深度学习Backbone网络系列(一)
目录
AlexNet
VGG
GoogLeNet
Inception V1
Inception V2&v3
Inception V4,Inception-Res-v1&v2
AlexNet
2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。ReLU激活函数比Sigmoid性能好,有助于加深网络层次,并在ReLU之后添加了Normalization操作(即LRN);Dropout缓解了过拟合问题;LRN(局部响应归一化),对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力;池化层全部采用max-pooling,避免平均池化的模糊化效果。同时AlexNet也使用了GPU进行运算加速。
百度百科中的数据增强部分:

个人认为,增加的数据量为2*(256*256-224*224)=30720倍,这一块不是很懂,请指正,谢谢!
LRN参考

VGG
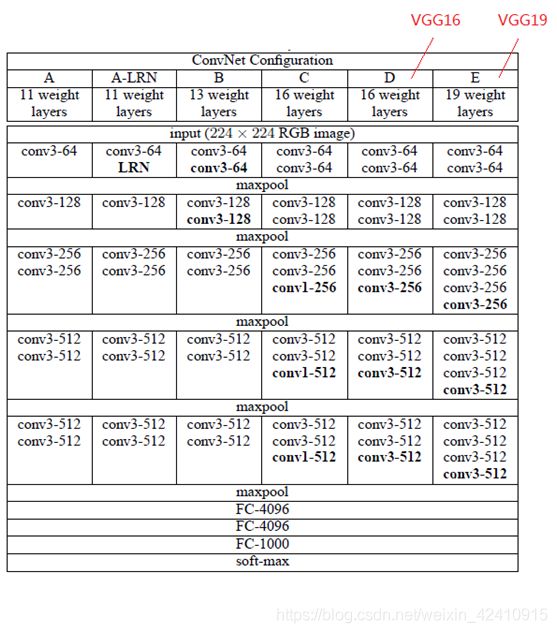
VGG模型是2014年ILSVRC竞赛的第二名。特点:
-
小卷积核。卷积核全部为3x3(极少用了1x1);
-
小池化核。全部为2x2的池化核;
-
通道数多。可以提取更多的特征信息;
-
层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
-
卷积层替换全连接层。网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高的输入。
GoogLeNet
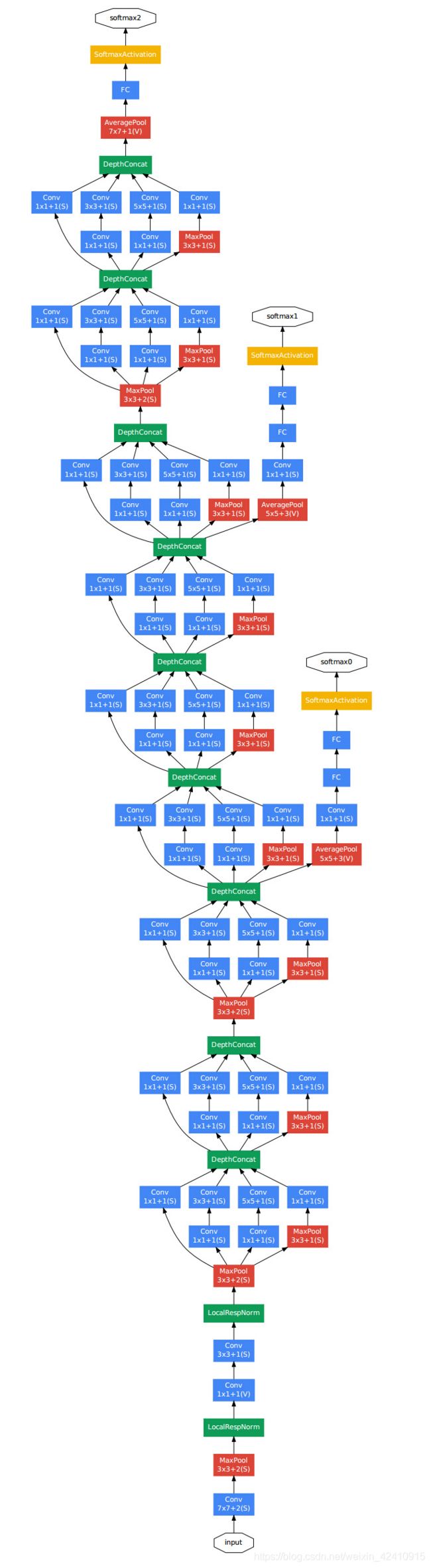
GoogLeNet模型是2014年ILSVRC竞赛的第一名。特点:
1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。
3)虽然移除了全连接,但是网络中依然使用了Dropout ;
4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器只是在训练时使用,在正常预测时会被去掉。辅助分类器促进了更稳定的学习和更好的收敛,往往在接近训练结束时,辅助分支网络开始超越没有任何分支的网络的准确性,达到了更高的水平。
Inception V1
墙裂建议参考
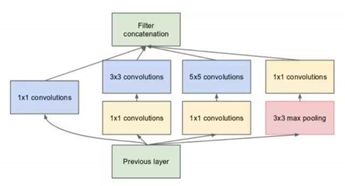
2014年提出,运用在了GoogLeNet。使网络变宽,在保证模型质量的前提下,减少参数个数,提取高维特征。
基本思想:首先通过1*1卷积降低通道数,将信息聚集;再进行不同尺度(3*3、5*5)的特征提取以及池化,得到多尺度的信息;因为信息的尺寸不一,所以经过padding操作,将小尺度的信息扩大为大尺度的信息,然后将特征进行叠加输出。(官方指出:可以将稀疏矩阵聚类为较密集的子矩阵来提高计算性能)
主要过程:1、在3*3卷积核、5*5卷积核前面、3*3池化后面添加1*1卷积(黄色方块),将信息聚类且可以有效减少参数量(称瓶颈层);2、进行1*1、3*3和5*5卷积,网络学习到稀疏(3*3、5*5)或不稀疏(1*1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;3、将每个block得到的特征,按照深度叠加,获得非线性属性。
注:在进行卷积之后都需要进行ReLU激活。下图从下往上看。
Inception V2&v3
inception-v3结构图可见此文章
原论文


论文中指出(上图):表示尺寸在成为最终测试用的表示信息之前,其输入尺寸到输出尺寸应该慢慢递减。理论上,不能仅仅由表示维度去评估最终得到的信息好坏,而忽略其他重要的因素,比如相关结构;维度仅仅提供了信息的粗略估计。

上图:“网络更容易处理高维表示信息,在每个tile(卷积层——>池化层——>激活函数,个人理解,有误请指正,谢谢)添加激活函数会获得更多独立信息。这样的网络会训练的更快。”

上图:“在低维嵌入中进行空间聚集,可以避免一定的表示损失。”

上图:“增加网络的宽度和深度可以提高网络性能。但是,如果两者并行增加,可以使计算量得到最优改进。”
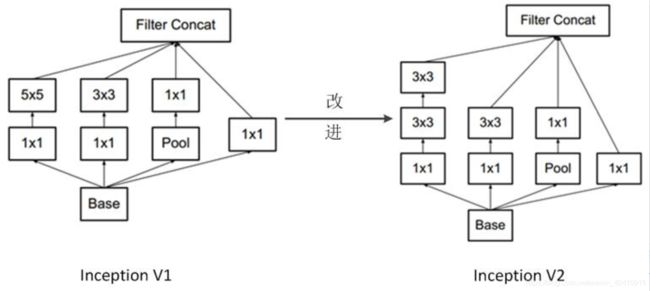
Inception-V2将5*5卷积核替换成两个3*3卷积核。如上图。

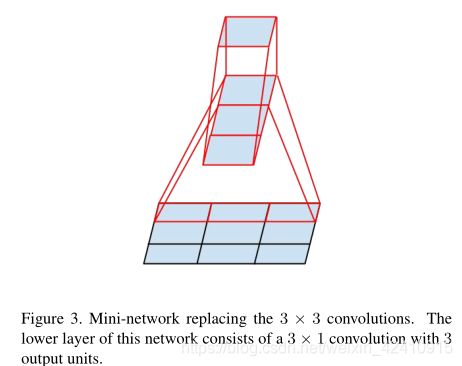
上图(左侧):“更小的卷积核尺寸可以减少参数量,还能保证网络性能,那么为什么没有将5*5卷积替换成2*2的卷积呢?因为作者发现,用3*1+1*3两层卷积代替一层3*3卷积的性能更好(如上图右侧)。”如果输入和输出的卷积核个数相同,在保证性能的前提下,计算量还能减少33%

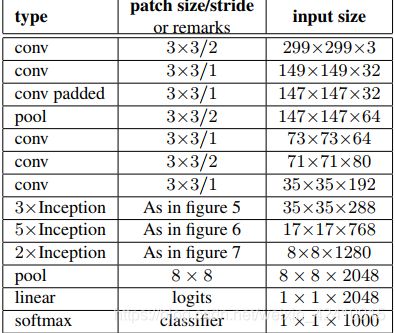
上图:“Inception-v2将7*7的卷积转换为3个3*3的卷积。对于网络中的每个Inception模块,用768个核的17*17的网格代替288个核的35*35的网格”。
总结:把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍。
Inception V4,Inception-Res-v1&v2
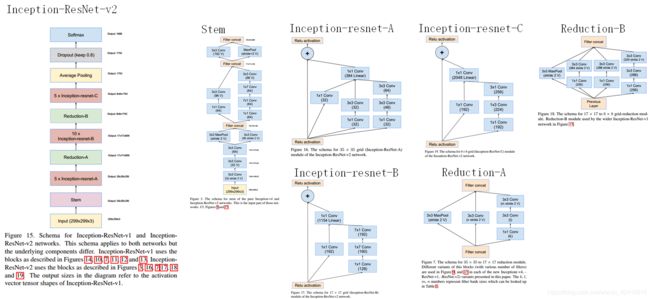
Inception V4研究了Inception模块与残差连接的结合。ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。Inception V4主要利用残差连接(Residual Connection)来改进V3结构,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。
Inception和残差结构结合后如下。
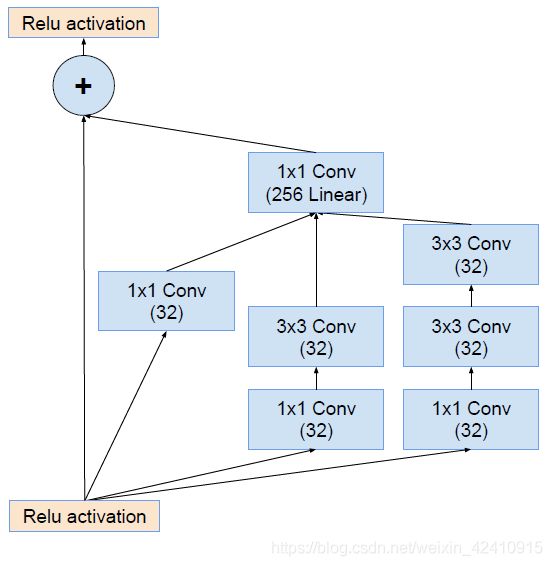
Inception-V4不包含Residual连接,其识别精度和Inception-ResNet-V2差不多,但还是后者稍强些。

通过20个类似的模块组合,Inception-V4构建如下
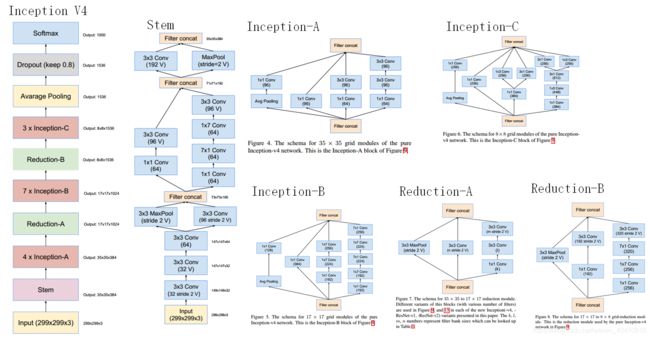
下图:Inception-ResNet-V1的计算量和Inception-V3类似。

Inception-ResNet-V1结构图如下
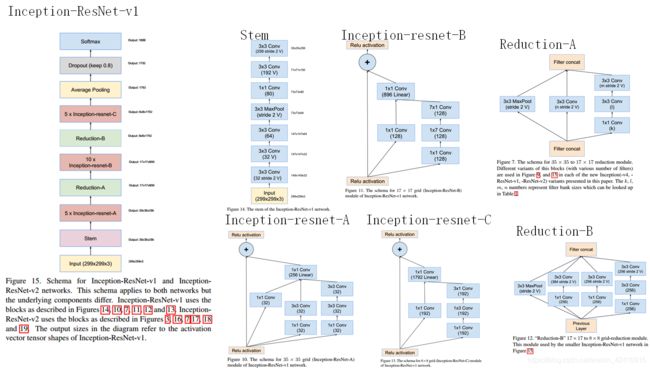
Inception-ResNet-V2的计算成本非常高,但是识别精度大大提高。

Inception-ResNet-V2结构图如下