【11月机器学习】Introduction
文章内容仅供参考,不能保证百分百正确,如有错误,感谢各位大佬在评论区指出,求亲喷orz。
视频参考链接 1-机器学习介绍_哔哩哔哩_bilibili
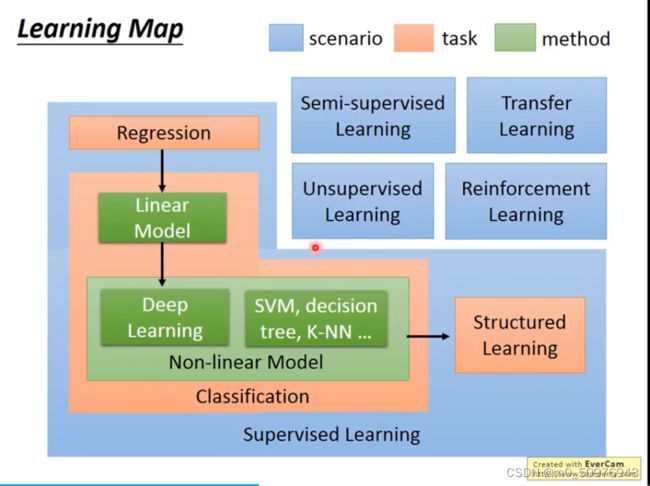
Scenario
Supervised Learning (监督学习)
监督学习在基于大量数据标注的基础上学习,大部分研究均基于此。见得多,学的多,但也有可能看某一类东西太多(样本不平衡),导致机器出现“倾向性”判断。
Semi-Supervised Learning (半监督学习)
李宏毅老师在视频中举的猫狗识别例子,即有一部分猫狗有标签和一部分猫狗没有标签的这样一批数据同时丢给机器学习,用于猫狗识别任务。这一部分没有标签的数据同样能起作用,具体什么作用,李老师留了一个悬念,那我先百度为快orz。
参考链接(本文简单整理自己觉得重要的,更多建议看原链接)
半监督学习 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/349107869
https://zhuanlan.zhihu.com/p/349107869
半监督深度学习小结 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/33196506
半监督学习笔记(一) - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/411533418
Why (why we need ?)
1、现实的数据往往缺乏标签;
2、数据标注过程的高成本;
3、很多任务很难获得如全部真实标签这样的强监督信息;
How ( How to do?)
1、简单自训练 / simple self-training / 伪标签技术
一句话就是用少量有标签的数据和模型预测的无标签数据(伪标签数据)去训练模型,直到训练结果不发生改变。这里的loss function值通常用选择无标签数据进行计算。
也是一种数据增广的方式
2、协同训练 / co-training / 基于分歧的方法
不同的分类器从不同的角度进行训练,再选出认为可信的无标签样本加入训练集中。
和1的关系感觉就像随机森林和决策树的关系?
通过使用多个学习器来对未标记数据进行利用,在学习过程中将未标记数据作为多学习器间信息交互的媒介,从而达到一个协同训练的目的。
3、生成式半监督模型
基于生成式模 型的方法假设所有数据均由相同的生成式模型产生,借助模型参数将未标记数据与学习目标联系起来,通常利用 EM 算法根据极大似然来估计模型参数,典型的例子就是半监督版的高斯混合模型。
(有点复杂的数学理论,暂时放放,欢迎大佬评论区教学orz)
4、基于图的半监督算法
图这样一种结构自带节点信息和边的信息,可以通过节点之间信息的沟通对节点标签进行更新。比如之前做研究用过的Fast-Unfolding算法等等。
Requirement / Assumption
俗话说,上帝给你关上一道门,同时给你打开一扇窗。半监督学习在极大减少了数据量的同时,也会对数据有更多的要求。
1 无标签数据一般是有标签数据中的某一个类别的(不要不属于的,也不要属于多个类别的);
2 有标签数据的标签应该都是对的;
3 无标签数据一般是类别平衡的(即每一类的样本数差不多);
4 无标签数据的分布应该和有标签的相同或类似。
此外,机器学习等数据驱动的方法对数据有着一些相同的要求:
1 数据特征筛选是否有效;
2 数据质量是否可靠;
3 分类问题中数据类别数目是否平衡...
半监督学习中有三大基本假设
1、平滑假设 (Smoothness Assumption)
位于稠密数据区域(C2)的两个距离很近的样例的类标签相似,也就是说,当两个样例被稠密数据区域中的边连接时,它们在很大的概率下有相同的类标签;相反地,当两个样例被稀疏数据区域分开时,它们的类标签趋于不同。
所谓稠密数据区域,即样本之间的距离都比较接近,如左下图,而稀疏数据如点O1,虽然O1看起来和左下的样本比较接近,但我们不能像聚类或者knn那样以距离的相对远近作为评价直接将其划归为其中一类;
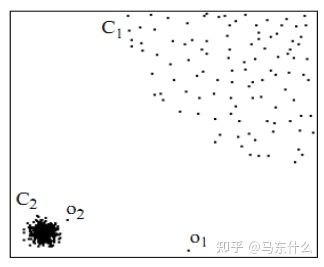
(不是非黑即白的世界,是这意思?)
2、聚类假设(Cluster assumption)
平滑假设的一个特例,数据出现明显的簇。
3、流形假设(Manifold assumption)
用于支撑高维数据依然满足1、2假设的假设。
假定如果高维样本恰好可以映射到一个低维的流形结构上,此时在低维的流型空间中,前两大假设仍旧是可以成立的
关于流形学习就又是一个可以展开很多的东西了。
简单来说,流形学习将高维数据映射到低维,进一步揭示其本质。(真的好简单哈哈哈哈哈哈)
Transfer Learning (迁移学习)
这个与半监督学习差不多,但是在数据上,如果是猫狗识别,有一部分是有标签的猫狗图片,而另外一部分则是无标签的不只有猫狗的图片。
这个其实在本专业用的挺多的,大部分经典的深度学习模型比如U-net,最初用于医学影像分割。在pytorch等框架中都会有预训练模型,含有一些超参数值,在用于遥感影像分割任务训练时会有一个好的开始,或者说冻结前几层,保证前几层的浅层特征提取作用。机器学习上还有待体验,比如随机森林中是否可以冻结部分决策树。
Unsupervised Learning (无监督学习)
对我来说像是一个终极模型了,喂给模型一堆没有任何标签的数据,让其自己学习,很神奇。
Reinforement Learning (强化学习)
其实我一直觉得强化学习和无监督学习比较相似,强化学习的优化方式是外界的奖惩结果,无监督学习依赖的应该还是损失函数吧?(这里不是很确定)
Task
Structure Task
结构化任务。李宏毅老师给出的一个例子是翻译。
输出是彼此有前后依赖关系的。
目前感觉这个东西在像素级图像分割上会有用?空间上的依赖关系
其实上面的每一个小标题都有很多拓展内容,一篇博客无法涵盖全部,希望自己后续能慢慢理解、完善。
感谢大家看到这里,今天暂时到这里啦,掰掰ヾ(•ω•`)o。
btw,感觉这篇文章太多理论,少了模型应用,下次改进!
