目标检测经典之作-Fast RCNN论文解读
视频链接:https://www.bilibili.com/video/BV1n54y1S71L/
1、看abstract时候的问题(看其他部分时候的回答)
1.1.Two-stage算法的主要难点?
第一是如何去生成proposals;第二是前面生成的propasal都是粗略的,因此对这些proposal进行调整。
1.2.为什么Fast RCNN的论文里用r和c代表top和left?
1.3.文中说网络的input是一张完整的图片和region of interest(RoIs),那么输入的这些RoIs又是怎么来的呢?
1.4.在Fast R-CNN训练时,用SGD在进行optimize的时候,进行了分层采样,先采样N张图片,在采样每张图片中的R/N个RoIs。为什么这样的效果就会比较好?
2、创新点
2.1.训练过程是one-stage的(SPPNet、R-CNN的训练过程都是multi-stage pipeline的),使用了multi-task的loss,不需要额外占用硬盘空间。
3、做了什么
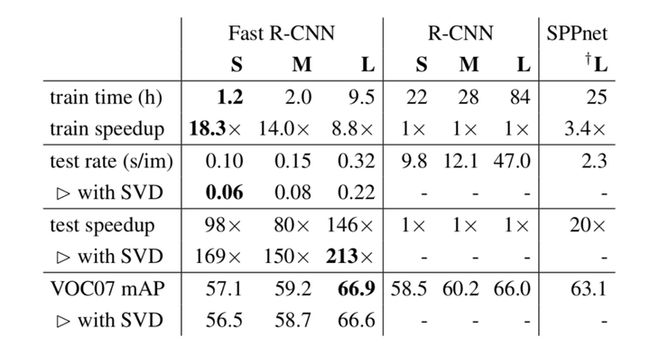
提出了一个目标检测算法,在training和testing的过程中都做了很多的创新,训练比RCNN快9倍,test比RCNN快213倍(这可能就是写论文的技巧吧,一定要找好对比的对象,如果跟SPPNet比的话,也就加速了3倍左右,并没有这么惊人),并且精度更高。
此外,本文的conclution的最后也提出了,如果能够在提出:在region proposal过程中,如果能发现一种比sparse proposals更高效的方法,那么能够大大加速目标检测的算法,这也为后面Faster RCNN的提出奠定了基础。
4、难点
。
5、怎么做
总体流程
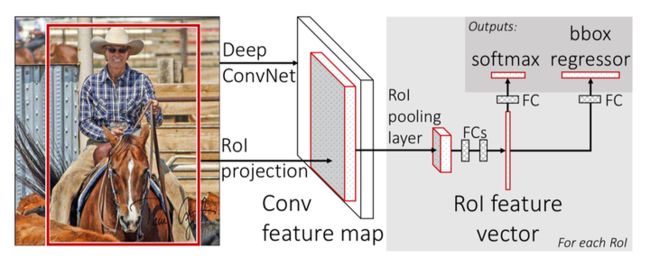
如图所示,网络的input是一张完整的图片和region of interest(RoIs);
首先对image进行进行特征提取生成feature map;
然后对feature map上RoI的区域,先进行池化到fixed size;
然后将这些fixed size的feature map通过fully connected layers映射成一维的vector;
这些一维的向量再通过2个全连接层,输出两个信息:一是当前RoI中包含的物体是每个类别的概率(长度为K+1,因为有一个类别是背景),二是每个类别bounding box的偏移量(长度为4K)——K代表数据集中的类别数量。
5.1. The RoI pooling layer
输入的RoIs的大小为w x h,经过ROI polling之后,RoIs的大小就会变成W x H(其中W、H为超参数,由用户设定)
具体的过程的话,就是用一个w/W x h/H的sliding window,在RoI上做max pooling。
5.2. Initializing from pre-trained networks
用了ImageNet pretrained model去初始化Fast R-CNN,主要有以下三个变化:
第一:把原来网络中最后一层的max pooling换成了ROI pooling,来生成fixed size的feature map
第二:把原来网络中的全连接层换成了两个sibling layers(一个用来生类别的概率,一个用来生成坐标信息)
第三:把模型的输入改成了2个,一个是image的list,另一个image对应的RoI的list
5.3. Fine-tuning for detection
为了解决以前的方法训练效率低的问题,在Fast R-CNN训练时,用SGD在进行optimize的时候,进行了分层采样,先采样N张图片,在采样每张图片中的R/N个RoIs。(不知道为啥这样效果就比较好)
通过一个fine-tuning stage,来共同optimize分类器(对物体分类)和回归器(回归坐标),就可以把整个过程给串起来,让整个training过程是一个one-stage的过程,不需要像R-CNN那样将softmax classifier, SVMs 和 regressors分开训练。
5.3.1 Multi-task loss
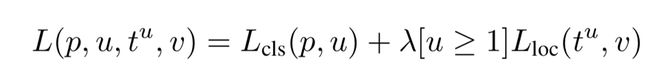
其中
p=(p0,...,pK),是predict box里包含每个物体的概率,u是类别的编号
v是GT box的坐标,tu是第u个类的predicted box的坐标信息;[u ≥ 1]只有在u ≥ 1才是1,否则为0,因为u=0的话,就代表是背景,如果是背景,就没必要去计算坐标回归的loss;λ是一个超参数,来控制分类和回归loss占总体loss的比重,如果更注重分类损失,那么λ<1,否则就λ>1。
Lcls()是log loss,Lloc是smooth L1 loss,如下图所示
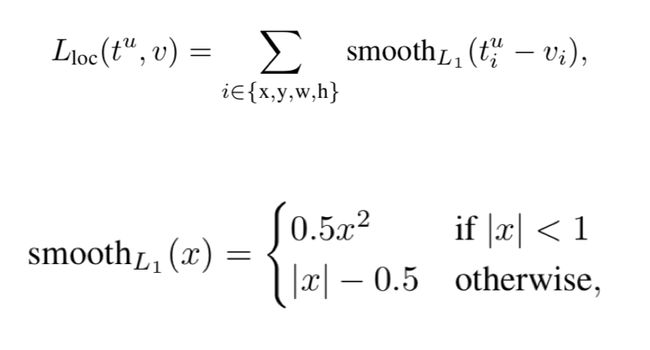
5.4. Scale invariance
为了实现Scale invariance,本文提出了两个方法:(1)via “brute force” learning、(2)using image pyramids
(1)“brute force” learning:在训练和测试之前,将图片缩放到pre-defined pixel size
(2)using image pyramids:使用image pyramid去初始化每一个proposal的尺度
6、结果怎么样
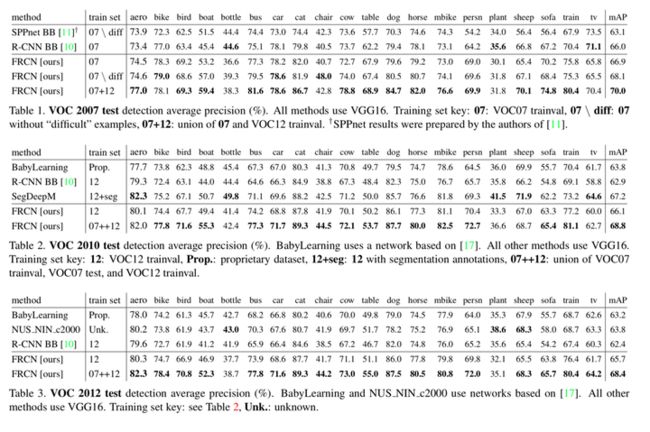
三个数据集下效果对比:
Fast R- CNN, R-CNN, and SPPnet训练和测试时间对比:
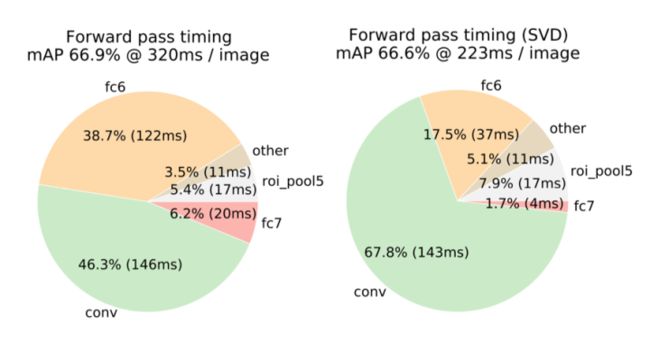
Truncated SVD能够减少30%的detection time,主要也是减少全连接层的时间
Ablation Experiment:固定前面的层,fine tune后面的层,对准确率的影响。

探究Multi-task training是否有用:

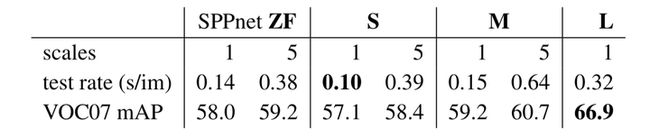
Multi-Scale VS Single-Scale
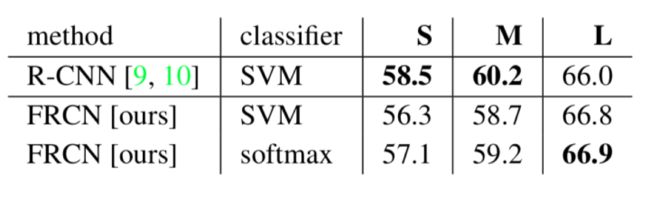
Faster R-CNN的分类器用softmax和SVM的对比:
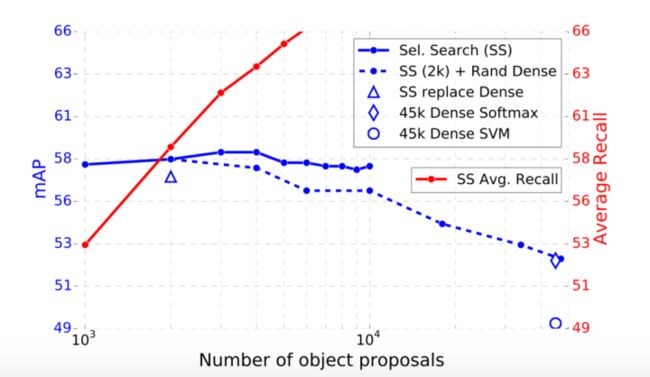
随着proposal的增加,reall和mAP的变化曲线(reall增加,mAP先上升再下降)
7、备注(写自己的问题,感受)
Fast RCNN定位一个bounding box是用r、c、w、h,分别代表top、left、width、height
Faster RCNN定位一个bounding box是用x,y,w,h,分别代表bounding box的中心坐标和width、height
——————————————————————————————
如果内容有帮助到您,希望大家多多点赞+收藏+关注!!!
经常会在知乎中分享自己的学习笔记,和大家一起学习进步!!!
——————————————————————————————