机器学习---sklearn

1.Sklearn简介
sklearn (全称 Scikit-Learn) 是基于 Python 语言的机器学习工具,Sklea是处理机器学习 (有监督学习和无监督学习) 的包。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上,其主要集成了数据预处理、数据特征选择,sklearn有六个任务模块和一个数据引入模块:
- 有监督学习的分类任务
- 有监督学习的回归任务
- 无监督学习的聚类任务
- 无监督学习的降维任务
- 数据预处理任务
- 模型选择任务
- 数据引入
具体流程如下:
 下载 sklearn。
下载 sklearn。
// 已经下载过Anaconda
conda install scikit-learn
2.Sklearn数据
2.1 数据格式
在 Sklean 里,模型能即用的数据有两种形式:
- Numpy 二维数组 (ndarray) 的稠密数据 (dense data),通常都是这种格式。
- SciPy 矩阵 (scipy.sparse.matrix) 的稀疏数据 (sparse data),比如文本分析每个单词 (字典有 100000 个词) 做独热编码得到矩阵有很多 0,这时用 ndarray 就不合适了,太耗内存。
上述数据在机器学习中通常用符号 X 表示,是模型自变量。它的大小 = [样本数, 特征数],有监督学习除了需要特征 X 还需要标签 y,而 y 通常就是 Numpy 一维数组,无监督学习没有 y。
2.2 自带数据集

引入数据集的方法:
- 获取小数据:load_dataname
- 获取大数据:fetch_dataname
- 构造随机数据:make_dataname
Load一个数字小数据集 digits
digits=datasets.load_digits()
digits.keys()
![]()
Fetch 一个加州房屋大数据集 california_housing
housing=datasets.fetch_california_housing()
housing.keys()
![]()
Make 一个高斯分位数数据集 gaussian_quantile
gaussian=datasets.make_gaussian_quantiles()
type(gaussian),len(gaussian)
引入数据集的两种代码:
from sklearn import datasets
#使用数据集时,以鸢尾花数据集为例
iris=datasets.load_iris()
from sklearn.datasets import load_iris
#使用数据集时,以鸢尾花数据集为例
iris=load_iris()
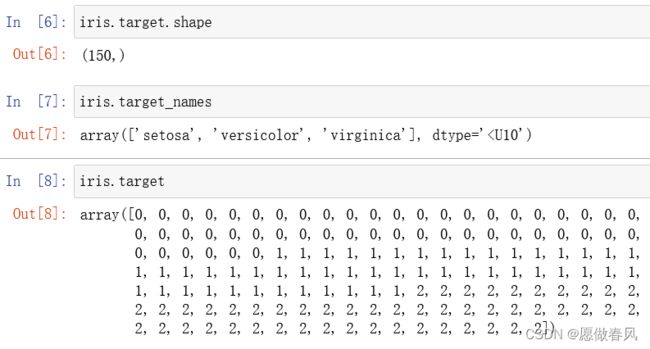
iris.keys()
#结果
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
键里面的名称解释如下:
data:特征值 (数组)
target:标签值 (数组)
target_names:标签 (列表)
DESCR:数据集描述
feature_names:特征 (列表)
filename:iris.csv 文件路径
 将数据集转换为DataFram:
将数据集转换为DataFram:
import pandas as pd
iris_data=pd.DataFrame(iris.data,
columns=iris.feature_names)
iris_data['species']=iris.target_names[iris.target]
iris_data.head(3).append(iris_data.tail(3))
 可视化seaborn
可视化seaborn
import seaborn as sns
sns.pairplot(iris_data,hue='species',palette='husl')

3.核心API
三大API:
1.估计器(estimator) :拟合器(fitter)可把它当成一个模型 (用来回归、分类、聚类、降维)。
2. 预测器 (predictor) 是具有预测功能的估计器
3.转换器 (transformer) 是具有转换功能的估计器
3.1 估计器
定义:任何可以基于数据集对一些参数进行估计的对象都被称为估计器
拟合估计器:在有监督学习中的代码范式为
model.fit( X_train, y_train )
在无监督学习中的代码范式为
model.fit( X_train )
拟合之后可以访问 model 里学到的参数,比如线性回归里的特征前的系数 coef_,或 K 均值里聚类标签 labels_。
model.coef_
model.labels_
线性回归
from sklearn.linear_model import LinearRegression
model=LinearRegression(normalize=True)
model
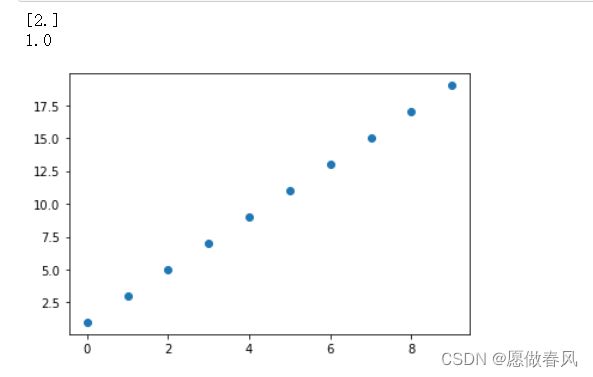
创建一个简单的数据集
import matplotlib.pyplot as plt
x=np.arange(10)
y=2*x+1
plt.plot(x,y,'o')
X=x[:,np.newaxis] #Sklearn 里模型要求特征 X 是个两维变量么 (样本数×特征数),但在本例中 X 是一维,因为我们用 np.newaxis 加一个维度,就是把一维 [1, 2, 3] 转成 [[1],[2],[3]]
model.fit(X,y)
print(model.coef_)
print(model.intercept_)
K均值
from sklearn.cluster import KMeans
model=KMeans(n_clusters=3)
X=iris.data[:,0:2]
model.fit(X)
print(model.cluster_centers_,'\n')
print(model.labels_,'\n')
print(model.inertia_,'\n')
print(iris.target)
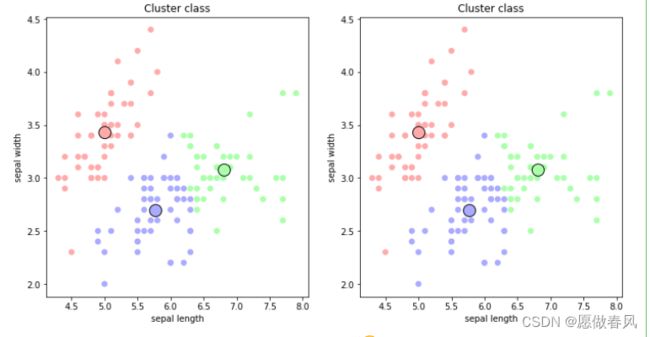
 解释一下 KMeans 模型这几个参数:
解释一下 KMeans 模型这几个参数:
model.cluster_centers_:簇中心。三个簇那么有三个坐标。
model.labels_:聚类后的标签
model.inertia_:所有点到对应的簇中心的距离平方和 (越小越好)
左图是根据聚类得到的标签画出散点图,而右图是根据真实标签画出散点图,对比两幅图看很像,聚类的效果还不错。
from matplotlib.colors import ListedColormap
cmap_light=ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold1=ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold2=ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
centroid=model.cluster_centers_
label=iris.target
true_centroid=np.vstack((X[label==0,:].mean(axis=0),
X[label==1,:].mean(axis=0),
X[label==2,:].mean(axis=0)))
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.scatter(X[:,0],X[:,1],c=model.labels_,cmap=cmap_bold1)
plt.scatter(centroid[:,0],centroid[:,1],marker='o',s=200,
edgecolors='k',c=[0,1,2],cmap=cmap_light)
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('Cluster class')
plt.subplot(1,2,2)
plt.scatter(X[:,0],X[:,1],c=model.labels_,cmap=cmap_bold2)
plt.scatter(centroid[:,0],centroid[:,1],marker='o',s=200,
edgecolors='k',c=[0,1,2],cmap=cmap_light)
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('Cluster class')
plt.show()
3.2 预测器
最常见的就是 predict() 函数:
- model.predict(X_test):评估模型在新数据上的表现
- model.predict(X_train):确认模型在老数据上的表现
做预测之前,将数据分为8:2的的训练集 (X_train, y_train) 和测试集 (X_test, y_test),用从训练集上拟合 fit() 的模型在测试集上预测 predict()。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris=load_iris()
x_train,x_text,y_train,y_test=train_test_split(iris['data'],iris['target'],
test_size=0.2)
print(x_train.shape)
print(y_train.shape)
print(x_text.shape)
print(y_test.shape)

监督学习的对率回顾。
from sklearn.linear_model import LogisticRegression
model=LogisticRegression(solver='lbfgs',multi_class='multinomial')
model.fit(x_train,y_train)
y_pred=model.predict(x_text)
p_pred=model.predict_proba(x_text)
print(y_test,'\n')
print(y_pred,'\n')
print(p_pred,'\n')
其中predict & predict_proba,前者是预测的类别,后者是只预测的准确度
预测器里还有额外的两个函数可以使用。在分类问题中
- score() 返回的是分类准确率
- decision_function() 返回的是每个样例在每个类下的分数值
监督学习的K均值。
from sklearn.cluster import KMeans
model=KMeans(n_clusters=3)
model.fit(x_train[:,0:2])
pred=model.predict(x_text[:,0:2])
print(pred)
print(y_test)
model.score(x_text[:,0:2])
 以上例子是以有监督学习的 LinearRegression 和无监督学习的 KMeans 举例,在实际应用时可以替换成其他模型。使用的通用伪代码如下
以上例子是以有监督学习的 LinearRegression 和无监督学习的 KMeans 举例,在实际应用时可以替换成其他模型。使用的通用伪代码如下
有监督学习。
#有监督学习
from sklearn.xxx import SomeModel
#xxx 可以是 linear_model 或 ensemble 等
model = SomeModel( hyperparameter )
model.fit( X, y )
y_pred = model.predict( X_new )
s = model.score( X_new )
无监督学习。
from sklearn.xxx import SomeModel
# xxx 可以是 cluster 或 decomposition 等
model = SomeModel( hyperparameter )
model.fit( X )
idx_pred = model.predict( X_new )
s = model.score( X_new )
3.3 转换器
定义:转换器也是一种估计器,两者都带拟合功能,但估计器做完拟合来预测,而转换器做完拟合来转换
估计器里:fit+predict
转换器:fit+transform
 preprocessing.scale( ) 标准化
preprocessing.scale( ) 标准化
preprocessing.MinMaxScaler( ) 最大最小值标准化
preprocessing.StandardScaler( ) 数据标准化
preprocessing.MaxAbsScaler( ) 绝对值最大标准化
preprocessing.RobustScaler( ) 带离群值数据集标准化
preprocessing.QuantileTransformer( ) 使用分位数信息变换特征
preprocessing.PowerTransformer( ) 使用幂变换执行到正态分布的映射
preprocessing.Normalizer( ) 正则化
preprocessing.OrdinalEncoder( ) 将分类特征转换为分类数值
preprocessing.LabelEncoder( ) 将分类特征转换为分类数值
preprocessing.MultiLabelBinarizer( ) 多标签二值化
preprocessing.OneHotEncoder( ) 独热编码
preprocessing.KBinsDiscretizer( ) 将连续数据离散化
preprocessing.FunctionTransformer( ) 自定义特征处理函数
preprocessing.Binarizer( ) 特征二值化
preprocessing.PolynomialFeatures( ) 创建多项式特征
preprocesssing.Normalizer( ) 正则化
preprocessing.Imputer( ) 弥补缺失值
下面展示一些 预处理代码。
import numpy as np
from sklearn import preprocessing
#标准化
x=np.array([[1,-1,2],[2,0,0],[0,1,-1]])
x_scale=preprocessing.scale(x)
print(x_scale)
print(x_scale.mean(axis=0),x_scale.std(axis=0))

上述preprocessing类函数的方法如下:
name.fit( ) 拟合数据
name.fit_transform( ) 拟合并转换数据
name.get_params( ) 获取函数参数
name.inverse_transform( ) 逆转换
name.set_params( ) 设置参数
name.transform( ) 转换数据
本文主要介绍两大类转换器
- 将分类型变量 (categorical) 编码成数值型变量 (numerical)
- 规范化 (normalize) 或标准化 (standardize) 数值型变量
分类型变量编码
LabelEncoder 和 OrdinalEncoder 都可以将字符转成数字,但是
- LabelEncoder 的输入是一维,比如 1d ndarray
- OrdinalEncoder 的输入是二维,比如 DataFrame
enc = ['win','draw','lose','win']
dec = ['draw','draw','win']
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
print(le.fit(enc))
print(le.classes_)
print(le.transform(dec))

OrdinalEncoder
from sklearn.preprocessing import OrdinalEncoder
oe=OrdinalEncoder()
enc_df=pd.DataFrame(enc)
dec_df=pd.DataFrame(dec)
print(oe.fit(enc_df))
print(oe.categories_)
print(oe.transform(dec_df))
 独热编码是把一个整数用向量的形式表现。转化器OneHotEncoder可以接受两种类型的输入:
独热编码是把一个整数用向量的形式表现。转化器OneHotEncoder可以接受两种类型的输入:
1)用 LabelEncoder 编码好的一维数组 (元素为整数),重塑 (用 reshape(-1,1)) 成二维数组作为 OneHotEncoder 输入。
转化独热编码。
from sklearn.preprocessing import OneHotEncoder
ohe=OneHotEncoder()
num=le.fit_transform(enc)
print(num)#打印编码结果[2 0 1 2]
ohe_y=ohe.fit_transform(num.reshape(-1,1))#将其转成独热形式,输出是一个「稀疏矩阵」形式,因为实操中通常类别很多,因此就一步到位用稀疏矩阵来节省内存
ohe_y

2) DataFrame作为 OneHotEncoder 输入。
转化独热编码。
ohe=OneHotEncoder()
ohe.fit_transform(enc_df).toarray()
特征缩放数据要做的最重要的转换之一是特征缩放 (feature scaling)。当输入的数值的量刚不同时,机器学习算法的性能都不会好。
具体来说,对于某个特征,有两种方法:
- 规范化 (normalization):每个维度的特征减去该特征最小值,除以该特征的最大值与最小值之差。将数据缩放到0和1之间,用MinMaxScaler函数.
- 标准化 (standardization):每个维度的特征减去该特征均值,除以该维度的标准差。将数据缩放到以0位中心而分散为1的区间,使用StandardScaler函数
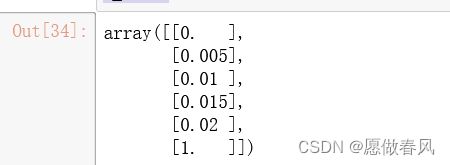
MinMaxScaler。
from sklearn.preprocessing import MinMaxScaler
x=np.array([0,0.5,1,1.5,2,100])
x_scale=MinMaxScaler().fit_transform(x.reshape(-1,1))
x_scale
StandardScaler。
from sklearn.preprocessing import StandardScaler
x_scale=StandardScaler().fit_transform(x.reshape(-1,1))
x_scale

4.分类模型

| Sklearn.tree | 功能 |
|---|---|
| tree.DecisionTreeClassifier | 决策树 |
决策树。
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
x,y=load_iris(return_X_y=True)
clf=DecisionTreeClassifier()
clf=clf.fit(x,y)
tree.plot_tree(clf)

Ensemble 估计器是用来做集成学习,该估计器里面有若干个分类器 (classifier) 或回归器 (regressor)。其中分类器统计每个子分类器的预测类别数,再用「多数投票」原则得到最终预测。
| Sklearn.ensemble | 功能 |
|---|---|
| BaggingClassifier() | 装袋法集成学习 |
| AdaBoostClassifier( ) | 提升法集成学习 |
| RandomForestClassifier( ) | 随机森林分类 |
| ExtraTreesClassifier( ) | 极限随机树分类 |
| RandomTreesEmbedding( ) | 嵌入式完全随机树 |
| GradientBoostingClassifier( ) | 梯度提升树 |
| VotingClassifier( ) | 投票分类法 |
BaggingClassifier()。
#使用sklearn库实现的决策树装袋法提升分类效果。其中X和Y分别是鸢尾花(iris)数据集中的自变量(花的特征)和因变量(花的类别)
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
#加载iris数据集
iris=datasets.load_iris()
X=iris.data
Y=iris.target
#生成K折交叉验证数据
kfold=KFold(n_splits=9)
#决策树及交叉验证
cart=DecisionTreeClassifier(criterion='gini',max_depth=2)
cart=cart.fit(X,Y)
result=cross_val_score(cart,X,Y,cv=kfold) #采用K折交叉验证的方法来验证算法效果
print('CART数结果:',result.mean())
#装袋法及交叉验证
model=BaggingClassifier(base_estimator=cart,n_estimators=100) #n_estimators=100为建立100个分类模型
result=cross_val_score(model,X,Y,cv=kfold) #采用K折交叉验证的方法来验证算法效果
print('装袋法提升后的结果:',result.mean())

| Sklearn.linear_model | 功能 |
|---|---|
| LogisticRegression( ) | 逻辑回归 |
| Perceptron( ) | 线性模型感知机 |
| SGDClassifier( ) | 具有SGD训练的线性分类器 |
| PassiveAggressiveClassifier( ) | 增量学习分类器 |
| Sklearn.svm | 功能 |
|---|---|
| svm.SVC( ) | 支持向量机分类 |
| svm.NuSVC( ) | Nu支持向量分类 |
| svm.LinearSVC( ) | 线性支持向量分类 |
| Sklearn.naive_bayes | 功能 |
|---|---|
| naive_bayes.GaussianNB( ) | 朴素贝叶斯 |
| naive_bayes.MultinomialNB( ) | 多项式朴素贝叶斯 |
| naive_bayes.BernoulliNB( ) | 伯努利朴素贝叶斯 |
5.回归模型
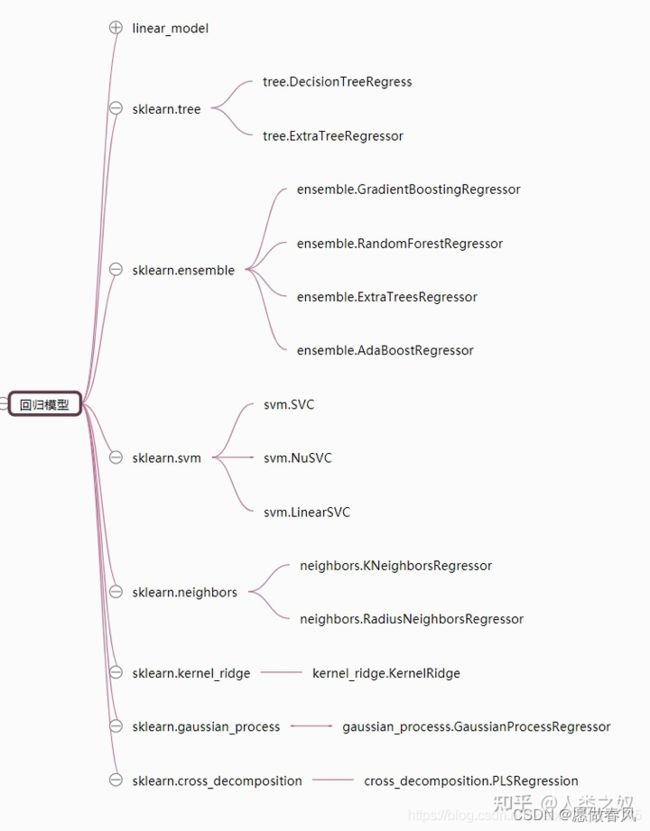
GradientBoostingRegressor。
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor as GBR
from sklearn.datasets import make_regression
X, y = make_regression(1000, 2, noise=10)#make_regression函数能生成回归样本数据。样本数100,参与的特征2
gbr = GBR()
gbr.fit(X, y)
gbr_preds = gbr.predict(X);
6.超参数调节
超参数的优化或调整是为学习算法选择一组最佳超参数的问题。
6.1 手动调参
在传统调优中,我们通过训练算法来手动检查随机的超参数集,并选择适合我们目标的最佳参数集。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold , cross_val_score
from sklearn.datasets import load_wine
wine = load_wine()
X = wine.data
y = wine.target
#划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3,random_state = 14)
#声明参数范围
k_value = list(range(2,11))
algorithm = ['auto','ball_tree','kd_tree','brute']
scores = []
best_comb = []
kfold = KFold(n_splits=5)
#超参数循环找最优
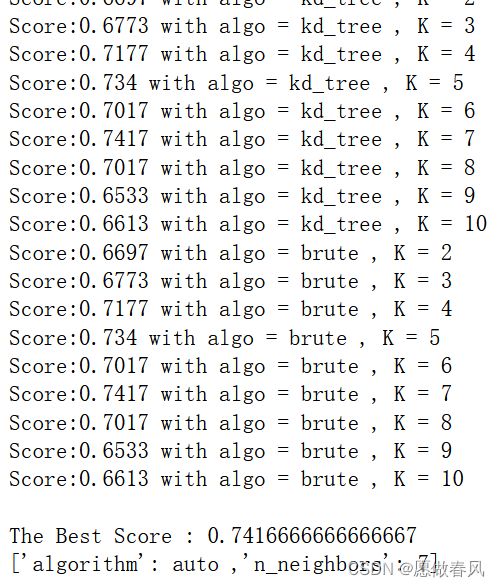
for algo in algorithm:
for k in k_value:
knn = KNeighborsClassifier(n_neighbors=k,algorithm=algo)
results = cross_val_score(knn,X_train,y_train,cv = kfold)
print(f'Score:{round(results.mean(),4)} with algo = {algo} , K = {k}')
scores.append(results.mean())
best_comb.append((k,algo))
best_param = best_comb[scores.index(max(scores))]
print(f'\nThe Best Score : {max(scores)}')
print(f"['algorithm': {best_param[1]} ,'n_neighbors': {best_param[0]}]")
6.1 网格搜索
网格搜索是一种基本的超参数调整技术。它类似于手动调整,在手动调整中,它为网格中指定的所有给定超参数集合构建一个模型,评估并选择最佳模型。考虑上面的示例,它有两个超参数 k_value = [2,3,4,5,6,7,8,9,10]&algorithm = [‘auto’,‘ball_tree’,‘kd_tree’,‘brute’] ,在这种情况下,它总共构建了 9 * 4 = 36 个不同的模型。官方文档:网格搜索
from sklearn.model_selection import RandomizedSearchCV
knn = KNeighborsClassifier()
grid_param = { 'n_neighbors' : list(range(2,11)) ,
'algorithm' : ['auto','ball_tree','kd_tree','brute'] }
rand_ser = RandomizedSearchCV(knn,grid_param,n_iter=10)
rand_ser.fit(X_train,y_train)
#best parameter combination
print(rand_ser.best_params_)
#score achieved with best parameter combination
print(rand_ser.best_score_)
6.3随机搜索
随机搜索代替网格搜索的动机是,在许多情况下,所有超参数可能都没有同等重要。随机搜索从超参数空间中选择参数的随机组合,参数将以 n_iter 给出的固定迭代次数进行选择。一般情况下,随机搜索比网格搜索可提供更好的结果。
官方文档:随机搜索
from sklearn.model_selection import RandomizedSearchCV
knn = KNeighborsClassifier()
grid_param = { 'n_neighbors' : list(range(2,11)) ,
'algorithm' : ['auto','ball_tree','kd_tree','brute'] }
rand_ser = RandomizedSearchCV(knn,grid_param,n_iter=10)
rand_ser.fit(X_train,y_train)
rand_ser.best_params_
rand_ser.best_score_