用于光流估计的无监督深度学习DSTFlow
用于光流估计的无监督深度学习DSTFlow
原文链接
摘要
最近的工作表明,光流估计可以被表述为一个监督学习问题。 此外,卷积网络已成功应用于此任务。 然而,监督流学习由于缺乏标记的训练数据而变得模糊。 因此,现有方法必须转向计算机轻松生成地面实况(ground truth)的大型合成数据集。 在这项工作中,我们探索是否可以在没有监督的情况下训练用于流量估计的深度网络。 估计流量使用图像扭曲,我们设计了一种简单而有效的无监督学习光流方法,通过直接最小化光度一致性。 我们证明了可以使用我们的无监督方案从端到端训练流网络。 在某些情况下,我们的结果非常接近在完全监督下训练的方法的性能。
1、简介
每分钟都会生成大量的数字视频。 这对有效的视频分析提出了新的挑战。 估计像素级运动,也称为光流,是早期视频分析的基本构建块。 光流是计算机视觉中的一个经典问题,在现实世界中有许多应用,包括自动驾驶、视频分割和视频语义理解(Menze 和 Geiger 2015)。然而,光流的准确估计仍然是一个具有挑战性的问题(Sun、Roth 和 Black 2014;Butler 等人 2012)。
深度学习极大地推进了人工智能的所有前沿领域,尤其是计算机视觉。 我们见证了卷积神经网络 (CNN) 这个聚宝盆在大量计算机视觉任务(包括图像去噪、图像分割和对象识别)中实现了卓越的性能。 最近的一些进展也允许像素级预测,如语义分割(Long、Shelhamer 和 Darrell 2015)和轨迹分析(Lin 等人,2017)。 然而,对标记数据的贪婪成为深度学习方法的主要限制。 对于本文中的问题,这甚至是明显的:光流估计需要在两个连续帧之间有像素级运动的密集标签。 为现实中的视频获得这样的光流地面实况极具挑战性(Butler et al. 2012)。 因此,最先进的深度学习方法(Fischer 等人,2015 年;Mayer 等人,2016 年)通过繁琐且困难的像素级标记步骤,转向合成标记的数据集。 一项基于众包(crowd-sourcing)的研究(Altwaijry 等人,2016 年)表明,人类参与者主要依赖全局外观线索来感知运动,而人类不太关注细粒度的像素级对应关系。
学习光流是否需要像素级监督? 最近关于从视频中学习的工作表明,通过质量控制,通过无监督或半监督学习可以获得有效的特征表示(Wang 和 Gupta 2015;Li et al. 2016)甚至跨实例关键点匹配(Zhou et al. 2016)。 另一项观察是,人脑带有视觉短期记忆(VSTM)模块(Hollingworth 2004),主要负责理解视觉变化,2.5 个月大的没有任何教学的婴儿能够辨别 需要运动理解的遮挡、抑制和覆盖事件(Bail largeon 2004)。 这些计算和生物学研究表明,我们可以在没有(或很少)真实标签的情况下学习光流。 在这项工作中,我们探索了神经网络是否可以完全基于光度一致性而无需监督进行训练。
给定两个输入图像,我们的网络从使用 FlowNet 结构的本地化网络开始(Fischer 等人,2015 年)。 定位网络输出像素级平移估计。 这被送入双线性采样网络以生成空间扭曲特征图。 最后,源图像和目标图像的扭曲特征图之间的光度误差被视为损失,由广泛用于无学习变分方法的目标函数测量(Brox 等人,2004 年)。 我们的网络可以看作是为最近提出的空间变换器网络 (STN) (Jader berg et al. 2015) 的光流量身定制的像素级实施例,该网络最初是为对象级变换建模而设计的。 另一个根本区别是 STN 在使用对象级监督的识别的上下文中学习转换,而我们的方法在完全无监督的设置中利用损失。
我们论文的主要结果是使用我们的无监督方案训练的深度网络接近完全监督训练的性能水平。 我们认为这主要是由于我们的端到端训练,它允许网络利用大区域内的上下文信息来推断局部运动。 为此,我们总结了我们的主要贡献如下:
1)据我们所知,这是使用深度神经网络在没有任何监督的情况下学习光流的首批作品之一。 我们的工作与最先进的无学习方法 DeepFlow(Wein zaepfel 等人,2013 年)或 EpicFlow(Revaud 等人,2015 年),以及有监督的深度学习方法 FlowNet(Fischer 等人,2015 年)和 DispNet(Mayer 等人,2016 年)有着根本的不同。 2015)。
2)我们提出了一种新的光流网络,它类似于空间变换器网络(Jaderberg 等人,2015 年)的管道,利用变分方法(Brox 等人,2004 年)中使用的损失函数而无需监督,对于用于光流估计的端到端无监督学习。 虽然收益不大,但我们认为这是未来探索的一个有希望的方向。
3) 最后,为了进行比较和进一步创新,我们将在本文发布后提供我们方法的公共 Caffe (Jia et al. 2014) 实现。
2、相关工作
我们使用视频中的卷积网络解决了光流的无监督学习问题。 首先,我们简要介绍了最近关于光流估计和从视频学习的方法。 我们的方法受到空间变换器网络(Jaderberg et al. 2015)的启发,这将在本节的最后一部分进行讨论。
2.1光流
光流是计算机视觉中的一个经典问题。 尽管关于该主题的文献丰富,但它仍然非常具有挑战性(Sun、Roth 和 Black 2014)。 许多光流方法基于变分方法,该方法被表述为能量最小化问题(Horn 和 Schunck 1981)。 这种范式依赖于颜色和渐变的光度一致性,以及自然图像的空间平滑度。 虽然很有吸引力,但这些方法可能会陷入局部最小值,并在跨尺度上累积误差,并且在大位移时往往会失败。
为了解决这个问题,大位移光流 (LDOF) (Brox 和 Malik 2011) 将局部描述符匹配与变分方法相结合。 本地描述符,例如 HOG(Mikolajczyk 和 Schmid 2005)在刚性局部帧中提取并在图像中匹配。 这些匹配结果用于初始化流量估计,并在粗到细金字塔内使用变分方法进一步优化。 徐等 (Xu、Jia 和 Matsushita 2012)进一步集成了更先进的匹配方法,例如 SIFT-flow(Liu、Yuen 和 Torralba 2011)和 PatchMatch(Barnes 等人,2010)以提高流的准确性。
类似 HOG 的特征最近被 CNN 启发的补丁匹配方案:DeepMatching(Revaud et al. 2016)所取代,成就了最先进的 DeepFlow 方法(Weinzaepfel et al. 2013)。 DeepFlow 遵循从细到粗的过程。 它从局部补丁匹配开始,通过最大池化(LeCun et al. 1998)构建逐渐降低分辨率的匹配图,然后是传统的能量最小化框架。 后续工作 EpicFlow(Revaud 等人,2015 年)通过利用轮廓线索来约束流图来改进 DeepFlow。 这是通过从初始匹配集进行稀疏到密集插值来完成的,其中权重由边缘感知测地距离(edge aware geodesic distance)定义。DeepFlow 和 EpicFlow 都是免学习的,因为特征是手工制作的,不涉及学习。
虽然光流估计已经很成熟,但在最近的工作(Fischer 等人,2015 年)之前,很少使用端到端卷积网络。 FlowNet (Fischer et al. 2015) 不依赖于手工设计的特征,而是将光流作为监督学习任务,并利用端到端的卷积网络来预测流场。 DispNet (Mayer et al. 2016) 将这个想法扩展到视差和场景流估计。 然而,这些神经网络方法需要强大的训练监督。 具体来说,FlowNet 和 DispNet 的训练是通过大型合成生成的数据集实现的。 在这项工作中,我们探索是否可以使用无监督学习。
最后,我们强调学习与 CNN 匹配并不是一个全新的想法(Zbontar 和 LeCun 2015;Zagoruyko 和 Komodakis 2015;Fischer 等人 2015)。 与学习匹配局部补丁(match local patches)不同(Zbontar 和 LeCun 2015;Zagoruyko 和 Komodakis 2015),我们的方法直接预测一对输入帧的像素级偏移。 虽然我们的网络类似于(Fischer et al. 2015),但我们的训练是完全无监督的。 据我们所知,最相关的工作是(Zhou et al. 2016)。 我们的方法与 (Zhou et al. 2016) 在三个方面不同:
1)他们利用额外的 3-D CAD 模型来建立跨实例对应链,因此训练图像需要相似或属于同一类别 作为可用的 CAD 模型;
2)他们使用循环一致性损失,需要一次涉及四张图像;
3)他们主要解决跨实例匹配问题,不关注通常涉及连续视频帧的光流场景。 因此,我们的贡献与这些以前的工作是互不相关的。
2.2从视频中学习
以半监督或无监督的方式从视频本身学习视觉表示的研究正在兴起。 开创性工作(van Hateren 和 Ruderman 1998 年;Hurri 和 Hyvarinen 2003 年)基于使用时间相干性概念的独立分量分析 (ICA)(n Independent Component Analysis)。 斯里瓦斯塔瓦等(Srivastava、Mansimov 和 Salakhutdinov 2015)使用长短期记忆(LSTM)(Hochreiter 和 Schmidhuber 1997)编码器-解码器框架来学习视频表示。 五郎等 al (R. Goroshin and LeCun 2015) 建议通过施加时间上接近的帧应该具有相似特征表示的约束来从视频中学习特征。 此外,Wang 和 Gupta(Wang 和 Gupta 2015)学习通用的 CNN 特征通过强制不同帧中的跟踪块应该具有相似的视觉表示。 (Agrawal、Carreira 和 Malik 2015)利用自我运动意识作为特征学习的监督,其中关于自我运动的全局转换由相机姿势假设给出。 然而,虽然在以前的方法中,训练目标被用作替代物来鼓励网络学习有用的表示,但我们的主要目标是训练像素级光流模型,与网络关联的学习到的表示只是一个有用的副产品(注:网络权重有用,但不是主要目的,主要目的是得到像素级光流估计模型)。 本着这种精神,我们的工作是类似的想法:从视频中学习边缘检测器(Li et al. 2016)。 然而,设计的网络和目标都非常不同,因为边缘检测只涉及单个图像,而光流需要匹配一对帧中的像素。
2.3通过解开(disentangle)姿势和身份来学习
光流试图估计像素或局部补丁的运动。 然而,普通的CNNs 只有有限的预定义池化机制来处理空间变化。 为了实现更灵活的空间变换能力,(Hinton、Krizhevsky 和 Wang 2011)学习了单元的层次结构,这些单元局部变换其输入以生成对输入立体对的小旋转。 (Cheung et al. 2014) 提出了一种具有表示姿势和身份的解耦语义单元的自动编码器。 最近,空间变换器网络 (STN) 由(Jaderberg 等人,2015 年)提出作为一种注意力机制(Mnih 等人,2014 年;Ba、Mnih 和 Kavukcuoglu 2015 年),能够扭曲输入以提高识别精度。 它将图像作为输入并为预先确定的转换模型生成参数,该模型又用于转换图像。 (Altwaijry et al. 2016) 使用 STN 进行图像相似性验证,因为该模型可以使用标准反向传播进行训练,这与依赖于强化学习的注意力机制的技术 (Mnih et al. 2014; Ba, Mnih, and Kavukcuoglu 2015) 不同。 我们的方法受到 STN 范式的启发,并向网络加入了一个采样层,允许端到端的反向传播。
3、网络和训练过程
图 1:我们的密集空间变换流 (DSTFlow) 网络的呈现网络架构由三个关键组件组成:基于类似 flowNet 结构的定位层,基于密集空间变换的采样层(这篇论文由双线性插值层实现)和最后的损失层。 所有层权重都是通过反向传播进行端到端地学习。

使用一对图像作为输入,我们的光流网络在概念上可以被视为一个空间变换网络(Jaderberg et al. 2015),具有三个主要组件:i)通过 FlowNet 结构输出像素级变换的定位部分,即如图 1 所示的流程; ii) 双线性采样网络,用于通过定位网络的平移输出生成扭曲帧; iii)最后一层涉及关于目标图像和来自源图像的扭曲图像之间差异的损失函数。 损失类似于之前工作中使用的基于变分框架的经典目标函数(Brox et al. 2004),但我们使用它来训练流网络权重而不是估计流图。 我们将我们的网络称为密集空间变换流 (DSTFlow)(概览参见图 1),其详细说明如下:
3.1定位网络
我们采用 FlowNet 的网络结构,特别是 FlowNetSimple(参见 (Fischer et al. 2015)) 作为计算像素级偏移的网络。 FlowNet 是迄今为止为数不多的允许端到端流图估计的网络,即像素偏移计算,并且该模型可以通过反向传播进行差异训练。 一种潜在的替代方案是(Zhou 等人,2016 年)图 2 中提出的网络,该网络旨在用于交叉实例关键点匹配。 我们把它留到以后的工作中去。
图 2:我们用于无监督光流学习的神经网络的信息流。 中间的卷积层类似于 FlowNet 的简化版本(参见 (Fischer et al. 2015) 中的图 2)。 因此,使用类似的多尺度损失求和来训练网络。
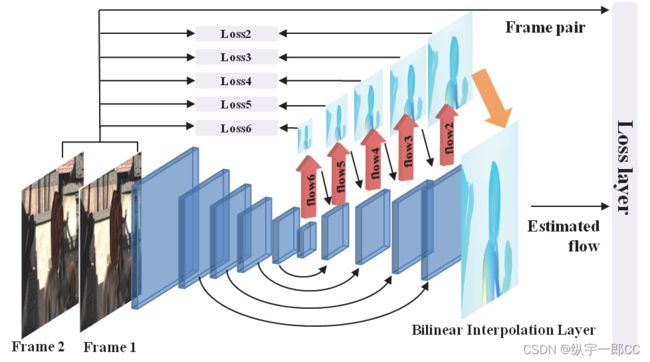
定位层以一对图像作为输入,并输出 x-y 流场。 为了简单和通用,我们将两个输入图像与 3 × 2=6 通道堆叠在一起,这是我们从 FlowNetSimple(Fischer 等人,2015 年)借来的。 如图 2 所示,它由 10 个卷积层和一个细化组成,其主要的梯度是“上卷积”又名“反卷积”层(Zeiler and Fergus 2014),这可以看作是一个反池化 (扩展特征图,而不是池化)和卷积操作。 我们将带有相应“conv”层的特征图的“反卷积”输出和来自先前尺度的未池化的流预测连接起来。 通过这样做,可以很好地维护预测层的高级表示和细粒度信息。
3.2采样网络
采样层使用来自定位网络的输出变换帮助将输入特征图扭曲为变换后的输出图。 具体来说,每个 (xsi , yis) 坐标定义了输入特征图 U 中的空间位置,其中用采样内核来获取输出特征图 V 中特定像素 i 的值。 而 Uc nm 是沿通道 c 的输入特征图在位置 (m, n) 处的值,而 Vic 是像素 i 的输出值。 为了允许可微的随机(子)梯度下降,我们采用双线性采样内核:
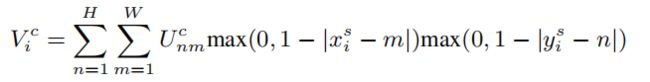
反向传播是通过计算偏导数来完成的:
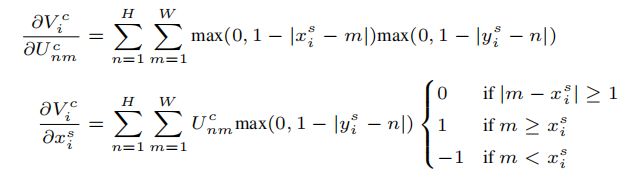
其中 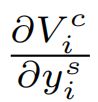 可以用类似的方式计算。
可以用类似的方式计算。
请注意,当我们得到大小为原始帧四分之一的 flow2(参见图 2 中最右侧的棕色箭头)时,我们既不会继续重复去卷积操作,也不会只是通过传统的双线性插值简单地放大大小。 相反,我们通过空间双线性变换进行放大,这是我们密集空间变换的一个特例,不仅通过简化网络节省了时间和空间的成本,而且还将它纳入到了我们整个网络进行端到端训练。 换句话说,我们可以将传统的双线性插值无缝集成到我们的网络管道中。
3.3损失层
我们遵循在无学习变分方法(Brox 等人,2004 年;Brox 和 Malik 2011 年)中使用的传统损失函数,它类似于(Horn 和 Schunck 1981 年)的原始公式。 这也受到最近的工作(Chen 和 Koltun 2016)的启发,该工作表明,即使在存在大位移的情况下,这种流动目标本身也足够强大,可以产生准确的速率映射。 它结合了一个数据项,该项假设某些图像属性随时间保持不变,以及一个空间项(通常是平滑的),建模流量在图像上的变化情况。 数据丢失基于预测的光流场测量一个输入图像与来自另一幅图像的扭曲图像之间的差异。 平滑项对相邻流预测之间的差异进行建模。 在这里,我们可以将损失解释为与真实情况的所需属性相关的代理,即虽然我们不知道真实情况是什么,但我们知道它应该如何表现。
对于图像 I1 和 I2,作为大多数光流算法的共同核心特征,我们选择通过 Charbonnier 惩罚(Bruhn and Weick ert 2005) Ψ(s) = (s2 + 0.0012) 对灰度和梯度恒常性进行建模 :绝对值的可微变体,以及针对异常值和噪声的稳健凸函数。 最近的系统评估(Sun、Roth 和 Black 2014)也推荐使用它。
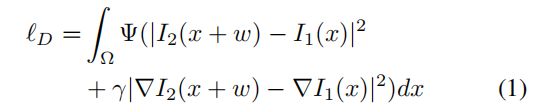
平滑项建模为:
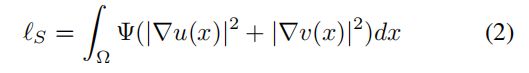
结合上述术语,称为密集空间变换 (DST) 损失的总体损失为 :
![]()
3.4多尺度损失累积
FlowNet 可以输出多尺度的流量,使用多尺度地面实况逐层改进预测的流量。 类似地,我们在下采样后在多尺度输入帧上施加我们的 DST 损失。 如图2所示,总共有六个损失层。 总之,我们使用总和损失来指导网络上的信息流。 参数通过标准反向传播进行更新,因为所有部分都可以进行不同的训练。
需要注意的是,我们的损失与监督学习 FlowNet 中使用的端点误差 (EPE) 损失有很大不同,即预测流向量和ground truth之间的欧几里德距离,在所有像素上取平均值。
3.5训练
类似于 Flownet,我们通过施加镜像、平移、旋转、缩放(空间增强)以及对比度、伽马和亮度变换(色度增强)来执行数据增强以避免过度拟合。
我们对所有非线性使用整流线性单元 (ReLU),并使用随机梯度下降训练网络。 为了处理六个多尺度损失层,我们采用了损失权重计划(Mayer et al. 2016),它从底部损失层到顶部损失层逐渐训练网络,直到将它们相加以供进一步训练。
最后我们要指出,虽然我们的网络由三部分组成,看起来比 FlowNet 更复杂,但在测试阶段只会涉及定位网络,其运行速度与 FlowNet 相同。
4、实验和讨论
4.1数据集和同期方法
我们在三个现代数据集上评估我们的方法:
MPI-Sintel
数据集(Butler et al. 2012)从动画电影中获得,该电影特别关注逼真的图像效果。 它包含多个序列,包括大/快速运动。 我们同时使用“clean”和“fifinal”版本图像来训练模型。
KITTI
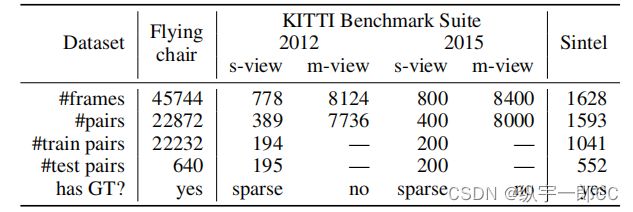
数据集(Geiger、Lenz 和 Urtasun 2012)包含从驾驶平台在城市街道上拍摄的照片。 它在大位移、不同材料、多种照明条件方面提出了更大的挑战。 “KITTI2012”(Geiger et al. 2013)由 194 个训练对和 195 个测试对组成,而 KITTI2015(Menze and Geiger 2015)由 200 个训练对和 200 个测试对组成。 在这两个数据集中,还有多视图扩展数据集,每个场景 20 帧,但没有提供地面实况。 在我们的实验中,我们将两个数据集的多视图扩展版本(无地面实况)一起作为具有 13372 个图像对的训练数据集,并使用具有地面实况的对作为我们的验证集,其中包含 194 对“KITTI2012”和 200 分别为“KITTI2015”。 最后,我们使用 KITTI 网站上的测试协议在线测试我们的模型2。 请注意,我们在多视图数据集中排除了具有地面实况的对及其相邻的两个帧,以进行无监督训练,以避免混合训练和测试样本。
Flying Chairs
数据集(Fischer et al. 2015)是最近发布的合成基准,它由来自 Flickr 的分段背景图像组成,上面叠加了来自(Aubry et al. 2014)的椅子的随机图像 . Flownet (Fischer et al. 2015) 已经表明它可以用来训练模型作为监督,尽管它是人工创建的。 与 (Fischer et al. 2015) 一样,我们将数据集分为 22232 个用于训练的样本(即图像对)和 640 个用于测试的样本。
表 1 中给出了所用数据集的概述。有关数据集的更多详细信息,请参见(Fischer 等人,2015 年)。
表 1:数据集概览。 GT 表示地面真相。 “飞椅”是合成生成的数据集。 KITTI 有两个版本。 注意在 KITTI 中,单视图(s-view)样本是成对的并用ground truth标记,多视图(m-view)是没有ground truth的扩展集。 注意“Sintel Clean”和“Sintel Final”具有相同的尺寸。
我们比较了最先进的方法,包括 EpicFlow(Revaud 等人 2015)、EPPM(Bao、Yang 和 Jin 2014 年)、DeepFlow(Weinzaepfel 等人 2013 年)、LDOF(Brox 和 Ma lik 2011 年), FlowNet(Fischer 等人,2015 年)。 对于监督学习方法 FlowNet,我们使用网站上公开提供的模型,在 (Fischer et al. 2015) 中称为 FlowNet+ft。 在这里,我们将其称为 FlowNet(C+S),它在“Chairs”数据集上训练并在“Sintel”上进一步微调。 请注意,其他对等方法都是无需学习的。
4.2训练和评估协议
对于损失函数,我们在方程 3 中设置 α = 2,在方程 1 中设置 γ = 1。 与 (Fischer et al. 2015) 一致,我们采用 Adam 方法并设置其参数 β1 = 0.9 和 β2 = 0.999。 起始学习率 λ 由 1e−4 设置,在前 30000 次迭代后每 6000 次迭代减少一半。 批量大小设置为 64。对于微调,我们从学习率 1e − 5 开始。
请注意,由于“Flying Chairs”具有丰富的样本,我们暂时使用它来使用我们的无监督训练程序从头开始初始化我们的模型,然后 使用“KITTI”和“MPI-Sintel”数据对模型进行微调,分别对这两个数据集进行性能评估。
4.3结果与讨论
表 2 报告了关于训练集和测试集的端点误差 (EPE) 的评估结果。数据集“Flying Chairs”, ‘KITTI2012’ 和 ‘Sintel’ 的视觉结果分别如图 3、图 4、图 5 所示。 我们的方法 DSTFlow 分别在三个数据集上进行了训练。 为了可视化流场,我们使用 Sintel 提供的工具(Butler et al. 2012)。 流向用颜色编码,大小用颜色强度编码。
表 2:与同期方法相比,我们网络的遮挡 (OCC) 和非遮挡区域 (NOC) 上的平均端点误差,即 EPE(以像素为单位)以及我们的方法在不同数据集上的变化。 DSTFlow(C+K) 表示首先使用“Chairs”训练 DSTFlow,然后使用“KITTI”进行细化。 DSTFlow(C+S) 表示首先使用“Chairs”训练 DSTFlow,然后使用“Sintel”进行细化。 f1-all:光流异常值在所有像素上的百分比。 仅当该点的端到端误差与地面实况相比 < 3px 或 < 5% 时,才计算该点正确。 请注意,带星号的数字是网络对它们进行训练的数据的结果,因此不能直接与其他结果进行比较,因为它们倾向于过度拟合。
图 3:椅子上的流量预测示例。
图 4:KITTI2012 上的流量预测示例。
图 5:Sintel 上的流量预测示例。
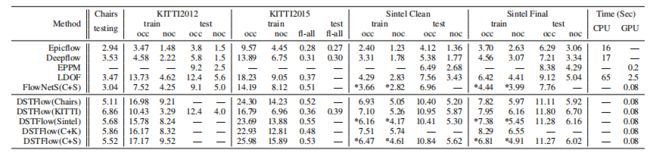



基于表 2 中的定量结果,我们分别对我们方法的每个变体进行了分析:
DSTFlow(Chairs)
这意味着该模型是通过无监督学习在 Flying Chairs 数据集上训练的。 DST Flow(Chairs) 在测试集上实现了合理的性能。 请注意,在非常具有挑战性的基准“Sintel Final”上,它的性能非常接近 LDOF(Brox 和 Malik 2011),并且在“KITTI2015”训练集上,它在度量 f1-all 上也实现了与 FlowNet 相似的性能。 这些结果令人鼓舞,特别是考虑到我们只使用计算机生成的数据进行无监督学习。
DSTFlow(KITTI) 和 DSTFlow(C+K)
我们还在“KITTI”数据上训练我们的模型。 KITTI 上的标签信息非常稀少,只有很小比例的样本有标签信息。 在这种情况下,无监督学习是受欢迎的。
具体来说,我们测试了两个变体。 DSTFlow(KITTI) 说明我们使用由 13372 个图像对组成的过滤后的多视图(无地面实况)数据作为无监督学习的训练数据。 尽管训练集的大小小于“飞椅”,但它明显大于 KITTI 数据集中数百个标记图像对。 与 DSTFlow(Chairs) 相比,它是在自然图像上训练的。 另一个版本的 DSTFlow(C+K) 是首先在“飞椅”数据上训练,然后通过“KITTI”数据改进的模型,所有这些都在无监督的设置中。 我们观察到,在微调阶段,获得合理目标所需的迭代次数更少。 同样值得注意的是,DSTFlow(KITTI) 在 2012 年和 2015 年的“KITTI”上均优于无学习方法 LDOF,甚至在“非遮挡”的“KITTI2012”测试集上的表现甚至略优于监督学习方法 FlowNet 。 在“KITTI2015”的训练集上,DST Flow(KITTI) 也与它的监督对手 FlowNet 相当。
DSTFLOW(Sintel) 和 DSTFlow(C+S)
尽管 Sintel 数据集仅提供 1041 对图像用于训练,我们仍然通过施加广泛的数据增强(称为DSTFLOW)在 sintel 上从头开始训练模型 (辛特尔)。 DSTFlow(C+S) 表示使用“Flying Chairs”数据训练模型并使用“Sintel”数据微调模型。 尽管这两种模型在训练集上的表现都更好,但与 DSTFlow(Chairs) 相比,它们在测试集上的表现都下降了。
无需标记更大数据集的潜力
尽管目前,我们的无监督模型并没有超越最先进的基于监督学习的模型,但我们相信有一些空间可以探索这种可能性。 背后的逻辑是,目前即使是无监督学习的训练数据集的大小仍然非常有限,例如 即使对于合成数据集“飞椅”,图像对的数量也少于 23000。这种现状可能无法充分发挥无监督流网络的潜力。 本着这种精神,我们推测在没有监督的情况下,给定更多的训练数据,可以进一步改进无监督的光流网络。
5、结论和展望
我们提出了一个以无监督方式训练的端到端可微分光流网络,据我们所知,这是第一个无监督光流学习网络。 尽管它目前的性能略落后于最先进的技术,但我们认为这是一个很有前途的方向,因为它可以利用大量现成的视频数据和建议框架下的新损失函数。 近期的一项工作是整合 (Brox and Malik 2011) 中的匹配项以获取损失函数。