3D Instance Segmentation via Multi-Task Metric Learning
Abstract
我们提出了一种新方法,用于密集 3D 体素网格的实例标签分割。我们的目标是使用深度传感器或多视图立体方法获取的体积场景表示,并使用语义 3D 重建或场景完成方法进行处理。主要任务是学习有关单个对象实例的形状信息,以便准确地分离它们,包括连接的和不完全扫描的对象。我们使用多任务学习策略解决了 3D 实例标记问题。第一个目标是学习一个抽象特征嵌入,它将具有相同实例标签的体素彼此靠近,同时将具有不同实例标签的集群彼此分开。第二个目标是通过密集估计每个体素的实例质心的方向信息来学习实例信息。这对于在聚类后处理步骤中找到实例边界以及对第一个目标的分割质量进行评分特别有用。合成和真实世界的实验都证明了我们方法的可行性和优点。事实上,它在 ScanNet 3D 实例分割基准 [5] 上实现了最先进的性能。
1. Introduction
计算机视觉研究的中心目标是高级场景理解。 2D 图像的最新方法学进展使得各种计算机视觉问题的可靠结果成为可能,包括图像分类 [24、44、48]、图像分割 [1、32、42]、对象检测 [30、39、41] 和实例二维图像中的分割[9,18,37]。此外,现在可以使用低成本深度传感器 [20,35,47,55] 或使用基于图像的 3D 重建算法 [12,22,43] 恢复高度详细的 3D 几何形状。结合这两个概念,已经开发了许多算法用于 3D 场景和对象分类 [33、45、51]、3D 对象检测 [26、52],以及联合 3D 重建和语义标记 [4、6、7、25、49 ]。
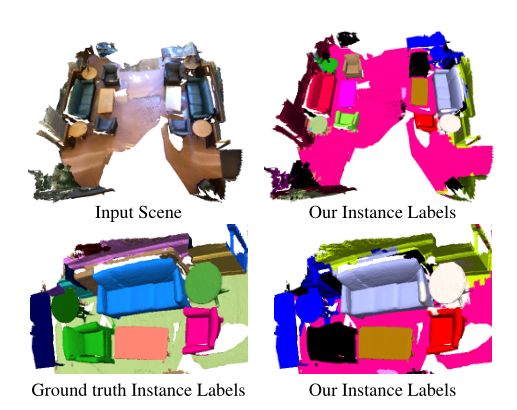
图 1. 我们方法的示例结果。我们提出的方法将 3D 点云作为输入,并输出场景中每个对象唯一的实例标签。标签是通过学习一个度量来生成的,该度量将同一对象实例的部分分组并估计朝向实例质心的方向。
2D 实例分割的进步主要是由 2D 领域中可用的大量数据集和挑战推动的。与 2D 图像的实例分割等众多强大方法相比,3D 对应问题在文献中的探索较少。除了缺乏数据集之外,大多数 2D 方法不适用于 3D 设置,或者它们的扩展绝不简单。
随着用于 3D 实例分割任务的标记数据集和基准(例如 ScanNet [5])的出现,许多工作已经浮出水面来解决这项任务。在许多情况下,3D 工作受益于 2D 的开创性工作,以及允许处理 3D 输入数据的修改。因此,这种 3D 处理往往类似于其他 3D 理解技术,主要是语义分割。
在本文中,我们解决了 3D 实例分割的问题。给定场景的 3D 几何图形,我们希望使用唯一标签标记属于同一对象的所有几何图形。与之前将实例标签与语义标签纠缠在一起的方法不同,我们提出了一种主要关注实例标签的技术,该技术通过对与单个对象有关的信息进行分组/聚类来进行实例标签。我们的方法仍然受益于作为局部提示的语义信息,但添加了与 3D 维度和 3D 连接相关的信息,其有用性是 3D 设置所独有的。
特别是,我们提出了一种处理 3D 体素网格并学习两个主要特征的学习算法:(1)每个实例唯一的特征描述符,以及(2)指向实例中心的方向。我们的方法旨在提供一种独立于场景大小和其中实例数量的分组力。
Contributions. 我们的贡献是双重的。 (i) 我们提出了一种多任务神经网络架构,用于基于体素的场景表示的 3D 实例分割。除了度量学习任务之外,我们还要求我们的网络预测到对象中心的方向信息。我们证明了多任务学习改善了这两个任务的结果。我们的方法稳健且可扩展,因此适用于处理大量 3D 数据。(ii) 我们的实验证明了 3D 实例分割的最新性能。在提交时,我们的方法在 ScanNet 3D 实例分割基准 [5] 上的平均 AP50 得分排名第一。
2. Related Work
本节简要概述了相关的 2D 和 3D 方法。值得注意的是,基于二维深度学习的语义分割和实例标签分割存在大量相关工作。最近的调查可以在 [13, 16] 中找到。
2D Instance Segmentation via Object Proposals or Detection. Girshick [14] 提出了一种网络架构,可以创建区域建议作为候选对象段。在一系列后续工作中,这个想法已经被扩展为更快[41],并额外输出像素精确的掩码以进行实例分割[18]。 YOLO [39] 及其后续工作 [40] 的作者应用了基于网格的方法,其中每个网格单元生成一个对象建议。 DeepMask [37] 学习联合估计对象建议和对象分数。 Lin 等人 [30] 提出了一种用于目标检测的多分辨率方法,他们称之为特征金字塔网络。在 [17] 中,区域建议通过预测到边界的距离的网络进行细化,然后将其转换为二进制对象掩码。 Khoreva 等人 [21] 联合执行实例和语义分割。类似的路径遵循[27],它将用于语义分割的完全卷积网络与实例掩码提议相结合。 Dai 等人 [9] 使用全卷积网络 (FCN) 并将问题拆分为边界框估计、掩码估计和对象分类,并提出了一种多任务级联网络架构。在后续工作 [8] 中,他们将 FCN 与窗口化的实例敏感分数图相结合。
尽管所有这些方法在 2D 领域都非常成功,但其中许多方法需要大量资源,并且它们向 3D 领域的扩展并非易事且具有挑战性。
2D Instance Segmentation via Metric Learning. Liang 等人 [28] 提出了一种没有对象提议的方法,因为它们直接估计边界框坐标和置信度,并结合聚类作为后处理步骤。 Fathi 等人 [10] 通过在嵌入空间中将相似像素分组在一起来计算像素属于同一对象的可能性。 Bai 和 Urtasun [2] 学习了可以轻松预测对象实例的图像能量图。 Novotny 等人 [36] 学习了一个位置敏感度量(半卷积嵌入),以更好地区分同一对象的相同副本。 Kong 和 Fowlkes [23] 训练了一个将所有像素分配给球形嵌入的网络,其中同一对象实例的点在附近,而与非实例相关的点彼此分开放置。然后通过变体提取实例DeBrabandere 等人 [3] 的方法遵循相同的想法,但作者并未对嵌入空间的形状施加限制。同样,他们通过特征空间中的均值偏移聚类计算最终分割。
这些方法都没有应用于 3D 设置。我们的方法建立在 DeBrabandere 等人 [3] 的工作之上。我们使用多任务方法扩展了这种方法,用于在密集体素网格上进行 3D 实例分割。
3D Instance Segmentation. Wang 等人 [50] 提出了 SGPN,一种 3D 点云的实例分割。在第一步中,他们使用 PointNet [38] 提取特征,然后构建一个相似度矩阵,其中每个元素对两个点是否属于同一个对象实例进行分类。该方法的可扩展性不是很强,并且仅限于小点云大小,因为相似度矩阵的大小是点云中点数的平方。此外,最近有许多并发或未发表的作品涉及 3D 实例分割。 GSPN 方法 [54] 提出了一种生成形状提议网络,它依赖于对象提议来识别 3D 点云中的实例。 3D-SIS 方法 [19] 结合了从多个 RGB-D 输入视图聚合的 2D 和 3D 特征。 MASC [31] 依赖于 SparseConvNet [15] 架构的卓越性能,并将其与跨多个尺度估计的实例亲和力得分相结合。 PanopticFusion [34] 预测 RGB 帧的像素级标签,并将它们传送到 3D 网格中,其中使用完全连接的 CRF 进行最终推理。

图 2. 我们的网络架构概述。我们将 3D 实例分割视为一个多任务学习问题。我们方法的输入是一个体素网格,输出是两个潜在空间:1)一个特征向量嵌入,它在潜在空间中将具有相似实例标签的体素分组; 2) 一个 3D 潜在空间,为每个体素编码方向预测。我们网络的输入和输出在图 3 中进行了可视化和解释。图中的参数对应于(过滤器数量、内核大小、步幅、扩张)。
3. Method Overview
在这项工作中,我们的目标是在给定的 3D 场景中分割 3D 实例。要完全定位 3D 实例,需要语义标签和实例标签。我们不是一次解决场景完成、语义标记和实例分割的复杂任务,而是将我们的 3D 实例分割过程建模为语义分割标记的后处理步骤。我们专注于语义标签的分组和拆分,依赖于实例间和实例内的关系。我们受益于 3D 场景中的真实距离,其中对象之间的大小和距离是最终实例分割的关键。
我们将任务分为标签分割和实例分割问题,因为我们相信在每一步中学习到的特征都具有特定于任务的信息。语义分割一方面可以依靠局部信息来预测类标签。学习对体积表示进行语义标记会固有地对相邻体积的特征进行编码,但不需要了解整个环境。另一方面,实例分割需要对场景有一个整体的理解,以便加入或分离语义标记的卷。
Problem Setting. 我们方法的输入是一个体素化的 3D 空间,每个体素编码一个语义标签或通过语义标签学习的局部特征向量。在本文中,我们使用[15]中的语义标记网络。我们固定体素大小以保持场景中所有体素之间的 3D 距离。在点云或网格可用的问题设置中,可以通过对来自每个体素内的点的信息进行分组来生成 3D 体素化。然后,我们的方法处理体素化的 3D 空间并输出实例标签掩码,每个标签掩码对应于场景中的单个对象,连同它的语义标签。输出掩码也可以通过将体素标签分配给其中的所有点来重新投影回点云。
3.1. Network Architecture
为了处理 3D 输入,我们利用基于 SSCNet 架构的 3D 卷积网络 [46]。我们对原始的 SSCNet 网络进行了一些更改,以更好地适应我们的任务。如图 2 所示,网络输入和输出大小相同。由于池化层缩小了场景大小,我们使用卷积转置(也称为反卷积 [56])将上采样回原始大小。我们还对稀释的 3D 卷积层使用更大的膨胀来增加感受野。我们使感受野足够大,可以访问通常室内房间的所有体素。体素大小为 10cm,我们的感受野高达 14.2m。对于更大的场景,我们的 3D 卷积网络仍然适用于整个场景,同时保留过滤器和体素大小,从而保留真实距离。默认情况下,距离大于感受野的对象是分开的。
3.2. Multi-task Loss Function
为了对同一实例的体素进行分组,我们的目标是学习两种类型的特征嵌入。第一种类型将每个体素映射到一个特征空间,其中相同实例的体素比属于不同实例的体素更接近。这类似于 DeBrabandere 等人 [3] 的工作,但应用于 3D 设置。第二种类型的特征嵌入为每个体素分配一个 3D 向量,其中该向量将指向它所属对象的物理中心。这使得能够学习形状包含并消除相似形状之间的歧义。
为了学习这两种特征嵌入,我们引入了一个在训练期间最小化的多任务损失函数。损失的第一部分鼓励在多个实例之间的特征空间中进行区分,而第二部分则惩罚向量与期望的角度偏差方向。
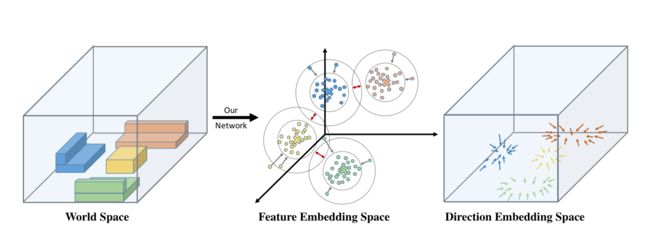
图 3. 嵌入空间可视化。在世界空间(左)中具有相似实例标签的体素被映射:(1)到特征嵌入空间中的相似位置,使得实例形成集群(中)和(2)到指向对象中心的方向向量(右) )。红色箭头表示聚类中心之间的类间推力,而灰色箭头表示点和聚类中心之间的类内拉力。其他颜色区分不同对象实例的体素或特征。
Feature Embedding Loss. 我们遵循 DeBrabandere 等人 [3] 的工作,它学习了可以随后聚类的特征嵌入。因此,我们将特征嵌入损失定义为三个项的加权和:(1)一个集群内方差项 L var \mathcal{L}_{\text {var }} Lvar ,它将应该属于同一实例的特征拉向平均特征,(2)一个集群间距离项 L dist \mathcal{L}_{\text {dist }} Ldist 鼓励将具有不同实例标签的集群推开,以及 (3) 一个正则化项 L reg \mathcal{L}_{\text {reg }} Lreg ,它将所有特征拉向原点以限制激活。
L F E = γ v a r L v a r + γ d i s t L d i s t + γ r e g L r e g (1) \mathcal{L}_{\mathrm{FE}}=\gamma_{\mathrm{var}} \mathcal{L}_{\mathrm{var}}+\gamma_{\mathrm{dist}} \mathcal{L}_{\mathrm{dist}}+\gamma_{\mathrm{reg}} \mathcal{L}_{\mathrm{reg}} \tag{1} LFE=γvarLvar+γdistLdist+γregLreg(1)
各个损失函数由 γ v a r = γ d i s t = 1 \gamma_{\mathrm{var}}=\gamma_{\mathrm{dist}}=1 γvar=γdist=1, γ r e g = 0.001 \gamma_{\mathrm{reg}}=0.001 γreg=0.001加权,其定义类似于 [3],如下所示:
L v a r = 1 C ∑ c = 1 C 1 N c ∑ i = 1 N c [ ∥ μ c − x i ∥ − δ v a r ] + 2 (2) \mathcal{L}_{\mathrm{var}}=\frac{1}{C} \sum_{c=1}^C \frac{1}{N_c} \sum_{i=1}^{N_c}\left[\left\|\boldsymbol{\mu}_c-\mathbf{x}_i\right\|-\delta_{\mathrm{var}}\right]_{+}^2 \tag{2} Lvar=C1c=1∑CNc1i=1∑Nc[∥μc−xi∥−δvar]+2(2)
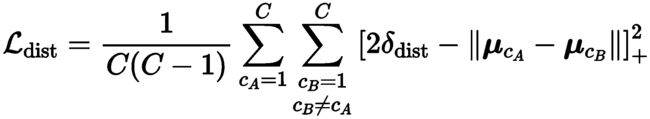
L reg = 1 C ∑ c = 1 C ∥ μ c ∥ (4) \mathcal{L}_{\text {reg }}=\frac{1}{C} \sum_{c=1}^C\left\|\boldsymbol{\mu}_c\right\| \tag{4} Lreg =C1c=1∑C∥μc∥(4)
这里 C C C是ground truth簇的数量, N c N_{c} Nc表示簇 c c c中元素的数量, μ c \boldsymbol{\mu}_c μc是簇中心,即簇 c c c中元素的均值, x i \mathbf{x}_i xi是特征向量。此外,范数 ∥ ⋅ ∥ \|\cdot\| ∥⋅∥表示 ℓ 2 \ell_2 ℓ2-范数, [ x ] + = max ( 0 , x ) [x]_{+}=\max (0, x) [x]+=max(0,x)表示铰链。参数 δ v a r \delta_{\mathrm{var}} δvar描述了特征向量 x i \mathbf{x}_i xi和集群中心 μ c \boldsymbol{\mu}_c μc之间的最大允许距离,以便属于集群 c c c。同样, 2 δ d i s t 2 \delta_{\mathrm{dist}} 2δdist是不同集群中心应该具有的最小距离,以避免重叠。力和嵌入空间的可视化可以在图 3 中找到。不同集群的特征嵌入相互施加力,即每个特征嵌入都受到其他集群中心的数量和位置的影响。这种连接在某些情况下可能是不利的,尤其是当单个场景中存在大量实例时。因此,我们接下来提出一个额外的损失,它提供了实例分离所必需的局部信息,而不受其他实例的影响。
Directional Loss. 我们在这里的目标是生成一个向量特征,该特征将在本地描述集群内的关系,而不受其他集群的影响。我们选择向量作为指向对象的地面实况中心的向量。为了学习这个向量特征,我们关注以下方向损失:
L d i r = − 1 C ∑ c = 1 C 1 N c ∑ i = 1 N c v i ⊤ v i G T with v i G T = z i − z c ∥ z i − z c ∥ (5) \mathcal{L}_{\mathrm{dir}}=-\frac{1}{C} \sum_{c=1}^C \frac{1}{N_c} \sum_{i=1}^{N_c} \mathbf{v}_i^{\top} \mathbf{v}_i^{G T} \quad \text { with } \mathbf{v}_i^{G T}=\frac{\mathbf{z}_i-\mathbf{z}_c}{\left\|\mathbf{z}_i-\mathbf{z}_c\right\|} \tag{5} Ldir=−C1c=1∑CNc1i=1∑Ncvi⊤viGT with viGT=∥zi−zc∥zi−zc(5)
这里, v i \mathbf{v}_i vi表示归一化的方向矢量特征, v i G T \mathbf{v}_i^{G T} viGT是指向对象中心的期望方向, z i \mathbf{z}_i zi是体素中心位置, z c \mathbf{z}_c zc是对象中心位置。
Joint Loss. 我们在训练期间共同最小化特征嵌入损失和方向损失。我们最终的联合损失如下:
L joint = α F E L F E + α d i r L d i r (6) \mathcal{L}_{\text {joint }}=\alpha_{\mathrm{FE}} \mathcal{L}_{\mathrm{FE}}+\alpha_{\mathrm{dir}} \mathcal{L}_{\mathrm{dir}} \tag{6} Ljoint =αFELFE+αdirLdir(6)
我们使用 α F E = 0.5 \alpha_{\mathrm{FE}}=0.5 αFE=0.5和 α d i r = 1 \alpha_{\mathrm{dir}}=1 αdir=1。
Post-processing. 我们在特征嵌入上应用均值偏移聚类[11]。与对象检测算法类似,实例分割不会将标记限制在一个连贯的集合中,因此允许多个对象之间存在重叠。我们使用具有多个阈值的均值偏移聚类输出作为根据其方向特征一致性进行评分的建议。我们还使用连接组件来建议拆分,这将通过其特征嵌入的一致性进一步评分。特征嵌入的连贯性由特征嵌入的数量来描述,该数量位于距离特征聚类中心的给定阈值内。方向特征相干性分数就是 L dir \mathcal{L}_{\text {dir }} Ldir ,它是从体素指向对象中心的归一化向量与预测的归一化方向特征之间的平均余弦相似度。然后,我们对所有对象建议进行排序并执行非最大抑制 (NMS) 以删除重叠超过阈值的对象。最终分数是通过将两个特征嵌入分数与一个分数相加来获得的,该分数鼓励规则大小的对象超过极大或极小的对象。至于语义标签,它被选为聚类体素内所有点中出现次数最多的标签。
3.3. Network Training
Training Data. 在训练期间,我们将体素化场景的翻转以及围绕垂直轴的多个方向附加到我们的训练数据中。我们使用地面实况分割标签作为输入对我们的网络进行预训练,标签 one-hot 编码以保持与使用语义分割输出进行训练相同大小的输入。
5. Conclusion
提出了一种基于体素场景的三维实例分割方法。我们的方法是基于度量学习的,第一部分分配属于邻近的相同对象实例特征向量的所有体素。相反,属于不同对象实例的体素被赋予在特征空间中彼此相距较远的特征。第二部分估计对象中心的方向信息,用于对第一部分生成的分割结果进行评分。
论文链接:https://openaccess.thecvf.com/content_ICCV_2019/papers/Lahoud_3D_Instance_Segmentation_via_Multi-Task_Metric_Learning_ICCV_2019_paper.pdf
References
[1] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla.Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12):2481–2495, 2017.
[2] Min Bai and Raquel Urtasun. Deep watershed transform for instance segmentation. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[3] Bert De Brabandere, Davy Neven, and Luc V an Gool.Semantic instance segmentation with a discriminative loss function. CoRR, abs/1708.02551, 2017.
[4] Ian Cherabier, Johannes L. Schönberger, Martin R. Oswald, Marc Pollefeys, and Andreas Geiger. Learning priors for semantic 3d reconstruction. In Proc. European Conference on Computer Vision (ECCV), September 2018.
[5] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[6] Angela Dai and Matthias Nießner. 3dmv: Joint 3d-multiview prediction for 3d semantic scene segmentation. In Proc. European Conference on Computer Vision (ECCV), pages 458–474, 2018.
[7] Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, Jrgen Sturm, and Matthias Niener. Scancomplete: Large-scale scene completion and semantic segmentation for 3d scans.In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[8] Jifeng Dai, Kaiming He, Yi Li, Shaoqing Ren, and Jian Sun.Instance-sensitive fully convolutional networks. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors, Proc. European Conference on Computer Vision (ECCV), pages 534–549, Cham, 2016. Springer International Publishing.
[9] Jifeng Dai, Kaiming He, and Jian Sun. Instance-aware semantic segmentation via multi-task network cascades. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 3150–3158, 2016.
[10] Alireza Fathi, Zbigniew Wojna, Vivek Rathod, Peng Wang, Hyun Oh Song, Sergio Guadarrama, and Kevin P . Murphy.
Semantic instance segmentation via deep metric learning.CoRR, abs/1703.10277, 2017.
[11] K. Fukunaga and L. Hostetler. The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Transactions on Information Theory, 21(1):32– 40, January 1975.
[12] Y asutaka Furukawa and Jean Ponce. Accurate, dense, and robust multiview stereopsis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(8):1362–1376, 2010.
[13] Alberto Garcia-Garcia, Sergio Orts-Escolano, Sergiu Oprea, Victor Villena-Martinez, and Jose Garcia-Rodriguez. A Review on Deep Learning Techniques Applied to Semantic Segmentation. ArXiv e-prints, April 2017.
[14] Ross B. Girshick. Fast R-CNN. In Proc. International Conference on Computer Vision (ICCV), pages 1440–1448, 2015.
[15] Benjamin Graham, Martin Engelcke, and Laurens van der Maaten. 3d semantic segmentation with submanifold sparse convolutional networks. Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[16] Y anming Guo, Y u Liu, Theodoros Georgiou, and Michael S.
Lew. A review of semantic segmentation using deep neural networks. International Journal of Multimedia Information Retrieval, Nov 2017.
[17] Zeeshan Hayder, Xuming He, and Mathieu Salzmann.
Boundary-aware instance segmentation. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR).
[18] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross B.
Girshick. Mask R-CNN. In Proc. International Conference on Computer Vision (ICCV), pages 2980–2988, 2017.
[19] Ji Hou, Angela Dai, and Matthias Nießner. 3d-sis: 3d semantic instance segmentation of rgb-d scans. Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[20] Shahram Izadi, Richard A. Newcombe, David Kim, Otmar Hilliges, David Molyneaux, Steve Hodges, Pushmeet Kohli, Jamie Shotton, Andrew J. Davison, and Andrew W. Fitzgibbon. Kinectfusion: real-time dynamic 3d surface reconstruction and interaction. In International Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 2011, V ancouver , BC, Canada, August 7-11, 2011, Talks Proceedings, page 23, 2011.
[21] Anna Khoreva, Rodrigo Benenson, Jan Hendrik Hosang, Matthias Hein, and Bernt Schiele. Simple does it: Weakly supervised instance and semantic segmentation. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 1665–1674, 2017.
[22] Kalin Kolev, Maria Klodt, Thomas Brox, and Daniel Cremers. Continuous global optimization in multiview 3d reconstruction. International Journal of Computer Vision, 84(1):80–96, 2009.
[23] Shu Kong and Charless C. Fowlkes. Recurrent pixel embedding for instance grouping. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 9018–9028, 2018.
[24] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton.Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012., pages 1106–1114, 2012.
[25] Abhijit Kundu, Yin Li, Frank Dellaert, Fuxin Li, and James M. Rehg. Joint semantic segmentation and 3d reconstruction from monocular video. In Proc. European Conference on Computer Vision (ECCV), pages 703–718. Springer, 2014.
[26] Jean Lahoud and Bernard Ghanem. 2d-driven 3d object detection in rgb-d images. In Proc. International Conference on Computer Vision (ICCV), pages 4622–4630, 2017.
[27] Yi Li, Haozhi Qi, Jifeng Dai, Xiangyang Ji, and Yichen Wei.Fully convolutional instance-aware semantic segmentation.In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 4438–4446, 2017.
[28] Xiaodan Liang, Liang Lin, Y unchao Wei, Xiaohui Shen, Jianchao Y ang, and Shuicheng Y an. Proposal-free network for instance-level semantic object segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, PP(99):1–1, 2017.
[29] Zhidong Liang, Ming Y ang, and Chunxiang Wang. 3d graph embedding learning with a structure-aware loss function for point cloud semantic instance segmentation. arXiv preprint arXiv:1902.05247, 2019.
[30] Tsung-Yi Lin, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan, and Serge J. Belongie. Feature pyramid networks for object detection. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR).
[31] Chen Liu and Y asutaka Furukawa. Masc: Multi-scale affinity with sparse convolution for 3d instance segmentation. arXiv preprint arXiv:1902.04478, 2019.
[32] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR).
[33] Daniel Maturana and Sebastian Scherer. V oxnet: A 3d convolutional neural network for real-time object recognition.In IEEE/RSJ International Conference on Intelligent Robots and Systems, Pittsburgh, PA, September 2015.
[34] Gaku Narita, Takashi Seno, Tomoya Ishikawa, and Y ohsuke Kaji. Panopticfusion: Online volumetric semantic mapping at the level of stuff and things. arXiv preprint arXiv:1903.01177, 2019.
[35] Matthias Nießner, Michael Zollhöfer, Shahram Izadi, and Marc Stamminger. Real-time 3d reconstruction at scale using voxel hashing. ACM Trans. Graph., 32(6):169:1–169:11, 2013.
[36] David Novotn´y, Samuel Albanie, Diane Larlus, and Andrea V edaldi. Semi-convolutional operators for instance segmentation. In Proc. European Conference on Computer Vision (ECCV), pages 89–105, 2018.
[37] Pedro H. O. Pinheiro, Ronan Collobert, and Piotr Dollár.Learning to segment object candidates. In Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 1990–1998, 2015.
[38] Charles Ruizhongtai Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 77–85, 2017.
[39] Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, and Ali Farhadi. Y ou only look once: Unified, real-time object detection. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 779– 788, 2016.
[40] Joseph Redmon and Ali Farhadi. YOLO9000: better, faster, stronger. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 6517–6525, 2017.
[41] Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun.Faster R-CNN: towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 91–99, 2015.
[42] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation.In Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015 - 18th International Conference Munich, Germany, October 5 - 9, 2015, Proceedings, Part III, pages 234–241, 2015.
[43] Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise view selection for unstructured multi-view stereo. In Proc. European Conference on Computer Vision (ECCV), 2016.
[44] Karen Simonyan and Andrew. Zisserman. V ery deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 2015.
[45] Richard Socher, Brody Huval, Bharath Putta Bath, Christopher D. Manning, and Andrew Y . Ng. Convolutionalrecursive deep learning for 3d object classification. In Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012., pages 665–673, 2012.
[46] Shuran Song, Fisher Y u, Andy Zeng, Angel X. Chang, Manolis Savva, and Thomas A. Funkhouser. Semantic scene completion from a single depth image. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[47] Frank Steinbrücker, Christian Kerl, and Daniel Cremers.Large-scale multi-resolution surface reconstruction from RGB-D sequences. In Proc. International Conference on Computer Vision (ICCV), pages 3264–3271, 2013.
[48] Christian Szegedy, Wei Liu, Y angqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent V anhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR).
[49] Keisuke Tateno, Federico Tombari, Iro Laina, and Nassir Navab. CNN-SLAM: real-time dense monocular SLAM with learned depth prediction. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 6565–6574, 2017.
[50] Weiyue Wang, Ronald Y u, Qiangui Huang, and Ulrich Neumann. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[51] Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Y u, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), pages 1912–1920, 2015.
[52] Bin Y ang, Wenjie Luo, and Raquel Urtasun. Pixor: Realtime 3d object detection from point clouds. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[53] Bo Y ang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, and Niki Trigoni. Learning object bounding boxes for 3d instance segmentation on point clouds. arXiv preprint arXiv:1906.01140, 2019.
[54] Li Yi, Wang Zhao, He Wang, Minhyuk Sung, and Leonidas Guibas. Gspn: Generative shape proposal network for 3d instance segmentation in point cloud. Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[55] Christopher Zach, Thomas Pock, and Horst Bischof. A globally optimal algorithm for robust tv-l1 range image integration. In Proc. International Conference on Computer Vision (ICCV), pages 1–8, 2007.
[56] Matthew D Zeiler, Dilip Krishnan, Graham W Taylor, and Robert Fergus. Deconvolutional networks. Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2010.