PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model-2022.4.6
最近看到了这个PP-LiteSeg,虽然没有用过paddle但是一直想尝试下,看到这个网络结构看起来不错的亚子,先浅看下叭。
论文地址
代码地址
pp-liteseg的代码段
pp-liteseg
- 摘要
- 1.introduction
- 2.related work
-
- 2.1 semantic segmentation
- 2.2 real-time semantic segmentation
- 2.3 feature fusion module
- 3.proposed method
-
- 3.1 flexible and lightweight decoder
- 3.2 unified attention fusion module
- 3.3 Simple Pyramid Pooling Module
- 3.4. Network Architecture
- 4. Experiments
-
- 4.1. Datasets and Implementation Details
- 4.2. Experiments on Cityscapes
-
- 4.2.1 Comparisons with State-of-the-arts
- 4.2.2 Ablation study
- 4.3. Experiments on CamVid
- 5. Conclusions
摘要
实际应用对语义分割方法有很高的要求。尽管语义分割在深度学习中取得了显著的进步,但实时性方法的性能并不令人满意。在这项工作中,我们提出了一个新的轻量级模型PP-LiteSeg用于实时语义分割任务。具体地说,我们提出了一种灵活的轻量级解码器(FLD),以减少以前解码器的计算开销。为了增强特征表示,我们提出了一种统一注意融合模块(UAFM),该模块利用空间注意和通道注意产生一个权值,然后将输入特征与权值融合。此外,提出了一种简单金字塔池化模块(SPPM),以较低的计算成本聚合全局上下文。广泛的评估表明,与其他方法相比,PP-LiteSeg实现了精度和速度之间的优越权衡。在Cityscapes测试集上,PP-LiteSeg在NVIDIA GTX 1080Ti上达到72.0% mIoU/273.6 FPS和77.5% mIoU/102.6 FPS。
######ps这一段很经典的论文格式,可以仿写#####
Real-world applications have high demands for semantic segmentation methods. Although semantic segmentation has made remarkable leap-forwards with deep learning, the performance of real-time methods is not satisfactory. In this work, we propose PP-LiteSeg, a novel lightweight model for the real-time semantic segmentation task. Specifically, we present a Flexible and Lightweight Decoder (FLD) to reduce computation over-head of previous decoder. To strengthen feature representations, we propose a Unified Attention Fusion Module (UAFM), which takes advantage of spatial and channel attention to produce a weight and then fuses the input features with the weight. Moreover, a Simple Pyramid Pooling Module (SPPM) is proposed to aggregate global context with low computation cost. Extensive evaluations demonstrate that PP-LiteSeg achieves a superior tradeoff between accuracy and speed compared to other methods. On the Cityscapes test set, PP-LiteSeg achieves 72.0% mIoU/273.6 FPS and 77.5% mIoU/102.6 FPS on NVIDIA GTX 1080Ti. Source code and models are available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
小结:
首先指明现在的语义分割在实时性上仍有欠缺,为此提出了该模型,该模型主要包括三个组件:1.FLD:用于减小解码器计算开销;2.UAFM:增强特征表示;3.SPPM:低成本聚合全局上下文。(很清晰这个摘要)
1.introduction
ps:此处有基础的可以跳过不看哈,只看我标黑的也可
语义分割的目的是精确地预测图像中每个像素的标签。在现实生活中得到了广泛的应用,如医学影像[30]、自动驾驶[10,24]、视频会议[5]、半自动注释[9]等。语义分割作为计算机视觉的一项基础任务,受到了研究者的广泛关注[13,16]。
随着深度学习的显著进展,许多基于卷积神经网络的语义分割方法被提出[3,15,18,26,29]。FCN[18]是第一个以端到端、像素到像素的方式训练的完全卷积网络。给出了在语义段中被广泛采用的原始的编码器-解码器结构。为了达到更高的准确性,PSPNet[29]利用金字塔池化模块聚合全局上下文,SFNet[15]提出流对齐模块增强特征表示。
然而,这些模型由于计算成本高,不适合实时应用。为了加快推理速度,Espnetv2[21]利用轻量级卷积从放大的接收野中提取特征。BiSeNetV2[26]提出双边分割网络,分别提取细节特征和语义特征。为了提高计算效率,STDCSeg[8]设计了一个新的骨干STDC。然而,这些模型并没有在精度和速度之间取得令人满意的平衡。
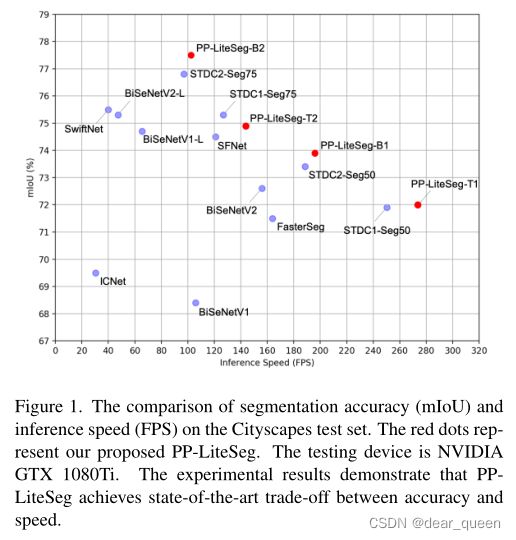
在这项工作中,我们提出了一个实时的手工网络命名为PP-LiteSeg。如图2所示,PPLiteSeg采用了编码-解码器架构,由三个新的模块组成:Flexible and Lightweight Decoder (FLD)、Unified Attention Fusion Module (UAFM)和Simple Pyramid Pooling Module (SPPM)。下面介绍这些模块的动机和细节。
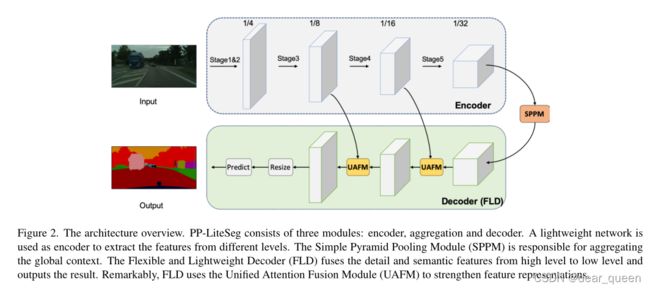
浅浅分析下这个图:首先encoder模块是正常的特征提取部分,不过融合了不同层的分支与decoder连接。在encoder结束后连接了一个sppm模块,这个是个轻量的特征金字塔,随后进入decoder结构(这里作者将这个新结构称为FLD),里面包含了UAFM结构,起到注意力机制的作用。
###########重点在这里:#####################
FLD: 在语义分割模型中,编码器提取层次特征(hierarchical features),解码器融合和反采样特征(upsamples features)。对于编码器从low level到high level 的特征,channels增加,空间尺寸减小,是一种有效的设计。对于解码器中从高电平到低电平的特征,空间大小增加,而在最近的模型中信道数量是相同的[8,15]。因此,我们提出了一个灵活的轻量级解码器(FLD),逐渐减少通道和增加空间大小的特征。此外,所提出的解码器的体积可以根据编码器容易地调整。灵活的设计平衡了编码器和解码器的计算复杂度,提高了整体模型的效率。
UAFM:加强特征表示是提高分割精度的关键途径[11,15,25]。它通常是通过在解码器中融合低级和高级特征来实现的。然而,现有方法中的融合模块计算成本较高。在这项工作中,我们提出了一种统一注意融合模块(UAFM),以有效地增强特征表示。如图4所示,UAFM首先利用注意模块产生权重α,然后将输入特征与α融合。在UAFM中,有两种注意模块,即空间注意模块和通道注意模块,它们利用输入特征的空间间关系和通道间关系。
SPPM: 上下文聚合是提高分割精度的另一个关键,但以往的聚合模块对实时网络来说是非常耗时的。基于PPM[29]框架,我们设计了一个简单金字塔池化模块(SPPM),它减少了中间通道和输出通道,消除了快捷方式,用添加操作代替了连接操作。实验结果表明,SPPM算法在计算成本较低的情况下提高了分割精度。
我们通过在cityscape和CamVid数据集上的广泛实验来评估所提出的PP-LiteSeg。如图1所示,PP-LiteSeg在分割精度和推理速度之间取得了卓越的折衷。具体来说,PP-LiteSeg在cityscape测试集上达到72.0% mIoU/273.6 FPS和77.5% mIoU/102.6 FPS。
Our main contributions are summarized as follows:
•我们提出了一种灵活轻量级的译码器(FLD),它减轻了译码器的冗余,平衡了编码器和译码器的计算成本。
•我们提出了一种统一注意融合模块(UAFM),利用通道和空间注意来加强特征表示。
•我们提出了一个简单的金字塔池化模块(SPPM)来聚合全球上下文。SPPM在较少的额外推理时间下提高了分割精度。
•基于上述模块,我们提出了PP-LiteSeg,一个实时语义分割模型。大量的实验证明了我们的SOTA在准确性和速度方面的性能
2.related work
2.1 semantic segmentation
深度学习帮助语义分割取得了显著的飞跃。FCN[18]是第一个用于语义分割的全卷积网络。它以端到端和像素到像素的方式进行训练。此外,FCN还可以对任意大小的图像进行分割。随着FCN的设计,后来又提出了各种方法。网段[1]将编码器中的最大池化操作索引应用于解码器的上采样操作。因此,解码器中的信息被重用,解码器产生精细的特征。PSPNet[29]提出了金字塔池化模块来聚合局部和全局信息,有效地提高了分割精度。此外,近年来的语义分割方法[11,17]利用变压器体系结构来获得更好的准确性。
2.2 real-time semantic segmentation
为了满足语义分割的实时性要求,人们提出了许多方法,如轻量级模块设计[8,21]、双分支架构[26,27]、早期降采样策略[23]、多尺度图像级联网络[28]等。ENet[23]使用早期降采样策略来减少处理大图像和特征映射的计算成本。为了提高效率,ICNet[28]设计了一个多分辨率图像级联网络。Bisenet[26]基于双边分割网络,分别提取细节特征和语义特征。双边网络轻量级,推理速度快。STDCSeg[8]提出了减小信道的接收场放大STDC模块,并设计了一个高效的骨干,以较低的计算成本增强特征表示。为了消除双支路网络中的冗余,STDCSeg以详细的地面真实度引导特征,进一步提高了效率。Espnetv2[21]使用组点向和深度向扩张的可分离卷积,以一种计算友好的方式从扩大的接受域学习特征。
2.3 feature fusion module
特征融合模块是语义分割中常用的增强特征表示的模块。除了基于元素的求和和串联方法外,研究人员还提出了以下几种方法。在BiSeNet[26]中,BGA模块采用基于元素的mul方法来融合来自空间分支和上下文分支的特征。为了使用高级上下文增强特性,DFANet[14]以阶段级和子网级的方式融合特性。为了解决不对中问题,SFNet[15]和AlignSeg[12]首先通过一个CNN模块学习转换偏移量,然后将转换偏移量应用到网格样本操作中生成细化特征。其中,SFNet设计了流对准模块。AlignSeg设计对齐的特性聚合模块和对齐的上下文建模模块。FaPN[11]通过将变换偏移量应用于可变形卷积来解决特征不对齐问题。
3.proposed method
在本节中,我们首先介绍了灵活轻量级解码器(FLD)、统一注意力融合模块(UAFM)和简单金字塔池化模块(SPPM)。然后,我们提出了PP-LiteSeg的实时语义分割体系结构。
3.1 flexible and lightweight decoder
编码器-译码器结构已被证明是有效的语义分割。通常,编码器利用一系列层分组成几个阶段,以提取分层特征。从低层到高层特征,通道数逐渐增加,特征空间大小逐渐减小。该设计平衡了各个阶段的计算成本,保证了编码器的效率。解码器也有几个阶段,负责融合和上采样特征。尽管特征的空间大小从高级别到低级别不断增加,但在最近的轻量级模型中,解码器在所有级别中保持特征通道相同。因此**,浅层阶段的计算成本远远大于深层阶段,导致了浅层阶段的计算冗余**。为了提高解码器的效率,我们提出了一种灵活轻量级的解码器(FLD)。如图3所示,FLD将特征的通道由高级别逐渐减少到低级别。FLD可以很容易地调整计算成本,以实现编码器和解码器之间的更好平衡。虽然FLD中特征通道的减少,但我们的实验表明,PP-LiteSeg具有与其他方法相媲美的精度。
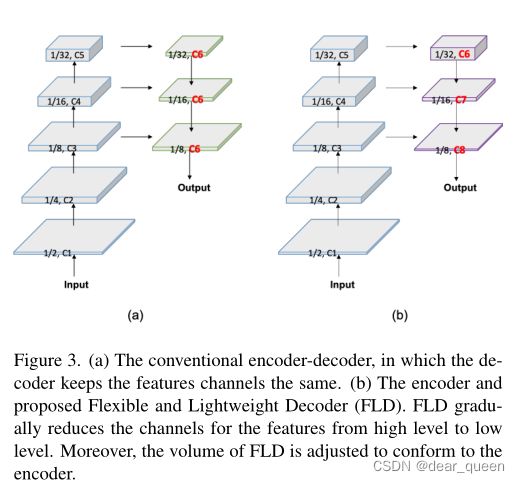
第一眼看到这个图,我都没发现不同,然后看到红色的字哪里不同。
3.2 unified attention fusion module
如前所述,融合多层次特征是实现高分割精度的关键。除了基于元素的求和和拼接方法外,研究者还提出了SFNet[15]、FaPN[11]、AttaNet[25]等方法。在这项工作中,我们提出了一个统一注意融合模块(UAFM),应用通道和空间注意来丰富融合的特征表示。
UAFM框架。如图4 (a)所示,UAFM利用注意模块产生权重α,并通过Mul和Add操作将输入特征与α融合。其中输入特性记为Fhigh和Flow。Fhigh是deep模块的输出,Flow是编码器的对应部分。注意,它们具有相同的通道。UAFM首先利用双线性插值运算将Fhigh上采样到Flow的相同大小,而上采样特征记为Fup。然后,注意模块以Fup和Flow为输入,产生权重α。注意,注意模块可以是插件,比如空间注意模块、通道注意模块等。然后,我们分别对Fup和Flow应用元素智能Mul运算来获得注意加权特征。最后,UAFM对注意加权特征进行逐元素相加,并输出融合后的特征。我们可以用公式1表示上述过程。
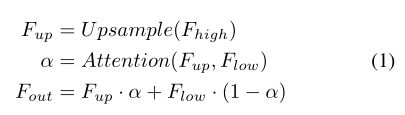
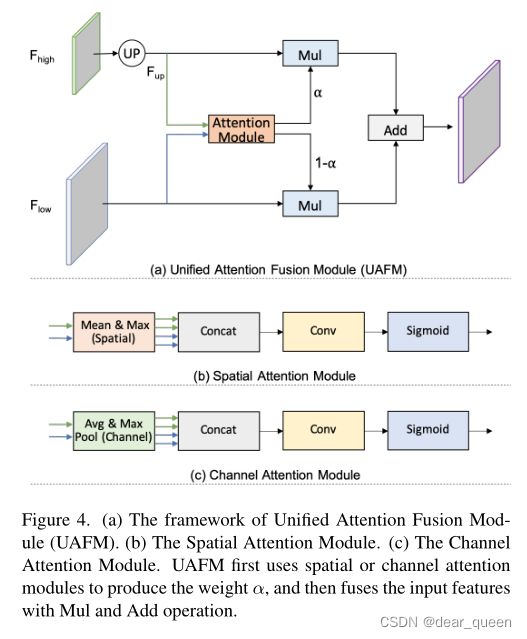
spatial attention module(空间关注模块)。空间注意模块的动机是利用空间间关系产生一个权重,它代表输入特征中每个像素的重要性。如图4 (b)所示,给定输入特征Fup∈RC×H×W和Flow∈RC×H×W,我们首先沿通道轴进行mean和max运算,生成四个特征,其维数为R1×H×W。然后,将这四个特征连接到一个特征Fcat∈R4×H×W。对于串联特征,对输出α∈R1×H×W进行卷积和s型运算。空间注意模块的表达式如式2所示。此外,空间注意模块可以灵活,如删除max操作,以减少计算成本。
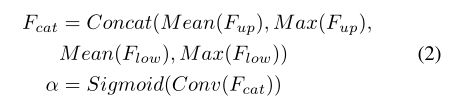

channel attention module。通道注意模块的关键概念是利用通道间的关系产生一个权重,该权重表示每个通道在输入特征中的重要性。如图4 (b)所示,提出的通道注意模块利用平均池化和最大池化操作来压缩输入特征的空间维度。这个过程用维度RC×1×1生成四个特性。然后,它沿着通道轴将这四个特征串联起来,进行卷积和sigmoid运算,产生一个权重α∈RC×1×1。总之,channel attention模块的流程可以写成式3。

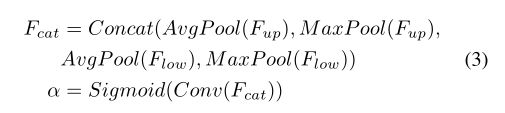
这里比较一下
spatial attention module和channel attention module感觉这里差不多的亚子:
单看公式:
spatial:
channel
空间是采用了mean运算和max运算,而channel是采用了平均池化和最大池化。这里看下
代码段解析看下附录部分(后面有博文介绍)
3.3 Simple Pyramid Pooling Module
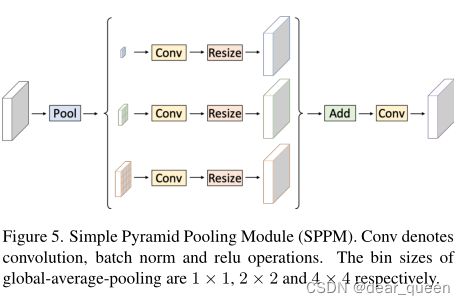
如图5所示,我们提出了一个简单金字塔池化模块(SPPM)。它首先利用金字塔池模块融合输入特性。金字塔池化模块有三种全局平均池化操作,大小分别为1 × 1、2 × 2和4 × 4。然后,输出特征后进行卷积和上采样操作。对于卷积操作,内核大小为1×1,输出通道小于输入通道。最后,我们将这些上采样特征加起来,并应用卷积运算产生精化特征。与原始PPM相比,SPPM减少了中间和输出通道,消除了捷径,用加法操作代替了拼接操作。因此,SPPM更有效,更适合于实时模型。
3.4. Network Architecture
图2展示了提议的PP-LiteSeg的架构。PP-LiteSeg主要包括三个模块:编码器、聚合器和解码器。首先,给定输入图像,PP-Lite利用一个通用的轻量级网络作为编码器提取层次特征。详细地,我们选择STDCNet的[8],因为它的出色的性能。STDCNet有5个阶段,每个阶段的stride是2,所以最终的feature size是输入图像的1/32。如表1所示,我们提出了两个版本的PP-LiteSeg,即PP-LiteSeg- t和PP-LiteSeg- b,编码器分别为STDC1和STDC2。PPLiteSeg-B的分割精度更高,而PP-LiteSeg-T的推理速度更快。值得注意的是,我们将SSLD[7]方法应用到编码器的训练中,得到了增强的预训练权值,这有利于分割训练的收敛。

其次,PP-LiteSeg采用SPPM对远程依赖进行建模。将编码器的输出特征作为输入,SPPM产生一个包含全局上下文信息的特征。最后,PP-LiteSeg利用我们提出的FLD逐步融合多层次特征并输出结果图像。具体来说,FLD由两个UAFM和一个分割头组成。为了提高效率,我们在UAFM中采用了空间注意模块。每个UAFM以两个特征作为输入,即编码器各阶段提取的低级特征,SPPM或深度融合模块产生的高级特征。后一种UAFM输出下采样比为1/8的融合特征。在分割头部,我们进行convn - bn - relu操作,将1/8下样本特征的通道减少到类的数量。接着进行上采样操作,将特征大小扩大到输入图像的大小,并通过argmax操作预测每个像素的标签。采用交叉熵损失与在线硬例挖掘相结合的方法对模型进行优化。
4. Experiments
在本节中,我们首先介绍数据集和实现细节。然后,我们将实验结果在准确性和推理速度方面与其他先进的实时方法进行了比较。最后,我们通过消融实验证明了所提出模块的有效性。
4.1. Datasets and Implementation Details
Cityscapes。Cityscapes[6]是一个用于城市分割的大型数据集。它包含5000张经过精细注释的图像,这些图像被进一步划分为2975,500张和1525张,分别用于训练、验证和测试。图像分辨率为2048 × 1024,这对实时语义分割方法提出了很大的挑战。带注释的图像有30个类,我们的实验只使用了19个类,以便与其他方法进行公平的比较。
CamVid。剑桥驾驶标记视频数据库(CamVid)[2]是一个用于道路场景分割的小型数据集。有701张具有高质量像素级标注的图像,其中分别选取367张、101张和233张图像进行训练、验证和测试。这些图像的分辨率都是960 × 720。标注后的图像提供了32个类别,我们的实验使用了其中11个类别的子集。
培训设置。按照常规设置,选择动量为0.9的随机梯度下降(SGD)算法作为优化器。我们也采用预热策略和“聚”学习率调度。对于cityscape,批量大小为16,最大迭代次数为160,000,初始学习率为0.005,优化器中的权重衰减为5e−4。对于CamVid,批量大小为24,最大迭代次数为1000次,初始学习率为0.01,权重衰减为1e−4。对于数据增强,我们使用随机缩放,随机裁剪,随机水平翻转,随机颜色抖动和标准化。cityscape和Camvid的随机尺度分别为[0.125,1.5]和[0.5,2.5]。cityscape的裁剪分辨率为1024×512, CamVid的裁剪分辨率为960 × 720。我们所有的实验都是在特斯拉V100 GPU上使用PaddlePaddle1[19]进行的。代码和预训练的模型可在PaddleSeg2[16]。
推理的设置。为了进行公平的比较,我们将PPLiteSeg导出到ONNX,并使用TensorRT来执行模型。类似于其他方法[8,26],首先将来自Cityscapes的图像调整为1024 × 512和1536 × 768,然后将缩放后的图像进行推理模型,得到预测的图像,最后将预测的图像调整为输入图像的原始大小。这三个步骤的代价被计算为推断时间。对于CamVid,推理模型以原始图像作为输入,分辨率为960×720。我们在NVIDIA 1080Ti GPU上,在CUDA 10.2, CUDNN 7.6, TensorRT 7.1.3下进行所有的推理实验。我们使用标准mIoU进行分割精度比较和FPS进行推断速度比较。
4.2. Experiments on Cityscapes
4.2.1 Comparisons with State-of-the-arts
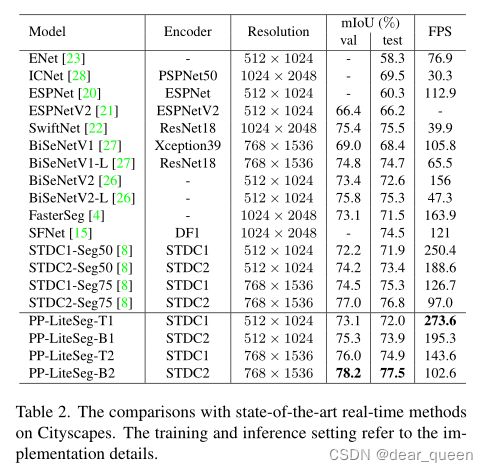
通过上述训练和推理设置,我们将提出的PP-LiteSeg与之前最先进的Cityscapes实时模型进行了比较。为了进行公平的比较,我们在512 × 1024和768 × 1536两种分辨率下评估PP-LiteSeg-T和PP-LiteSeg-B。表2给出了各种方法的模型信息、输入分辨率、mIoU和FPS。图1提供了分割精度和推理速度的直观比较。实验评估表明,提出的PP-LiteSeg实现了最先进的准确性和速度之间的权衡与其他方法。具体来说,我们可以观察到PP-LiteSeg-T1达到了273.6 FPS和72.0% mIoU,这意味着最快的推断速度和竞争精度。在768 × 1536的分辨率下,PPLiteSeg-B2达到了最佳的精度。验证集的78.2% mIoU,测试集的77.5% mIoU。此外,使用与STDC-Seg相同的编码器和输入分辨率,PPLiteSeg具有更好的性能。
4.2.2 Ablation study
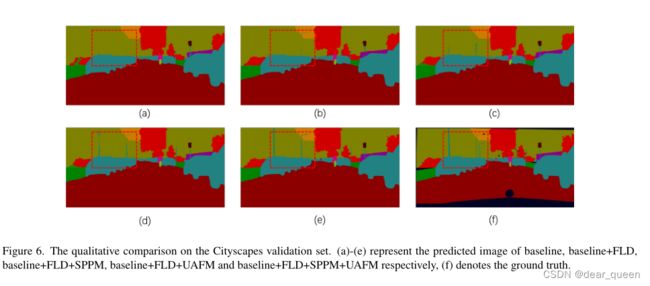
消融实验证明了该模块的有效性。实验选择PP-LiteSeg-B2进行比较,使用相同的训练和推理设置。基线模型为PP-LiteSeg-B2(不含所提模块),解码器特征通道数为96,融合方法为元素加权求和。表3是我们消融研究的定量结果。我们可以发现,PP-LiteSeg-B2中的FLD使mIoU提高了0.17%。加入SPPM和UAFM也提高了分割精度,但推理速度略有下降。基于这三个模块,PP-LiteSeg-B2实现了78.21 mIoU, 102.6 FPS。mIoU比基线模型提高了0.71%。图6提供了定性比较。我们可以看到,将FLD、SPPM和UAFM分别加入预测后的图像更符合地面真实情况。总之,我们提出的模块是有效的语义分割。
4.3. Experiments on CamVid
为了进一步演示PP-LiteSeg的功能,我们还在CamVid数据集上进行了实验。与其他作品类似,用于训练和推理的输入分辨率为960 × 720。如表4所示,PP-LiteSeg-T实现了222.3 FPS,比其他方法快了12.5%以上。PP-LiteSeg-B达到了最好的精度,即75.0% mIoU和154.8 FPS。总之,对比显示,PP-LiteSeg在Camvid上实现了最先进的准确性和速度之间的权衡。

5. Conclusions
本文重点设计了一种新的实时语义分割网络。首先,提出了灵活轻量级解码器(FLD),以提高以往解码器的效率。然后,我们提出了一种统一注意融合模块(UAFM),它能有效地增强特征表示。此外,我们提出了一个简单金字塔池化模块(SPPM),以较低的计算成本聚合全局上下文。基于这些新的模块,我们提出了PP-LiteSeg,一个实时语义分割网络。大量实验表明,PP-LiteSeg实现了分割精度和推理速度之间的平衡。在未来的工作中,我们计划将我们的方法应用到更多的任务中,比如matting和interactive segmentation。
参考
参考