UNet3+详解
目录
1. UNet3+解决的问题
(1)UNet
(2)UNet++
2. UNet3+的创新点
3. UNet3+的结构体
(1) 编码层
(2) 解码层
a.跳跃连接
b.分类引导模块(CGM)
c.特征聚合机制
d.深监督
e.混合损失函数
4. UNet3+的代码实现解说
(1) UNet_3Plus.py
(2) layers.py
(3) init_weights.py
(4) bceLoss.py
(5) iouLoss.py
(6) msssimLoss.py
1. UNet3+解决的问题
UNet++是由UNet结构更改而来,然而他不能从全部尺度上捕获信息,仍有很大的提升空间。于是UNet3+主要是解决了可以从全尺度上获取信息的问题。
既然说到全尺度,那就将UNet、UNet++、UNet3+捕获信息的情况讲解下。
(1)UNet
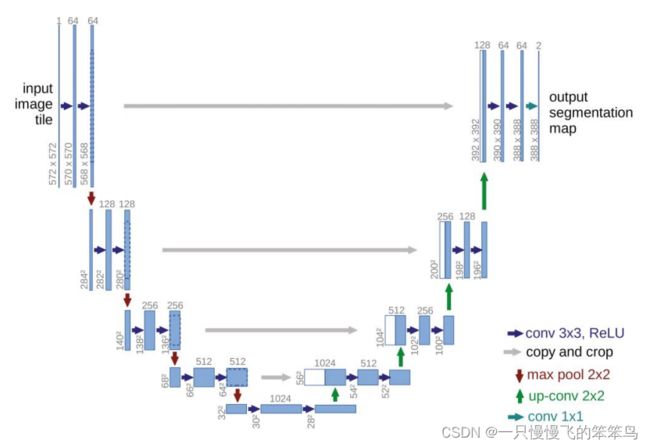
UNet主要是将解码层(下采样层)与编码层(上采样层)中同层之间进行连接。U型结构的低层主要是获取细粒度的细节特征(捕获丰富的空间信息),高层主要是获取粗粒度的语义特征(提现位置信息),所以UNet的这种仅有同层之间的连接,使得他的上下层连接时存在信息代沟现象。
(2)UNet++
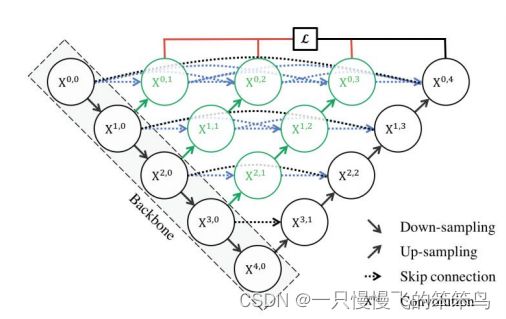
UNet++由UNet改编而来,具有嵌套、稠密的跳跃连接,一定程度缓解了UNet层次间的代沟问题,性能也相对提升了不少。
2. UNet3+的创新点
(1)UNet3+提出全尺度跳跃连接,此连接将来自不同尺度特征图的低级细节与高级语义相结合,最大程度使用全尺度的特征图,提高分割精度。
(2)深监督:深度监督从全尺度聚合特征图中学习层次代表。
(3)通过减少网络参数来提升计算效益。
(4)提出混合损失函数以增强器官边缘。
(5)设计了一个分类引导模型以减少在无器官图像中的过度分割现象。
3. UNet3+的结构体
由于我在初学该模型的时候,论文里的结构是分两个图提供的,当时我理解起来是有点小困难的,所以就想着画个完整的图分享给大家。
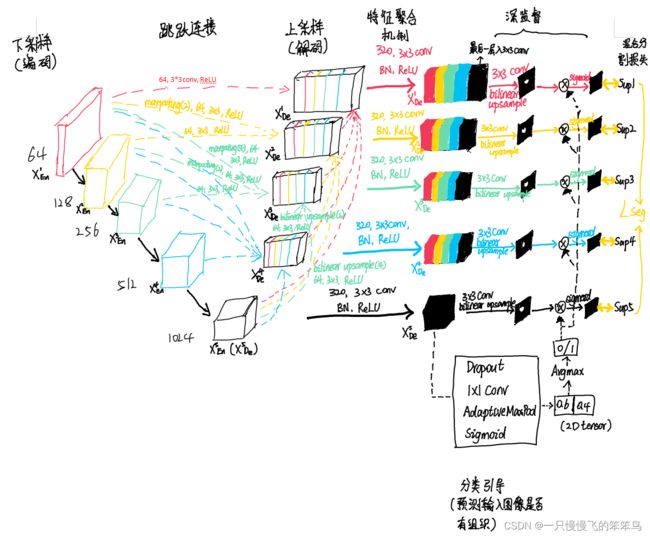
嘿,这是我第一次画网络图,不确定用哪个软件画比较好,就在派派(ipad)上手画的,有点乱乱的。等我有空时,再好好画画。如果大家有好用的画网络图的软件,也欢迎推荐我呀~
从左至右讲解~
(1) 编码Encoder
编码部分和UNet的编码部分是一样的。首先将输入的图像经过两次3*3卷积,每次卷积都紧跟着BatchNorm2d、ReLU。然后进行最大池操作,即 stride=2的2*2卷积。值得注意的是最下面一层即第五层卷积后不再进行下采样(最大池操作)。
解释 3*3卷积、BatchNorm2d、ReLU、最大池操作:
a. 3*3卷积
【突然间想不通为啥3*3卷积后特征通道不变了,等知道了再更新。】
b. BatchNorm2d
此处是为了将3*3卷积后的特征图进行数据归一化处理,防止后续的ReLU激活函数操作时,出现由于特征图数据过大,出现网络性能不稳定的问题。
c. ReLU
d. 最大池
最大池max pool使用的是2*2的卷积核,用来提取特征,使得特征通道放大一倍,由64到128.
(2) 解码Decoder
每个解码的实现机制是一样的,论文中是以Decoder3为例讲解的,我们也以Decoder3为例详细讲解,同时也介绍其它层的具体实现过程。
a. 跳跃连接 (此步骤在图中,由于图的跳跃线比较密集,没有将操作全部标在图上。)
Unet3+以全尺度连接为突出创新点,他的全尺度连接是在解码层实现的,具体来说就是该网络的每个解码层的特征图是通过5个尺度的特征图通过一定操作组成的。以Decoder3 为例详细介绍:
Decoder3的特征图是由来源于编码层中比它低层的Encoder1、Encoder2,和它同层的Encoder3,以及解码层中比它高层的Decoder4、Decoder5的特征图分别通过一些操作后构成的。那分别是做了哪些操作呢?
Encoder1:将特征图进行最大池无重叠操作,即stride=4的操作,记为maxpooling(4),然后进行64特征通道的3*3卷积,以及ReLU,总结就是maxpooling(4)、64特征通道、3*3conv、ReLU。
Encoder2:maxpooling(2),64, 3*3Conv,ReLU。
Encoder3:64, 3*3conv, ReLU. (因为是同层,他们的特征通道是相同的,不需要最大池提取特征。)
Decoder4:首先进行双线性上采样操作,然后特征图64的3*3卷积,ReLU操作。总计即 bilinear upsample(2), 64, 3*3conv, ReLU。
Decoder5:bilinear upsample(4), 64, 3*3conv, ReLU。
接下来从下往上简要介绍其他解码层的情况。
Decoder5: = Encoder5,故不做任何处理。
Decoder4:
encoder1: maxpooling(8), 64, 3*3conv, ReLU.
encoder2: maxpooling(4), 64, 3*3cong, ReLU.
encoder3: maxpooling(2), 64, 3*3cong, ReLU.
encoder4: 64, 3*3cong, ReLU.
decoder5: bilinear upsample(2), 64, 3*3conv, ReLU.
Decoder2:
encoder1: maxpooling(2), 64, 3*3conv, ReLU.
encoder2: 64, 3*3cong, ReLU.
Decoder3: bilinear umsample(2), 64, 3*3conv, ReLU.
Decoder4: bilinear umsample(4), 64, 3*3conv, ReLU.
Decoder5: bilinear umsample(8), 64, 3*3conv, ReLU.
Decoder1:
encoder1: 64, 3*3conv, ReLU.
Decoder2: bilinear umsample(2), 64, 3*3conv, ReLU.
Decoder3: bilinear umsample(4), 64, 3*3conv, ReLU.
Decoder4: bilinear umsample(8), 64, 3*3conv, ReLU.
Decoder5: bilinear umsample(16), 64, 3*3conv, ReLU.
b. 分类引导模块 classification-guided module(CGM)
1)提出原因:在大多数的医学图像分割中,在无器官的图像中出现假正率是一件必然发生的事情。这种事情的发生可能是由于存在于浅层中图像背景的噪声信息导致的过度分割现象。为实现更精确的分割结果,UNet3+提出通过加入一个额外的分类任务,预测输入的图片是否含有器官。
2)实现
从拥有最丰富语义信息的Encoder5中进行一系列操作,最后分割结果能进一步指导解码层中每一层的输出。
对Encoder5的一系列操作包括dropout,1*1卷积,自适应最大池AdaptiveMaxPool, Sigmoid操作,该一系列操作后得到一个2维张量;通过一个argmax函数,2维tensor转化为 {0,1} 中的一个单一输出,0代表无器官,1代表有器官;在每一个解码层中,将深监督阶段内bilinear up-sampling操作后的分割结果与分割结果0/1相乘。最后实现了将每层中的分割结果进行了分类。
【文章中说该模块的分类结果是在二值交叉上损失函数的优化下实现的,但我在作者提供的代码中没能找到该损失函数,后面等我真实复现时,再补充说明分类中损失函数的使用情况。】
c. 特征聚合机制
为了将浅层空间信息与深层语义信息精密合并,提出了特征聚合机制,该机制是将跳跃连接组成的320通道的特征图进一步聚合。具体操作是:将跳跃连接后的320个通道的特征图进行3*3卷积操作,BN数据归一化处理,ReLU激活。
d. 深监督
为了了解全尺度聚合特征图的阶层表达,在UNet3+上提出了全尺度深监督,在每一个解码层生成一个受ground truth监督的侧边输出。该步骤的操作包括:3*3conv,bilinear up-sampling, sigmoid。
深监督的具体操作是:将每个解码层的经过特征聚合机制生成的特征图的最后一层输入3*3卷积层内,之后伴随着一个双线性上采样bilinear up-sampling。然后将上采样后得到的分割结果与分类模块的结果0/1相乘;将相乘后的结果经过sigmoid处理,得到的结果即深监督的输出结果。然后将深监督结果输入损失函数。
e. 混合损失函数
文章中并没有明确说明将混合损失函数用在了何处,通过阅读文章中提供的图例,了解到应该是将混合损失函数用在了每个解码层深监督的后面,即将深监督中的最后一步sigmoid得到的操作结果再使用了混合损失函数。
混合损失函数:multi-scale structural sililarity index (MS-SSIM) loss (![]() ),focal loss (
),focal loss (![]() ), IoU loss (
), IoU loss (![]() ).
).
为进一步提升器官的边界,提出多尺度结构相似性损失函数 ![]() 。通过该函数,UNet3+将密切关注模糊边界,区域分布差异越大,他的MS-SSIM值越大。
。通过该函数,UNet3+将密切关注模糊边界,区域分布差异越大,他的MS-SSIM值越大。
focal loss是用在像素级的损失。MS-SSIM loss是用在通道级,IoU loss是用在特征图级。
4. UNet3+的代码实现解说
由于作者提供的代码内解释太少,对于我这种小白来说是有一定困难的,所以我将带有自己阅读笔记的代码分享给大家。
(1) UNet_3Plus.py
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers import unetConv2
from init_weights import init_weights
'''
UNet 3+
'''
class UNet_3Plus(nn.Module):
def __init__(self, in_channels=3, n_classes=1, feature_scale=4, is_deconv=True, is_batchnorm=True): #in_channels=3表示输入的是彩色图
super(UNet_3Plus, self).__init__()
self.is_deconv = is_deconv #作用??
self.in_channels = in_channels
self.is_batchnorm = is_batchnorm #一个卷积层后是否进行归一化处理,以防止ReLU处理时,由于数据过大,导致网络性能不稳定。
self.feature_scale = feature_scale
filters = [64, 128, 256, 512, 1024] #feature channels
## -------------Encoder--------------
#这是一个编码层
self.conv1 = unetConv2(self.in_channels, filters[0], self.is_batchnorm)
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = unetConv2(filters[0], filters[1], self.is_batchnorm)
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = unetConv2(filters[1], filters[2], self.is_batchnorm)
self.maxpool3 = nn.MaxPool2d(kernel_size=2)
self.conv4 = unetConv2(filters[2], filters[3], self.is_batchnorm)
self.maxpool4 = nn.MaxPool2d(kernel_size=2)
self.conv5 = unetConv2(filters[3], filters[4], self.is_batchnorm)
## -------------Decoder--------------
self.CatChannels = filters[0] #每个decoder用5个尺度的特征图进行拼接,每个尺度的特征图的特征通道都为64,即filter[0]
self.CatBlocks = 5 #每个decoder有来自五个尺度的特征图进行拼接
self.UpChannels = self.CatChannels * self.CatBlocks #每个decoder拼接后的特征通道数量 320
'''stage 4d'''
#Deccoder4中,获取较小四层的详细信息的拼接操作
#对En1的操作 maxpooling(8), 64, 3*3
# h1->320*320, hd4->40*40, Pooling 8 times
self.h1_PT_hd4 = nn.MaxPool2d(8, 8, ceil_mode=True) #MaxPool2d(kernel_size, stride, ceil_mode) kernel_size指最大池的窗口大小,stride是一次移动的步长,ceil_mode是向上取整。
self.h1_PT_hd4_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1) #padding对卷积后的特征图进行了边缘像素的修补。
self.h1_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels) #参数为特征通道的数量
self.h1_PT_hd4_relu = nn.ReLU(inplace=True) #inplace=True 函数会把输出直接覆盖到输入中。
#对En2的操作,maxpooling(4), 64, 3*3
# h2->160*160, hd4->40*40, Pooling 4 times
self.h2_PT_hd4 = nn.MaxPool2d(4, 4, ceil_mode=True)
self.h2_PT_hd4_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_PT_hd4_relu = nn.ReLU(inplace=True)
#对En3的操作,maxpooling(2), 64, 3*3
# h3->80*80, hd4->40*40, Pooling 2 times
self.h3_PT_hd4 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h3_PT_hd4_conv = nn.Conv2d(filters[2], self.CatChannels, 3, padding=1)
self.h3_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h3_PT_hd4_relu = nn.ReLU(inplace=True)
#对同层En4的操作,64, 3*3。 同层没有最大池的操作。
# h4->40*40, hd4->40*40, Concatenation
self.h4_Cat_hd4_conv = nn.Conv2d(filters[3], self.CatChannels, 3, padding=1)
self.h4_Cat_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h4_Cat_hd4_relu = nn.ReLU(inplace=True)
#Decoder4中,获取较大层的粗粒度信息的拼接操作
#bilinear upsample(2)
# hd5->20*20, hd4->40*40, Upsample 2 times
self.hd5_UT_hd4 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14 #scale_factor指定输出为输入的多少倍
self.hd5_UT_hd4_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd4_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4)
# #特征聚合机制
self.conv4d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn4d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu4d_1 = nn.ReLU(inplace=True)
'''stage 3d'''
# h1->320*320, hd3->80*80, Pooling 4 times
self.h1_PT_hd3 = nn.MaxPool2d(4, 4, ceil_mode=True)
self.h1_PT_hd3_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd3_relu = nn.ReLU(inplace=True)
# h2->160*160, hd3->80*80, Pooling 2 times
self.h2_PT_hd3 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h2_PT_hd3_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_PT_hd3_relu = nn.ReLU(inplace=True)
# h3->80*80, hd3->80*80, Concatenation
self.h3_Cat_hd3_conv = nn.Conv2d(filters[2], self.CatChannels, 3, padding=1)
self.h3_Cat_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h3_Cat_hd3_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd4->80*80, Upsample 2 times
self.hd4_UT_hd3 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd4_UT_hd3_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1) #注意此处卷积的输入channels为UpChannels,即Decoder4聚合后的特征通道数量。
self.hd4_UT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd3_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd4->80*80, Upsample 4 times
self.hd5_UT_hd3 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd5_UT_hd3_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd3_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3)
self.conv3d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn3d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu3d_1 = nn.ReLU(inplace=True)
'''stage 2d '''
# h1->320*320, hd2->160*160, Pooling 2 times
self.h1_PT_hd2 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h1_PT_hd2_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd2_relu = nn.ReLU(inplace=True)
# h2->160*160, hd2->160*160, Concatenation
self.h2_Cat_hd2_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_Cat_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_Cat_hd2_relu = nn.ReLU(inplace=True)
# hd3->80*80, hd2->160*160, Upsample 2 times
self.hd3_UT_hd2 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd3_UT_hd2_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd3_UT_hd2_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd2->160*160, Upsample 4 times
self.hd4_UT_hd2 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd4_UT_hd2_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd2_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd2->160*160, Upsample 8 times
self.hd5_UT_hd2 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd5_UT_hd2_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd2_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2)
self.conv2d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn2d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu2d_1 = nn.ReLU(inplace=True)
'''stage 1d'''
# h1->320*320, hd1->320*320, Concatenation
self.h1_Cat_hd1_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_Cat_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_Cat_hd1_relu = nn.ReLU(inplace=True)
# hd2->160*160, hd1->320*320, Upsample 2 times
self.hd2_UT_hd1 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd2_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd2_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd2_UT_hd1_relu = nn.ReLU(inplace=True)
# hd3->80*80, hd1->320*320, Upsample 4 times
self.hd3_UT_hd1 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd3_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd3_UT_hd1_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd1->320*320, Upsample 8 times
self.hd4_UT_hd1 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd4_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd1_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd1->320*320, Upsample 16 times
self.hd5_UT_hd1 = nn.Upsample(scale_factor=16, mode='bilinear') # 14*14
self.hd5_UT_hd1_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd1_relu = nn.ReLU(inplace=True)
# fusion(h1_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1)
self.conv1d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn1d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu1d_1 = nn.ReLU(inplace=True)
# output
self.outconv1 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1) #最后通过3*3卷积,将320通道转为n_classes通道。
# initialise weights
for m in self.modules():
if isinstance(m, nn.Conv2d): #isinstance(object, classes)判断实例object是否为classes类型,是则返回true
init_weights(m, init_type='kaiming') #【理解权重函数??】
elif isinstance(m, nn.BatchNorm2d):
init_weights(m, init_type='kaiming')
def forward(self, inputs):
## -------------Encoder-------------
h1 = self.conv1(inputs) # h1->320*320*64
h2 = self.maxpool1(h1)
h2 = self.conv2(h2) # h2->160*160*128
h3 = self.maxpool2(h2)
h3 = self.conv3(h3) # h3->80*80*256
h4 = self.maxpool3(h3)
h4 = self.conv4(h4) # h4->40*40*512
h5 = self.maxpool4(h4)
hd5 = self.conv5(h5) # h5->20*20*1024
## -------------Decoder-------------
#decoder4
h1_PT_hd4 = self.h1_PT_hd4_relu(self.h1_PT_hd4_bn(self.h1_PT_hd4_conv(self.h1_PT_hd4(h1))))
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h3_PT_hd4 = self.h3_PT_hd4_relu(self.h3_PT_hd4_bn(self.h3_PT_hd4_conv(self.h3_PT_hd4(h3))))
h4_Cat_hd4 = self.h4_Cat_hd4_relu(self.h4_Cat_hd4_bn(self.h4_Cat_hd4_conv(h4)))
hd5_UT_hd4 = self.hd5_UT_hd4_relu(self.hd5_UT_hd4_bn(self.hd5_UT_hd4_conv(self.hd5_UT_hd4(hd5))))
hd4 = self.relu4d_1(self.bn4d_1(self.conv4d_1(
torch.cat((h1_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4), 1)))) # hd4->40*40*UpChannels
#decoder3
h1_PT_hd3 = self.h1_PT_hd3_relu(self.h1_PT_hd3_bn(self.h1_PT_hd3_conv(self.h1_PT_hd3(h1))))
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h3_Cat_hd3 = self.h3_Cat_hd3_relu(self.h3_Cat_hd3_bn(self.h3_Cat_hd3_conv(h3)))
hd4_UT_hd3 = self.hd4_UT_hd3_relu(self.hd4_UT_hd3_bn(self.hd4_UT_hd3_conv(self.hd4_UT_hd3(hd4))))
hd5_UT_hd3 = self.hd5_UT_hd3_relu(self.hd5_UT_hd3_bn(self.hd5_UT_hd3_conv(self.hd5_UT_hd3(hd5))))
hd3 = self.relu3d_1(self.bn3d_1(self.conv3d_1(
torch.cat((h1_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3), 1)))) # hd3->80*80*UpChannels
#decoder2
h1_PT_hd2 = self.h1_PT_hd2_relu(self.h1_PT_hd2_bn(self.h1_PT_hd2_conv(self.h1_PT_hd2(h1))))
h2_Cat_hd2 = self.h2_Cat_hd2_relu(self.h2_Cat_hd2_bn(self.h2_Cat_hd2_conv(h2)))
hd3_UT_hd2 = self.hd3_UT_hd2_relu(self.hd3_UT_hd2_bn(self.hd3_UT_hd2_conv(self.hd3_UT_hd2(hd3))))
hd4_UT_hd2 = self.hd4_UT_hd2_relu(self.hd4_UT_hd2_bn(self.hd4_UT_hd2_conv(self.hd4_UT_hd2(hd4))))
hd5_UT_hd2 = self.hd5_UT_hd2_relu(self.hd5_UT_hd2_bn(self.hd5_UT_hd2_conv(self.hd5_UT_hd2(hd5))))
hd2 = self.relu2d_1(self.bn2d_1(self.conv2d_1(
torch.cat((h1_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2), 1)))) # hd2->160*160*UpChannels
#decoder1
h1_Cat_hd1 = self.h1_Cat_hd1_relu(self.h1_Cat_hd1_bn(self.h1_Cat_hd1_conv(h1)))
hd2_UT_hd1 = self.hd2_UT_hd1_relu(self.hd2_UT_hd1_bn(self.hd2_UT_hd1_conv(self.hd2_UT_hd1(hd2))))
hd3_UT_hd1 = self.hd3_UT_hd1_relu(self.hd3_UT_hd1_bn(self.hd3_UT_hd1_conv(self.hd3_UT_hd1(hd3))))
hd4_UT_hd1 = self.hd4_UT_hd1_relu(self.hd4_UT_hd1_bn(self.hd4_UT_hd1_conv(self.hd4_UT_hd1(hd4))))
hd5_UT_hd1 = self.hd5_UT_hd1_relu(self.hd5_UT_hd1_bn(self.hd5_UT_hd1_conv(self.hd5_UT_hd1(hd5))))
hd1 = self.relu1d_1(self.bn1d_1(self.conv1d_1(
torch.cat((h1_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1), 1)))) # hd1->320*320*UpChannels
#输出
d1 = self.outconv1(hd1) # d1->320*320*n_classes
return F.sigmoid(d1) #输出的结果需要经过sigmoid激活
'''
UNet 3+ with deep supervision
'''
class UNet_3Plus_DeepSup(nn.Module):
def __init__(self, in_channels=3, n_classes=1, feature_scale=4, is_deconv=True, is_batchnorm=True):
super(UNet_3Plus_DeepSup, self).__init__()
self.is_deconv = is_deconv
self.in_channels = in_channels
self.is_batchnorm = is_batchnorm
self.feature_scale = feature_scale
filters = [64, 128, 256, 512, 1024]
## -------------Encoder--------------
self.conv1 = unetConv2(self.in_channels, filters[0], self.is_batchnorm)
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = unetConv2(filters[0], filters[1], self.is_batchnorm)
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = unetConv2(filters[1], filters[2], self.is_batchnorm)
self.maxpool3 = nn.MaxPool2d(kernel_size=2)
self.conv4 = unetConv2(filters[2], filters[3], self.is_batchnorm)
self.maxpool4 = nn.MaxPool2d(kernel_size=2)
self.conv5 = unetConv2(filters[3], filters[4], self.is_batchnorm)
## -------------Decoder--------------
self.CatChannels = filters[0]
self.CatBlocks = 5
self.UpChannels = self.CatChannels * self.CatBlocks
'''stage 4d'''
# h1->320*320, hd4->40*40, Pooling 8 times
self.h1_PT_hd4 = nn.MaxPool2d(8, 8, ceil_mode=True)
self.h1_PT_hd4_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd4_relu = nn.ReLU(inplace=True)
# h2->160*160, hd4->40*40, Pooling 4 times
self.h2_PT_hd4 = nn.MaxPool2d(4, 4, ceil_mode=True)
self.h2_PT_hd4_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_PT_hd4_relu = nn.ReLU(inplace=True)
# h3->80*80, hd4->40*40, Pooling 2 times
self.h3_PT_hd4 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h3_PT_hd4_conv = nn.Conv2d(filters[2], self.CatChannels, 3, padding=1)
self.h3_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h3_PT_hd4_relu = nn.ReLU(inplace=True)
# h4->40*40, hd4->40*40, Concatenation
self.h4_Cat_hd4_conv = nn.Conv2d(filters[3], self.CatChannels, 3, padding=1)
self.h4_Cat_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h4_Cat_hd4_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd4->40*40, Upsample 2 times
self.hd5_UT_hd4 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd5_UT_hd4_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd4_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4)
self.conv4d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn4d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu4d_1 = nn.ReLU(inplace=True)
'''stage 3d'''
# h1->320*320, hd3->80*80, Pooling 4 times
self.h1_PT_hd3 = nn.MaxPool2d(4, 4, ceil_mode=True)
self.h1_PT_hd3_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd3_relu = nn.ReLU(inplace=True)
# h2->160*160, hd3->80*80, Pooling 2 times
self.h2_PT_hd3 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h2_PT_hd3_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_PT_hd3_relu = nn.ReLU(inplace=True)
# h3->80*80, hd3->80*80, Concatenation
self.h3_Cat_hd3_conv = nn.Conv2d(filters[2], self.CatChannels, 3, padding=1)
self.h3_Cat_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h3_Cat_hd3_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd4->80*80, Upsample 2 times
self.hd4_UT_hd3 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd4_UT_hd3_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd3_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd4->80*80, Upsample 4 times
self.hd5_UT_hd3 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd5_UT_hd3_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd3_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3)
self.conv3d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn3d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu3d_1 = nn.ReLU(inplace=True)
'''stage 2d '''
# h1->320*320, hd2->160*160, Pooling 2 times
self.h1_PT_hd2 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h1_PT_hd2_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd2_relu = nn.ReLU(inplace=True)
# h2->160*160, hd2->160*160, Concatenation
self.h2_Cat_hd2_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_Cat_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_Cat_hd2_relu = nn.ReLU(inplace=True)
# hd3->80*80, hd2->160*160, Upsample 2 times
self.hd3_UT_hd2 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd3_UT_hd2_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd3_UT_hd2_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd2->160*160, Upsample 4 times
self.hd4_UT_hd2 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd4_UT_hd2_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd2_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd2->160*160, Upsample 8 times
self.hd5_UT_hd2 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd5_UT_hd2_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd2_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2)
self.conv2d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn2d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu2d_1 = nn.ReLU(inplace=True)
'''stage 1d'''
# h1->320*320, hd1->320*320, Concatenation
self.h1_Cat_hd1_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_Cat_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_Cat_hd1_relu = nn.ReLU(inplace=True)
# hd2->160*160, hd1->320*320, Upsample 2 times
self.hd2_UT_hd1 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd2_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd2_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd2_UT_hd1_relu = nn.ReLU(inplace=True)
# hd3->80*80, hd1->320*320, Upsample 4 times
self.hd3_UT_hd1 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd3_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd3_UT_hd1_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd1->320*320, Upsample 8 times
self.hd4_UT_hd1 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd4_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd1_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd1->320*320, Upsample 16 times
self.hd5_UT_hd1 = nn.Upsample(scale_factor=16, mode='bilinear') # 14*14
self.hd5_UT_hd1_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd1_relu = nn.ReLU(inplace=True)
# fusion(h1_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1)
self.conv1d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn1d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu1d_1 = nn.ReLU(inplace=True)
# -------------Bilinear Upsampling-------------- #双线性上采样【什么地方用到了??】
self.upscore6 = nn.Upsample(scale_factor=32,mode='bilinear')###该函数没用,应该是作者多写了。
self.upscore5 = nn.Upsample(scale_factor=16,mode='bilinear') #scale_factor处理,是为了让输出的特征图和第一层的特征图尺寸相同。
self.upscore4 = nn.Upsample(scale_factor=8,mode='bilinear')
self.upscore3 = nn.Upsample(scale_factor=4,mode='bilinear')
self.upscore2 = nn.Upsample(scale_factor=2, mode='bilinear')
# DeepSup #深监督:将decoder的最后一层进行conv3*3,bilinear upsampling, sigmoid
self.outconv1 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv2 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv3 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv4 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv5 = nn.Conv2d(filters[4], n_classes, 3, padding=1)
# initialise weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
init_weights(m, init_type='kaiming')
elif isinstance(m, nn.BatchNorm2d):
init_weights(m, init_type='kaiming')
def forward(self, inputs):
## -------------Encoder-------------
h1 = self.conv1(inputs) # h1->320*320*64
h2 = self.maxpool1(h1)
h2 = self.conv2(h2) # h2->160*160*128
h3 = self.maxpool2(h2)
h3 = self.conv3(h3) # h3->80*80*256
h4 = self.maxpool3(h3)
h4 = self.conv4(h4) # h4->40*40*512
h5 = self.maxpool4(h4)
hd5 = self.conv5(h5) # h5->20*20*1024
## -------------Decoder-------------
#decoder4
h1_PT_hd4 = self.h1_PT_hd4_relu(self.h1_PT_hd4_bn(self.h1_PT_hd4_conv(self.h1_PT_hd4(h1)))) #与encoder1连接,relu( bn( conv( maxpool( h1 ) ) ) )
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2)))) #与encoder2连接
h3_PT_hd4 = self.h3_PT_hd4_relu(self.h3_PT_hd4_bn(self.h3_PT_hd4_conv(self.h3_PT_hd4(h3)))) #与encoder3连接
h4_Cat_hd4 = self.h4_Cat_hd4_relu(self.h4_Cat_hd4_bn(self.h4_Cat_hd4_conv(h4))) #同层连接-与encoder4连接,relu( bn( conv( h4 ) ) )
hd5_UT_hd4 = self.hd5_UT_hd4_relu(self.hd5_UT_hd4_bn(self.hd5_UT_hd4_conv(self.hd5_UT_hd4(hd5)))) #与decoder5连接,relu( bn( conv( upsample ) ) )
hd4 = self.relu4d_1(self.bn4d_1(self.conv4d_1(
torch.cat((h1_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4), 1)))) # hd4->40*40*UpChannels #特征聚合机制 relu( bn( conv( cat( 五个特征图 ) ) ) ) , 1表示按维度1拼接,即按行拼接。
#decoder3
h1_PT_hd3 = self.h1_PT_hd3_relu(self.h1_PT_hd3_bn(self.h1_PT_hd3_conv(self.h1_PT_hd3(h1))))
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h3_Cat_hd3 = self.h3_Cat_hd3_relu(self.h3_Cat_hd3_bn(self.h3_Cat_hd3_conv(h3)))
hd4_UT_hd3 = self.hd4_UT_hd3_relu(self.hd4_UT_hd3_bn(self.hd4_UT_hd3_conv(self.hd4_UT_hd3(hd4))))
hd5_UT_hd3 = self.hd5_UT_hd3_relu(self.hd5_UT_hd3_bn(self.hd5_UT_hd3_conv(self.hd5_UT_hd3(hd5))))
hd3 = self.relu3d_1(self.bn3d_1(self.conv3d_1(
torch.cat((h1_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3), 1)))) # hd3->80*80*UpChannels
#decoder2
h1_PT_hd2 = self.h1_PT_hd2_relu(self.h1_PT_hd2_bn(self.h1_PT_hd2_conv(self.h1_PT_hd2(h1))))
h2_Cat_hd2 = self.h2_Cat_hd2_relu(self.h2_Cat_hd2_bn(self.h2_Cat_hd2_conv(h2)))
hd3_UT_hd2 = self.hd3_UT_hd2_relu(self.hd3_UT_hd2_bn(self.hd3_UT_hd2_conv(self.hd3_UT_hd2(hd3))))
hd4_UT_hd2 = self.hd4_UT_hd2_relu(self.hd4_UT_hd2_bn(self.hd4_UT_hd2_conv(self.hd4_UT_hd2(hd4))))
hd5_UT_hd2 = self.hd5_UT_hd2_relu(self.hd5_UT_hd2_bn(self.hd5_UT_hd2_conv(self.hd5_UT_hd2(hd5))))
hd2 = self.relu2d_1(self.bn2d_1(self.conv2d_1(
torch.cat((h1_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2), 1)))) # hd2->160*160*UpChannels
#decoder1
h1_Cat_hd1 = self.h1_Cat_hd1_relu(self.h1_Cat_hd1_bn(self.h1_Cat_hd1_conv(h1)))
hd2_UT_hd1 = self.hd2_UT_hd1_relu(self.hd2_UT_hd1_bn(self.hd2_UT_hd1_conv(self.hd2_UT_hd1(hd2))))
hd3_UT_hd1 = self.hd3_UT_hd1_relu(self.hd3_UT_hd1_bn(self.hd3_UT_hd1_conv(self.hd3_UT_hd1(hd3))))
hd4_UT_hd1 = self.hd4_UT_hd1_relu(self.hd4_UT_hd1_bn(self.hd4_UT_hd1_conv(self.hd4_UT_hd1(hd4))))
hd5_UT_hd1 = self.hd5_UT_hd1_relu(self.hd5_UT_hd1_bn(self.hd5_UT_hd1_conv(self.hd5_UT_hd1(hd5))))
hd1 = self.relu1d_1(self.bn1d_1(self.conv1d_1(
torch.cat((h1_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1), 1)))) # hd1->320*320*UpChannels
#深监督:将每个decoder的最后一层进行conv3*3,bilinear upsampling, sigmoid
#decoder5的深监督
d5 = self.outconv5(hd5) #conv3*3
d5 = self.upscore5(d5) # 16->256 #bilinear upsampling
#decoder4的深监督
d4 = self.outconv4(hd4)
d4 = self.upscore4(d4) # 32->256
#decoder3的深监督
d3 = self.outconv3(hd3)
d3 = self.upscore3(d3) # 64->256
#decoder2的深监督
d2 = self.outconv2(hd2)
d2 = self.upscore2(d2) # 128->256
#decoder1的深监督
d1 = self.outconv1(hd1) # 256 #decoder1不做上采样处理
return F.sigmoid(d1), F.sigmoid(d2), F.sigmoid(d3), F.sigmoid(d4), F.sigmoid(d5) #将深监督的结果进行sigmoid,做最后处理。
'''
UNet 3+ with deep supervision and class-guided module
'''
class UNet_3Plus_DeepSup_CGM(nn.Module):
def __init__(self, in_channels=3, n_classes=1, feature_scale=4, is_deconv=True, is_batchnorm=True):
super(UNet_3Plus_DeepSup_CGM, self).__init__()
self.is_deconv = is_deconv #【什么地方用到了??】
self.in_channels = in_channels
self.is_batchnorm = is_batchnorm
self.feature_scale = feature_scale ##【什么地方用到了??】
filters = [64, 128, 256, 512, 1024]
## -------------Encoder--------------
self.conv1 = unetConv2(self.in_channels, filters[0], self.is_batchnorm)
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = unetConv2(filters[0], filters[1], self.is_batchnorm)
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = unetConv2(filters[1], filters[2], self.is_batchnorm)
self.maxpool3 = nn.MaxPool2d(kernel_size=2)
self.conv4 = unetConv2(filters[2], filters[3], self.is_batchnorm)
self.maxpool4 = nn.MaxPool2d(kernel_size=2)
self.conv5 = unetConv2(filters[3], filters[4], self.is_batchnorm)
## -------------Decoder--------------
self.CatChannels = filters[0]
self.CatBlocks = 5
self.UpChannels = self.CatChannels * self.CatBlocks
'''stage 4d'''
# h1->320*320, hd4->40*40, Pooling 8 times
self.h1_PT_hd4 = nn.MaxPool2d(8, 8, ceil_mode=True)
self.h1_PT_hd4_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd4_relu = nn.ReLU(inplace=True)
# h2->160*160, hd4->40*40, Pooling 4 times
self.h2_PT_hd4 = nn.MaxPool2d(4, 4, ceil_mode=True)
self.h2_PT_hd4_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_PT_hd4_relu = nn.ReLU(inplace=True)
# h3->80*80, hd4->40*40, Pooling 2 times
self.h3_PT_hd4 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h3_PT_hd4_conv = nn.Conv2d(filters[2], self.CatChannels, 3, padding=1)
self.h3_PT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h3_PT_hd4_relu = nn.ReLU(inplace=True)
# h4->40*40, hd4->40*40, Concatenation
self.h4_Cat_hd4_conv = nn.Conv2d(filters[3], self.CatChannels, 3, padding=1)
self.h4_Cat_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.h4_Cat_hd4_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd4->40*40, Upsample 2 times
self.hd5_UT_hd4 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd5_UT_hd4_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd4_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd4_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4)
self.conv4d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn4d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu4d_1 = nn.ReLU(inplace=True)
'''stage 3d'''
# h1->320*320, hd3->80*80, Pooling 4 times
self.h1_PT_hd3 = nn.MaxPool2d(4, 4, ceil_mode=True)
self.h1_PT_hd3_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd3_relu = nn.ReLU(inplace=True)
# h2->160*160, hd3->80*80, Pooling 2 times
self.h2_PT_hd3 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h2_PT_hd3_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_PT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_PT_hd3_relu = nn.ReLU(inplace=True)
# h3->80*80, hd3->80*80, Concatenation
self.h3_Cat_hd3_conv = nn.Conv2d(filters[2], self.CatChannels, 3, padding=1)
self.h3_Cat_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.h3_Cat_hd3_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd4->80*80, Upsample 2 times
self.hd4_UT_hd3 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd4_UT_hd3_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd3_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd4->80*80, Upsample 4 times
self.hd5_UT_hd3 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd5_UT_hd3_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd3_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd3_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3)
self.conv3d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn3d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu3d_1 = nn.ReLU(inplace=True)
'''stage 2d '''
# h1->320*320, hd2->160*160, Pooling 2 times
self.h1_PT_hd2 = nn.MaxPool2d(2, 2, ceil_mode=True)
self.h1_PT_hd2_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_PT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_PT_hd2_relu = nn.ReLU(inplace=True)
# h2->160*160, hd2->160*160, Concatenation
self.h2_Cat_hd2_conv = nn.Conv2d(filters[1], self.CatChannels, 3, padding=1)
self.h2_Cat_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.h2_Cat_hd2_relu = nn.ReLU(inplace=True)
# hd3->80*80, hd2->160*160, Upsample 2 times
self.hd3_UT_hd2 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd3_UT_hd2_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd3_UT_hd2_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd2->160*160, Upsample 4 times
self.hd4_UT_hd2 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd4_UT_hd2_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd2_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd2->160*160, Upsample 8 times
self.hd5_UT_hd2 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd5_UT_hd2_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd2_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd2_relu = nn.ReLU(inplace=True)
# fusion(h1_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2)
self.conv2d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn2d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu2d_1 = nn.ReLU(inplace=True)
'''stage 1d'''
# h1->320*320, hd1->320*320, Concatenation
self.h1_Cat_hd1_conv = nn.Conv2d(filters[0], self.CatChannels, 3, padding=1)
self.h1_Cat_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.h1_Cat_hd1_relu = nn.ReLU(inplace=True)
# hd2->160*160, hd1->320*320, Upsample 2 times
self.hd2_UT_hd1 = nn.Upsample(scale_factor=2, mode='bilinear') # 14*14
self.hd2_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd2_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd2_UT_hd1_relu = nn.ReLU(inplace=True)
# hd3->80*80, hd1->320*320, Upsample 4 times
self.hd3_UT_hd1 = nn.Upsample(scale_factor=4, mode='bilinear') # 14*14
self.hd3_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd3_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd3_UT_hd1_relu = nn.ReLU(inplace=True)
# hd4->40*40, hd1->320*320, Upsample 8 times
self.hd4_UT_hd1 = nn.Upsample(scale_factor=8, mode='bilinear') # 14*14
self.hd4_UT_hd1_conv = nn.Conv2d(self.UpChannels, self.CatChannels, 3, padding=1)
self.hd4_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd4_UT_hd1_relu = nn.ReLU(inplace=True)
# hd5->20*20, hd1->320*320, Upsample 16 times
self.hd5_UT_hd1 = nn.Upsample(scale_factor=16, mode='bilinear') # 14*14
self.hd5_UT_hd1_conv = nn.Conv2d(filters[4], self.CatChannels, 3, padding=1)
self.hd5_UT_hd1_bn = nn.BatchNorm2d(self.CatChannels)
self.hd5_UT_hd1_relu = nn.ReLU(inplace=True)
# fusion(h1_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1)
self.conv1d_1 = nn.Conv2d(self.UpChannels, self.UpChannels, 3, padding=1) # 16
self.bn1d_1 = nn.BatchNorm2d(self.UpChannels)
self.relu1d_1 = nn.ReLU(inplace=True)
# -------------Bilinear Upsampling--------------
self.upscore6 = nn.Upsample(scale_factor=32,mode='bilinear')###
self.upscore5 = nn.Upsample(scale_factor=16,mode='bilinear')
self.upscore4 = nn.Upsample(scale_factor=8,mode='bilinear')
self.upscore3 = nn.Upsample(scale_factor=4,mode='bilinear')
self.upscore2 = nn.Upsample(scale_factor=2, mode='bilinear')
# DeepSup
self.outconv1 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv2 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv3 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv4 = nn.Conv2d(self.UpChannels, n_classes, 3, padding=1)
self.outconv5 = nn.Conv2d(filters[4], n_classes, 3, padding=1)
#分类指引,仅用于encoder5
self.cls = nn.Sequential(
nn.Dropout(p=0.5), #p为不保留节点数的比例。
nn.Conv2d(filters[4], 2, 1), #Conv2d的参数:输入的特征通道,卷积核尺寸,步长
nn.AdaptiveMaxPool2d(1), #自适应最大池化,参数为(H,W)或只有一个H,表示输出信号的尺寸。输出的尺寸不变,后两个维度变为参数大小。
nn.Sigmoid())
# initialise weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
init_weights(m, init_type='kaiming')
elif isinstance(m, nn.BatchNorm2d):
init_weights(m, init_type='kaiming')
#将分割结果与分类二维矩阵进行相乘,返回四维乘积结果。
def dotProduct(self,seg,cls):
B, N, H, W = seg.size() #seg是传入的深度卷积结果,是矩阵。
seg = seg.view(B, N, H * W) #view和reshape作用一样,重新定义矩阵的性状。
final = torch.einsum("ijk,ij->ijk", [seg, cls]) #利用爱因斯坦求和约定方法求乘积的和。
final = final.view(B, N, H, W)
return final
def forward(self, inputs):
## -------------Encoder-------------
h1 = self.conv1(inputs) # h1->320*320*64
h2 = self.maxpool1(h1)
h2 = self.conv2(h2) # h2->160*160*128
h3 = self.maxpool2(h2)
h3 = self.conv3(h3) # h3->80*80*256
h4 = self.maxpool3(h3)
h4 = self.conv4(h4) # h4->40*40*512
h5 = self.maxpool4(h4)
hd5 = self.conv5(h5) # h5->20*20*1024
# -------------Classification-------------
#对encoder5做分类处理
cls_branch = self.cls(hd5).squeeze(3).squeeze(2) # (B,N,1,1)->(B,N) #操作(dropout, conv1*1, adaptiveMaxPool, Sigmoid)后,产生一个二维张量 squeeze(x)只有当维度x的值为1时,才能去掉该维度。
cls_branch_max = cls_branch.argmax(dim=1) #dim=1将1维去掉,返回最大值对应的索引。 通过argmax,分类结果被转为一个单一数字输出。 #argmax(a, axis=None, out=Nont):a为输入的数组;axis=0按列寻找,axis=1按行寻找最大值对应的索引;out结果将被插入到a中。
cls_branch_max = cls_branch_max[:, np.newaxis].float() #在np.newaxis的位置增加一个维度,故此时是增加一个列维度。
## -------------Decoder-------------
h1_PT_hd4 = self.h1_PT_hd4_relu(self.h1_PT_hd4_bn(self.h1_PT_hd4_conv(self.h1_PT_hd4(h1))))
h2_PT_hd4 = self.h2_PT_hd4_relu(self.h2_PT_hd4_bn(self.h2_PT_hd4_conv(self.h2_PT_hd4(h2))))
h3_PT_hd4 = self.h3_PT_hd4_relu(self.h3_PT_hd4_bn(self.h3_PT_hd4_conv(self.h3_PT_hd4(h3))))
h4_Cat_hd4 = self.h4_Cat_hd4_relu(self.h4_Cat_hd4_bn(self.h4_Cat_hd4_conv(h4)))
hd5_UT_hd4 = self.hd5_UT_hd4_relu(self.hd5_UT_hd4_bn(self.hd5_UT_hd4_conv(self.hd5_UT_hd4(hd5))))
hd4 = self.relu4d_1(self.bn4d_1(self.conv4d_1(
torch.cat((h1_PT_hd4, h2_PT_hd4, h3_PT_hd4, h4_Cat_hd4, hd5_UT_hd4), 1)))) # hd4->40*40*UpChannels #1表示按维度1拼接,即按列拼接,即列变多。
h1_PT_hd3 = self.h1_PT_hd3_relu(self.h1_PT_hd3_bn(self.h1_PT_hd3_conv(self.h1_PT_hd3(h1))))
h2_PT_hd3 = self.h2_PT_hd3_relu(self.h2_PT_hd3_bn(self.h2_PT_hd3_conv(self.h2_PT_hd3(h2))))
h3_Cat_hd3 = self.h3_Cat_hd3_relu(self.h3_Cat_hd3_bn(self.h3_Cat_hd3_conv(h3)))
hd4_UT_hd3 = self.hd4_UT_hd3_relu(self.hd4_UT_hd3_bn(self.hd4_UT_hd3_conv(self.hd4_UT_hd3(hd4))))
hd5_UT_hd3 = self.hd5_UT_hd3_relu(self.hd5_UT_hd3_bn(self.hd5_UT_hd3_conv(self.hd5_UT_hd3(hd5))))
hd3 = self.relu3d_1(self.bn3d_1(self.conv3d_1(
torch.cat((h1_PT_hd3, h2_PT_hd3, h3_Cat_hd3, hd4_UT_hd3, hd5_UT_hd3), 1)))) # hd3->80*80*UpChannels
h1_PT_hd2 = self.h1_PT_hd2_relu(self.h1_PT_hd2_bn(self.h1_PT_hd2_conv(self.h1_PT_hd2(h1))))
h2_Cat_hd2 = self.h2_Cat_hd2_relu(self.h2_Cat_hd2_bn(self.h2_Cat_hd2_conv(h2)))
hd3_UT_hd2 = self.hd3_UT_hd2_relu(self.hd3_UT_hd2_bn(self.hd3_UT_hd2_conv(self.hd3_UT_hd2(hd3))))
hd4_UT_hd2 = self.hd4_UT_hd2_relu(self.hd4_UT_hd2_bn(self.hd4_UT_hd2_conv(self.hd4_UT_hd2(hd4))))
hd5_UT_hd2 = self.hd5_UT_hd2_relu(self.hd5_UT_hd2_bn(self.hd5_UT_hd2_conv(self.hd5_UT_hd2(hd5))))
hd2 = self.relu2d_1(self.bn2d_1(self.conv2d_1(
torch.cat((h1_PT_hd2, h2_Cat_hd2, hd3_UT_hd2, hd4_UT_hd2, hd5_UT_hd2), 1)))) # hd2->160*160*UpChannels
h1_Cat_hd1 = self.h1_Cat_hd1_relu(self.h1_Cat_hd1_bn(self.h1_Cat_hd1_conv(h1)))
hd2_UT_hd1 = self.hd2_UT_hd1_relu(self.hd2_UT_hd1_bn(self.hd2_UT_hd1_conv(self.hd2_UT_hd1(hd2))))
hd3_UT_hd1 = self.hd3_UT_hd1_relu(self.hd3_UT_hd1_bn(self.hd3_UT_hd1_conv(self.hd3_UT_hd1(hd3))))
hd4_UT_hd1 = self.hd4_UT_hd1_relu(self.hd4_UT_hd1_bn(self.hd4_UT_hd1_conv(self.hd4_UT_hd1(hd4))))
hd5_UT_hd1 = self.hd5_UT_hd1_relu(self.hd5_UT_hd1_bn(self.hd5_UT_hd1_conv(self.hd5_UT_hd1(hd5))))
hd1 = self.relu1d_1(self.bn1d_1(self.conv1d_1(
torch.cat((h1_Cat_hd1, hd2_UT_hd1, hd3_UT_hd1, hd4_UT_hd1, hd5_UT_hd1), 1)))) # hd1->320*320*UpChannels
#做深监督处理
d5 = self.outconv5(hd5)
d5 = self.upscore5(d5) # 16->256
d4 = self.outconv4(hd4)
d4 = self.upscore4(d4) # 32->256
d3 = self.outconv3(hd3)
d3 = self.upscore3(d3) # 64->256
d2 = self.outconv2(hd2)
d2 = self.upscore2(d2) # 128->256
d1 = self.outconv1(hd1) # 256
#将每个decoder的分割结果与分类结果相乘,返回计算后的四维矩阵。
d1 = self.dotProduct(d1, cls_branch_max) #d1为深监督中的卷积结果,为矩阵;cls_branch_max:float类型,为分类结果。
d2 = self.dotProduct(d2, cls_branch_max)
d3 = self.dotProduct(d3, cls_branch_max)
d4 = self.dotProduct(d4, cls_branch_max)
d5 = self.dotProduct(d5, cls_branch_max)
return F.sigmoid(d1), F.sigmoid(d2), F.sigmoid(d3), F.sigmoid(d4), F.sigmoid(d5) #sigmoid进行回归,将结果回归到0-1之间。
(2) layers.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from init_weights import init_weights
#获得两个卷积后的结果
class unetConv2(nn.Module):
def __init__(self, in_size, out_size, is_batchnorm, n=2, ks=3, stride=1, padding=1): #is_batchnorm卷积后是否做归一化处理
super(unetConv2, self).__init__()
self.n = n
self.ks = ks
self.stride = stride
self.padding = padding
s = stride
p = padding
if is_batchnorm: #卷积后,做数据归一化处理
for i in range(1, n + 1): #range(start, stop, step)计数迭代的过程中不包括stop
conv = nn.Sequential(nn.Conv2d(in_size, out_size, ks, s, p),
nn.BatchNorm2d(out_size),
nn.ReLU(inplace=True), )
setattr(self, 'conv%d' % i, conv)
in_size = out_size
else: #卷积后不做数据归一化处理,可能会出现卷积得到的数据过大,导致ReLU的网络性能不稳定
for i in range(1, n + 1):
conv = nn.Sequential(nn.Conv2d(in_size, out_size, ks, s, p),
nn.ReLU(inplace=True), )
setattr(self, 'conv%d' % i, conv)
in_size = out_size
# initialise the blocks #自定义参数初始化方法
for m in self.children(): #children包括net的方法
init_weights(m, init_type='kaiming') #意思是给网络的每一层赋予权重
def forward(self, inputs): #返回每一个编码模块的结果
x = inputs
for i in range(1, self.n + 1): #n表示卷积层的个数,为2
conv = getattr(self, 'conv%d' % i)
x = conv(x)
return x
class unetUp(nn.Module):
def __init__(self, in_size, out_size, is_deconv, n_concat=2):
super(unetUp, self).__init__()
# self.conv = unetConv2(in_size + (n_concat - 2) * out_size, out_size, False)
self.conv = unetConv2(out_size*2, out_size, False)
if is_deconv:
self.up = nn.ConvTranspose2d(in_size, out_size, kernel_size=4, stride=2, padding=1)
else:
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
# initialise the blocks
for m in self.children():
if m.__class__.__name__.find('unetConv2') != -1: continue
init_weights(m, init_type='kaiming')
def forward(self, inputs0, *input):
# print(self.n_concat)
# print(input)
outputs0 = self.up(inputs0)
for i in range(len(input)):
outputs0 = torch.cat([outputs0, input[i]], 1)
return self.conv(outputs0)
class unetUp_origin(nn.Module):
def __init__(self, in_size, out_size, is_deconv, n_concat=2):
super(unetUp_origin, self).__init__()
# self.conv = unetConv2(out_size*2, out_size, False)
if is_deconv:
self.conv = unetConv2(in_size + (n_concat - 2) * out_size, out_size, False)
self.up = nn.ConvTranspose2d(in_size, out_size, kernel_size=4, stride=2, padding=1)
else:
self.conv = unetConv2(in_size + (n_concat - 2) * out_size, out_size, False)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
# initialise the blocks
for m in self.children():
if m.__class__.__name__.find('unetConv2') != -1: continue
init_weights(m, init_type='kaiming')
def forward(self, inputs0, *input):
# print(self.n_concat)
# print(input)
outputs0 = self.up(inputs0)
for i in range(len(input)):
outputs0 = torch.cat([outputs0, input[i]], 1)
return self.conv(outputs0)
(3) init_weights.py
此部分本人没再添加多余解释。
import torch
import torch.nn as nn
from torch.nn import init
def weights_init_normal(m):
classname = m.__class__.__name__
#print(classname)
if classname.find('Conv') != -1:
init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('Linear') != -1:
init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
init.normal_(m.weight.data, 1.0, 0.02)
init.constant_(m.bias.data, 0.0)
def weights_init_xavier(m):
classname = m.__class__.__name__
#print(classname)
if classname.find('Conv') != -1:
init.xavier_normal_(m.weight.data, gain=1)
elif classname.find('Linear') != -1:
init.xavier_normal_(m.weight.data, gain=1)
elif classname.find('BatchNorm') != -1:
init.normal_(m.weight.data, 1.0, 0.02)
init.constant_(m.bias.data, 0.0)
def weights_init_kaiming(m):
classname = m.__class__.__name__
#print(classname)
if classname.find('Conv') != -1:
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif classname.find('Linear') != -1:
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif classname.find('BatchNorm') != -1:
init.normal_(m.weight.data, 1.0, 0.02)
init.constant_(m.bias.data, 0.0)
def weights_init_orthogonal(m):
classname = m.__class__.__name__
#print(classname)
if classname.find('Conv') != -1:
init.orthogonal_(m.weight.data, gain=1)
elif classname.find('Linear') != -1:
init.orthogonal_(m.weight.data, gain=1)
elif classname.find('BatchNorm') != -1:
init.normal_(m.weight.data, 1.0, 0.02)
init.constant_(m.bias.data, 0.0)
def init_weights(net, init_type='normal'):
#print('initialization method [%s]' % init_type)
if init_type == 'normal':
net.apply(weights_init_normal)
elif init_type == 'xavier':
net.apply(weights_init_xavier)
elif init_type == 'kaiming':
net.apply(weights_init_kaiming)
elif init_type == 'orthogonal':
net.apply(weights_init_orthogonal)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
(4) bceLoss.py
import torch
import torch.nn as nn
#二进制交叉熵损失函数
def BCE_loss(pred,label):
bce_loss = nn.BCELoss(size_average=True) #nn.BCELoss()计算目标值与测试值之间的二进制交叉熵损失函数。 size_average求平均。
bce_out = bce_loss(pred, label)
print("bce_loss:", bce_out.data.cpu().numpy())
return bce_out
(5) iouLoss.py
import torch
def _iou(pred, target, size_average = True):
b = pred.shape[0]
IoU = 0.0
for i in range(0,b):
#compute the IoU of the foreground
Iand1 = torch.sum(target[i,:,:,:]*pred[i,:,:,:]) #交
Ior1 = torch.sum(target[i,:,:,:]) + torch.sum(pred[i,:,:,:])-Iand1 #并
IoU1 = Iand1/Ior1 #交并比
#IoU loss is (1-IoU1) #交并比的损失:1-IoU
IoU = IoU + (1-IoU1)
return IoU/b #返回交并比的平均值作为交并比
class IOU(torch.nn.Module):
def __init__(self, size_average=True):
super(IOU, self).__init__()
self.size_average = size_average
def forward(self, pred, target):
return _iou(pred, target, self.size_average) #size_average即对结果求平均值。
def IOU_loss(pred,label):
iou_loss = IOU(size_average=True)
iou_out = iou_loss(pred, label)
print("iou_loss:", iou_out.data.cpu().numpy())
return iou_out
(6) msssimLoss.py
import torch
import torch.nn.functional as F
from math import exp
import numpy as np
#高斯滤波器的正态分布,window_size是位置参数,决定分布的位置;sigma是尺度参数,决定分布的幅度。
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)]) #双星号:幂的意思。 双//:表示向下取整,有一方是float型时,结果为float。 exp()返回e的x次方。
return gauss/gauss.sum()
def create_window(window_size, channel=1):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1) #unsqueeze(x)增加维度x
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0) #t() 将tensor进行转置。 x.mm(self.y) 将x与y相乘。
window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()
return window
#返回的均值。
def ssim(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):
#求像素的动态范围
# Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).
if val_range is None:
if torch.max(img1) > 128:
max_val = 255
else:
max_val = 1
if torch.min(img1) < -0.5:
min_val = -1
else:
min_val = 0
L = max_val - min_val
else:
L = val_range
#求img1,img2的均值。
padd = 0
(_, channel, height, width) = img1.size() # _ 为批次batch大小。
#定义卷积核window
if window is None:
real_size = min(window_size, height, width) #求最小值,是为了保证卷积核尺寸和img1,img2尺寸相同。
window = create_window(real_size, channel=channel).to(img1.device)
#空洞卷积:有groups代表是空洞卷积; F.conv2d(输入图像tensor,卷积核tensor, ...)是卷积操作。
#mu1为img1的均值;mu2为img2的均值。
mu1 = F.conv2d(img1, window, padding=padd, groups=channel) #groups控制分组卷积,默认不分组,即为1. delition默认为1.
mu2 = F.conv2d(img2, window, padding=padd, groups=channel) #conv2d输出的是一个tensor-新的feature map。
#mu1_sq:img1均值的平方。 mu2_sq:img2均值的平方
mu1_sq = mu1.pow(2) #对mu1中的元素逐个2次幂计算。
mu2_sq = mu2.pow(2)
#img1,img2均值的乘积。
mu1_mu2 = mu1 * mu2
#x的方差σx²
sigma1_sq = F.conv2d(img1 * img1, window, padding=padd, groups=channel) - mu1_sq
#y的方差σy²
sigma2_sq = F.conv2d(img2 * img2, window, padding=padd, groups=channel) - mu2_sq
#求x,y的协方差σxy
sigma12 = F.conv2d(img1 * img2, window, padding=padd, groups=channel) - mu1_mu2
#维持稳定的两个变量
C1 = (0.01 * L) ** 2
C2 = (0.03 * L) ** 2
#v1:2σxy+C2
v1 = 2.0 * sigma12 + C2
#v2:σx²+σy²+C2
v2 = sigma1_sq + sigma2_sq + C2
cs = torch.mean(v1 / v2) # contrast sensitivity #对比敏感度
#ssim_map为img1,img2的相似性指数。
ssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)
#求平均相似性指数。 ??
if size_average: #要求平均时
ret = ssim_map.mean()
else: #不要求平均时
ret = ssim_map.mean(1).mean(1).mean(1) #mean(1) 求维度1的平均值
if full:
return ret, cs
return ret
def msssim(img1, img2, window_size=11, size_average=True, val_range=None, normalize=False):
device = img1.device
weights = torch.FloatTensor([0.0448, 0.2856, 0.3001, 0.2363, 0.1333]).to(device) #to(device)使用GPU运算
# weights = torch.FloatTensor([0.0448, 0.2856, 0.3001, 0.2363, 0.1333])
levels = weights.size()[0]
mssim = [] #存放每一尺度的ssim的平均值
mcs = [] #存放每一尺度的cs的平均值
#将img1,img2两张图像分为levels个小窗口,求每对小窗口的SSIM
for _ in range(levels):
#求每一对小窗口的结构相似性指数(SSIM)
sim, cs = ssim(img1, img2, window_size=window_size, size_average=size_average, full=True, val_range=val_range)
print("sim", sim)
mssim.append(sim)
mcs.append(cs)
#以求最大池的方式移动图像img1, img2的位置
img1 = F.avg_pool2d(img1, (2, 2)) #平均池化。 (2,2):stride横向、纵向都步长为2.
img2 = F.avg_pool2d(img2, (2, 2))
mssim = torch.stack(mssim) #torch.stack()保留序列、张量矩阵信息,将一个个张量按照时间序列排序,拼接成一个三维立体。 扩张维度。
mcs = torch.stack(mcs)
#避免当两张图像都有非常小的MS-SSIM时,无法继续训练。
# Normalize (to avoid NaNs during training unstable models, not compliant with original definition)
if normalize:
mssim = (mssim + 1) / 2 #mssim+1: 将mmsim中的每个元素都加1.
mcs = (mcs + 1) / 2
pow1 = mcs ** weights
pow2 = mssim ** weights
# From Matlab implementation https://ece.uwaterloo.ca/~z70wang/research/iwssim/
output = torch.prod(pow1[:-1] * pow2[-1]) #pow1的所有行列 * pow2改成一串。 返回输入tensor的所有原始的乘积
return output
#Structural similarity index 结构相似性指标
# Classes to re-use window
class SSIM(torch.nn.Module):
def __init__(self, window_size=11, size_average=True, val_range=None):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.val_range = val_range
# Assume 1 channel for SSIM #assume:假定
self.channel = 1
self.window = create_window(window_size)
def forward(self, img1, img2):
(_, channel, _, _) = img1.size()
if channel == self.channel and self.window.dtype == img1.dtype:
window = self.window
else:
window = create_window(self.window_size, channel).to(img1.device).type(img1.dtype)
self.window = window
self.channel = channel
return ssim(img1, img2, window=window, window_size=self.window_size, size_average=self.size_average)
#多尺度结构相似性
class MSSSIM(torch.nn.Module):
def __init__(self, window_size=11, size_average=True, channel=3): #size_average求出每个小窗口的相似性后,要计算所有窗口相似性的平均值,作为整个图像的相似性指标。
super(MSSSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.channel = channel
def forward(self, img1, img2):
# TODO: store window between calls if possible,
# return msssim(img1, img2, window_size=self.window_size, size_average=self.size_average)
return msssim(img1, img2, window_size=self.window_size, size_average=self.size_average, normalize=True)