图像特征提取(VGG和Resnet特征提取卷积过程详解)
图像特征提取(VGG和Resnet算法卷积过程详解)
第一章 图像特征提取认知
1.1常见算法原理和性能
众所周知,计算机不认识图像,只认识数字。为了使计算机能够“理解”图像,从而具有真正意义上的“视觉”,本章我们将研究如何从图像中提取有用的数据或信息,得到图像的“非图像” 的表示或描述,如数值、向量和符号等。这一过程就是特征提取,而提取出来的这些“非图像”的表示或描述就是特征。有了这些数值或向量形式的特征我们就可以通过训练过程教会计算机如何懂得这些特征, 从而使计算机具有识别图像的本领。

1.2 什么是图像特征
特征是某一类对象区别于其他类对象的相应(本质)特点或特性, 或是这些特点和特性的集合。特征是通过测量或处理能够抽取的数据。对于图像而言, 每一幅图像都具有能够区别于其他类图像的自身特征,有些是可以直观地感受到的自然特征,如亮度、边缘、纹理和色彩等;有些则是需要通过变换或处理才能得到的, 如矩、直方图以及主成份等。
1.3 特征向量及其几何解释
我们常常将某一类对象的多个或多种特性组合在一起, 形成一个特征向量来代表该类对象,如果只有单个数值特征,则特征向量为一个一维向量,如果是n个特性的组合,则为一个n维特征向量。该类特征向量常常作为识别系统的输入。实际上,一个n维特征就是位于n维空间中的点,而识别分类的任务就是找到对这个n维空间的一种划分。例如要区分3种不同的鸢(yuān)尾属植物,可以选择其花瓣长度和花瓣宽度作为特征,这样就以1个2维特征代表1个植物对象,比如(5.1,3.5).如果再加上萼片长度和萼片宽度, 则每个鸢尾属植物对象由一个4维特征向置表示, 如(5.1, 3.5.1.4, 0.2)。




1.4 特征提取的一般原则
图像识别实际上是一个分类的过程,为了识别出某图像所属的类别,**我们需要将它与其他不同类别的图像区分开来。这就要求选取的特征不仅要能够很好地描述图像, 更重要的是还要能够很好地区分不同类别的图像。**我们希望选择那些在同类图像之间差异较小(较小的类内距),在不同类别的图像之间差异较大(较大的类间距)的图像特征, 我们称之为最具有区分能力(most discriminative)的特征。此外, 在特征提取中先验知识扮演着重要的角色, 如何依靠先验知识来帮助我们选择特征也是后面将持续关注的问题。
第二章 常见特征提取算法
2.1 常见图像特征提取的算法
SIFT
HOG
ORB
HAAR
Deep Learning(神经网络特征提取)
SIFT(尺度不变特征变换)
SIFT特征提取的实质,在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出、不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
HOG(方向梯度直方图)
HOG特征提取的实质,通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
SIFT和HOG的比较
共同点:都是基于图像中梯度方向直方图的特征提取方法
不同点:SIFT 特征通常与使用SIFT检测器得到的兴趣点一起使用。这些兴趣点与一个特定的方向和尺度相关联。通常是在对一个图像中的方形区域通过相应的方向和尺度变换后,再计算该区域的SIFT特征。HOG特征的单元大小较小,故可以保留一定的空间分辨率,同时归一化操作使该特征对局部对比度变化不敏感。
ORB
ORB特征描述算法的运行时间远优于SIFT算法,可用于实时性特征检测。ORB特征基于FAST角点的特征点检测与描述技术,具有尺度与旋转不变性,同时对噪声及透视仿射也具有不变性,良好的性能使得用ORB在进行特征描述时的应用场景十分广泛。
HAAR
人脸检测最为经典的算法Haar-like特征+Adaboost。这是最为常用的物体检测的方法(最初用于人脸检测),也是用的最多的方法。
训练过程: 输入图像->图像预处理->提取特征->训练分类器(二分类)->得到训练好的模型;
测试过程:输入图像->图像预处理->提取特征->导入模型->二分类(是不是所要检测的物体)。
第三章 深度学习提取特征
3.1 神经网络提取图像特征
小块的图形可以由基本edge构成,更结构化,更复杂的,就需要更高层次的特征表示,高层表达由低层表达的组合而成。如图所示:这就是神经网络每层提取到的特征。由于是通过神经网络自动学习到了,因此也是无监督的特征学习过程。直观上说,就是找到make sense的小patch再将其进行combine,就得到了上一层的feature,递归地向上learning feature。在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就会completely different了。

3.2 认识VGG网络和Resnet网络
VGGNet:2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的)和定位项目的第一名。由此可见,VGGNet的效果非常的好。VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好
Resnet: ResNet获得2015年ImageNet比赛的冠军,主要创新点在于设计了一种使用了skip connection的残差结构,使得网络达到很深的层次,同时提升了性能。神经网络随着层数的增加,显示出退化问题,即深层次的网络反而不如稍浅层次的网络性能;而且这并非是过拟合导致的,因为在训练集上就显示出退化差距。所以,一种直觉是:如果神经网络能够轻松的实现层次间的等效映射,即一个block的输入等于这个block的输出,那么更深层次的网络也就不应该出现比浅层网络性能更差的退化问题。所以何博士等设计了一种skip connection结构,使得网络具有更强的identity mapping的能力,从而拓展了网络的深度,同时也提升了网络的性能。
3.3 VGG16
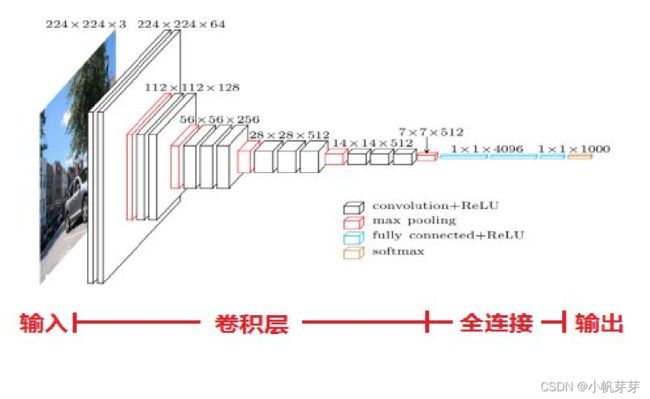
VGG16构成:13个卷积层,5个池化层,3个全连接层组成。13+3 = 16,所以叫VGG16。
5个池化层没有计入其中。是不做运算的,为什么后面不做运算,在后面章节做解释。一张图经过多层网络提取得到的特征。
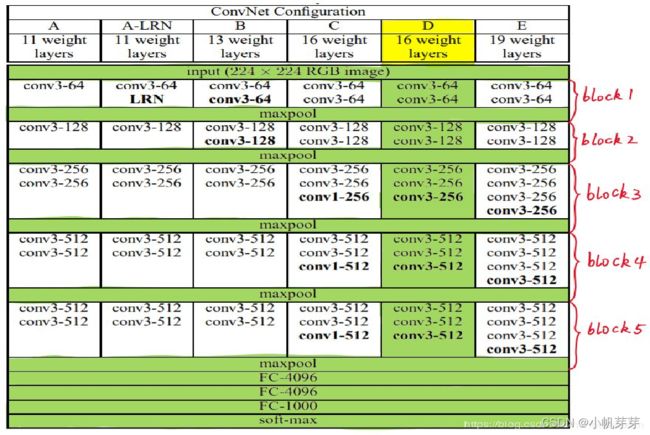
3.4 VGG网络系列
3.5.1 卷积层怎么工作的
卷积立体图解
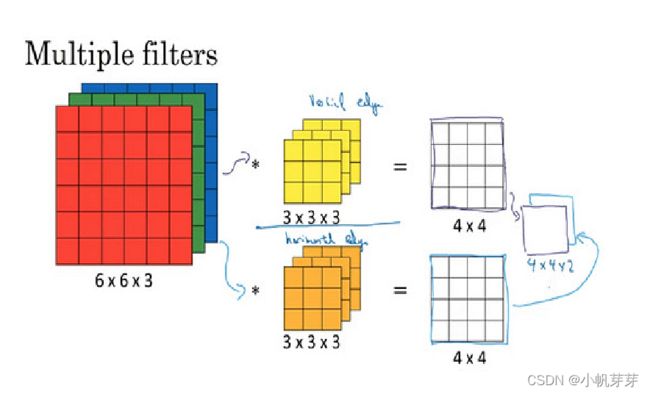
一副彩色图像有 RGB 三个通道,一个 (6×6) 大小的图像维度是(6×6×3),这里的 3 便对应三个通道(颜色RGB),对这样的图像进行卷积运算时,用到的过滤器的通道数必须与其一致,比如这里可以使用 一个 维度为 (3×3×3) 的过滤器,得到卷积后的图像维度为 (4×4),最后输出的维度为(4×4×2)。如果使用 (y) 个该维度的过滤器,那么卷积后的图像维度应为 (4×4×y)
3.5.2 卷积过程平面图解
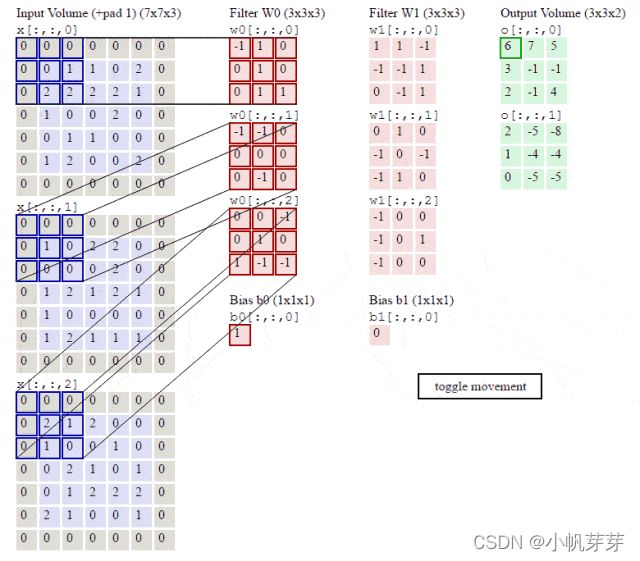
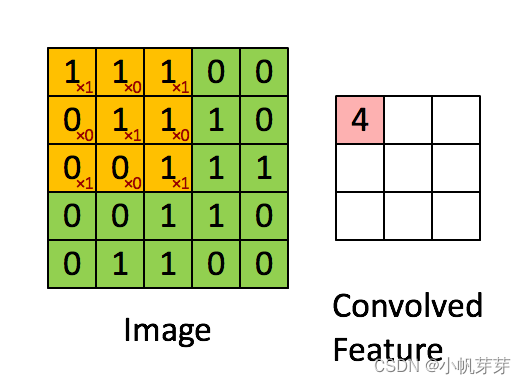
卷积层计算:矩阵采用点乘方式,卷积核与滑动到的位置的每个元素与输入的矩阵单元相乘,每次乘积得到的结果后相加作为输出的特征矩阵的一个单元。
前后卷积形状大小变化:

3.5.3 池化层是怎么运作的
池化层通常有两种方式,第一种是最大池化,第二种是平均池化,在VGG16中采用的是最大池化,池化层是不参与计算的,池化层作用是降维,每一移动一个步长取最大值也就是为什么VGG16 是等于13 + 3 ,而不是13 + 3 + 5。在VGG16采用的是2x2 的矩阵,移动步长为2.
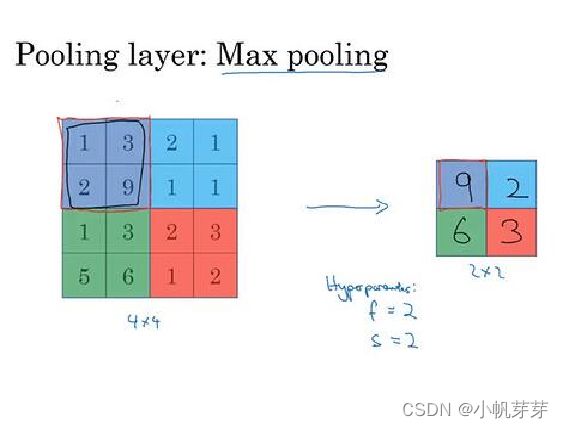
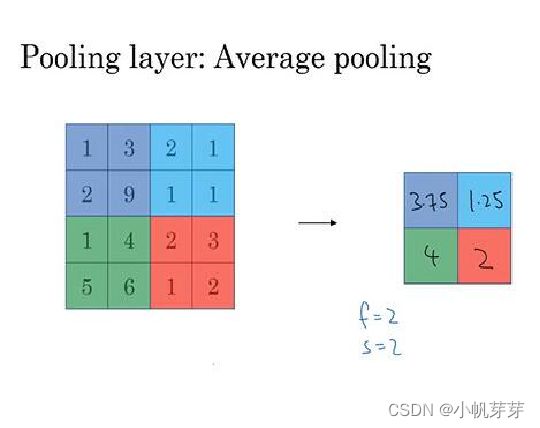
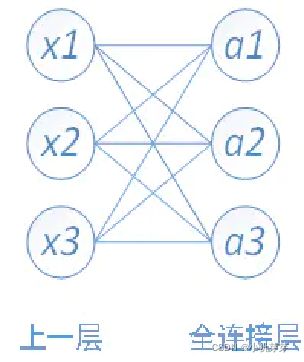
3.5.4 全连接层工作原理
全连接可以看成是特殊的卷积层。全连接层的每一个节点都与上一层每个节点连接,是把前一层的输出特征都综合起来,所以该层的权值参数是最多的。例如在VGG16中,第一个全连接层FC1有4096个节点,上一层POOL2是77512 = 25088个节点。由于可以把全连接层看成卷积层的一个特例,比如VGG16,POOL2到FC1层是全连接的,把pool2的输出节点按向量排列,即有25088个维,每一维大小为1*1,卷积核可以看成num_filters = 4096,channal = 25088,kernel_size = 1,stride=1,no pad。

3.5.5 VGG16网络性能评估
VGG优点:
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:验证了通过不断加深网络结构可以提升性能。
VGG缺点:
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG有3个全连接层 PS:据测试发现这些全连接层即使被去除,对于性能也没有什么影响,但这样就显著降低了参数数量。注:很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model(预训练模型)让我们很方便的使用。
3.6 神经网络深度增加的研究和发现
在计算机视觉里,网络的深度是实现网络好的效果的重要因素,输入特征的“等级”随增网络深度的加深而变高。然而在网络深度不断加深的情况下,梯度消失和/爆炸成为训练深层次的网络的障碍,导致导致网络无法收敛。虽然,归一初始化,各层输入归一化,使得可以收敛的网络的深度提升为原来的十倍。虽然网络收敛了,但网络却开始退化 (增加网络层数却导致更大的误差), 如下图所示:
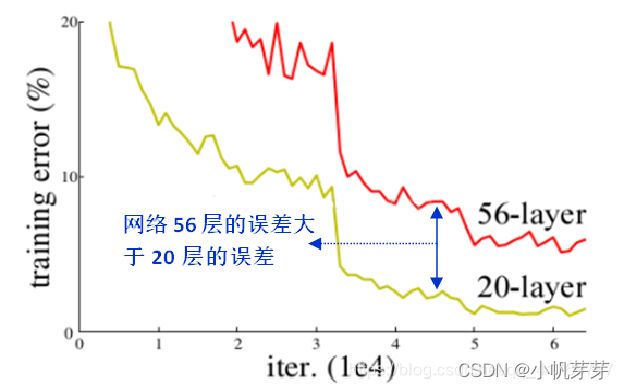
3.6.1 Resnet网络
Resnet的残差单元:
ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域里得到广泛的应用。它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,下面是这个resnet的网络结构:
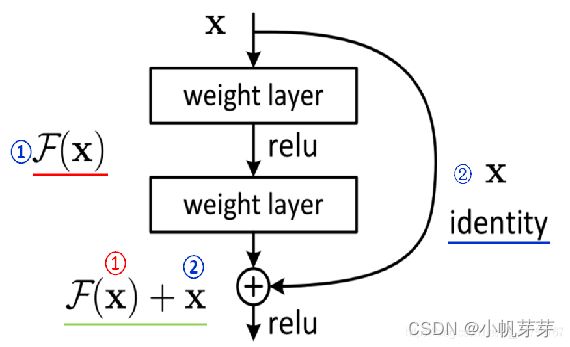
其中σ代表激活函数ReLU:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WCJ3LcvE-1640420041399)(%E5%9B%BE%E5%83%8F%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96%EF%BC%88VGG%E5%92%8CRESNET50%EF%BC%89.assets/1640418983433.png)]](http://img.e-com-net.com/image/info8/ccc304af62cc4701a0105d5107a478b3.jpg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kHe2losM-1640420041400)(%E5%9B%BE%E5%83%8F%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96%EF%BC%88VGG%E5%92%8CRESNET50%EF%BC%89.assets/1640418993146.png)]](http://img.e-com-net.com/image/info8/5319ded13c76473e956f0d40167025dd.jpg)
当需要对输入和输出维数进行变化时(如改变通道数目),可以在shortcut时对x做一个线性变换Ws,如下式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ANpPxTmB-1640420041400)(%E5%9B%BE%E5%83%8F%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96%EF%BC%88VGG%E5%92%8CRESNET50%EF%BC%89.assets/1640419017527.png)]](http://img.e-com-net.com/image/info8/0d47ee4ac6d04e278eeb17a709b2668e.jpg)
3.6.2 Resnet残差单元
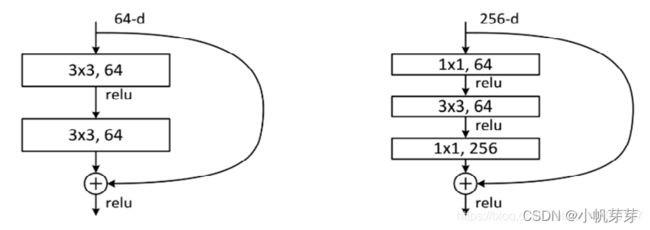
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个“building block” 。其中右图又称为“bottleneck design”,目的就是为了降低参数的数目,实际中,考虑计算的成本,对残差块做
了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1,如右图所示。新结构中的中间3x3的卷积层首先在
一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。
第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,
整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量。
3.6.3 Resnet各类模型卷积参数
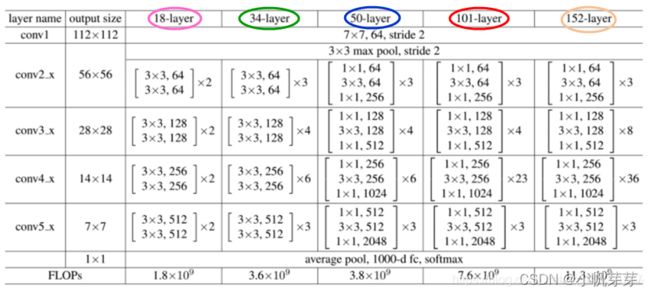
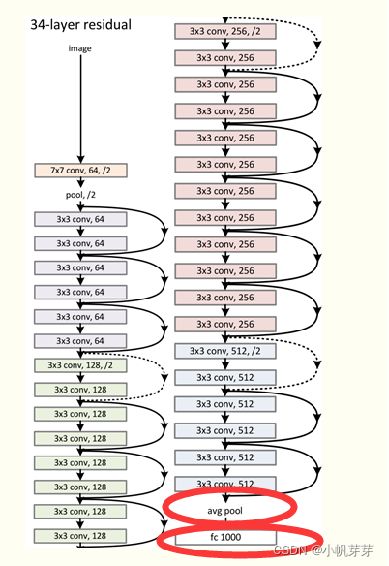
3.6.4 Resnet50网络构成
Resnet50 网络中包含了 49 个卷积层、1个全连接层。如图下图所示,Resnet50网络结构可以分成七个部分,第一部分不包含残差块,主要对输入进行卷积、正则化、激活函数、最大池化的计算。第二、三、四、五部分结构都包含了残差块。在 Resnet50 网 络 结 构 中 , 残 差 块 都 有 三 层 卷 积 , 那 网 络 总 共 有1+3×(3+4+6+3)=49个卷积层,加上最后的全连接层总共是 50 层,这也是Resnet50 名称的由来。网络的输入为 224×224×3,经过前五部分的卷积计算,输出为 7×7×2048,池化层会将其转化成一个特征向量,最后分类器会对这个特征向量进行计算并输出类别概率。
3.6.5 Resnet50 卷积和池化
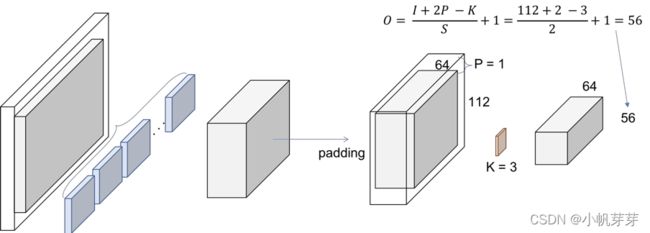
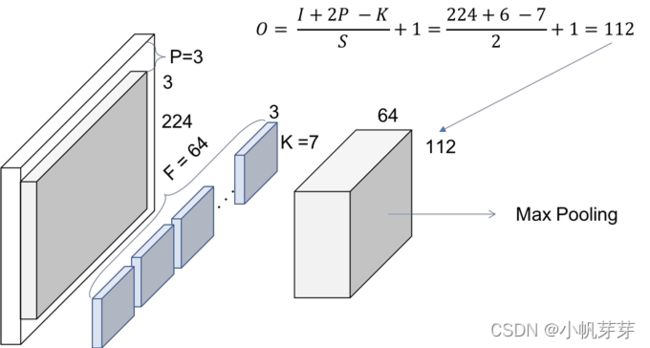
注意:当尺寸不被整除时,卷积向下取整,池化向上取整。
3.6.6 Resnet与普通神经网络对比(向前传播和误差向后传播)

前向过程,最后的结果表示直接的前向过程,连加的运算(考虑的残差元为一个单元,残差元的内部还是两层的连
乘),即从第l层可以直接到第L层,而传统的网络则是连乘运算,计算量明显不同。(从连乘到连加)

对于残差元来说,前向过程是线性的,而且后面的输入等于输入加上每一次的残差元的结果,而普通的网络,则为每一层卷积的连乘运算;残差网络的第一大特点,反向更新解决梯度消失的问题.
3.6.7 为什么残差网络能解决梯度消失
BP神经网络举例,其使用sigmiod函数作为激活函数,其导数下面第二个图,最大值是0.25。

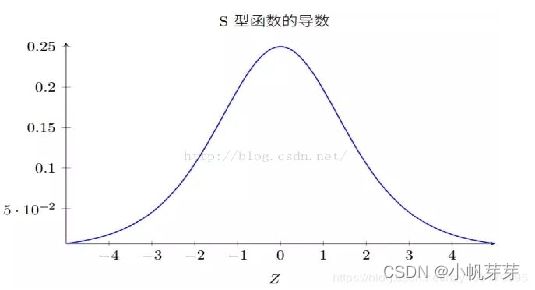
在BP网络的误差方向传导过,由求导的链式法则,对激活函数求导,随着网络层数增加,由于连乘,即使取最大值,若干个0.25相乘慢慢趋近于0,到后面梯度基本消失,权值也不再变化,即使网络再多也学不到东西。
3.6.8 Resnet能解决梯度消失
Resnet误差向后传播过程:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KzEKgp2G-1640420041409)(%E5%9B%BE%E5%83%8F%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96%EF%BC%88VGG%E5%92%8CRESNET50%EF%BC%89.assets/1640419614550.png)]](http://img.e-com-net.com/image/info8/718926c1027c49e1bc50626a6aba0b06.jpg)
可以看出反向传播的梯度由两项组成:
1.对xl 求导,梯度为1
2.对多层普通神经网络求导为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JpxvdjLJ-1640420041410)(%E5%9B%BE%E5%83%8F%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96%EF%BC%88VGG%E5%92%8CRESNET50%EF%BC%89.assets/1640419723501.png)]](http://img.e-com-net.com/image/info8/6f6c2ab11671491b9b737ad73a776e07.jpg)
即使普通神经网络求导趋近0,那两项相加,那和1相加不可能为0,所以误差也能够有效传播到很深的网络,所以使用残差网络结构能够避免梯度消失的问题。
3.6.9 Resnet网络性能评估
在过于深的网络在反传时容易发生梯度消失,一旦某一步开始导数小于1,此后继续反传,传到前面时,用float32位数字已经无法表示梯度的变化了,相当于梯度没有改变,也就是浅层的网络学不到东西了。这是网络太深反而效果下降的原因。加入ResNet中的shortcut结构之后,在反传时,每两个block之间不仅传递了梯度,还加上了求导之前的梯度,这相当于把每一个block中向前传递的梯度人为加大了,也就会减小梯度消失的可能性,从而能够很好的学习更深层的特征。
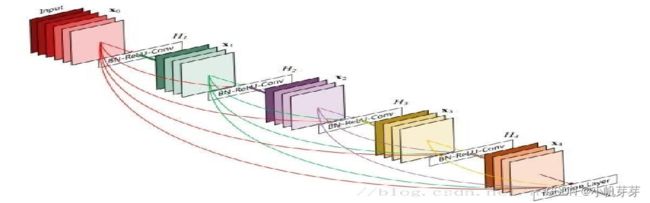
特征冗余:认为在正向卷积时,对每一层做卷积其实只提取了图像的一部分信息,这样一来,越到深层,原始图像信息的丢失越严重,而仅仅是对原始图像中的一小部分特征做提取。这显然会发生类似欠拟合的现象。加入shortcut结构,相当于在每个block中又加入了上一层图像的全部信息,一定程度上保留了更多的原始信息。
总的来说,由于每做一次卷积(包括对应的激活操作)都会浪费掉一些信息:比如卷积核参数的随机性(盲目性)、激活函数的抑制作用等等。这时,ResNet中的shortcut相当于把以前处理过的信息直接再拿到现在一并处理,起到了减损的效果。对于深层特征的学习效果还是比较优越的
3.7 Resnet50提取特征并实现图像相似性比对实操


这篇文章有没有帮到你呢,有的话欢迎关注点赞收藏哦,后续还有大波福利推送!!!!!!!!
