笔记: Gradient Reversal Layer (unsupervised domain adaptation by backpropagation. ICML 2015)
paper: Ganin, Yaroslav, and Victor Lempitsky. “Unsupervised domain adaptation by backpropagation.” ICML 37. JMLR. org, 2015.
论文用domain adaptation算法解决目标域无标签的分类问题。文章假设source domain有数据 x x x,和label y y y, target domain 的数据没有label。
文章的思路是用三个网络进行domian adaptation : 分别是feature extractor G f G_f Gf, label predictor G y G_y Gy, domain classifier G d G_d Gd。

损失函数设置的目的是:
1)训练特征提取网络 G f G_f Gf、label分类网络 G y G_y Gy,使得source domain下的数据能够正确分类。
2)训练特征提取网络 G f G_f Gf以及domain分类网络 G d G_d Gd,使得特征提取网络将不同domain下的数据映射到一个空间并且数据分布相近难以区分,同时加强domain分类网络对提取网络得到的特征空间下不用domain数据的分类能力。(这是一种对抗,类似于GAN)
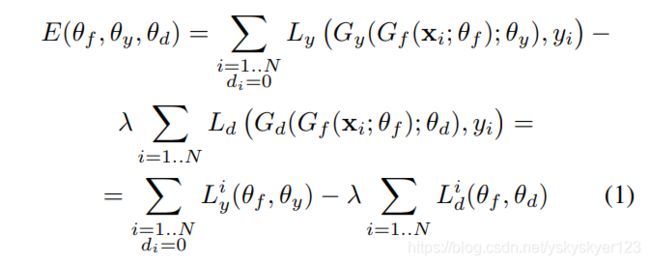
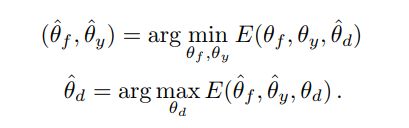
理想的domain分类器应该使得分类损失尽可能小,但因为 L d i L_d^i Ldi 那一项加了负系数,也就是使 E E E尽可能大。
同时 L d i L_d^i Ldi还与提取器 G f G_f Gf的参数有关,为了让 G f G_f Gf将两个域的数据映射到一个空间并且不易区分, G f G_f Gf的目标是让 L D L_D LD尽可能大,也就是 E E E尽可能小。

Gradient Reversal Layer (GRL)


文章用GRL,使得将minmax这种对抗学习整合为一个损失函数 E ~ \tilde{E} E~:
在前向传播时这个层不改变数据的值,相当于一个恒等映射。
而在反向传播时,在往回传到这一层时将导数乘以了一个负系数 − λ -\lambda −λ。
这样最小化 E ~ \tilde{E} E~会提高domain分类器的性能,也提高了特征提取器将两个域的数据映射到特征空间中相同分布的能力。
λ \lambda λ的设置用于权衡二者的学习效果。

知乎上相关链接:
https://www.zhihu.com/question/266710153
有人说:
没人觉得这个paper有问题吗?一个好的feature应该是让discriminator分辨不出它来自哪个domain,而不是让discriminator永远把它分到错误的那个domain。如果是后者的情况,说明其实domain discrepancy还是可以被捕捉到,所以达不到domain adaptation的效果。所以GRL训练的时候不能训练到完全收敛,否则结果会大幅度下降。。。
作者:匿名用户
链接:https://www.zhihu.com/question/266710153/answer/313295525
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我觉得文章的设置是合理的。这是因为文章的思路并不是要让domain分类器无法分类或者是错误的分类,相反文章是想让domian分类器尽可能正确地进行分类。是特征提取网络想让两个域的数据在特征空间上分布接近,以至于domain分类器不能正确分类。
另外,假如特征提取网络让两个域的数据在提取到的特征空间上具有discrepancy,并且domian分类网络此时进行了错误分类 (预测标签与Ground truth完全相反)。那么通过损失函数的学习,domain分类网络很快会正确分类。这是因为只要两个数据在特征空间上具有明显分布差异,在给出domian label的情况下,domain分类器应该就能很快学习如何正确分类。