
2021年8月1日至6日
本文针对汉语拼写改正问题,提出了一种具有误拼知识预训练掩蔽语言PLOME。以下特点使得具有误拼知识预训练掩蔽语言mOdel(PLOME)比普通的BERT用于中文拼写校正(CSC)更有效。首先,我们提出了基于混淆集的掩蔽策略,其中根据混淆集,而不是BERT中的固定Token“[MASK]”,将每个选择的Token随机地替换为类似的字符。因此,PLOM掩蔽语言mOdel在训练前共同学习语义和误拼知识。其次,该模型以每个字符的笔画和语音作为输入,使预先训练的带有错误拼写知识的掩蔽语言mOdel(PLOME)能够模拟任意字符之间的相似性。第三,预训练掩蔽语言mOdel与错误拼写知识(PLOME)通过联合恢复伪装符号的真实字符和语音,学习字符和语音水平的错误拼写知识。
我们在广泛使用的基准数据集SIGHAN上进行实验(Wu et ai.,2013;Yu et ai.,2014;Tseng et ai.,2015)。实验结果表明,具有误拼知识E(PLOME)的预训练掩蔽语言mOdel明显优于所有比较的方法,包括最新的软掩蔽BERT(Zhang等,2020)和拼写图卷积网络(GCN)(Cheng等,2020)。
(1)MOdel(PLOME)是为汉语拼写改正而设计的第一个任务专用语言模型。基于混淆集的掩蔽策略使我们的模型能够在训练前共同学习语义和拼写错误的知识。(2)mOdel与错误拼写知识E(PLOME)结合了语音和笔划,这使得它能够模拟任意字符之间的相似性。(3)mOdel与错误拼写知识E(PLOME)是第一个在字符和语音级别上模拟这个任务。
1.相关工作
在自然语言处理中,中文拼写改正是一项具有挑战性的任务,它在搜索引擎(Martins and Silva,2004;Gao等,2010)、自动作文评分(Burstein and Chodorow,1999;Lonsdale and Strong-Krause,2003)和光学字符识别(Afli et ai,2016;Wang et ai,2018)等许多应用中发挥了重要作用。这是一个积极的主题,近年来提出了各种办法(Yu and Li, 2014;Wang et ai, 2018, 2019;Zhang et ai, 2020;Cheng et ai, 2020)。
早期的中文拼写纠正(CSC)工作遵循了错误识别、候选生成和选择的流程。一些研究人员侧重于无监督的方法,通常采用混淆集来找到正确的候选人,并使用语言模型来选择正确的候选人(Chang,1995;Huang et ai,2000;Chen et ai,2013;Yu and Li,2014;Tseng et ai,2015)。然而,这些方法未能对输入句子进行修正。为了对输入上下文建模,使用鉴别序列标记方法(Wang et ai,2018)和序列到序列生成模型(Chollampatt et ai,2016;Ji et ai,2017;Ge et ai,2018;Wang et ai,2019)。
BERT(Devlin等,2019)是基于Transformer编码器的双向语言模型(Vaswani等,2017)。在诸如问答(Yang et ai.,2019)、信息提取(Lin et ai.,2019)和语义匹配(Reimers and Gurevych,2019)的广泛应用中已经证明其有效。最近,它主导了汉语拼写改正(CSC)的研究(Hong et ai,2019;Zhang et ai,2020;Cheng et ai,2020)。Hong et ai.(2019)采用以BERT为编码器的DAE-解码器模式。Zhang et ai(2020)引入了检测网络来为基于BERT的校正网络生成掩蔽向量。Cheng et ai(2020)利用图卷积网络(GCN)(Kipf和Welling,2016)结合BERT来建模字符相互依赖性。然而,BERT的设计和预训练独立于中文拼写校正(CSC)任务,因此它并不是最优的。为了提高中文拼写纠正的性能,我们提出了一个任务特定的语言模型。
1.方法
在本节中,我们介绍了带有错误拼写知识(PLOME)的mOdel及其详细实现。图2展示了PLOME的预训掩蔽语言mOdel的框架。类似于BERT(Devlin et ai.,2019),所建议的模型也遵循预训练和微调范例。在以下几个小节中,我们首先介绍了基于混淆集的掩蔽策略,然后给出了具有误拼知识E(PLOME)的预训练掩蔽语言mOdel的体系结构和学习目标,最后给出了微调的细节。
1.基于模糊集的掩蔽策略

为了训练mOdel,我们随机地掩蔽一些百分比的输入Token,然后恢复它们。Devlin et ai.(2019)用固定Token“[MASK]”替换所选Token,该固定Token在下游任务中不存在。在对比之下,我们删除这个Token,并用一个类似于它的随机字符替换每个选择的Token。类似的字符是从公开可用的混淆集(Wu et ai.,2013)获得的,该混淆集包含两种类型的类似字符:语音相似和视觉相似。由于语音错误是视觉错误的两倍(Liu et ai,2010),这两种类型的相似字符被分配不同的机会在掩蔽期间选择。Devlin et ai(2019)之后,我们完全屏蔽了语料库中15%的Token。此外,我们使用动态掩蔽策略(Liu et ai,2019),其中每次将序列馈送到模型中时生成掩蔽模式。
总是用混淆集中的字符替换所选的Token会导致两个问题。模型倾向于对所有输入作出校正决定,因为在训练前要预测的所有Token“拼错”。为了避免这个问题,所选Token按一定的百分比保持不变。混淆集的大小是有限的,然而,拼写错误可能是由于在真实文本中任意一对字符的误用。为了提高泛化能力,我们用词汇表中的随机字符替换某些百分比的选定标记。总结,如

果选择第i个Token,我们将其替换为(i)时间的60%的随机语音相似字符(ii)时间的15%的随机视觉相似字符(iii)时间的15%的未改变的第i个Token(iv)时间的10%的词汇表中的随机Token。表1给出了不同掩蔽策略的示例。
1.嵌入层
如图2所示,每个字符的最终嵌入是字符嵌入、位置嵌入、语音嵌入和形状嵌入的总和。前两个是通过查找嵌入表获得的,其中词汇表和嵌入维度的大小与BERTfo,se中的相同(Devlin等,2019)。
在汉语中,语音(又称拼音)代表一个字符的发音,这是一个小写字母序列

带有发烧。在本文中,我们使用UnihanDatabase3来获得字符-语音映射(删除了发音符号)。为了建模字符之间的语音关系,我们将每个字符发音的字母送到1层GRU(Bah-danau等人,2014)网络以生成发音嵌入,其中类似的发音预期具有相似的嵌入。图3中的中间部分给出了一个示例。
形状嵌入我们使用笔画顺序4来表示字符的形状,该笔画顺序指示汉字笔画的书写顺序。笔划是书写工具在书写表面上的运动。本文利用Chaizi数据库5获取笔画数据。为了建模字符之间的视觉关系,将每个字符的笔画顺序馈送到另一个1层GRU网络中,以生成形状嵌入。图3中的底部给出了一个示例。
1.Transformer编码器
Transformer编码器具有与BERRQse(Devlin等,2019)中相同的结构。Transformer层的数量(Vaswani等,2017)是12,隐藏单元的尺寸是768,并且关注头的数量是12。更详细的配置请参阅Devlin et ai(2019)。
1.输出层
如图2所示,我们的模型对每个选定的字符进行两次预测。
字符预测与BERT相似,PUOME预测每个字符的原始字符掩蔽Token,基于最后一个Transformer层生成的嵌入。给定句子中z-lhToken所预测的字符的概率定义为:
![]()
其中pc(yi=J|A")是z-lhTokenXi的真实字符被预测为词汇表中第J个字符的条件概率,hi表示Xi的最后转换层的嵌入输出,Wc G R"x7"、x和bc G R"词汇表是字符预测的参数,
发音预测共有430种不同发音(以发音表示),但共有2500多个常用字符。因此,许多字符具有相同的发音。此外,有些发音非常相似,很容易被滥用,例如“京”和“晋”。因此,语音错误主导着汉语拼写错误。实际上,大约80%的拼写错误是语音的(Zhang等人,2020年)。为了从语音水平上学习拼写错误的知识,PUOME还预测每个掩蔽Token的真实发音,其中发音由发音没有发音符号地呈现。发音预测的概率定义为:
![]()
其中pp(gi=k\X)是掩蔽字符Xi的正确发音被预测为语音词汇表中的第fc个发音的条件概率,hj表示Xi、W、Grupx768和bp GRn的最后Transformer层的嵌入输出?是语音预测的参数,np是语音词汇表的大小。
1.知识
学习过程通过优化分别对应于字符预测和发音预测的两个目标来完成的
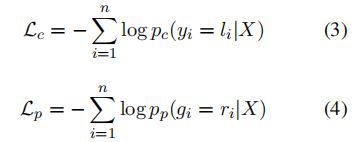
其中Lc是字符预测的优化目标吗,Li是Xi的真实值,Lp是发音预测的优化目标,ri是发音的真实值,
总体的优化目标是![]()
1.微调过程
以上小节介绍了预训练的细节。在本小节中,我们介绍了微调过程。针对中文拼写改正(CSC)任务,设计了带有误拼知识预训练掩蔽语言MLOdel(PLOME),目的是检测和改正中文文本中的拼写错误。形式上,给出一个字符序列
![]()
由n个字符组成,期望该模型生成目标序列
![]()
,其中,错误被校正。
学习目标与训练前程序完全相同(见第3.5节)。这个过程类似于预训练,只是:(1)消除了第3.1节中引入的掩蔽操作。(2)所有输入字符都需要预测,而不是像预训练中那样只选择Token。
如第3.4节所示,具有误拼知识(PLOME)的预先训练的掩蔽语言mOdel预测每个掩蔽Token的字符分布和发音分布。我们把联合分布改为:
其中Pj(yi=j|X)是结合字符和发音预测将Xi的原始字符预测为第J字符的概率,pc和pp在等式1和等式2中分别定义,jp是第J字符的发音。为此,我们构造了一个指标矩阵I G其中Jpj被设置为
1,如果z-lh字符的发音是第J个发音,否则设置为0。然后,可以通过以下步骤计算联合分布:
![]()
其中0是按元素生成的。
我们使用联合概率作为预测分布。对于每个输入Token,具有最高联合概率的字符被选择为最终输出:yi=argmax Pj(j/i|A”)。联合分布同时考虑字符和发音预测,因此更准确。我们将在第4.5节中核实。
实验实验
在本节中,我们介绍了使用错误拼写知识(PLOME)对训练前掩蔽语言mOdel进行预处理的细节以及在使用最广泛的基准数据集上进行微调结果的细节。
训练前
数据集我们使用wiki2019zh6作为训练前语料库,该语料库由100万个中文维基7页组成。此外,我们还从中国新闻平台收集了300万篇新闻文章。我们把这些书页和文章分成句子,总共得到1.621亿句。然后,我们连接连续的句子以获得最多510个字符的文本片段,它们被用作训练实例。
参数设置我们分别用dc、di、ds表示字符嵌入、字母嵌入和笔画嵌入的维度,用hp表示语音和形状GRU网络中隐藏状态的维度。然后我们有dc=768,di=ds=32,hp=hs=768。Transformer编码器的配置与BERT{,ase(Devlin et ai,2019))中的配置完全相同,并且学习率被设置为5e-5。这些参数基于经验设置,因为预训练成本大。如果采用参数调整技术(例如,网格搜索),则可以实现更好的性能。此外,我们采用google8发布的中文BERT参数来初始化Transformer块,而不是从头开始训练带有错误拼写知识的预训练掩蔽语言mOdel(PLOME)。
微调
Cheng et ai(2020)训练数据由来自SIGHAN(Wu et ai,2013;Yu et ai,2014;Tseng et ai,2015)的10K人工注释样本和来自Wang et ai(2018)的271K自动生成的样本组成。
评估数据我们使用Zhang et ai(2020)中的最新SIGHAN测试数据集(Tseng et ai,2015)来评估所提议的模型,该模型包含1100个文本和461种类型的错误。
在以前的工作之后(Cheng et ai.,2020;Zhang et ai.,2020),我们使用
6https://github.com/suzhoulir/nlp_Chinese_corpedia.org/wiki/8https://github.com/google-research/bert
精度、召回和F1分数作为评估指标。除了字符级评估之外,我们还报告关于检测和校正子任务的句子级度量。我们使用来自Chenget ai.(2020)9的脚本来评估这些度量。

表2:我们方法的绩效和基线模型。后两组的结果来自我们的实施Cheng et ai(2020),我们运行实验4次并报告平均度量。
Chenget ai(2020)中的参数设置,将最大句长设置为180,批量设置为32,学习速率设置为5e-5。所有实验进行4次,并报告平均度量。代码和经过训练的模型将发布(当前代码附加在补充文件中)。
基准模型
我们使用以下方法进行比较。
Hybird(Wang et ai.,2018)使用在自动生成的数据集上训练的基于BiLSTM的模型。
PN(Wang等,2019)是结合指针网络的Seq2Seq模型。
FASPell(Hong et ai.,2019)采用DAE-Decoder模式,采用BERT作为去噪自动编码器。
SKBERT(Zhang et ai.,2020)在BERT中引入了软混合策略,以提高错误检测的性能。
SpellGCN(Cheng et ai.,2020)将图卷积网络(GCN)网络与BERT结合以建模给定混淆集中的字符之间的关系。
此外,我们实现了一个基线模型cBERT(基于混淆集的BERT), 其输入和编码层与BERTbase(De-De-BERT)相同
9https://github.com/ACL2020SpellGCN/SpellGCNvlin等人,2019年。输出层类似于 E(PLOME)的预训练掩蔽语言mOdel,但是仅具有如等式1中定义的字符预测。cBERT还通过基于混淆集的掩蔽策略进行预训练。
1.主要结果
表2说明了所提出方法和基线模型的性能。在Lirst组中给出了最近提出的模型的结果。在第二组和第三组中分别给出了预训练模型和微调模型的结果。我们从这张桌子上观察到:
1.在不进行微调的情况下,中间组的预训练模型取得了较好的效果,甚至优于有监督的PN,取得了显著的效果。这表明基于混淆集的掩蔽策略使得我们的模型能够在训练前学习任务特定的知识。
2.与精细模型相比,cBERT在所有指标上均优于BERT。特别地,句子级评价的F分提高了超过4个绝对点。通过如此大量的训练数据(281k个文本),改进是显著的,这表明所提议的掩蔽策略提供了基本知识,并且不能从微调中学习。
3.结合语音和形状嵌入,PLOME-Finetune优于cBERT-Finetune2.3%和2.8%。这表明字符的语音和笔划提供了有用的信息,很难从混淆集中学到它。
4.SpellGCN和我们的方法使用相同的con-
融合集(2013年),但采用不同的策略学习其中的知识。SpellGCN建立了一个图形卷积网络(GCN)网络来模拟这些信息,而带有错误拼写知识的预训练掩蔽语言mOdel(PLOME)则从训练前的大量数据中提取该信息。预先训练的带有错误拼写知识的掩蔽语言mOdel(PLOME)在所有度量上都取得了更好的性能,表明我们的方法对于这些知识建模更有效。
![]()
表3:对整个测试集进行评价的实验结果。FPR表示假阳性率,A表示准确性,通过SIGHAN2015官方工具进行评价。
![]()
表4:PLOME字符预测pc联合预测pj作为产出。
先前的工作(Wang et ai.,2019;Cheng et ai.,2020)对包含至少一个错误的阳性句子进行字符级评价(在整个测试集上评价句子级度量)。因此,精度分数非常高。表2中的字符级结果也以这种方式评价,以便公平比较。为了进行更加全面的评价,我们在表3的整个测试集上报告了评价的结果。此外,根据Cheng et ai(2020),我们还报告了SIGHAN官方工具评估的句子级结果。我们观察到,在所有指标上,具有误拼知识(PLOME)的预训练掩蔽语言mOdel始终优于BERT和SpellGCN。
为了进行更全面的比较,我们还对SIGHAN13(Wu等人,2013年)和SIGHAN14(Yu等人,2014年)的拟议模型进行评估。紧随Cheng et ai(2020)之后,我们又在SIGHAN 13上执行了6个精细周期,因为其数据分布不同于其他数据集。表5显示了结果,从中我们观察到带有误拼知识(PLOME)的预训练掩蔽语言mOdel始终优于所有比较模型。
表5:SIGHAN 13和SIGHAN 14上具有误拼知识预训练掩蔽语言mOdel(PLOME)的字符级性能。
1.预测策略的影响
如第3.4和3.6节所示,带有误拼知识E(PLOME)的预训练掩蔽语言mOdel预测每个字符的三个分布:字符分布pc、发音分布pp和联合分布pj。后两种分布与语音预测有关,在本文中首先介绍。在本小节中,我们研究了预训练掩蔽语言mOdel的误拼知识(PLOME)的性能,其中每一个作为线性输出。汉字拼写校正(CSC)任务需要字符预测,因此仅比较字符预测pc和联合预测pj的效果。
表4给出了实验结果,从中我们观察到联合分布在所有评价度量上优于字符分布。特别是精度分数的差距更为明显。联合分布同时具有字符和语音前音
因此,预测结果更准确。
![]()
表6:cBER和PLOME不同的初始化策略。**-兰德表示所有参数被随机初始化,并且’-BER表示参数由BERT初始化。
1.初始化策略的影响
一般来说,初始化策略对深模型的性能有很大的影响。在本小节中,我们研究了不同初始化策略在训练前过程中的影响。为了比较,我们实现了基于cBERT和带有错误拼写知识的预训练掩蔽语言mOdel(PLOME)的四个基线。
表6说明了结果,其中命名为“-Rand”的方法随机初始化所有参数,命名为“-BERT”的方法通过Google发布的BERT初始化Transformer编码器。从表中我们观察到,用BERT初始化的 (PLOME)的cBERT和预训练掩蔽语言mOdel都取得了更好的性能。尤其,对于所有评价而言,召回得分显著提高。1)BERT中丰富的语义信息能有效地提高泛化能力。2)具有误码知识的预训练掩蔽语言mOdel(PLOME)由两个1层GRU网络和一个12层Transformer编码器组成,共包含110M以上的参数。当从零开始训练这样一个大型模型时,很容易陷入局部最优。
1.声形/形状嵌入可视化
在本小节中,我们研究了语音和形状GRU网络是否为字符带来了有意义的表示。为此,我们通过图2中的GRU网络为每个字符生成语音和形状嵌入s,然后将它们可视化。
图4展示了根据GRU网络生成的768-dim嵌入的余弦相似性最接近的30个字符,通过t-SNE可视化(Maaten和Hinton,2008)。一方面,几乎所有类似于“t^”的字符都包含在其中

图4:形状嵌入的可视化。

图5:语音嵌入的可视化。
数字。另一方面,类似的字符彼此非常接近(用圆圈标记)。这些现象表明所习得的形状嵌入井模拟了形状相似性。图5显示了与“ding”相关的语音嵌入的相同情况,并演示了其建模语音相似性的能力。
1.各种模型的转换速度
在本小节中,我们研究了Hne调谐过程中各种模型的收敛速度。图6显示了错误拼写知识(PLOME)的BERT、cBERT和预训练掩蔽语言mOdel的字符级检测度量的测试曲线。由于基于混淆集的掩蔽策略,cBERT和带误拼知识预训练掩蔽语言mOdel(PLOME)在训练前学习任务专有知识,因此它们在训练开始时比BERT获得更好的性能。随着训练的进行,差距逐渐缩小
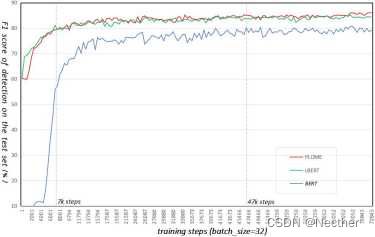
图6:微调过程中各种模型的字符级检测度量的测试曲线。
在最初的35, 000步之后保持稳定,间隙为6%(86%vs.80%)。此外,所建议的模型需要少得多的训练步骤来实现相对良好的性能。预训练掩蔽语言mOdel与错误拼写知识(PLOME)只需要7k步达到80%,而BERT需要47k步。
1.结论
我们提出了PLOME,一个带有拼写错误知识的预先训练掩蔽语言模型,用于中文拼写校正(CSC)。基于误拼知识预训练掩蔽语言MLOdel(PLOME)是汉语拼写纠正(CSC)的第一种任务型语言模型,它利用基于混淆集的掩蔽策略联合学习语义和拼写错误。之前的研究表明汉字之间的语音和视觉相似性是完成这项任务的关键。我们引入语音和形状GRU网络来模拟这些特征。此外,具有误拼知识的预训练掩蔽语言mOdel(PLOME)也是第一个通过联合考虑目标发音和字符分布来进行决策的模型。实验结果表明,具有误拼知识的预训练掩蔽语言MLOdel(PLOME)优于所有模型并取得显著成绩。
致谢
我们感谢雷和、郑成聪和王维康的有益讨论,并感谢匿名评论家的深刻评论。