自然语言处理总复习(十一)—— 信息检索
自然语言处理总复习(十一)—— 信息检索
- 一、概述
-
- 1. 概念
- 2. IR系统的体系结构
-
- (1)系统要素
- (2)Web搜索
- 3. IR的历史
- 4. IR的困难
- 5. IR相关领域
- 6. 主要的搜索引擎
- 7. 信息检索的应用
- 8. 国际国内会议
- 9. 重要工具
- 二、评价
-
- (一)评价的概述
-
- 1. 评价IR的原因
- 2. 评价IR系统的困难
- 3. 评价的对象
- 4. 如何评价效果?
- (二)基本指标 **`precision, recall, F-measure`**
-
- 1. 精准率(precision),召回率(recall)
- 2. F-measure(precision + recall)
- (三)TREC评测
-
- 1. TREC的查询方式
- 2. Pooling技术
- 3. 性能评价指标 —— MAP(算数平均精度)
- 4. 性能评价指标 —— 11-point AP(11点平均精度)
-
- - 计算实例
- 5. 其他评价指标
- 三、模型
-
- (一)模型概述
-
- 1. 模型的概念
- 2. 检索模型的核心问题
- 3. 模型分类
- 4. 信息检索的两种主要方式
-
- (1)特别(ad hoc retrieval)检索
- (2)过滤(filtering)
- (二)信息检索模型
-
- 1. 布尔模型(Boolean Model)
-
- 布尔模型的定义和描述
-
- (1)定义
- (2)举例
- (3)模型小结
- (4)问题
- 2. 向量空间模型(Vector Space Model, VSM)
-
- (1)索引项
- (2)文档集的表示方法
- (3)相似度计算
-
- (1)相似度函数 —— 内积
- (2)相似度函数 —— 余弦
- (4)文档和词项的权重计算方法
-
- a. 一些定义
- b. 计算公式 —— 典型计算公式
- c. 计算公式 —— 归一化计算公式
- (5)向量空间模型小结
-
- a. 模型优点
- b. 思考
- 3. 概率检索模型
- (三)信息检索模型总结
- (四)其他检索模型
-
- 1. 问题提出
- 2. 潜在语义索引模型(LSI)
- 四、Web-Spider
-
- (一)概述
- (二)Spider基本工作原理
-
- 1. 基本工作流程
- 2. 简单的Spider问题
- (三)Spider的关键问题和技术
-
- 1. 抓取策略
- 2. 分布式采集
- 3. 内容重复判别
- 4. 作弊页面、采集器陷阱处理
- 5. 礼貌性、新鲜度
-
- (1)爬行周期的确定
- (1)爬行器要遵守采集协议
- (四)网站运营者对Spider的态度
- (五)Web-Spider总结
- 五、相关反馈和查询扩展
-
- (一)问题背景
- (二)局部方法 —— 相关反馈
-
- 1. 基本思想
- 2. 相关反馈分类
-
- (1)显式相关反馈
- (2)隐式相关反馈
- (3)伪相关反馈或盲相关反馈
- 3. 相关反馈的特点
- 4. 核心概念 —— 质心
- 5. 相关反馈的实现方式 —— Rocchio算法
- 6. 反馈的处理方式
- 7. 相关反馈能够提高召回率的条件 —— 基于假设
- 8. 相关反馈的评价
- 9. 相关反馈存在的问题
- 10. 相关反馈 —— 新查询词的选择
-
- (1)基于局部聚类的方法
-
- —— 关联簇介绍
- (2)基于局部上下文分析的方法
- (三)全局方法 —— 查询拓展
-
- 1. 概念介绍
- 2. 查询扩展的类型
-
- 2-1. 人工构建的同(近)义词词典
- 2-2. 自动导出的同(近)义词词典
-
- 词典的自动构建方式:
- 3. 搜索引擎中的查询扩展
- (四)本讲小结
- 六、Web页面的评分机制(PageRank和HITS)
-
- (一)Web页面中的链接
- (二)PageRank
-
- 1. 随机冲浪模型的简化模型
-
- (1)PageRank公式1
- (2)PageRank公式2
-
- 例子
- 2. 锚文本
- 3. PageRank的一些数据结论
- (二)Hypertext Induced Topic Search (HITS)
- 七、文本处理
-
- (一)词法分析
-
- 1. 英文词法分析
- 2. 中文词法分析
- (二)停用词消除
- (三)英文词干还原
- (四)Term选择
- 八、文本索引
-
- (一)字符串匹配
-
- 相关方法
- (二)向前索引
- (三)倒排索引
-
- 倒排索引的更新
- 九、多媒体检索
-
- (一)多媒体检索概述
- (二)声音检索
- (三)图像检索
- (四)视频检索
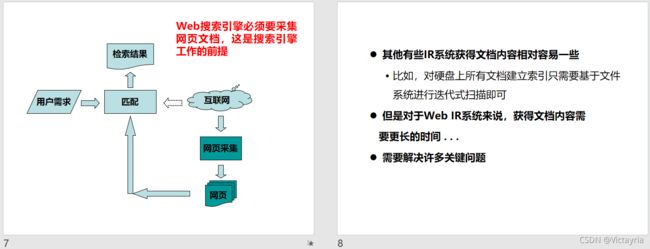
一、概述

1. 概念
信息检索: 从非结构化的文档集中找出与用户需求相关的信息。
和其它相关技术的区别:
和数据库的区别:数据库是结构化数据
和情报检索的区别:情报检索介绍如何利用信息检索工具
处理的对象:
- 非结构化数据
文本数据:新闻、科技论文等
网页:HTML、XML
多媒体数据:图像、图形、视频、音频 - 目前最主要的处理对象是互联网
典型的IR任务
- 给定
- 自然语言的文档集合
- 用户的提问(Query)-- 由用户需求而来
- 查找
- 和Query相关的经过排序(Rank)的文档子集
IR系统
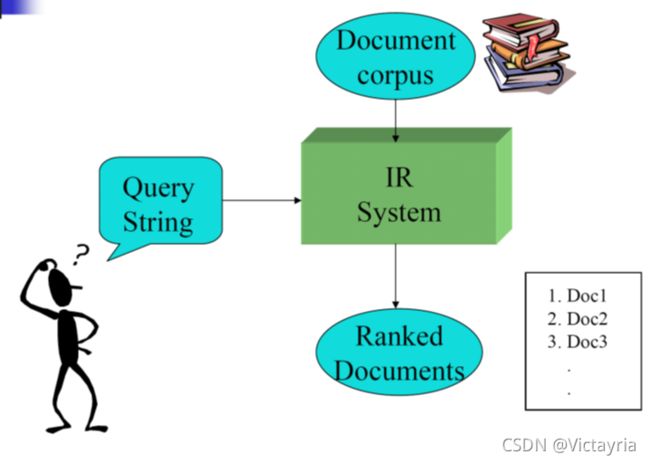
基于内容的图像查询:

2. IR系统的体系结构

(1)系统要素

(2)Web搜索

3. IR的历史



4. IR的困难




5. IR相关领域




6. 主要的搜索引擎
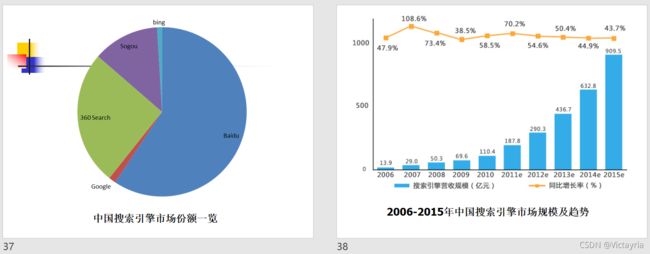
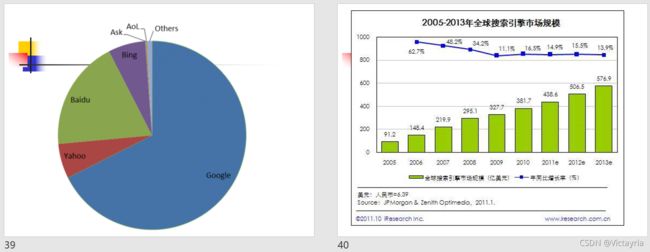
- 2003年底以前,中国搜索引擎市场的格局是:雅虎和Google都提供中文搜索服务,但没有正式进入中国。中国本土的搜索引擎服务商主要是百度、3721、中国搜索(慧聪搜索)。然而,这一切在2004年发生了彻底的变化。
- 2003年11月21日,雅虎中国收购3721公司。3721的搜索服务成为了YHAOO中国的重要组成,YHAOO正式进军中国搜索引擎服务市场。
- 2004年6月15日,Google进入中国市场
- 2004年6月21日,雅虎中国除了坚固其门户搜索、3721之外,推出了专门的中文搜索门户网站“一搜(www.yisou.com)”。
- 2004年7月1日,微软公司董事长比尔·盖茨在北京含蓄地表示,要加强MSN搜索开拓中国市场的力度。
- 2010,google撤退至香港

7. 信息检索的应用
8. 国际国内会议

9. 重要工具
二、评价
基本指标:precision、recall、F-measure
TREC评测
TREC的查询形式
Pooling技术
MAP(算术平均精度)
11-point AP(11点平均精度)
(一)评价的概述
1. 评价IR的原因
通过评估可以评价不同技术的优劣,不同因素对系统的影响,从而促进本领域研究水平的不断提高。
信息检索的目标: 在较少消耗情况下尽快、全面返回准确的结果。
2. 评价IR系统的困难

3. 评价的对象

4. 如何评价效果?

(二)基本指标 precision, recall, F-measure
1. 精准率(precision),召回率(recall)
precision = 检出的相关文档数/检出文档数,也称查准率
recall = 检出的相关文档数/相关文档总数,也称查全率
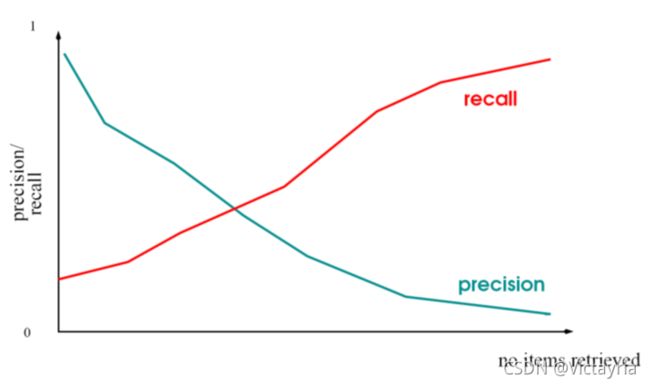
两个极端情况:
返回1篇,P=100%,但R极低;全部返回,R=1,但P极低。
一个例子:
查询Q,本应该有100篇相关文档,某个系统返回200篇文档,其中80篇是真正相关的文档
recall = 80/100 = 0.8
precision = 80/200 = 0.4
结论:召回率较高但是精准率较低
召回率和精准率的关系:

一个Query的P-R曲线:
2. F-measure(precision + recall)
F m e a s u r e = { 0 , P = R = 0 2 P R P + R , P 和 R 不 同 时 为 0 F_{measure} = \begin{cases} 0, &P =R=0 \\ \dfrac{2PR}{P+R}, &P和R不同时为0 \end{cases} Fmeasure=⎩⎨⎧0,P+R2PR,P=R=0P和R不同时为0
(三)TREC评测
1. TREC的查询方式

2. Pooling技术

3. 性能评价指标 —— MAP(算数平均精度)


4. 性能评价指标 —— 11-point AP(11点平均精度)

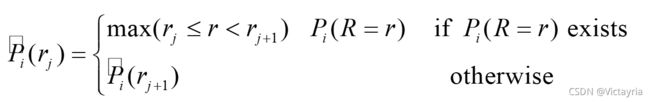
- 计算实例
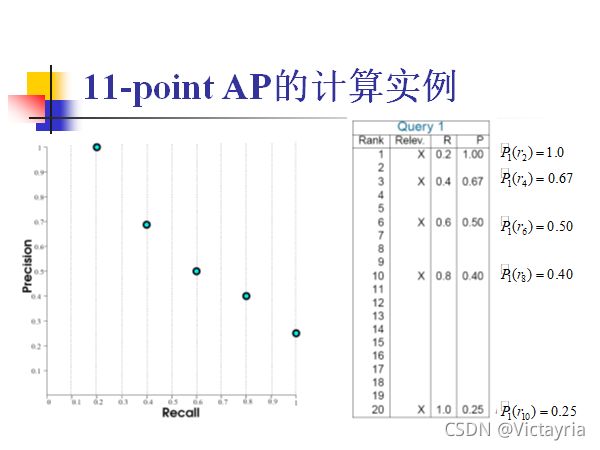
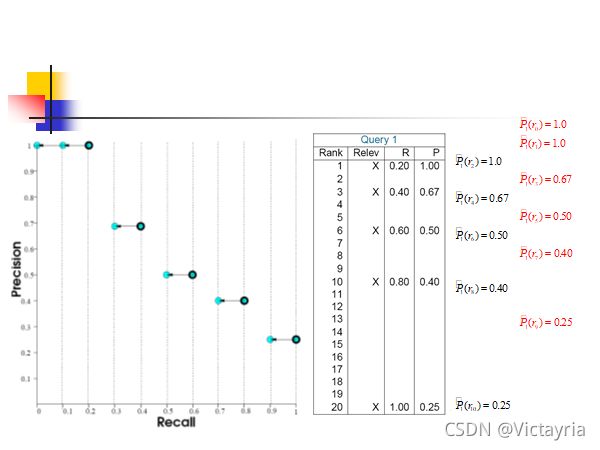

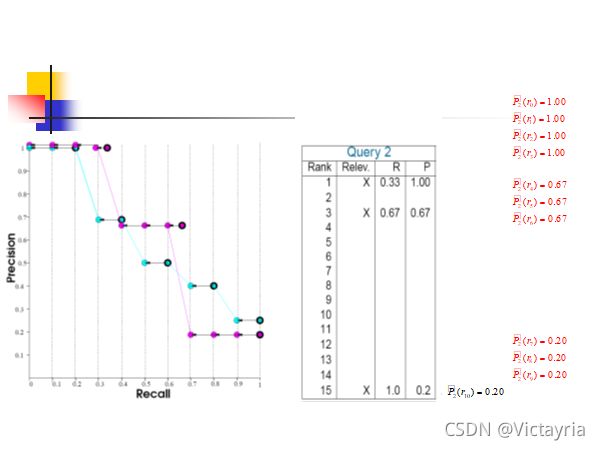
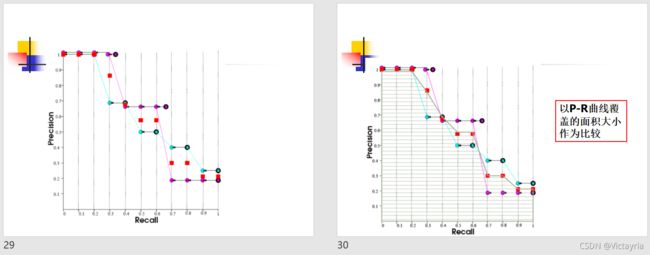
5. 其他评价指标
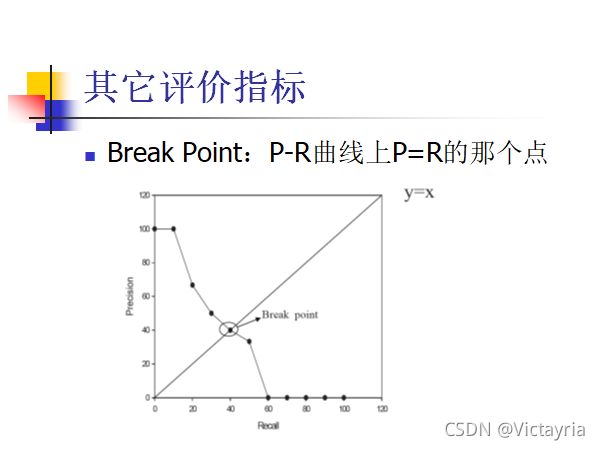
三、模型
(一)模型概述
1. 模型的概念
- 模型是采用数学工具,对现实世界某种事物运动、或问题的抽象描述
- 面对相同的输入,模型的输出应能够无限地逼近现实世界的输出
信息检索的模型,就是运用数学的语言和工具,对信息检索系统中的信息及其处理过程加以描述和抽象,表述为某种数学公式,再经过演绎、推断、解释和实际检验,反过来指导信息检索实践。
信息检索模型的形式化表示
[D, Q, F, R(qi, dj)]
D: 是一个文档集合,通常由文档逻辑视图来表示。可以是一组索引词或关键词。既可以自动提取,也可以是由人主观指定。
Q:是一个查询集合,用户任务的表达
目前主要是关键词
也可能是自然语言句子、文档的样本、图像、草图
F:是一个框架,用以构建文档、查询表示以及它们之间关系的模型 检索系统的理论框架,包括预处理、中间处理(分类、聚类、索引)
文档和查询的表示方法
R(qi, dj):是一个排序函数,它给查询qi和文档 dj 之间的相似度赋予一个排序值
如目前往往按与关键词匹配的数量和Google的pageRank的值。
2. 检索模型的核心问题
- 用户的需求表示:包括用户查询信息的获取与表示。
- 文档的表示:文档内容的识别与表示。
- 相似匹配及排序:用户需求表示与文档表示之间的查询机制,以及它们之间相关性排序的准则和函数表示。
- 反馈修正:对检索结果进行优化。
3. 模型分类
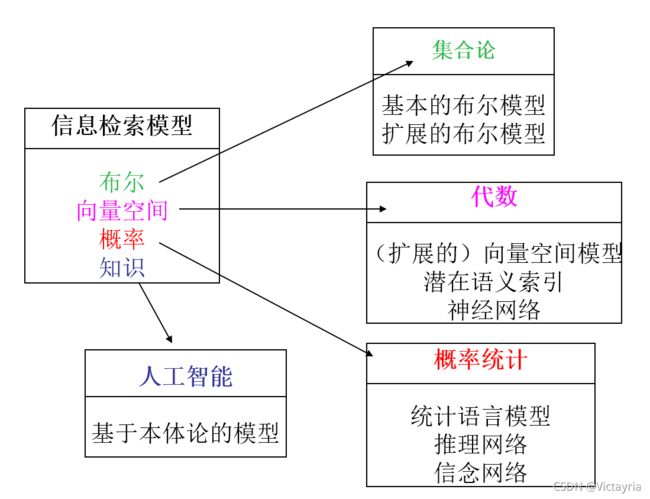
4. 信息检索的两种主要方式
(1)特别(ad hoc retrieval)检索
用户可以不断地提出新的检索需求或新组合,检索系统中的文献不变 ;
比如:Google, Baidu, bing
(2)过滤(filtering)
用户的检索需求描述是固定不变的,当得到新的文档后,把与用户需求相关的文档留下,并分类和排序后提交给用户。
比如:股票,新闻,天气,航班
(二)信息检索模型

1. 布尔模型(Boolean Model)
一种简单的检索模型,它建立在经典的集合论和布尔代数的基础上。
遵循的基本规则:
每个索引词在文档或查询中只有两种状态:出现或不出现,对应权值为1或0。
查询: 由三种布尔逻辑运算符 and, or, not 连接索引词组成的布尔表达式。
匹配: 一个文档当且仅当它能够满足布尔查询式时,才将其检索出来。
布尔模型的定义和描述
(1)定义


(2)举例

(3)模型小结

(4)问题

2. 向量空间模型(Vector Space Model, VSM)
(1)索引项
若干独立的词项被选作索引项(index terms) or 词表vocabulary.
索引项代表了一个应用中的重要词项
计算机科学图书馆中的索引项应该是哪些呢?
索引项的假设:
这些索引项是不相关的 (或者说是正交的) ,形成一个向量空间vector space.
实际上,这些词项是相互关联的
当你在一个文档中看到“计算机”, 非常有可能同时看到“科学”
当你在一个文档中看到“计算机”, 有中等的可能性同时看到“商务”
当你在一个文档中看到“商务”,只有很少的机会同时看到“科学”
索引项到向量:
n 个索引项构成 n 维空间
一个文档或查询式可以表示为 n 个元素的线性组合
2个索引项构成一个二维空间,一个文档可能包含0, 1 或2个索引项
di = (0, 0) (一个索引项也不包含)
dj = (0, 0.7) (包含其中一个索引项)
dk = (1, 2) (包含两个索引项)
类似的,3个索引项构成一个三维空间
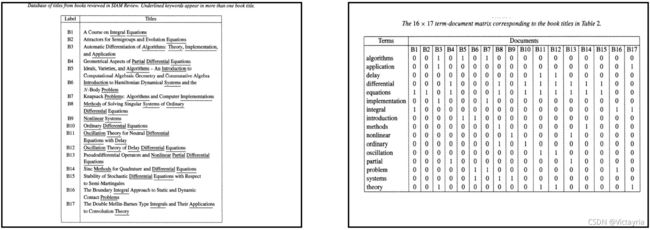
(2)文档集的表示方法
![]()


(3)相似度计算
相似度概念: 是一个函数,它给出两个向量之间的相似程度。
相似度存在的地方:
- 文档 – 文档
- 查询式 – 查询式
- 查询式 – 文档
- 可以根据预定的重要程度对检索出来的文档进行排序
- 通过强制设定某个阈值,控制被检索出来的文档的数量
- 检索结果可以被用于相关反馈中,以便对原始的查询式进行修正。(例如:将文档向量和查询式向量进行结合)
注:查询式和文档都是向量
(1)相似度函数 —— 内积


内积的属性:
- 内积值没有界限
- 对长文档有利
- 内积用于衡量有多少词项匹配成功,而不计算有多少词项匹配失败。
- 长文档包含大量独立词项,每个词项均多次出现,因此一般而言,和查询式中的词项匹配成功的可能性就会比短文档大。
(2)相似度函数 —— 余弦

(4)文档和词项的权重计算方法
a. 一些定义
文档: tf
文档集:idf
t f i j = 词 项 j 在 文 档 i 中 的 频 率 d f j = 词 项 j 的 文 档 频 率 = 包 含 词 项 j 的 文 档 数 量 i d f j = 词 项 j 的 反 文 档 频 率 = l o g 2 ( N / d f j ) ( 其 中 , N 为 文 档 集 中 文 档 总 数 , 反 文 档 频 率 用 词 项 区 别 文 档 ) tf_{ij} = 词项j在文档i中的频率 \\ df_{j} = 词项j的文档频率 = 包含词项j的文档数量 \\ idf_{j} = 词项j的反文档频率 = log_2(N/df_j) \\ (其中,N为文档集中文档总数,\\反文档频率用词项区别文档) tfij=词项j在文档i中的频率dfj=词项j的文档频率=包含词项j的文档数量idfj=词项j的反文档频率=log2(N/dfj)(其中,N为文档集中文档总数,反文档频率用词项区别文档)
b. 计算公式 —— 典型计算公式

c. 计算公式 —— 归一化计算公式
w i j = ( t f i j / max l { t f l j } ) ⋅ i d f j w_{ij} = (tf_{ij}/ \mathop{\max}_l\{tf_{lj}\}) \cdot idf_j wij=(tfij/maxl{tflj})⋅idfj
其中 max l { t f l j } \mathop{\max}_l\{tf_{lj}\} maxl{tflj}表示文档 j j j中最高频率的词频的频率。
(5)向量空间模型小结
a. 模型优点
- 索引项权重的算法提高了检索的性能
- 部分匹配的策略使得检索的结果文档集更接近用户的检索需求
- 可以根据结果文档对于查询串的相关度通过Cosine Ranking等公式对结果文档进行排序
b. 思考
- 如何判断两程序之间是否存在抄袭?
思路:
比如对每段程序建立一个<函数个数,变量个数,常量个数,…>向量,然后进行向量相似度计算。如果相似度大于某个阈值,则认为可能抄袭
3. 概率检索模型







(三)信息检索模型总结
- 信息检索模型是信息检索的核心。
- 主要问题:
- 文档的表示
- 查询的表示
- 匹配的数量
- 三种模型的优缺点比较
(四)其他检索模型
1. 问题提出

我们希望找到一种方法,能反映术语之间内在的相关性
2. 潜在语义索引模型(LSI)





四、Web-Spider
(一)概述


(二)Spider基本工作原理
1. 基本工作流程


2. 简单的Spider问题
- 规模问题: 必须要分布式处理
- 重复网页:必须要集成重复检测功能
- 作弊网页和采集器陷阱:必须要集成作弊网页检测功能
- 采集器陷阱:使得爬行器陷入无限循环出不来
- 礼貌性问题: 对同一网站的访问按遵照协议规定,并且访问的间隔必须要足够
- 新鲜度(freshness)问题:必须要定期更新或者重采
- 由于Web的规模巨大,我们只能对一个小的网页子集频繁重采。
- 同样,这也存在一个选择或者优先级问题
(三)Spider的关键问题和技术
1. 抓取策略
目标: 查得全
理想情况:遍历互联网上所有的网页
遍历方式: 深度优先、广度优先
遍历的问题: 要抓取互联网上所有的网页几乎是不可能的
原因:
(1)技术瓶颈
- 无法遍历所有网页,许多网页无法从其他网页的链接中找
(2)存储技术和处理技术的问题
- 如果按照每个页面的平均大小为2M计算,xx亿网页的容量是多少?
- 即使能够存储,下载也存在问题(时间开销太大)。
- 同时,由于数据量太大,在提供搜索时也会有效率方面的影响。
解决方式:设置访问层数

2. 分布式采集
如果要在一个月内采集20,000,000,000个页面. . .
. . . 那么必须要在一秒内大概采集 8000个网页!
由于我们采集的网页可能重复、不可下载或者是作弊网
页,实际上可能需要更快的采集速度才能达到上述指标
运行多个采集线程,这些线程可以分布在不同节点上
这些节点往往在地理上分散在不同位置
将采集的主机分配到不同节点上
3. 内容重复判别
- 对每个抓取的页面,判断它是否已在索引当中
- 可以采用文档指纹或者shingle的方法判别
- 忽略那些已经在索引中的重复页面
4. 作弊页面、采集器陷阱处理
- 一些恶意的服务器可以产生无穷的链接网页序列
- 一些复杂的采集器陷阱产生的页面不能简单地判断为动态页面
作弊方法:
背景文字、超小号文字
链接重定向
故意制作大量的链接指向一个网址
使用程序机在web2.0等网站大量的群发指向您某网站的链接
通过扫描网站漏洞在高质量站点中加入隐藏链接
不具推荐意义的交换链接等等
5. 礼貌性、新鲜度
- 礼貌性: 不要非常频繁第访问某个Web服务器(比如,可以在两次服务器访问之间设置一个时间间隔)
- 新鲜度: 对某些网站的采集频率(如新闻网站)要高于其他网站(实现上述功能并不容易,一个简单的优先级队列难以成功)
(1)爬行周期的确定

(1)爬行器要遵守采集协议


(四)网站运营者对Spider的态度

(五)Web-Spider总结
任意一个Spider应该做到:
(1)能够进行分布式处理
(2)支持规模的扩展:能够通过增加机器支持更高的采集速度
(3)优先采集高质量网页
(4)能够持续运行:不断进行更新
五、相关反馈和查询扩展
(一)问题背景
-
用户有明确的查询目的,但是用户不知道如何构造好的查询,因此,初始查询往往不能很好地表达其查询需求
用户没有经验
查询的表达方式很多
对检索系统不熟悉
对目标文档分布不熟悉 -
用户不知道要具体查询什么,需要查看结果以后才逐渐细化
优化目标:提高召回率
提高召回率的方法:
- 局部方法:对用户查询进行局部的即时的分析 —— 相关反馈
- 全局方法:进行一次性的全局分析(比如分析整个文档集)来产生同/近义词词典 —— 利用该词典进行查询扩展
(二)局部方法 —— 相关反馈
1. 基本思想
- 用户提交一个(简短的)查询,搜索引擎返回一系列文档
- 用户将部分返回文档标记为相关的,将部分文档标记为不相关的
- 搜索引擎根据标记结果计算得到信息需求的一个新查询表示。
- 搜索引擎对新查询进行处理,返回新结果,新结果可望(理想上说)有更高的召回率
2. 相关反馈分类
(1)显式相关反馈
概念: 用户相关反馈或显式相关反馈(User Feedback or Explicit Feedback): 用户显式参加交互过程
(2)隐式相关反馈
概念: 系统跟踪用户的行为来推测返回文档的相关性,从而进行反馈。

用户行为种类:
-
鼠标键盘操作
点击链接、加入收藏夹、拷贝粘贴、停留、翻页等等 -
用户眼球动作
Eye tracking可以跟踪用户的眼球动作
拉近、拉远、瞟、凝视、往某个方向转
隐式相关反馈的优缺点:
(1)优点
- 不需要用户显式参与,减轻用户负担
- 用户行为某种程度上反映用户的兴趣,具有可行性
(2)缺点
- 对行为分析有较高要求
- 准确度不一定能保证
- 某些情况下需要增加额外设备
(3)伪相关反馈或盲相关反馈
概念: 没有用户参与,系统直接假设返回文档的前k篇是相关的,然后进行反馈。

伪相关反馈优缺点小结:
(1)优点
- 不用考虑用户的因素,处理简单
- 很多实验也取得了较好效果
(2)缺点
- 没有通过用户判断,所以准确率难以保证
- 不是所有的查询都会提高效果
3. 相关反馈的特点
- 相关反馈可以循环若干次
- 不仅仅局限于文档
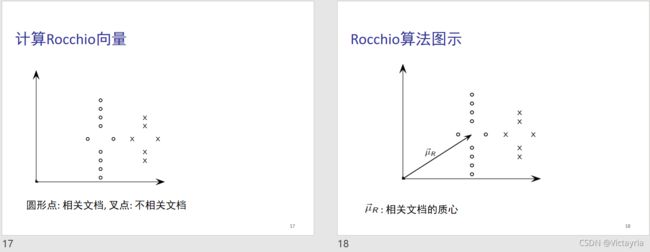
4. 核心概念 —— 质心
文档质心的计算:

5. 相关反馈的实现方式 —— Rocchio算法






6. 反馈的处理方式

7. 相关反馈能够提高召回率的条件 —— 基于假设


8. 相关反馈的评价

9. 相关反馈存在的问题

10. 相关反馈 —— 新查询词的选择
根据相关反馈修改查询条件的方法,判断哪些词应该加入到查询条件中。
(1)基于局部聚类的方法

基于簇的查询扩展 —— 簇的相关概念介绍:
簇中的不同term互称为邻居(neighborhood),或者搜索同义项(searchonym),有别于语法意义上的同义词。
—— 关联簇介绍


局部聚类的缺点:
计算的是 q 中每个 term和所有 term 之间的相似度,而不是计算 q 和所有 term 的相似度。
(2)基于局部上下文分析的方法
核心思想:
在局部文档中计算出和查询 q 最相近的 term 进行扩展。
三个步骤:

q和c的相似度计算:

LCA的使用:

(三)全局方法 —— 查询拓展
1. 概念介绍
我们使用 “全局查询扩展” 来指那些 “查询重构(query reformulation)的全局方法”。
主要使用的信息: 同义词或近义词
在全局扩展查询中,查询基于一些全局的资源进行修改,这些资源与查询无关。
同义词或近义词词典的构建方法: 【人工构建】 和 【自动构建】
基于基于同(近)义词词典的查询扩展:

2. 查询扩展的类型
2-1. 人工构建的同(近)义词词典
人工编辑人员维护的词典
2-2. 自动导出的同(近)义词词典
比如,基于词语的共现统计信息
词典的自动构建方式:
通过分析文档集中的词项分布来自动生成同(近)义词词典
基本想法:计算词语之间的【相似度】
- 相似度的衡量:

- 相似度的定义
对于所有N篇文档,考虑其矩阵表示
文档的矩阵表示

N:文档数目
t:整个文档集中的term数目
t j t_j tj :文档 d_j 中的不同 term 数目
i t f j = l o g t t j itf_j = log \dfrac{t}{t_j} itfj=logtjt,为文档 d j d_j dj的逆term频率
每个 w i , j w_{i,j} wi,j表示的是 [ k i , d j ] [k_i, d_j] [ki,dj]对应的权重(term k i k_i ki在文档 d j d_j dj中的权重);
f i , j f_{i,j} fi,j为term k i k_i ki在文档 d j d_j dj中的频度
term之间的相似度计算
将上述矩阵的地 i i i行看成term k i k_i ki的一个向量表示 k i ⃗ \vec{k_i} ki
计算 term k u k_u ku和 k v k_v kv之间的相似度,可以采用内积计算方法,至此,可以得到term相似度矩阵。
至此,可以得到term相似度矩阵。其中的u行v列为:
c u , v = k u ⃗ ⋅ k v ⃗ = ∑ ∀ d j w u , j × w v , j c_{u,v} = \vec{k_u} \cdot \vec{k_v} = \sum_{\forall d_j}w_{u,j} \times w_{v,j} cu,v=ku⋅kv=∀dj∑wu,j×wv,j
查询q和term之间的相似度计算
将q向量化,对于q总的每个term k i k_i ki,可以利用前面计算 [ k i , d j ] [k_i, d_j] [ki,dj]权重的公式计算权重 w i , q w_{i,q} wi,q,从而得到q的向两边表示:
q ⃗ = ∑ ∀ k i ∈ q w i , q k i ⃗ \vec{q} = \sum_{\forall k_i \in q}w_{i,q}\vec{k_i} q=∑∀ki∈qwi,qki
q和任意term k v k_v kv之间的相似度 sim :
s i m ( q , k v ) = q ⃗ ⋅ k v ⃗ = ∑ k u ∈ q w u , q × k u ⋅ k v = ∑ k u ∈ q w u , q × c u , v sim(q,k_v) = \vec{q} \cdot \vec{k_v} \\ =\sum_{k_u \in q}w_{u,q} \times k_u \cdot k_v \\ =\sum_{k_u\in q} w_{u,q} \times c_{u,v} sim(q,kv)=q⋅kv=ku∈q∑wu,q×ku⋅kv=ku∈q∑wu,q×cu,v
利用 sim 进行查询扩展
- 选择sim值最高的r个term
- 加入到原始查询中新查询q’
- 新加入的term k v k_v kv的权重设置为:
w v , q ′ = s i m ( q , k v ) ∑ k u ∈ q w u , q w_{v,q'} = \frac{sim(q,k_v)}{\sum_{k_u\in q}w_{u,q}} wv,q′=∑ku∈qwu,qsim(q,kv)
3. 搜索引擎中的查询扩展
搜索引擎进行查询扩展主要依赖的资源: 查询日志(query log)

(四)本讲小结
- 交互式相关反馈:
在初始检索结果的基础上,通过用户交互指定哪些文档相关或不相关,然后改进检索的结果
-
最著名的相关反馈算法:Rocchio算法
-
查询扩展:
通过在查询中加入同义词或者相关的词项来提高检索结果
- 相关词项的来源:人工编辑的同义词词典,自动构造的同义词词典,查询日志等
六、Web页面的评分机制(PageRank和HITS)
(一)Web页面中的链接

(二)PageRank
1. 随机冲浪模型的简化模型
前提假设:不返回已经浏览过的页面
模型:给定一个随机页面,按照页面提供的链接向前浏览的概率为q,在浏览厌烦之后随机跳到其它页面的概率为1-q
PageRank值:浏览每个页面的概率分配
(1)PageRank公式1


(2)PageRank公式2
r ⃗ : = ( q A + 1 − q N I ) r ⃗ \vec{r} := (qA + \frac{1-q}{N}I)\vec{r} r:=(qA+N1−qI)r
例子
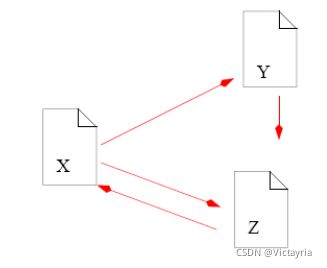
(1)定义链接矩阵 A A A
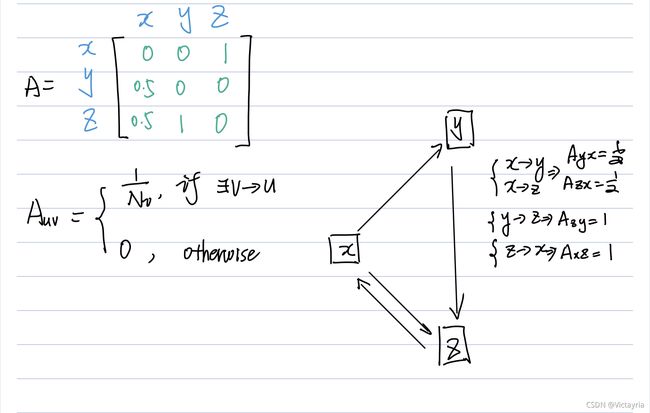
(2)定义迭代过程
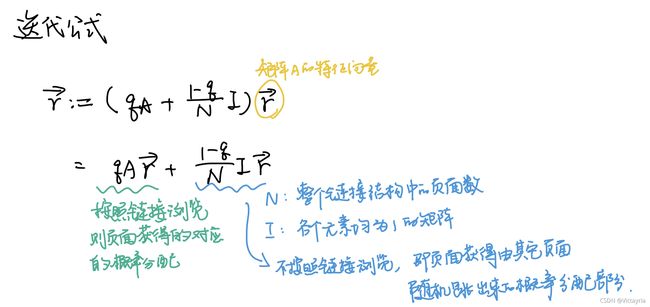
(3)公式2和公式1的对比
公式1:将从某一个页面链接到的其他页面的页面PageRank都当成了1;
公式2:还原了被链接页面的PageRank值;
(4)求解


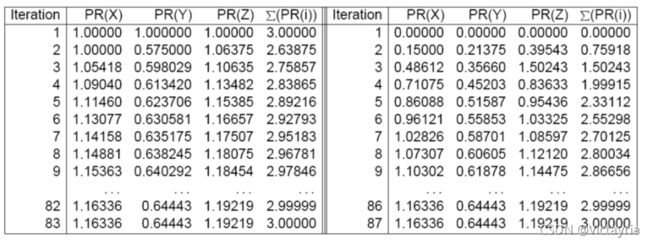
2. 锚文本



PageRank背后的假设:
- Web上的链接是网页质量的标志 —— 链出网页的作者认为链向的网页具有很高的质量
- 故意制作大量的链接指向一个网址
- 链接重定向
- 使用程序机在web2.0等网站大量的群发指向您网站的链接
- 通过扫描网站漏洞在高质量站点中加入隐藏链接
- 不具推荐意义的交换链接等等
-
锚文本能够描述链向网页的内容
Google炸弹
指的是这样一种情况:
(1)数目众多的网页链接指向某一个URL
(2)这些链接都使用特定锚文本做链接文字
(3)被链接的URL中一般并不包含这个锚文本,内容与
其也基本无关
(4)达到效果就是这个被链接的URL在这个特定锚文本
下,搜索引擎排名急剧上升,很多时候都排到第一

3. PageRank的一些数据结论

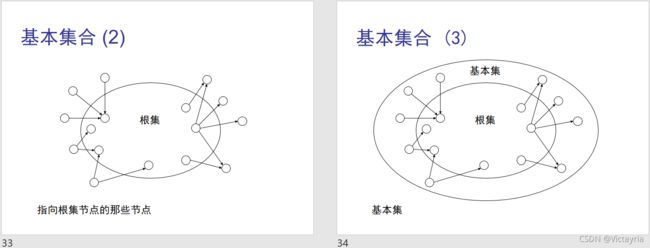
(二)Hypertext Induced Topic Search (HITS)
目标: 找到有关某个特定主题的权威页面(authorities)
思想: 在Web上存在 hubs 和 authorities页面,它们彼此之间是互相增强的关系





七、文本处理
文本的表示: 不论是文档还是查询,都要表示成索引词(index term)的某种形式(布尔表达式、向量、概率等)
问题:
抽取什么样的词语作为 index term ?
如何索引?
(一)词法分析
功能:将文档的字符串序列变成词序列
- 英文词法分析:通过空格分隔 —— 容易
- 中文词法分析:书写时通常没有空格,需要分词
1. 英文词法分析

2. 中文词法分析



(二)停用词消除

(三)英文词干还原





(四)Term选择
选择更有意义的词或者概念来表示文档
(1)选择名词
(2)选择短语
(3)选择一组组的名词
(每个组内的名词比较相似,一个组可以称为一个概念)
八、文本索引
检索效率问题:
- 检索面对的搜索基本问题:给定一个查询串,在文档集合里面搜索出现这些查询串的文档。
- 解决该问题的效率将影响检索的效率。
(一)字符串匹配
定义: 给定一个子串q,在字符串d中查找q所有出现的位置(有时只要判断是否出现即可)。q的长度假设为m,d的长度假设为n。
- 搜索问题转化为对每个查询q,在文档集合中搜索出现查询q的文档。
- 当文档集合规模不大时,通过字符串定位可以实现检索。如小型网站的全文检索。
优点:
方法简单易行
很方便地支持文档更新(增加和删除)
缺点:
效率不高
相关方法


(二)向前索引
问题提出: 对文本进行预处理,防止对一篇文档直接进行费时费力的扫描。
核心思想: 将每篇文档表示成 DocID 及其文本内容组成的类向量模式。

仍然是依次扫描每个文档,但是对于一个字符串的多次出现不需要一一扫描,而且对同一文档内的字符串查找可以采用二分查找的方式,加快匹配过程。也就是说通过预处理的方式加快对每篇文档的匹配速度。
(三)倒排索引
问题提出: 使用前向索引,仍然需要一篇篇扫描每个文档,如果文档数目较多,那么就非常费时费力。【有没有一种方法能够直接从查询词定位到文档?—— 倒排索引】


倒排索引的更新

九、多媒体检索
(一)多媒体检索概述






(二)声音检索


(三)图像检索



(四)视频检索

