第七周-咖啡豆识别
>- ** 本文为[365天深度学习训练营](https://mp.weixin.qq.com/s/xLjALoOD8HPZcH563En8bQ) 中的学习记录博客**
>- ** 参考文章:365天深度学习训练营-第7周:咖啡豆识别(训练营内部成员可读)**
>- ** 原作者:[K同学啊|接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**1、设置环境
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")2、导入数据
from tensorflow import keras
from tensorflow.keras import layers,models
import numpy as np
import matplotlib.pyplot as plt
import os,PIL,pathlib
data_dir = "D:/DeepLearning/49-data"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.png')))
print("图片总数为:",image_count)图片总数为: 1200
3、加载数据
batch_size = 16
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1200 files belonging to 4 classes. Using 960 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1200 files belonging to 4 classes. Using 240 files for validation.
class_names = train_ds.class_names
print(class_names)['Dark', 'Green', 'Light', 'Medium']
4、可视化数据
plt.figure(figsize=(10, 4)) # 图形的宽为10高为5
for images, labels in train_ds.take(1):
for i in range(10):
ax = plt.subplot(2, 5, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break(16, 224, 224, 3) (16,)
5、配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]
# 查看归一化后的数据
print(np.min(first_image), np.max(first_image))0.0 1.0
6、构建模型(官方与自建)
model = keras.applications.VGG16(include_top=False,weights='imagenet')
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
prediction_layer1 = tf.keras.layers.Dense(1024,activation='relu')
prediction_layer2 = tf.keras.layers.Dense(512,activation='relu')
prediction_layer3 = tf.keras.layers.Dense(len(class_names),activation='softmax')
model = tf.keras.Sequential([
model,
global_average_layer,
prediction_layer1,
prediction_layer2,
prediction_layer3
])
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, None, None, 512) 14714688
global_average_pooling2d (G (None, 512) 0
lobalAveragePooling2D)
dense (Dense) (None, 1024) 525312
dense_1 (Dense) (None, 512) 524800
dense_2 (Dense) (None, 4) 2052
=================================================================
Total params: 15,766,852
Trainable params: 15,766,852
Non-trainable params: 0
_________________________________________________________________
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(len(class_names), (img_width, img_height, 3))
model.summary()Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 4) 16388
=================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
_________________________________________________________________
7、编译模型,设置早停
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
epochs = 100
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=20,
verbose=1)8、训练模型
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])Epoch 1/100
c:\users\32566\appdata\local\programs\python\python37\lib\site-packages\tensorflow\python\util\dispatch.py:1082: UserWarning: "`sparse_categorical_crossentropy` received `from_logits=True`, but the `output` argument was produced by a sigmoid or softmax activation and thus does not represent logits. Was this intended?" return dispatch_target(*args, **kwargs)
60/60 [==============================] - ETA: 0s - loss: 1.3384 - accuracy: 0.2906 Epoch 1: val_accuracy improved from -inf to 0.40833, saving model to best_model.h5 60/60 [==============================] - 17s 195ms/step - loss: 1.3384 - accuracy: 0.2906 - val_loss: 1.3027 - val_accuracy: 0.4083 Epoch 2/100 60/60 [==============================] - ETA: 0s - loss: 0.8425 - accuracy: 0.5292 Epoch 2: val_accuracy improved from 0.40833 to 0.57083, saving model to best_model.h5 60/60 [==============================] - 12s 197ms/step - loss: 0.8425 - accuracy: 0.5292 - val_loss: 0.6924 - val_accuracy: 0.5708 Epoch 3/100 60/60 [==============================] - ETA: 0s - loss: 0.6604 - accuracy: 0.6687 Epoch 3: val_accuracy improved from 0.57083 to 0.61667, saving model to best_model.h5 60/60 [==============================] - 12s 197ms/step - loss: 0.6604 - accuracy: 0.6687 - val_loss: 0.5194 - val_accuracy: 0.6167 Epoch 4/100 60/60 [==============================] - ETA: 0s - loss: 0.4934 - accuracy: 0.7531 Epoch 4: val_accuracy improved from 0.61667 to 0.74583, saving model to best_model.h5 60/60 [==============================] - 12s 196ms/step - loss: 0.4934 - accuracy: 0.7531 - val_loss: 0.6450 - val_accuracy: 0.7458 Epoch 5/100 60/60 [==============================] - ETA: 0s - loss: 0.3286 - accuracy: 0.8729 Epoch 5: val_accuracy improved from 0.74583 to 0.93750, saving model to best_model.h5 60/60 [==============================] - 12s 197ms/step - loss: 0.3286 - accuracy: 0.8729 - val_loss: 0.1644 - val_accuracy: 0.9375 Epoch 6/100 60/60 [==============================] - ETA: 0s - loss: 0.1709 - accuracy: 0.9323 Epoch 6: val_accuracy did not improve from 0.93750 60/60 [==============================] - 11s 185ms/step - loss: 0.1709 - accuracy: 0.9323 - val_loss: 0.1847 - val_accuracy: 0.9167 Epoch 7/100 60/60 [==============================] - ETA: 0s - loss: 0.1160 - accuracy: 0.9594 Epoch 7: val_accuracy improved from 0.93750 to 0.96250, saving model to best_model.h5 60/60 [==============================] - 12s 197ms/step - loss: 0.1160 - accuracy: 0.9594 - val_loss: 0.1156 - val_accuracy: 0.9625 Epoch 8/100 60/60 [==============================] - ETA: 0s - loss: 0.1091 - accuracy: 0.9542 Epoch 8: val_accuracy did not improve from 0.96250 60/60 [==============================] - 11s 186ms/step - loss: 0.1091 - accuracy: 0.9542 - val_loss: 0.1414 - val_accuracy: 0.9458 Epoch 9/100 60/60 [==============================] - ETA: 0s - loss: 0.0889 - accuracy: 0.9719 Epoch 9: val_accuracy did not improve from 0.96250 60/60 [==============================] - 11s 185ms/step - loss: 0.0889 - accuracy: 0.9719 - val_loss: 0.0817 - val_accuracy: 0.9625 Epoch 10/100 60/60 [==============================] - ETA: 0s - loss: 0.0548 - accuracy: 0.9771 Epoch 10: val_accuracy improved from 0.96250 to 0.96667, saving model to best_model.h5 60/60 [==============================] - 12s 197ms/step - loss: 0.0548 - accuracy: 0.9771 - val_loss: 0.1049 - val_accuracy: 0.9667 Epoch 11/100 60/60 [==============================] - ETA: 0s - loss: 0.0619 - accuracy: 0.9812 Epoch 11: val_accuracy did not improve from 0.96667 60/60 [==============================] - 11s 186ms/step - loss: 0.0619 - accuracy: 0.9812 - val_loss: 0.1278 - val_accuracy: 0.9625 Epoch 12/100 60/60 [==============================] - ETA: 0s - loss: 0.0617 - accuracy: 0.9812 Epoch 12: val_accuracy did not improve from 0.96667 60/60 [==============================] - 11s 186ms/step - loss: 0.0617 - accuracy: 0.9812 - val_loss: 0.1468 - val_accuracy: 0.9542 Epoch 13/100 60/60 [==============================] - ETA: 0s - loss: 0.1255 - accuracy: 0.9563 Epoch 13: val_accuracy did not improve from 0.96667 60/60 [==============================] - 11s 186ms/step - loss: 0.1255 - accuracy: 0.9563 - val_loss: 0.0679 - val_accuracy: 0.9625 Epoch 14/100 60/60 [==============================] - ETA: 0s - loss: 0.0187 - accuracy: 0.9937 Epoch 14: val_accuracy improved from 0.96667 to 0.97500, saving model to best_model.h5 60/60 [==============================] - 12s 198ms/step - loss: 0.0187 - accuracy: 0.9937 - val_loss: 0.0583 - val_accuracy: 0.9750 Epoch 15/100 60/60 [==============================] - ETA: 0s - loss: 0.1493 - accuracy: 0.9563 Epoch 15: val_accuracy did not improve from 0.97500 60/60 [==============================] - 11s 185ms/step - loss: 0.1493 - accuracy: 0.9563 - val_loss: 0.1999 - val_accuracy: 0.9333 Epoch 16/100 60/60 [==============================] - ETA: 0s - loss: 0.2473 - accuracy: 0.9333 Epoch 16: val_accuracy did not improve from 0.97500 60/60 [==============================] - 11s 185ms/step - loss: 0.2473 - accuracy: 0.9333 - val_loss: 0.1881 - val_accuracy: 0.9583 Epoch 17/100 60/60 [==============================] - ETA: 0s - loss: 0.1977 - accuracy: 0.9448 Epoch 17: val_accuracy did not improve from 0.97500 60/60 [==============================] - 11s 185ms/step - loss: 0.1977 - accuracy: 0.9448 - val_loss: 0.0716 - val_accuracy: 0.9708 Epoch 18/100 60/60 [==============================] - ETA: 0s - loss: 0.0887 - accuracy: 0.9750 Epoch 18: val_accuracy did not improve from 0.97500 60/60 [==============================] - 11s 185ms/step - loss: 0.0887 - accuracy: 0.9750 - val_loss: 0.0854 - val_accuracy: 0.9625 Epoch 19/100 60/60 [==============================] - ETA: 0s - loss: 0.0400 - accuracy: 0.9854 Epoch 19: val_accuracy improved from 0.97500 to 0.98333, saving model to best_model.h5 60/60 [==============================] - 12s 196ms/step - loss: 0.0400 - accuracy: 0.9854 - val_loss: 0.0351 - val_accuracy: 0.9833 Epoch 20/100 60/60 [==============================] - ETA: 0s - loss: 0.0103 - accuracy: 0.9958 Epoch 20: val_accuracy improved from 0.98333 to 0.99167, saving model to best_model.h5 60/60 [==============================] - 12s 196ms/step - loss: 0.0103 - accuracy: 0.9958 - val_loss: 0.0499 - val_accuracy: 0.9917 Epoch 21/100 60/60 [==============================] - ETA: 0s - loss: 0.1027 - accuracy: 0.9708 Epoch 21: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 0.1027 - accuracy: 0.9708 - val_loss: 0.0877 - val_accuracy: 0.9833 Epoch 22/100 60/60 [==============================] - ETA: 0s - loss: 0.0627 - accuracy: 0.9781 Epoch 22: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 0.0627 - accuracy: 0.9781 - val_loss: 0.0441 - val_accuracy: 0.9833 Epoch 23/100 60/60 [==============================] - ETA: 0s - loss: 0.0056 - accuracy: 0.9990 Epoch 23: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 0.0056 - accuracy: 0.9990 - val_loss: 0.0513 - val_accuracy: 0.9833 Epoch 24/100 60/60 [==============================] - ETA: 0s - loss: 9.5442e-04 - accuracy: 1.0000 Epoch 24: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 9.5442e-04 - accuracy: 1.0000 - val_loss: 0.0595 - val_accuracy: 0.9875 Epoch 25/100 60/60 [==============================] - ETA: 0s - loss: 0.0450 - accuracy: 0.9906 Epoch 25: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 0.0450 - accuracy: 0.9906 - val_loss: 0.0472 - val_accuracy: 0.9833 Epoch 26/100 60/60 [==============================] - ETA: 0s - loss: 0.0215 - accuracy: 0.9927 Epoch 26: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 0.0215 - accuracy: 0.9927 - val_loss: 0.0333 - val_accuracy: 0.9833 Epoch 27/100 60/60 [==============================] - ETA: 0s - loss: 9.6706e-04 - accuracy: 1.0000 Epoch 27: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 184ms/step - loss: 9.6706e-04 - accuracy: 1.0000 - val_loss: 0.0495 - val_accuracy: 0.9917 Epoch 28/100 60/60 [==============================] - ETA: 0s - loss: 2.7682e-04 - accuracy: 1.0000 Epoch 28: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 2.7682e-04 - accuracy: 1.0000 - val_loss: 0.0617 - val_accuracy: 0.9875 Epoch 29/100
60/60 [==============================] - ETA: 0s - loss: 1.4114e-04 - accuracy: 1.0000 Epoch 29: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 1.4114e-04 - accuracy: 1.0000 - val_loss: 0.0534 - val_accuracy: 0.9875 Epoch 30/100 60/60 [==============================] - ETA: 0s - loss: 5.7586e-05 - accuracy: 1.0000 Epoch 30: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 5.7586e-05 - accuracy: 1.0000 - val_loss: 0.0641 - val_accuracy: 0.9875 Epoch 31/100 60/60 [==============================] - ETA: 0s - loss: 3.3608e-05 - accuracy: 1.0000 Epoch 31: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 184ms/step - loss: 3.3608e-05 - accuracy: 1.0000 - val_loss: 0.0613 - val_accuracy: 0.9917 Epoch 32/100 60/60 [==============================] - ETA: 0s - loss: 2.4320e-05 - accuracy: 1.0000 Epoch 32: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 2.4320e-05 - accuracy: 1.0000 - val_loss: 0.0654 - val_accuracy: 0.9875 Epoch 33/100 60/60 [==============================] - ETA: 0s - loss: 1.7902e-05 - accuracy: 1.0000 Epoch 33: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 1.7902e-05 - accuracy: 1.0000 - val_loss: 0.0649 - val_accuracy: 0.9917 Epoch 34/100 60/60 [==============================] - ETA: 0s - loss: 1.4983e-05 - accuracy: 1.0000 Epoch 34: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 1.4983e-05 - accuracy: 1.0000 - val_loss: 0.0663 - val_accuracy: 0.9917 Epoch 35/100 60/60 [==============================] - ETA: 0s - loss: 1.2395e-05 - accuracy: 1.0000 Epoch 35: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 1.2395e-05 - accuracy: 1.0000 - val_loss: 0.0670 - val_accuracy: 0.9917 Epoch 36/100 60/60 [==============================] - ETA: 0s - loss: 1.0415e-05 - accuracy: 1.0000 Epoch 36: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 184ms/step - loss: 1.0415e-05 - accuracy: 1.0000 - val_loss: 0.0674 - val_accuracy: 0.9917 Epoch 37/100 60/60 [==============================] - ETA: 0s - loss: 8.8860e-06 - accuracy: 1.0000 Epoch 37: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 184ms/step - loss: 8.8860e-06 - accuracy: 1.0000 - val_loss: 0.0684 - val_accuracy: 0.9917 Epoch 38/100 60/60 [==============================] - ETA: 0s - loss: 7.9480e-06 - accuracy: 1.0000 Epoch 38: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 184ms/step - loss: 7.9480e-06 - accuracy: 1.0000 - val_loss: 0.0696 - val_accuracy: 0.9875 Epoch 39/100 60/60 [==============================] - ETA: 0s - loss: 6.8942e-06 - accuracy: 1.0000 Epoch 39: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 185ms/step - loss: 6.8942e-06 - accuracy: 1.0000 - val_loss: 0.0697 - val_accuracy: 0.9875 Epoch 40/100 60/60 [==============================] - ETA: 0s - loss: 5.9561e-06 - accuracy: 1.0000 Epoch 40: val_accuracy did not improve from 0.99167 60/60 [==============================] - 11s 184ms/step - loss: 5.9561e-06 - accuracy: 1.0000 - val_loss: 0.0710 - val_accuracy: 0.9875 Epoch 40: early stopping
9、可视化结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()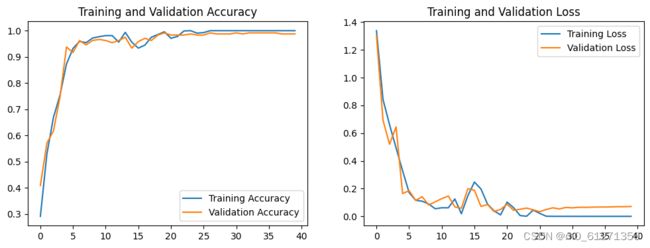
10、预测图片
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
from PIL import Image
import numpy as np
img = Image.open("D:/DeepLearning/49-data/Light/light (30).png") #这里选择你需要预测的图片
img=np.array(img)
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
1/1 [==============================] - 1s 666ms/step 预测结果为: Light