【菜菜的sklearn课堂笔记】逻辑回归与评分卡-步长的进一步理解和max_iter
视频作者:菜菜TsaiTsai
链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
既然参数迭代是靠 梯 度 向 量 的 大 小 d × 步 长 α 梯度向量的大小d \times步长\alpha 梯度向量的大小d×步长α来实现的,而 J ( θ ) J(\theta) J(θ)的降低又是靠调节 θ \theta θ来实现的,所以步长可以调节损失函数下降的速率。在损失函数降低的方向上,步长越长, θ \theta θ的变动就越大。相对的,步长如果很短, θ \theta θ每次变动就很小
这里的意思就是 θ j m + 1 = θ j m − α ⋅ d j \theta_{j}^{m+1}=\theta_{j}^{m}- \alpha \cdot d_{j} θjm+1=θjm−α⋅dj,如果我们确定了 θ j m \theta_{j}^{m} θjm,那么 d j d_{j} dj也就相应的确定了,因此 α \alpha α就影响了迭代后的 θ j m + 1 \theta_{j}^{m+1} θjm+1
一般而言 θ \theta θ变动越大 J ( θ ) J(\theta) J(θ)变化越大,也就下降的越快
二者结合就可以得到步长可以调节损失函数 J ( θ ) J(\theta) J(θ)下降的速率的结论
具体地说,如果步长太大,损失函数下降得就非常快,需要的迭代次数就很少,但梯度下降过程可能跳过损失函数的最低点,无法获取最优值。而步长太小,虽然函数会逐渐逼近我们需要的最低点,但迭代的速度却很缓慢,迭代次数就需要很多。
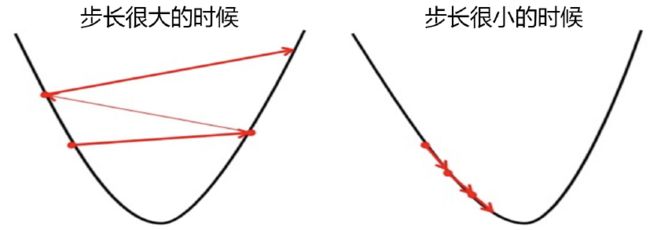
在看小球运动时注意到,小球在进入深蓝色区域后,并没有直接找到某个点,而是在深蓝色区域中来回震荡了数次才停下,这种”震荡“其实就是因为我们设置的步长太大的缘故。但是在我们开始梯度下降之前,我们并不知道什么样的步长才合适,但梯度下降一定要在某个时候停止才可以,否则模型可能会无限地迭代下去。
在sklearn当中,我们设置参数max_iter最大迭代次数来代替步长,帮助我们控制模型的迭代速度并适时地让模型停下。max_iter越大,代表步长越小,模型迭代时间越长,反之,则代表步长设置很大,模型迭代时间很短。
迭代结束,获取到 J ( θ ) J(\theta) J(θ)的最小值后,我们就可以找出这个最小值对应的参数向量 θ \theta θ,逻辑回归的预测函数也就可以根据这个参数向量 θ \theta θ来建立了
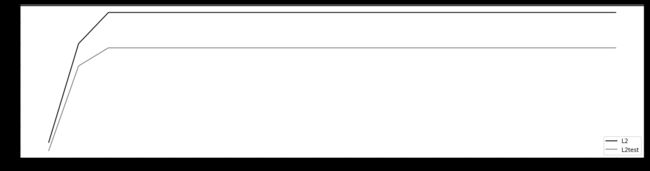
看看乳腺癌数据集下,max_iter的学习曲线:
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
X = data.data
y = data.target
l2 = []
l2test = []
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
for i in np.arange(1,201,10):
lrl2 = LR(solver='liblinear',C=0.8,max_iter=i)
lrl2 = lrl2.fit(Xtrain,Ytrain)
l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain))
l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest))
graph = [l2,l2test]
color = ['k','gray']
label = ['L2','L2test']
plt.figure(figsize=(20,5))
for i in range(len(graph)):
plt.plot(np.arange(1,201,10),graph[i],color[i],label=label[i])
plt.legend(loc=4)
plt.xticks(np.arange(1,201,10))
plt.show()
属性n_iter_来调用本次求解中真正实现迭代的次数
lr = LR(solver='liblinear',C=0.8,max_iter=300).fit(Xtrain,Ytrain)
lr.n_iter_ # 我们指定max_iter,但是实际上迭代24次就够了
---
array([24], dtype=int32)
当max_iter中限制的步数已经走完了,逻辑回归却还没有找到损失函数的最小值,参数 θ \theta θ的值还没有收敛,sklearn就会弹出这样的红色警告
当参数solver=“liblinear”:
![]()
当参数solver=“sag”:
![]()
虽然写法看起来略有不同,但其实都是一个含义,这是在提醒我们:参数没有收敛,请增大max_iter中输入的数字。
但我们不一定要听sklearn的。max_iter很大,意味着步长小,模型运行得会更加缓慢。虽然我们在梯度下降中追求的是损失函数的最小值,但这也可能意味着我们的模型会过拟合(在训练集上表现得太好,在测试集上却不一定),因此,如果在max_iter报红条的情况下,模型的训练和预测效果都已经不错了,那我们就不需要再增大max_iter中的数目了,毕竟一切都以模型的预测效果为基准,只要最终的预测效果好,运行又快,那就一切都好,无所谓是否报红色警告了。