目标检测: 一文读懂 FCOS (CVPR 2019)
论文:Fully Convolutional One-Stage Object Detection
论文链接:https://arxiv.org/pdf/1904.01355.pdf
代码链接:https://github.com/tianzhi0549/FCOS
文章目录
-
- 1 为什么要提出 FCOS ?
- 2 FCOS 网络框架
- 3 FCOS 实现细节
-
- 3.1 如何预测目标bbox?
- 3.2 什么是中心度?
- 3.3 为什么需要预测中心度?
- 3.4 为什么不同特征层的heas是共享的?
- 3.5 为何用FPN网络?
- 3.6 FPN网络需要注意哪些细节?
- 3.7 loss设计
- 4 FCOS 性能效果
- 5 总结
FCOS 是 anchor-free 的目标检测经典算法,今天我们就一起来分析这个算法。现在主流的目标检测网络如 RetinaNet, SSD, YOLOv3 和 Faster R-CNN 都是基于anchor-based,即先在特征图上生成 anchor box,随后调整这些anchor box 的位置和尺寸生成最后的预测值。而本文提出单阶段的 anchor-free 目标检测算法,无需事先生成 anchor,下面开始今天的正题!
1 为什么要提出 FCOS ?
之前目标检测算法有如下不足:
- 检测性能对
anchor boxes的数量和宽高比(aspect ratio)敏感; - 由于
anchor boxes的宽高比是固定的,难以处理尺度差异大的目标,尤其是小目标检测困难; - 为了提高
recall,anchor-based detector需要在输入图片上设置密集的anchor boxes,其中大部的anchor boxes是负样本,造成正负样本不平衡问题; anchor boxes涉及例如IOU的大量计算;- 一些
FCN-based检测框架如DenseBox使用图像金字塔,对图片进行裁剪和缩放,以处理不同尺度的bbox,违背了FCN一次计算的原则。
FCOS 做了如下改进:
- 提出
anchor-free的目标检测框架,避免了上述anchor-based方法带来的问题; - 为了处理不同尺度大小的
bbox,提出使用FPN网络进行图像的一次计算; - 提出使用
center-bess分支,来弥补预测像素点与对应bbox中心的误差。
2 FCOS 网络框架
FCOS采用类似语义分割方法的预测,主体网络框架如下:
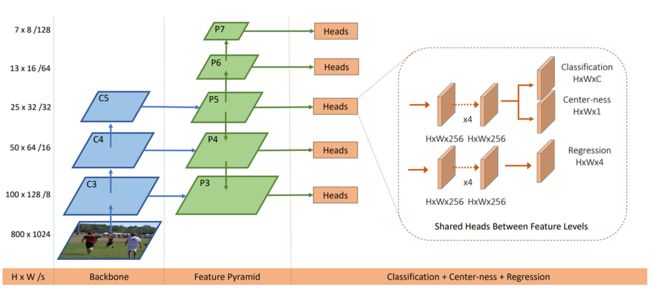
- 输入端 — 输入端表示输入的图片。该网络的输入图像大小为 W W W 和 H H H 。
- 基准网络 — 基准网络用来提取图片特征。论文使用
FPN网络,对每个像素点进行多尺度预测。 - Head输出端 — Head用来完成目标检测结果的输出。输出
head有5个,这5个head是共享权重的,每个head有三个分支,分别为:目标类别classification(H×W×C),中心度centerness(H×W×1),和目标尺寸Regerssion(H×W×4)。
3 FCOS 实现细节
3.1 如何预测目标bbox?
以下图左边人物目标为例,其bbox区域内所有黄色像素位置的类别都为person。bbox区域内的对应的特征图上每个像素点都有其对应的回归目标 ( l ∗ , r ∗ , t ∗ , b ∗ ) (l^*,r^*,t^*,b^*) (l∗,r∗,t∗,b∗),对于某个像素的坐标 ( x , y ) (x,y) (x,y):
l ∗ = x − x 0 ( i ) , t ∗ = y − y 0 ( i ) r ∗ = x 1 ( i ) − x , b ∗ = y 1 ( i ) − y l^*=x-x_0^{(i)},t^*=y-y_0^{(i)}\\ r^*=x_1^{(i)}-x,b^*=y_1^{(i)}-y l∗=x−x0(i),t∗=y−y0(i)r∗=x1(i)−x,b∗=y1(i)−y
上述回归目标为正数,所以网络输出时还需要进行指数运算,最后预测的bbox为( x x x , y y y , l l l , r r r , t t t , b b b)。
3.2 什么是中心度?
中心度是衡量边界与目标中心的归一化距离,假设回归目标为 l ∗ l^* l∗, t ∗ t^* t∗, r ∗ r^* r∗ 和 b ∗ b^* b∗,则center-ness目标为:
c e n t e r n e s s ∗ = m i n ( l ∗ , r ∗ ) m a x ( l ∗ , r ∗ ) × m i n ( t ∗ , b ∗ ) m a x ( t ∗ , b ∗ ) centerness^*=\sqrt{\frac{min(l^*,r^*)}{max(l^*,r^*)}×\frac{min(t^*,b^*)}{max(t^*,b^*)} } centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)
当像素在目标区域的中心位置时,则有 l ∗ = r ∗ l^*=r^* l∗=r∗ 且 t ∗ = b ∗ t^*=b^* t∗=b∗ 时,此时中心度的值为1;
当像素位于目标区域的其他位置时,比如当像素刚好在图像的边界上,则会有 m i n ( l ∗ , r ∗ ) = 0 min(l^*,r^*)=0 min(l∗,r∗)=0或者 m i n ( t ∗ , b ∗ ) = 0 min(t^*,b^*)=0 min(t∗,b∗)=0,此时中心度的值为0;
所以中心度取值范围为 0 ≤ c e n t e r n e s s ∗ ≤ 1 0\leq centerness^*\leq1 0≤centerness∗≤1,越往目标中心,中心度值越大,如下图,红色代表1,蓝色代表0。

3.3 为什么需要预测中心度?
作者在论文中提到原因如下,如果不加这一项,FCOS性能会弱于anchor-based的检测模型,原因是模型会生成很多偏离目标中心的低质量bbox。

中心度使用方法:
- 在训练阶段:使用
BCE loss,加入到代价函数中一起训练网络; - 在测试阶段:对预测的
bbox进行打分: s c o r e f i n a l = s c o r e c l a s s i f i c a t i o n ∗ c e n t e r n e s s score_{final}=score_{classification } * centerness scorefinal=scoreclassification∗centerness,所低质量的bbox最后会通过NMS过滤掉。
3.4 为什么不同特征层的heas是共享的?
论文中提到共享 head 的原因有2点:(1) 可以减少运算量;(2)可以提高模型性能。

3.5 为何用FPN网络?
由 3.1节可知,FCOS对目标bbox内的每个像素点做预测,如果2个目标bbox重叠,那么这个像素点预测哪个目标呢?这就是 ambiguity 问题,解决思路是在不同尺度的特征层上分别预测这2个目标,这里其实有一个bug,如果2个目标的尺度是相同的,那就难以将目标分配到不同尺度的特征层上了,总之作者在这里使用FPN网络来处理,进行多尺度预测,分别预测大小不同的目标。
3.6 FPN网络需要注意哪些细节?
由于FCOS使用的是FPN网络,进行多尺度预测,需要注意如下实施细节:
-
每个特征层处理的正负样本是不同的,比如P3层用于预测小目标 (size范围[0, 64]) ,P4层用于预测较大目标 (size范围 [64, 128] ),每个特征层只负责回归满足如下条件的目标:
m i − 1 ≤ m a x ( l ∗ , r ∗ , t ∗ , b ∗ ) < m i m_{i-1}\leq max(l^*,r^*,t^*,b^*)mi−1≤max(l∗,r∗,t∗,b∗)<mi
式中: m i m_i mi 表示特征层 i i i 需要回归某个目标的最大距离,论文中的设置: m 2 m_2 m2, m 3 m_3 m3, m 4 m_4 m4, m 5 m_5 m5, m 6 m_6 m6 和 m 7 m_7 m7 取值分别为 0, 64, 128, 256, 512, 和 ∞。 -
每个 head 处理不同的特征尺度,所以 head 最后输出时进行的指数运算不是常规的 e x p ( x ) exp(x) exp(x),而是 e x p ( s i x ) exp(s_ix) exp(six),其中 s i s_i si 是可学习的缩放因子。
3.7 loss设计
FCOS 使用的代函数如下:
L ( { p x , y } , { t x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + λ N p o s ∑ x , y 1 c x , y ∗ > 0 L r e g ( t x , y , t x , y ∗ ) L(\{p_{x,y}\},\{t_{x,y}\})=\frac{1}{N_{pos}}\sum_{x,y}L_{cls}(p_{x,y},c^*_{x,y}) +\frac{\lambda}{N_{pos}}\sum_{x,y}1_{c^*_{x,y}>0}L_{reg}(t_{x,y},t^*_{x,y}) L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑1cx,y∗>0Lreg(tx,y,tx,y∗)
式中: L c l s L_{cls} Lcls 采用 focal loss; L r e g L_{reg} Lreg 采用 IOU loss; N p o s N_{pos} Npos 是正样本数量; λ \lambda λ 为 L r e g L_{reg} Lreg 的平衡权重。
4 FCOS 性能效果
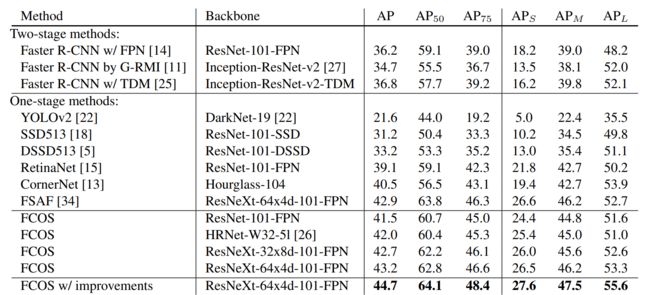
在COCO数据集上,FCOS 使用 ResNeXt-64x4d-101-FPN基础网络,改进后的 AP 值达到44.7%,高于RetinaNet 5.6个点,以及CornerNet 4.2个点。
所做出的改进Improvements是指:
- 将centerness分支移到regression分支上;
- 只将GT boxes的中心作为正样本;
- IOU loss 使用 GIOU;
- 对 bbox 的 l, r, t, b loss 计算时,使用FPN的不同步距做标准化
5 总结
FCOS 论文的主要贡献包括以下几点:
- FCOS 以很小的设计复杂度,取得了优于anchor-based 的 RetinaNet,YOLO 和 SSD 等检测网络的性能。
- FCOS 摆脱了anchor-based算法导致的复杂计算和超参调优。
- FCOS 还可以拓展应用到二阶段检测网络如 Faste R-CNN 的RPN网络,并且效果更好。
