深度学习10-经典深度学习模型简介二+VGG+ResNet+GooleNet
VGG
https://my.oschina.net/u/876354/blog/1634322
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的)和定位项目的第一名。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。
VGG的特点
1、结构简洁
VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
2、小卷积核和多卷积子层
VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
小卷积核是VGG的一个重要特点,虽然VGG是在模仿AlexNet的网络结构,但没有采用AlexNet中比较大的卷积核尺寸(如7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从1到4卷积子层,AlexNet:1子层)。
VGG的作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7x7的参数为49个,而3个3x3的参数为27)
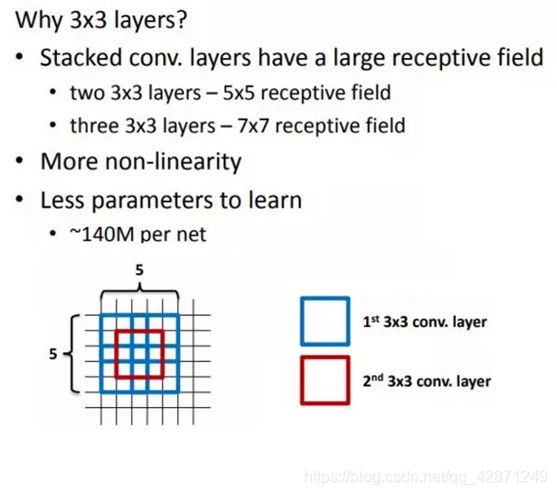
3、小池化核
相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
4、通道数多
VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。
5、层数更深、特征图更宽
由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
6、全连接转卷积(测试阶段)
这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用
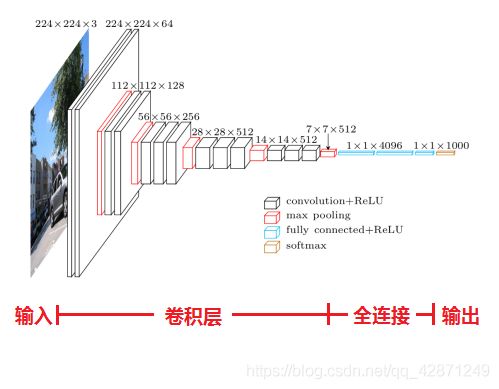
层数详解

以网络结构D(VGG16)为例,介绍其各层的处理过程如下:
1、输入224x224x3的图片,经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
2、作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
3、经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
4、作2x2的max pooling池化,尺寸变为56x56x128
5、经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
6、作2x2的max pooling池化,尺寸变为28x28x256
7、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
8、作2x2的max pooling池化,尺寸变为14x14x512
9、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
10、作2x2的max pooling池化,尺寸变为7x7x512
11、与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
12、通过softmax输出1000个预测结果
ResNet
背景
增加深度带来的首个问题就是梯度爆炸/消散的问题,这是由于随着层数的增多,在网络中反向传播的梯度会随着连乘变得不稳定,变得特别大或者特别小。这其中经常出现的是梯度消散的问题。这篇文章梯度爆炸/消失问题讲的很好。https://www.zhihu.com/question/64494691?sort=created
为了克服梯度消散也想出了许多的解决办法,如使用BatchNorm,将激活函数换为ReLu,使用Xaiver初始化等,可以说梯度消散已经得到了很好的解决
增加深度的另一个问题就是网络的degradation问题,即随着深度的增加,网络的性能会越来越差,直接体现为在训练集上的准确率会下降,残差网络文章解决的就是这个问题,而且在这个问题解决之后,网络的深度上升了好几个量级。
用学术点的话说,这种神经网络丢失的“不忘初心”/“什么都不做”的品质叫做恒等映射(identity mapping)。因此,可以认为Residual Learning的初衷,其实是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化!
Residual Module
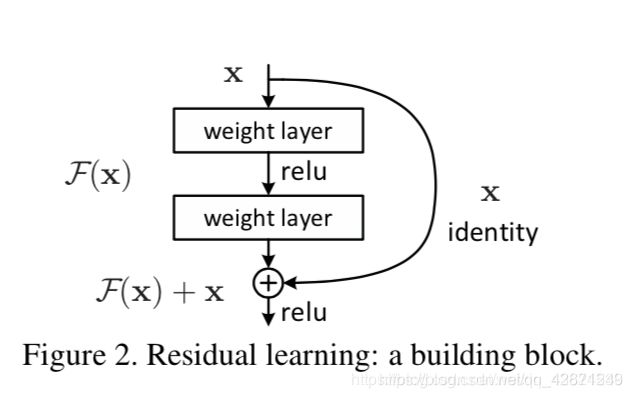
根据上图,copy一个浅层网络的输出加给深层的输出,这样当网络特征达到optimal的时候更深层恒等映射的任务就从原来堆叠的层中释放到新建的这个恒等映射关系中,而原来层中的任务就从恒等映射转为全0。
F(x)=H(x)−x F(x)=H(x)-xF(x)=H(x)−x,x为浅层的输出,H(x) H(x)H(x)为深层的输出,F(x) F(x)F(x)为夹在二者中间的的两层代表的变换,当浅层的x代表的特征已经足够成熟,如果任何对于特征x xx的改变都会让loss变大的话,F(x) F(x)F(x)会自动趋向于学习成为0,x xx则从恒等映射的路径继续传递。这样就在不增加计算成本的情况下实现了一开始的目的:在前向过程中,当浅层的输出已经足够成熟(optimal),让深层网络后面的层能够实现恒等映射的作用。
更多详细解释可以参考:
https://blog.csdn.net/weixin_43624538/article/details/85049699
GoogleNet
背景
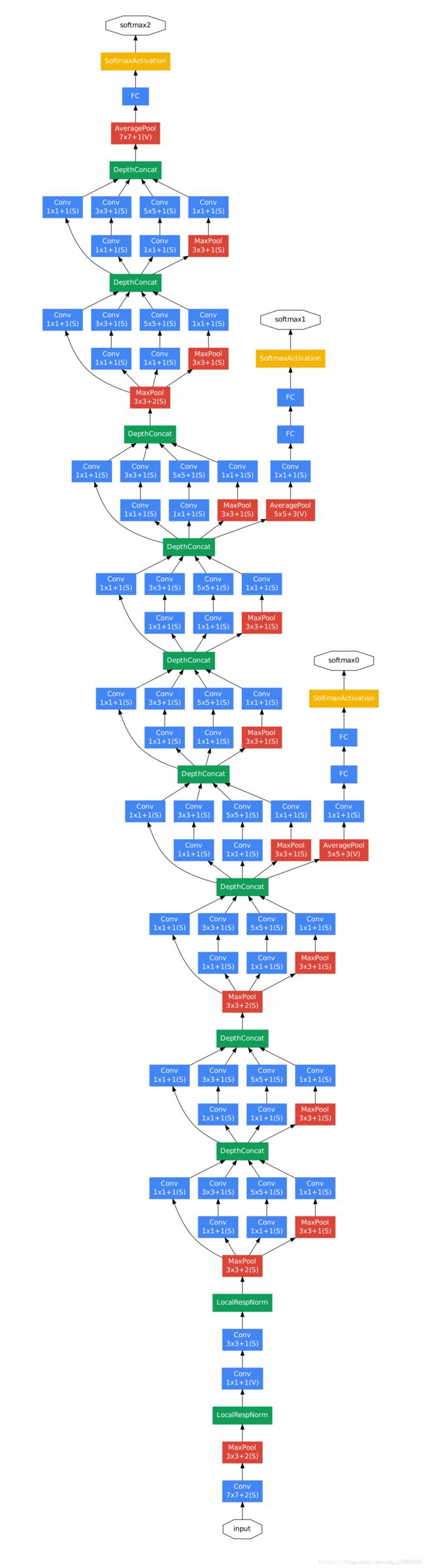
在2014年的ILSVRC比赛中,GoogLeNet取得了第一名的成绩,所用模型参数不足AlexNet(2012年冠军)的1/12。相比第二名的VGGNet,GoogLeNet拥有更深的网络结构和更少的参数和计算量,主要归功于在卷积网络中大量使用了1x1卷积,以及用AveragePool取代了传统网络架构中的全连接层。
Inception Module
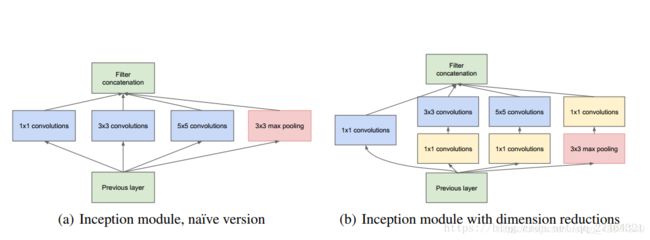
但是初级的版本有个很大的缺点就是参数量和计算量会很大,而且将三个卷积层和一个池化层的输出拼接后的feature map数量会变得很大,随着网络层数的增加,模型会变得很复杂,变得难以训练。以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×321×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32)1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1×1卷积,使得输出的feature map数降到了256。GoogLeNet利用1×1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层的AlexNet的十二分之一(当然也有很大一部分原因是去掉了全连接层)。
另外一个值得注意的地方是:为了避免网络过深引起的浅层梯度消失问题,GoogLenet在中间层的Inception module加入了两个辅助分类器(softmax),训练时在进行梯度下降求导的时候,将辅助分类器的损失函数(cost function)乘以0.3的权重加到总的损失函数上,这样可以有效避免梯度消失的问题。做预测的时候就不管这两个辅助分类器。
GoogleNet网络
Xception
Xception是基于Inception的增强版
https://blog.csdn.net/MOU_IT/article/details/84945512
DenseNet
https://www.cnblogs.com/zhhfan/p/10187634.html
NasNet
https://blog.csdn.net/qq_14845119/article/details/83050862