目标检测(四)——xml快速上手(可完整实现)
文章目录
- 什么是xml
- xml解析讲解
-
- 一、标签介绍
-
- filename标签
- size标签
- object标签
- 二、xml解析的API
- xml单个文件的解析
-
- 构建类别索引(category_id)
- 构建xml解析
- 代码测试
什么是xml
XML 被设计用来传输和存储数据。
XML于HTML的标签语言类似,都是使用标签来进行约束!【相对于html标签,xml标签可以自定义】
(对于上面的定义,我们简单了解一下就可以了,并不会对我们解析它有影响!)
下面展示一份简单的xml文件!(AI识虫的一份用于存储目标检测相关数据的xml文件)
<annotation>
<folder>刘霏霏folder>
<filename>1.jpegfilename>
<path>/home/fion/桌面/刘霏霏/1.jpegpath>
<source>
<database>Unknowndatabase>
source>
<size>
<width>1344width>
<height>1344height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>Lecontename>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>473xmin>
<ymin>578ymin>
<xmax>612xmax>
<ymax>727ymax>
bndbox>
object>
<object>
<name>Boernername>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>822xmin>
<ymin>505ymin>
<xmax>948xmax>
<ymax>639ymax>
bndbox>
object>
<object>
<name>linnaeusname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>607xmin>
<ymin>781ymin>
<xmax>690xmax>
<ymax>842ymax>
bndbox>
object>
<object>
<name>armandiname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>756xmin>
<ymin>786ymin>
<xmax>841xmax>
<ymax>856ymax>
bndbox>
object>
<object>
<name>coleopteraname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>624xmin>
<ymin>488ymin>
<xmax>711xmax>
<ymax>554ymax>
bndbox>
object>
annotation>
xml解析讲解
一、标签介绍
上边的示例xml文件中,其中最主要的是filename(文件–图片名称),size(图片大小和通道数), object(就是我们需要关注的目标检测的边界框位置等)。
【再次说明,xml中的标签可以自定义,只需要满足命名规范和标签闭合即可】
- 标签闭合:
自中,filename就是自定义的标签,前后对账,后者添加一个 /即可 - 命名规范:
名称可以包含字母、数字以及其他的字符
名称不能以数字或者标点符号开始
名称不能以字母 xml(或者 XML、Xml 等等)开始
名称不能包含空格
下面就对之前提到的三个部分做简要的说明!
filename标签
<filename>1.jpegfilename>
这个标签在AI识虫中对应着每一个xml文件对应的图片名称
size标签
<size>
<width>1344width>
<height>1344height>
<depth>3depth>
size>
可以看出,size中还包含其它的内部标签,此时我们需要解析内部的数据就需要继续继续往里边查找标签——比如对width标签就对应着图片的宽度。【depth:常常表示通道数】
object标签
<object>
<name>Lecontename>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>473xmin>
<ymin>578ymin>
<xmax>612xmax>
<ymax>727ymax>
bndbox>
object>
object通常就是我们目标检测中检测物体边界框所在的外层标签。
其中
更重要的是:
<bndbox>
<xmin>473xmin>
<ymin>578ymin>
<xmax>612xmax>
<ymax>727ymax>
bndbox>
在bndbox标签中,包含我们检测的边界框的左上顶点(xmin, ymin) ,右下顶点(xmax, ymax)!
以上,基本上就对一份xml文件内容和确定解析标签做了一个基本的阐述。
二、xml解析的API
python中解析xml是通过操做xml库实现的!
-
首先导入库:
import xml -
具体解析xml文件是使用
xml.etrre.ElementTree来构建xml解析树实现的 -
该API
xml.etrre.ElementTree下的parse可以快速解析xml文件
形式如下:
xml.etrre.ElementTree.parse(xml_path)实现对xml_path对应的xml文件进行解析,并返回一个xml解析树对象! -
此时获取的解析树还只是一个直接的数据,不能直接获取我们想要的东西,此时需要对解析树使用
find(标签)来对指定标签进行查讯,并返回该标签对象,然后,再跟上一个text获取该标签的属性(注意:text针对仅含有具体字符数据的标签,如1 1
eg:
# xml解析树
xml_tree = xml.etrre.ElementTree.parse(xml_path)
# find从解析对象中找到id标签对象,然后使用text属性,获取xml中该标签对应的数据
id_data = xml_tree.find('id').text # 此时返回的数据是str,如果是数值,可以使用int/float进行转换
总结起来,xml解析最主要的操作就是:
- 使用
xml.etrre.ElementTree.parse(xml_path)创建一个初始的xml树对象; - 然后对返回的树对象使用
find进行标签查找; - 找到所需要的子标签时,再使用
text属性进行读取即可!
xml单个文件的解析
在解析文件前,我们来确定一下分析xml中所要关注的标签。
在AI识虫的xml中,我们需要关注的标签:
- filename : 解析出当前xml对应的图片文件名
- size -> width , height, depth : 解析出图片的大小和通道数
- objeck -> bndbox : 解析出objeck下的bbox数据
- difficult : 解析当前bbox是否存在识别困难
接下来就从以上四个方面进行解析——
构建类别索引(category_id)
模型的输出与损失计算都是数值的,而xml中有时候会出现category(类别)名称,需要进行转换!
因此,我们就AI识虫数据集中的xml所存在的类别进行整理:
# 其对应的cotegory有7种
INSECT_NAMES = ['Boerner', 'Leconte', 'Linnaeus', 'acuminatus', 'armandi', 'coleoptera', 'linnaeus']
我们就对以上的类别设置顺序索引,从Boerner-0, Leconte-1, … , linnaeus-6进行映射!
这里利用字典来存取这样的映射,方便我们后边解析出xml中的类别时,可以使用key直接获取类别的id!
构建字典的函数如下:
# 构造类别对应的索引字典
def get_insect_name():
"""获取类别索引字典
return a dict,
{'Boerner': 0,
'Leconte': 1,
'Linnaeus': 2,
'acuminatus': 3,
'armandi': 4,
'coleoptera': 5,
'linnaeus': 6
}
"""
insect_category2id = {} # 从类别到id的一个映射
for i, item in enumerate(INSECT_NAMES): # 利用enumerate自带的索引序号进行映射
insect_category2id[item] = i
return insect_category2id
构建xml解析
通过上边的操作,我们就得到了类别映射,后边的的类别名称就可以很方便的解析成id序列号了!
代码具体如下:(所有的重要注释都已经在代码中覆盖了!)
# 传入类别索引字典和xml数据地址进行xml解析
# 返回xml中解析到的所有目标数据
def get_annotation(category2id, data_path):
'''
category2id: 类别索引字典
data_path: 数据地址(单个xml的数据的相对地址——1.xml)
return records
(这是一个list,包含其中返回的字典数据)
'''
# data_path: 1.xml => [:-4] = '1' , [-4:] = '.xml'
fid = data_path[:-4] # id:既是xml的,通常也是img的
tree = ET.parse(data_path)
objs = tree.findall('object') # 返回所有的object对象(标签)
img_w = tree.find('size').find('width').text # 通过text属性调用xml指定标签的数据
img_h = tree.find('size').find('height').text
# print('Image Width:', img_w, 'px , Image Height:', img_h, 'px')
# 预置我们需要从xml中读取的数据格式——这里的bbox采用xywh的数据格式存储
# 根据objs的个数,分配此时解析xml需要多少个bbox
gt_bbox = np.zeros((len(objs), 4), dtype=np.float32) # 4:表示bbox的数据: xywh
gt_class = np.zeros((len(objs), 1), dtype=np.int32) # 1:对应类别索引
is_difficult = np.zeros((len(objs), 1), dtype=np.int32) # 1:对应是否识别困难
# 预置后数据格式之后,开始遍历objs,依次读取其中的数据,存入到预置的数据格式中
for i, obj in enumerate(objs): # 利用enumerate返回自带索引,来方便多个obj的索引和遍历
# 类别读取
category_name = obj.find('name').text # 获取类别名
category_id = category2id[category_name] # 获取对应的类别索引
gt_class[i] = category_id # 添加识别类别索引
# 识别是否困难
_difficult = int(obj.find('difficult').text) # 获取识别难度
is_difficult[i] = _difficult # 读取目标识别是否困难
# bbox读取
x1 = float(obj.find('bndbox').find('xmin').text) # 将读取的左上点的x数据转换为float数据
y1 = float(obj.find('bndbox').find('ymin').text)
x2 = float(obj.find('bndbox').find('xmax').text) # 右下点
y2 = float(obj.find('bndbox').find('ymax').text)
# 将读取的bbox数据转换为:xywh的格式存入gt_bbox中
bbox_center_x = (x2 + x1) / 2.0
bbox_center_y = (y2 + y1) / 2.0
bbox_w = (x2 - x1) + 1.0
bbox_h = (y2 - y1) + 1.0
# 写入gt_bbox
gt_bbox[i] = [bbox_center_x, bbox_center_y, bbox_w, bbox_h] # 这里等价于将gt_bbox[i,:] = [....]
# 将当前xml中的所有obj遍历完后,对数据进行一个汇总
# 具体实践时的数据解析和汇总可以做适当的调整
xml_rcd = {
'image_name': fid+'.png', # 图片名称
'image_id': fid, # 图片id
'difficult': is_difficult, # 数据识别困难情况
'categoty_id': gt_class, # 识别对象的类别情况
'gt_bbox': gt_bbox # 识别对象的bbox情况
}
# 返回解析完归总后的xml内容
return xml_rcd
代码测试
# cotegory有7种
INSECT_NAMES = ['Boerner', 'Leconte', 'Linnaeus', 'acuminatus', 'armandi', 'coleoptera', 'linnaeus']
# 生成类别索引字典
category2id = get_insect_name()
# 返回解析后的xml内容
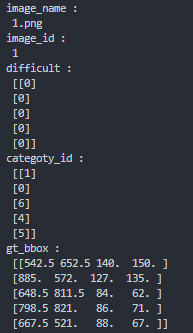
xml_rcd = get_annotation(category2id=category2id, data_path='1.xml')
# 打印解析出来的内容
for key, data in xml_rcd.items(): # 打印返回的内容
print(key, ':\n', data) # 当前数据的内容
打印结果:
到这里,xml的基本解析就介绍完了,如果大家感兴趣,可以在此基础上尝试文件列表中多个xml文件的解析。
目标检测相关教程如下:(更新中)
目标检测(一)——边界框总结与代码实现(可完整实现)
目标检测(二)——锚框总结与代码实现(可完整实现)
目标检测(三)——IoU总结与代码实现(可完整实现)