目标检测中的Label Assignment

©PaperWeekly 原创 · 作者|燕皖
单位|渊亭科技
研究方向|计算机视觉、CNN

Label Assignment
Label assignment 主要是指检测算法在训练阶段,如何给特征图上的每个位置进行合适的学习目标的表示,以及如何进行正负样本的分配的。也就是说 label assignment 有两个方面的内容:
1.1 学习目标的表示
对与如何给特征图上的每个位置赋予合适的学习目标这个问题,因为先验的不同,不同类型的算法的学习目标的表示也不一样:
anchor box 类检测器:这类检测方法都是采用 bounding box(x,y,w,h)的方法来表示图像中的一个目标。通过预测一个 4 维向量,也就是参数化坐标 ,来回归得到最终的目标框,如 Faster RCNN 的最终目标:
![]()
anchor box 类的检测法被称为 anchor 的方法,其先验就是 anchor box,将 anchor box 做为分类和框回归的基准框。通常,在构建 anchor box 时,需要若干个特定尺度(scale)和长宽比(aspect ratio) ,然后在特征图上以一定的步长滑动生成。
anchor point 类检测器:该类型的算法采用目标中心点,以及边框距中心点的距离或目标宽高或高斯热图来表示图像中的目标,本质上和 anchor-based 算法相似。经典例如:FCOS、CenterNet 等;
key point类检测器:这类算法采用图像中目标的边界点(如:角点),再将边界点组合成目标的框,例如:CornerNet, RepPoints。
anchor point 和 key-point 被称为 anchor free 的方法,其先验是 point,在 point 的基础上做分类和回归。
set predicion 类检测器:这类算法的代表作是 DETR,其首次使用 transformer 做目标检测,将目标检测任务视为一个图像到集合(image-to-set)的问题,可以说是 CV 领域的重要里程碑。
DETR 采用 bounding box(中心坐标和宽高)的形式来表示图像中的一个目标,并将先验表示为 object queries,object queries 就是一个 embedding 形式的 learned anchor。DETR 认为与其使用人工设计的 anchor,不如用 embedding,让网络自己去学习 anchor。
1.2 正负样本的分配
对于不同的表示,分配正负样本的方式也略有不同。
anchor box 类型检测器:通常采用 IoU 的方法。例如 RetinaNet,通过 anchor 与 GT 框之间的 IoU 判定是 positive、negative 还是 ignore,IoU 低于 0.4 为 negative,高于 0.5 为 positive,其他为 ignore。
anchor point 类型检测器:不同算法的表现形式不一样。例如 CenterNet 高斯热图确定正负样本,而 FOC 通过层级,区域和 centerness 分配正负样本
key point 的类型检测器:不同算法的也不太一样,例如 RepPoints 通过 feature map bin 和 IOU 进行正负样本的区分。
set predicion 类检测器:使用 Hungarian algorithm 实现预测值与真值实现最大的匹配,并且是一一对应。不会多个预测框匹配到同一个 ground truth 上,这样就无需 NMS 后处理了。
1.3 小节
Label assignment 是目标检测中一个重要的环节,其结果直接决定了模型性能的好坏。对于不同的先验,Label assignment 的学习目标的表示和正负样本的分配都有着不同的表示形式。
算法类型 |
先验 |
学习目标的表示 |
正负样本的分配 |
anchor box |
anchor box |
bounding box |
IoU |
anchor point |
center |
高斯等 |
高斯热图等 |
key point |
point |
representative points |
feature map bin和IoU等 |
set prediction |
embedding |
bounding box |
Hungarian算法 |
下面再来看看讨论 Label Assignment 的几篇文章。

ATSS

论文标题:
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
论文链接:
https://arxiv.org/abs/1912.02424
代码链接:
https://github.com/sfzhang15/ATSS
这篇文章从 anchor-free 和 anchor-base 算法的本质区别出发,通过分析对比 anchor-base 经典算法 retinanet 和 anchor-free 经典算法 FCOS 来说明正负样本分配(label assignment)的重要性。
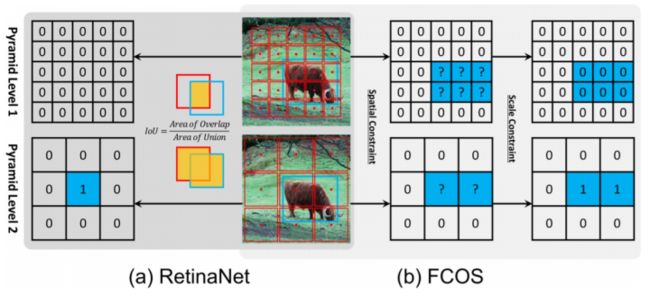
如上图所示,RetinaNet 使用 IoU 阈值 来区分正负 anchor box,处于中间 anchor box 的全部忽略。FCOS 使用空间(spatial)和尺寸(scale)限制来区分正负 anchor point,正样本首先选择在 GT box 内的 anchor points,其次选择 GT 尺寸对应的层 anchor points,其余均为负样本。
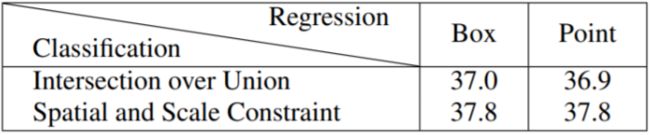
最后通过交叉实验,发现在相同正负样本定义下情况下,RetinaNet 和 FCOS 性能几乎一样,而且 spatila and scale constraint 的方式比 IOU 的效果好,如下表:
因此 ATSS 提出了一种新的正负样本选取方式,这种方法几乎不会引入额外的超参数并且更加鲁棒。
主要就是在每个 FPN 层选取离 gt 框中心点最近的 k 个 anchor,之后对所有选取的 anchor 与 gt 计算 IOU,同时计算 IOU 均值 和方差 ,最后保留 IOU 大于均值加方差 ( ) 的并且中心点在 gt 之内的 anchor 作为正样本。
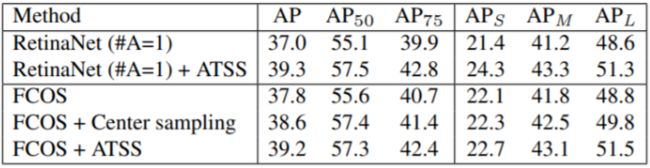
根据下表可以发现,即使 anchor box 数量为 1 的 RetinaNet 和 FOCS 在都加上 ATSS 策略之后,效果都有明显的提升,这也证明了 ATSS 策略的有效性。

SAPD

论文标题:
Soft Anchor-Point Object Detection
论文链接:
https://arxiv.org/abs/1911.12448
代码链接:
https://github.com/xuannianz/SAPD
SAPD 就是对 anchor-free 检测器中的 anchor-point 检测器进行了训练策略的改进。SAPD 分析了两个问题:注意力偏差(attention bias)和特征选择(feature selection)。其中,特征选择的问题对金字塔特征层级做软选择,这里就不深入了。而为了解决注意力偏差(attention bias),SAPD 使用了一个新颖的训练策略:Soft-weighted anchor points。
3.1 Attention bias 注意力偏差
在自然图像中,可能会出现遮挡、背景混乱等干扰,SAPD 发现原始的 anchor-point 检测器在处理这些具有挑战性的场景时存在注意力偏差的问题,即具有清晰明亮 views 的目标会生成过高的得分区域,从而抑制了周围的其他目标的得分区域。
这个问题是由于特征不对齐导致了靠近目标边界的位置会得到不必要的高分 所导致的。

3.2 Soft-weighted anchor points
将目标实际位置与 anchor point(也就是 center)的距离作为一个 anchor 的惩罚权重,加入到损失函数的计算中(仅针对正样本,负样本不做改动)。公式如下:
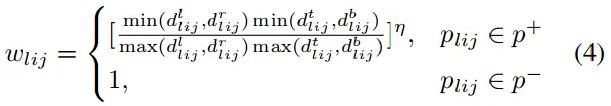
其中,η 控制递减幅度,权重 范围为 0~1,公式保证了目标边界处的 points 权重为 0,目标中心处的 ponit 权重为 1。
这种通过对 anchor points 做软加权,就是 label assign 的进行优化,减少对靠近边界包含大量背景信息的锚点的关注。

AutoAssign

论文标题:
AutoAssign: Differentiable Label Assignment for Dense Object Detection
论文链接:
https://arxiv.org/abs/2007.03496
AutoAssign 对 label assignment 进行非常全面的讨论。主要解决了在给定一个 bounding box (x, y, w, h) 后,根据框内的物体形状,动态分配正负样本的问题。如下图所示:
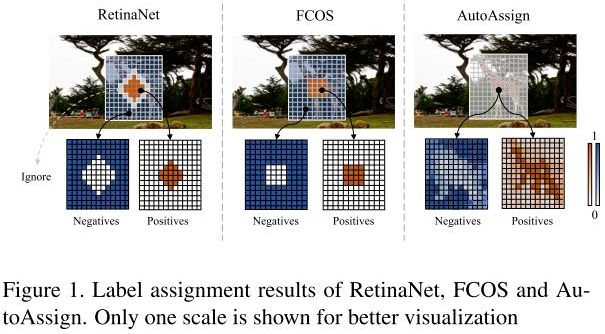
(1)RetinaNet 是根据 anchor box 和 ground truth 的 IOU 阈值定义正负样本,这样会每个样本都是打上非正即负以及 ignore 的标签,而且 anchor box 的 num,size,aspect ratios 等等都是超参数;
(2)FCOS 通过 centerness、空间和尺度约束来分配正负样本,也引入了很多超参数;
(3)AutoAssign 将 label assignment 看做一种连续问题,没有真正意义上的正负样本之分,每个特征图上的位置都有正样本属性和负样本属性,只是权重不同罢了;而且如上图最左变所示,动态分配正负样本更符合目标的形状,可以说有利用分割做检测的思想。
下面是 AutoAssign 的正负样本分配的示意图:
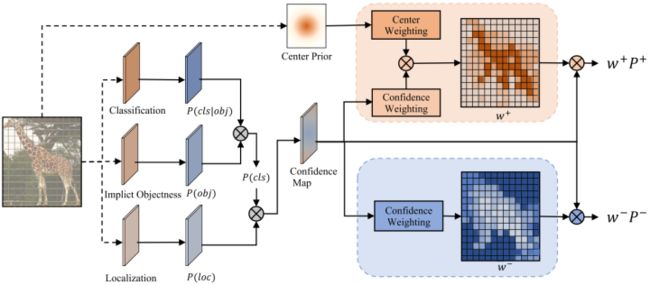
可以看到,比一般的检测算法多了一个 Implict Objectness 分支,用于背景与前景的判断,已解决引入的大量背景位置的问题。
(1)Center Weighting
先使用高斯中心先验确定图像中一个目标正负样本的权重:
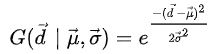
(2)Confidence Weighting
通过 ImpObj 分支来避免引入大量背景位置
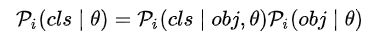
与 FreeAnchor 相似,将分类和定位联合看成极大似然估计问题,学习出样本的置信度 Confidence Weighting,即下面的 C(Pi):
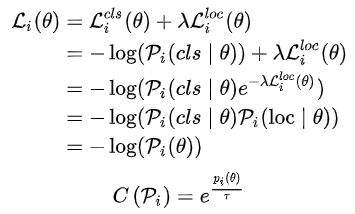
直观的理解 C(Pi) 就是,分类得分高、框预测的准的 location 拥有较大的 C(Pi) 值的概率就会高。
(3)正负样本的权重(w+/w-)
positive weights:通过Center Weighting和Confidence Weighting得到Positive weights
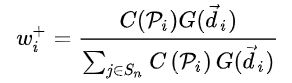
negative weights:通过最大 IOU 得到 Negative weights
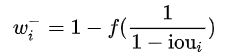
对于前景和背景的 weighting function,有一个共同的特点是 “单调递增”;这就保证了一个位置预测 pos / neg 的置信度越高,那么对应的权重就越大。
(4)loss function
有了对于正负样本的权重之后,对于一个 gt box,其 loss 如下:

Positive weights 和 Negative weights 在训练过程中动态调整达到平衡,像是在学该目标的形状。

DETR

论文标题:
End-to-End Object Detection with Transformers
论文链接:
https://arxiv.org/abs/2005.12872
代码链接:
https://github.com/facebookresearch/detr
5.1 Object detection set prediction
DETR 将目标检测任务视为一个图像到集合(image-to-set)的问题,即给定一张图像,模型的预测结果是一个包含了所有目标的无序集合。

那么对于一个目标 ground truth,如何找到对应的 prediction 呢?Detr 用的是 Hungarian algorithm 实现预测值与真值实现最大的匹配,并且是一一对应。
假设有 4 个 prediction(a,b,c,d),有 4 个 ground truth(p,q,r,s),每个 prediction 匹配 ground truth 的好坏都不同,那么便可构造一个代价矩阵(cost matrix,是 cost_bbox、cost_class 和 cost_giou 的加权和),通过求解最优的分配后,得到的每个 prediction 对应 ground truth 最佳分配的结果。
5.2 object queries
传统的 Anchor 是人工设计,铺在特征图上。最初人们给 Anchor 加上 scales 和 aspect ration,后来还有加上了 dense,再到后来,也出现了可学习的 Guided Anchoring,把 anchor 拆解为:位置预测和形状预测。
这种方式的 anchor 有个缺陷是:在推理阶段会产生大量的框,需要 NMS 进行抑制,这说明人工设计的 anchor 是存在冗余的(多个 anchor 匹配到一个 gt 上)。
而 DETR 的 object queries 就是一个 embedding 形式的 learned anchor,目的是让网络自己根据数据集自己学习 anchor。并且 DETR 的实验结果也证明 embedding 已经足够学习 anchor 了。
Detr 也在 coco 2017 val 上对把每个 object query 预测的框做了可视化,如下,选取 N=100 中的 20 个 object query,可以看到不同的 query vector 具有不同的分布(有些注重左下角,有些注重中间…),可以想成:有 N 个不同的人用不同的角度进行观测。


写在最后
很多文章都有目标检测的文章都有 Label Assignment 的影子,从 anchor box 到 anchor point 和 key point,都是在讨论 Label Assignment 的问题,都是先确定好先验,再对学习目标的进合理表示,最后做好正负样本的分配。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

