深度学习实验总结:PR-曲线、线性回归、卷积神经网络、GAN生成式对抗神经网络
目录
0、前言
1、实验一:环境配置
(1)本机
1、Jupyter
2、Pycharm
(2)云端
2、实验二:特征数据集制作和PR曲线
一、实验目的
二、实验环境
三、实验内容及实验步骤
3、实验三:线性回归及拟合
一、实验目的
二、实验环境
三、实验内容及实验步骤
4、实验四:卷积神经网络应用
一、实验目的
二、实验环境
三、实验内容及实验步骤
5、实验五:生成对抗式网络应用
一、实验目的
二、实验环境
三、实验内容及实验步骤
6、总结
0、前言
本人是深度学习初学者,为了加强对深度学习的认识和应用,从网上搜集了几个实验和代码,个人感觉对小白很有帮助,现与大家分享。代码原文链接均已在博客中标注。
学习资料:
《深度学习》:
github版:https://github.com/exacity/deeplearningbook-chinese
PDF电子书:
链接:https://pan.baidu.com/s/1mN4Mn330M82vnwi6Em1BzQ
提取码:qtex
深度学习框架实验:Pytorch:Dive-into-DL-PyTorch
TensorFlow:Dive-into-DL-TF2.0
以上资源仅供学习使用,不得用于商业目的。
1、实验一:环境配置
环境配置就是你在一个什么样的环境下敲代码做实验,我总结了两种环境,下面一一介绍给大家。
(1)本机
在本机上配置深度学习实验环境有两种方法:
1、Jupyter
用法:命令行(cmd)+交互式笔记本(Jupyter)
特点:简单方便个人比较推荐。
a、安装Anaconda
b、conda配置学习环境
c、conda切换国内镜像源
d、使用Jupyter进行深度学习开发
详细教程:深度学习环境配置Anaconda+Jupyter\\Pycharm+Tensorflow-数据集文档类资源-CSDN下载
2、Pycharm
用法:Pycharm编辑器
特点:编程老手比较喜欢的工作方式。
a、下载
地址:Download PyCharm: Python IDE for Professional Developers by JetBrains
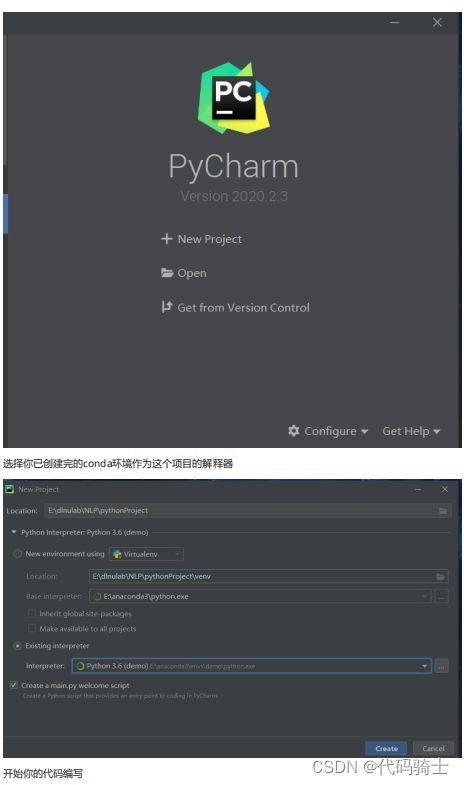
b、使用
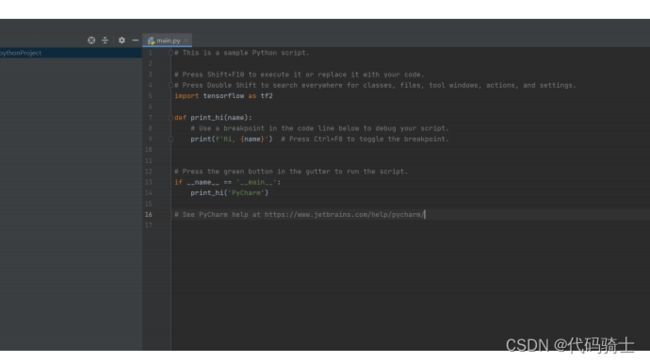
c、编写代码(注意:缺少相应的库到终端下载就行了,建议把下载源换成国内镜像源会快很多。)
(2)云端
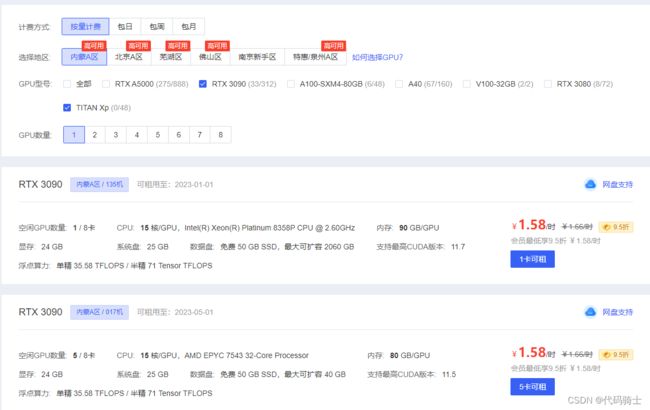
就是租一台GPU云服务帮助我们快速的跑深度学习代码。我用的是这款:
AutoDL-品质GPU租用平台-租GPU就上AutoDL
可以看到有很多性能强大的GPU,而且相对比较下来,价格还可以。
还有一点就是可以使用别人搭建好的深度学习算法框架,可以直接拿来使用:
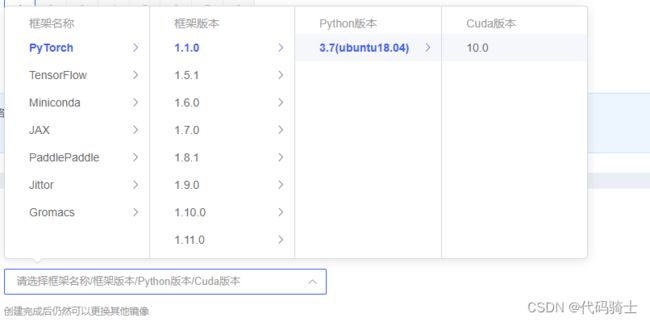
创建一个实例,点击JupyterLab就可以进行代码编辑了

在笔记本编写代码,然后保存为.py文件

然后在终端输入指令运行就可以了。
2、实验二:特征数据集制作和PR曲线
一、实验目的
1.掌握数据集的归一化方法;掌握K折交叉验证;
2.掌握P-R曲线特点及评价指标。
二、实验环境
1. 计算机;
2. TensorFlow环境、Iris(鸢尾花)数据集。
三、实验内容及实验步骤
1.实验内容
(1)掌握K折交叉验证原理,以及数据集拆分;
K折交叉验证原理参考:百度安全验证
K折交叉验证优缺点:【机器学习基础】详细介绍 7 种交叉验证方法!|序列|拟合|样本|算法_网易订阅
使用临近模型进行交叉验证:机器学习——鸢尾花案例——交叉验证_猿童学的博客-CSDN博客_鸢尾花交叉验证
验证使用SVC分类器的分类模型
K折交叉验证_直方大的博客-CSDN博客_k折交叉验证
了解鸢尾花数据集: 鸢尾花(Iris)数据集_qinzhongyuan的博客-CSDN博客_鸢尾花数据集
更多分类模型:关于鸢尾花数据集的分析 - 知乎
(2)掌握P-R曲线的评价指标和优点。
分类评价指标了解TP、TN、FP、FN超级详细解析-爱码网
输出鸢尾花原数据target的分类指标:https://blog.csdn.net/lxt1101/article/details/124280654
了解P-R曲线:https://blog.csdn.net/b876144622/article/details/80009867
SVM混淆矩阵:https://blog.csdn.net/Vicky_xiduoduo/article/details/124423779
2.实验步骤
(1)完成Iris数据集拆分(五折或十折);
a、10折交叉验证LR模型性能:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,KFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
logreg=LogisticRegression(max_iter=10000).fit(X, Y)#限制最大迭代次数
kf=KFold(n_splits=10)
score=cross_val_score(logreg,X,Y,cv=kf)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))输出:
该模型的泛化能力可达0.947

什么是LR模型:Kaggle知识点:sklearn模型迭代训练|bat|维度|神经网络_网易订阅
b、10折交叉验证KNN临近模型性能:
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt;
iris=load_iris()
X=iris.data
y=iris.target
knn=KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn,X,y,cv=10,scoring='accuracy')
print(scores)
print(scores.mean())
k_range=range(1,31)
k_scores=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')
k_scores.append(scores.mean())
print(k_scores)
k_range=range(1,31)
k_scores=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')
k_scores.append(scores.mean())
print(k_scores)
plt.plot(k_range,k_scores)
plt.xlabel('The value of the k in KNN')
plt.ylabel('accuracy')
plt.show()输出:
该模型的最优泛华能力可达0.98

c、验证SVC分类模型
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
# 导入用于分类的svc分类器
from sklearn.svm import SVC
iris = load_iris()
x, y = iris.data, iris.target
svc = SVC(kernel='linear')
# cv 为迭代次数, 这里设置为5
scores = cross_val_score(svc, x, y, cv=5)
# 5次,每次的结果
print("交叉验证得分: %.4f %.4f %.4f %.4f %.4f" % (scores[0], scores[1], scores[2], scores[3], scores[4]))
# 用得分均值作为最终得分
print("res: %.4f" % (scores.mean()))输出:

(2)采用分类算法(SVM、贝叶斯、或其它分类方法均可)对数据集进行分类;并记录TP、TN、FN和FP等参数;
采用SVM支持向量机对数据进行分类:https://zhuanlan.zhihu.com/p/356445360
1、导入需要的包
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 #有中文出现的情况,需要u'内容'
#导入鸢尾花数据集包
from sklearn.datasets import load_iris
#导入矩阵运算库
import numpy as np
#导入label_binarize()
from sklearn.preprocessing import label_binarize
#导入train_test_split
from sklearn.model_selection import train_test_split
#导入OneVsRestClassifier
from sklearn.multiclass import OneVsRestClassifier
#导入支持向量机
from sklearn import svm,datasets
from sklearn.svm import SVC
from itertools import cycle
from sklearn.metrics import precision_recall_curve
from sklearn.linear_model import LogisticRegression
from sklearn import metrics2、载入鸢尾花数据集
#载入鸢尾花数据集并显示
iris = load_iris()
print(iris)输出数据集:

3、下载数据并给重新定义数据
#鸢尾花数据集
TRAIN_URL = 'http://download.tensorflow.org/data/iris_training.csv' #数据下载地址
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL) #下载数据,并返回路径(默认路径)
title = '鸢尾花数据集'
names = ['花萼长度','花萼宽度','花瓣长度','花瓣宽度','品种'] #自定义列标题
df_iris = pd.read_csv(train_path,header=0, names=names) #names指定的列标题会替代header指定的列标题
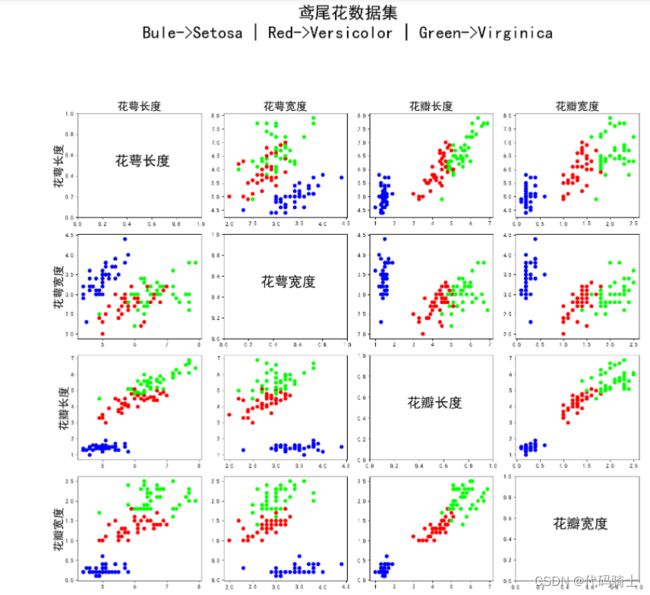
#df_iris.head() #读取前5行,参数n可以指定行数 tail(n)函数读取后n行数据4、鸢尾花数据集可视化函数
#鸢尾花数据集可视化函数
def draw_data(train_path,names,df_iris):
#可视化
fig = plt.figure('Iris Data', figsize=(15,15))
plt.suptitle('鸢尾花数据集\nBule->Setosa | Red->Versicolor | Green->Virginica', fontsize = 30)
for i in range(4):
for j in range(4):
plt.subplot(4,4, 4*i+(j+1)) #创建4*4的子画布,一行一行的循环画,其中每个子图的索引为 4*i+(j+1)
if i ==j:
plt.text(0.3,0.5, names[i], fontsize = 25) #正对角线上的子图只显示标签
else:
plt.scatter(np.array(df_iris)[:,j], np.array(df_iris)[:,i], c=np.array(df_iris)[:,4], cmap = 'brg')
if i == 0:
plt.title(names[j], fontsize= 20) #为了美观,把title当X轴标签
if j == 0:
plt.ylabel(names[i], fontsize = 20) #设置Y轴标签
plt.tight_layout(rect=[0,0,1,0.9]) #自动调整子图布局,设置0.9是为了给全局标题一点空间,避免拥挤
plt.savefig('Iris.jpg')
plt.show()
return;5、输出可视化数据集
draw_data(train_path,names,df_iris)输出数据集:
6、数据预处理
#数据预处理
'''
在开始对模型的训练之前,我们需要将数据集进行一定的处理。
我们需要将数据集分割为训练集和测试集两部分,同时加入噪音(noise),对于SVM模型,我们还需要将标签二值化,以便使用之后封装好的求值函数。
对于svm模型的数据集,我们使用:
'''
#获取鸢尾花数据集的特征和标签
iris_feature = iris.data
iris_label = iris.target
#将标签二值化
iris_label_res = label_binarize(iris_label,classes=[0,1,2])
#得到标签的类别数
n_classes = iris_label_res.shape[1]
#加入噪音
random_state = np.random.RandomState(0)
n_samples, n_features = iris_feature.shape
iris_feature_rand = np.c_[iris_feature, random_state.randn(n_samples, 200 * n_features)]
#分割数据集,训练集与测试集比为1:1
X_trainS, X_testS, y_trainS, y_testS = train_test_split(iris_feature_rand, iris_label_res, test_size=0.5, random_state=random_state)
7、SVM模型训练
#SVM模型训练
#建立支持向量机
clf1 = OneVsRestClassifier(svm.LinearSVC(random_state=random_state))
#训练
clf1.fit(X_trainS,y_trainS)训练过程
8、获取预测置信度
#使用测试集验证模型
#得到预测的置信度
y_scoreS=clf1.decision_function(X_testS)9、获取模型评测参数
#封装好的方法,用来获取某个模型的P,R,TPR,FPR值
def num_get(y_score,y_test,classes):
#建立存储字典
Precision=dict()
Recall=dict()
TPR=dict()
FPR=dict()
#由于我们是多标签模型,所以循环输出每种标签的值
for i in range(classes):
#截取预测结果的第i列,_代表无关变量
Precision[i],Recall[i],_ = precision_recall_curve(y_test[:,i],y_score[:,i])
FPR[i],TPR[i],_ = metrics.roc_curve(y_test[:,i], y_score[:,i])
return Precision,Recall,TPR,FPR10、绘图函数
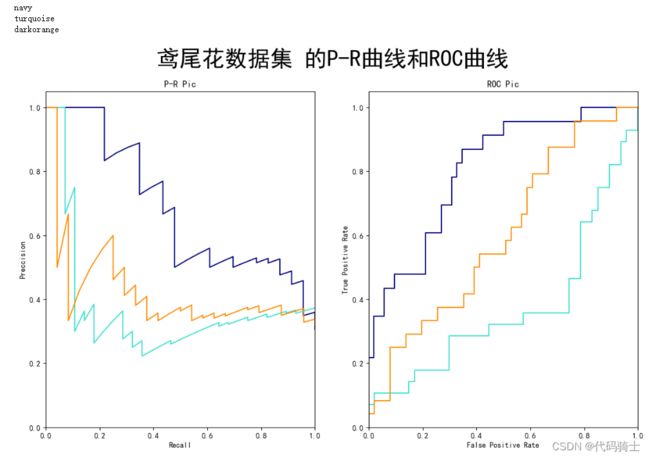
#绘制模型的P-R曲线与ROC曲线
def draw_line(Precision,Recall,TPR,FPR,classes,title):
colors = cycle(['navy', 'turquoise', 'darkorange', ])
plt.figure(figsize=(14, 8))
plt.suptitle(title+' 的P-R曲线和ROC曲线', fontsize = 30)
ax1=plt.subplot(1,2,1)
plt.xlabel("Recall")
plt.ylabel("Preccision")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
for i, color in zip(range(classes), colors):
l, = plt.plot(Recall[i], Precision[i], color=color)
ax2=plt.subplot(1,2,2)
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
for i, color in zip(range(classes), colors):
print(color)
l, = plt.plot(FPR[i], TPR[i], color=color)
ax1.set_title("P-R Pic")
ax2.set_title("ROC Pic")
plt.savefig(title+'PR-ROC.png')
plt.show()
return 011、获取函数返回值
Precision,Recall,TPR,FPR = num_get(y_scoreS,y_testS,3)12、绘制PR、ROC曲线
#SVM模型p-r曲线
draw_line(Precision,Recall,TPR,FPR,3,title)(3)绘制P-R曲线,保存曲线图片。
3、实验三:线性回归及拟合
一、实验目的
1.掌握二次回归、线性回归的思想;
2.掌握回归方法的评价R-squared。
二、实验环境
1. 计算机;
2. TensorFlow环境;
三、实验内容及实验步骤
1.实验内容
(1)掌握二次回归和线性回归的拟合方法,以及对比结果;保存对比结果图;
机器学习线性回归、多项式回归、逻辑回归总结:
[Python从零到壹] 十二.机器学习之回归分析万字总结全网首发(线性回归、多项式回归、逻辑回归)_Eastmount的博客-CSDN博客_什么是一元线性回归和多项式回归
基于sklearn线性回归、二次回归比较:
使用Sklearn进行线性回归和二次回归的比较(基于jupyter)_叽叽贝贝的博客-CSDN博客_sklearn 二次回归
(2)实验用数据集,如下:
表1 实验训练数据集
| 数据1 |
数据2 |
数据3 |
数据4 |
数据5 |
|
| 披萨尺寸(X) |
6 |
8 |
10 |
14 |
17 |
| 披萨价格(Y) |
7 |
9 |
13 |
17.5 |
18 |
表2 实验测试集
| 数据1 |
数据2 |
数据3 |
数据4 |
|
| 披萨尺寸(X) |
7 |
9 |
11 |
15 |
| 披萨价格(Y) |
8 |
12 |
15 |
18 |
2.实验步骤
(1)采用二次回归方法绘制回归曲线,保存回归曲线图;
# -*- coding: utf-8 -*-
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示披萨尺寸 Y表示披萨价格
X = [[6], [8], [10], [14], [17]]
Y = [[7], [9], [13], [17.5], [18]]
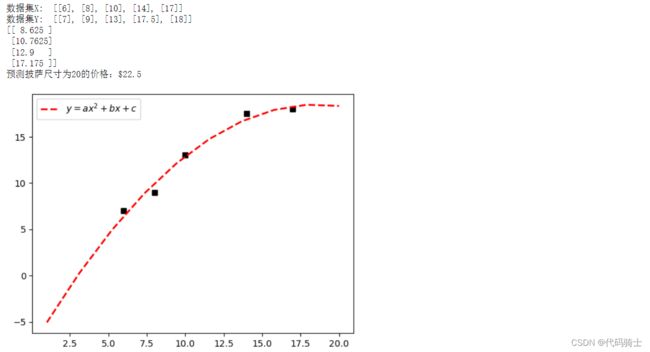
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
#预测结果
X2 = [[7], [9], [11],[15]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([20]).reshape(-1, 1))[0]
print('预测披萨尺寸为20的价格:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
#plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(1,20,10) #1到20等差数列,取20个点
quadratic_featurizer = PolynomialFeatures(degree = 2) #实例化一个二次多项式
x_train_quadratic = quadratic_featurizer.fit_transform(X) #用二次多项式x做变换
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^2 + bx + c$",linewidth=2)
plt.legend()
plt.show()
绘制二次回归曲线
(2)求解线性回归(一次~五次)和二次回归的R-squared参数,保存参数结果;
一次线性回归:
# -*- coding: utf-8 -*-
from sklearn import linear_model #导入线性模型
import matplotlib.pyplot as plt
import numpy as np
#X表示披萨尺寸 Y表示披萨价格
X = [[6], [8], [10], [14], [17]]
Y = [[7], [9], [13], [17.5], [18]]
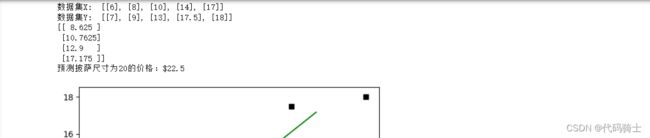
print('数据集X: ', X)
print('数据集Y: ', Y)
#回归训练
clf = linear_model.LinearRegression()
clf.fit(X, Y)
#预测结果
X2 = [[7], [9], [11],[15]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([20]).reshape(-1, 1))[0]
print('预测披萨尺寸为20的价格:$%.1f' % res)
#绘制线性回归图形
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
plt.show()
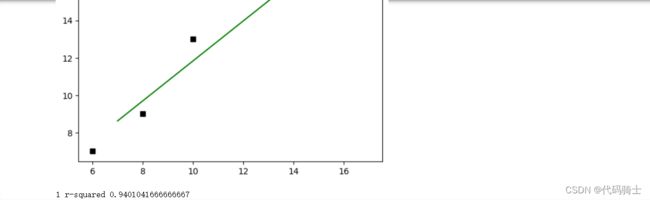
print('1 r-squared', clf.score(X, Y))输出图像和参数:
二次回归:
# -*- coding: utf-8 -*-
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示披萨尺寸 Y表示披萨价格
X = [[6], [8], [10], [14], [17]]
Y = [[7], [9], [13], [17.5], [18]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
#预测结果
X2 = [[7], [9], [11],[15]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([20]).reshape(-1, 1))[0]
print('预测披萨尺寸为20的价格:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
#plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(1,20,10) #1到20等差数列,取20个点
quadratic_featurizer = PolynomialFeatures(degree = 2) #实例化一个二次多项式
x_train_quadratic = quadratic_featurizer.fit_transform(X) #用二次多项式x做变换
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^2 + bx + c$",linewidth=2)
plt.legend()
plt.show()
print('2 r-squared', regressor_quadratic.score(x_train_quadratic, Y))输出图像及参数:
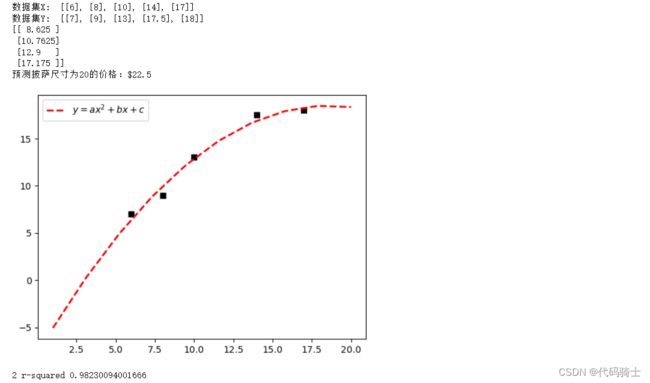
三次回归:
# -*- coding: utf-8 -*-
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示披萨尺寸 Y表示披萨价格
X = [[6], [8], [10], [14], [17]]
Y = [[7], [9], [13], [17.5], [18]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
#预测结果
X2 = [[7], [9], [11],[15]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([20]).reshape(-1, 1))[0]
print('预测披萨尺寸为20的价格:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
#plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(1,20,10) #1到20等差数列,取20个点
quadratic_featurizer = PolynomialFeatures(degree = 3) #实例化一个二次多项式
x_train_quadratic = quadratic_featurizer.fit_transform(X) #用二次多项式x做变换
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^3 + bx^2 + cx+d$",linewidth=3)
plt.legend()
plt.show()
print('2 r-squared', regressor_quadratic.score(x_train_quadratic, Y))图像及参数:
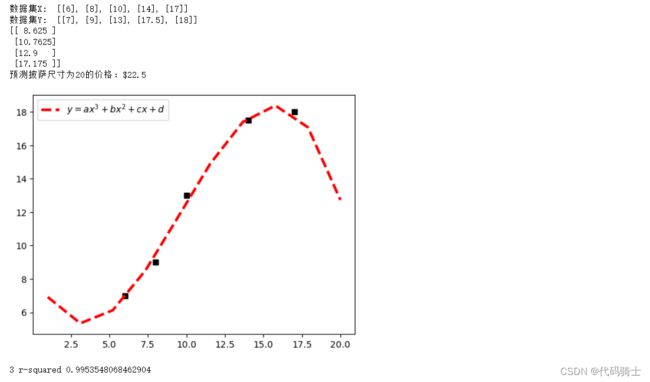
四次回归:
# -*- coding: utf-8 -*-
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示披萨尺寸 Y表示披萨价格
X = [[6], [8], [10], [14], [17]]
Y = [[7], [9], [13], [17.5], [18]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
#预测结果
X2 = [[7], [9], [11],[15]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([20]).reshape(-1, 1))[0]
print('预测披萨尺寸为20的价格:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
#plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(1,20,10) #1到20等差数列,取20个点
quadratic_featurizer = PolynomialFeatures(degree = 4) #实例化一个二次多项式
x_train_quadratic = quadratic_featurizer.fit_transform(X) #用二次多项式x做变换
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^4 + bx^3 + cx^2+dx+e$",linewidth=4)
plt.legend()
plt.show()
print('4 r-squared', regressor_quadratic.score(x_train_quadratic, Y))图像及参数:
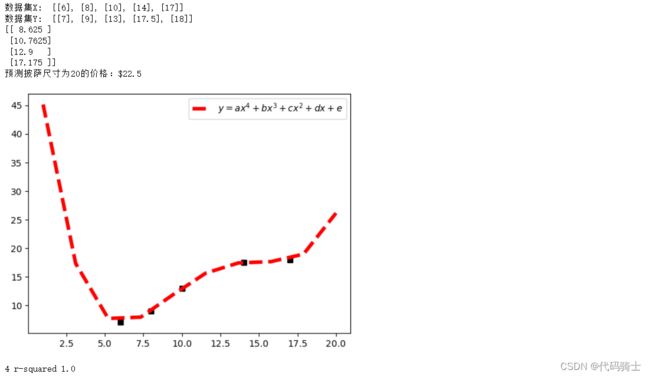
五次回归:
# -*- coding: utf-8 -*-
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示披萨尺寸 Y表示披萨价格
X = [[6], [8], [10], [14], [17]]
Y = [[7], [9], [13], [17.5], [18]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
#预测结果
X2 = [[7], [9], [11],[15]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([20]).reshape(-1, 1))[0]
print('预测披萨尺寸为20的价格:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
#plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(1,20,10) #1到20等差数列,取20个点
quadratic_featurizer = PolynomialFeatures(degree = 5) #实例化一个二次多项式
x_train_quadratic = quadratic_featurizer.fit_transform(X) #用二次多项式x做变换
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^5 + bx^4 + cx^3+dx^2+ex+f$",linewidth=5)
plt.legend()
plt.show()
print('5 r-squared', regressor_quadratic.score(x_train_quadratic, Y))图像及参数:
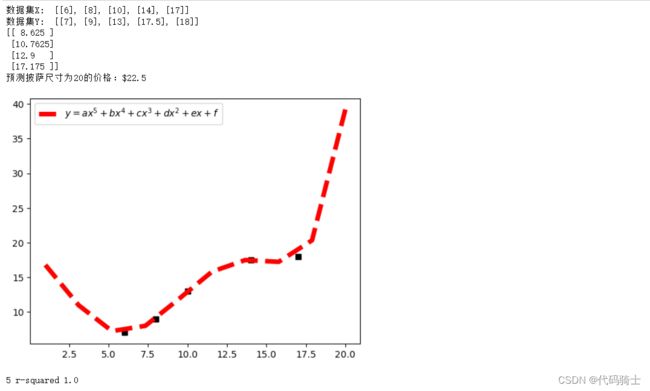
(3)对比R-squared参数,说明披萨尺寸和价格关系的回归曲线具有优势。
数据显示:
| 1 r-squared | 0.9401041666666667 |
| 2 r-squared | 0.98230094001666 |
| 3 r-squared | 0.9953548068462904 |
| 4 r-squared | 1.0 |
| 5 r-squared | 1.0 |
从数据显示来看,多项式越多且最高次幂越大,回归效果越好。但是本次实验数据较少,如果数据增多,肯能会存在峰值效应。
4、实验四:卷积神经网络应用
一、实验目的
1.掌握卷积神经网络(Convolutional Neural Networks, CNN)的结构;
2.掌握卷积层、池化层和全连接层的功能;
3.掌握卷积神经网络的基本功能。
二、实验环境
1. 计算机;
2. TensorFlow环境,手写数字(mnist)数据集。
mnist手写数据集:https://blog.csdn.net/OpenDataLab/article/details/125716623
三、实验内容及实验步骤
1. 实验内容
(1)搭建CNN网络;
CNN详解:CNN(卷积神经网络)介绍 - 知乎
搭建CNN进行MNIST手写数字识别模型训练:https://blog.csdn.net/qq_43673118/article/details/102992944
(2)识别手写数字。
对手写模型进行测试:
keras搭建神经网络实验(二):CNN识别手写数字_矢三郎的狸猫的博客-CSDN博客
2. 实验步骤
(1)搭建CNN网络,设置核函数数量及参数;按顺序建立卷积层和池化层;
1、导包
import keras
from keras.models import model_from_json
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
import h5py
from keras.models import load_model
import matplotlib.pyplot as plt
import os
import cv2
from PIL import Image
num_classes = 102、加载数据
# Load data
path='mnist.npz'
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()3、数据预处理
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)4、搭建CNN模型
# Build CNN
model = Sequential()
model.add(Conv2D(filters=16,
kernel_size=(5,5),
padding='same',
input_shape=(28,28,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=36,
kernel_size=(5,5),
padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax'))5、模型训练
# Train model
model.compile(loss='categorical_crossentropy',
optimizer='adam',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=100,epochs=20)
result = model.evaluate(x_test,y_test)
print ('\nTest Acc:',result[1])
result = model.evaluate(x_train,y_train)
print ('\nTrain Acc:',result[1])6、进行手写识别测试
(1)在项目环境中创建文件夹—testnumbers
(2)添加手写测试文件:
打开画图软件自己手写0·9的图片保存在文件夹中即可。

# Load Image
file_name = '0.png'
img = Image.open('./testnumbers/'+file_name)
im_arr = np.array(img.convert("L"))
im_arr = im_arr.astype('float32')/255
im_arr = 1-im_arr #灰度反转
print('\n输入:'+file_name)7、处理图像数组
#resize图片大小 先将原本的(224,222,3) ---> (28,28,3)
im_arr = cv2.resize(im_arr,(28,28))
#转换np数组格式
im_arr = np.array(im_arr) 8、进行预测
# predict
predict = model.predict(im_arr.reshape(1,28,28,1))
print('识别为:')
print(np.where(predict[0]==np.max(predict[0]))[0][0])
plt.imshow(im_arr, cmap='gray')
plt.show()(2)识别手写数字,并保存代码执行过程中的重要结果图,计算识别率;

(3)改变核函数、卷积层数量和池化层数量,重新计算识别率,并与之前结果比较。
修改模型:将卷积大小改为4*4,去去掉池化层。
# Build CNN
model = Sequential()
model.add(Conv2D(filters=16,
kernel_size=(4,4),
padding='same',
input_shape=(28,28,1),
activation='relu'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax'))输出结果:

代码附录:
1、CNN模型代码:
#导入模块
import tensorflow as tf
#导入数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#Reshape
x_train4D = x_train.reshape(x_train.shape[0],28,28,1).astype('float32')
x_test4D = x_test.reshape(x_test.shape[0],28,28,1).astype('float32')
#像素标准化
x_train, x_test = x_train4D / 255.0, x_test4D / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16, kernel_size=(5,5), padding='same',
input_shape=(28,28,1), activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Conv2D(filters=36, kernel_size=(5,5), padding='same',
activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10,activation='softmax')
])
#打印模型
print(model.summary())
#训练配置
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
#开始训练
model.fit(x=x_train, y=y_train, validation_split=0.2,
epochs=20, batch_size=300, verbose=2)
输出模型:
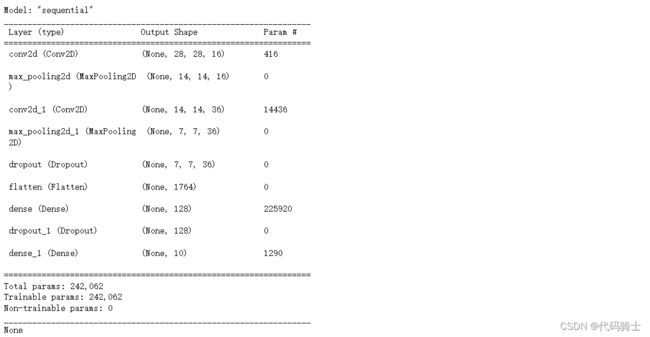
训练结果:

2、 保存h5模型文件:
import keras
from keras.models import model_from_json
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
import h5py
from keras.models import load_model
import matplotlib.pyplot as plt
import os
import cv2
from PIL import Image
num_classes = 10
# Load data
path='mnist.npz'
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# Build CNN
model = Sequential()
model.add(Conv2D(filters=16,
kernel_size=(5,5),
padding='same',
input_shape=(28,28,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=36,
kernel_size=(5,5),
padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax'))
# Train model
model.compile(loss='categorical_crossentropy',
optimizer='adam',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=100,epochs=20)
result = model.evaluate(x_test,y_test)
print ('\nTest Acc:',result[1])
result = model.evaluate(x_train,y_train)
print ('\nTrain Acc:',result[1])
# save model
model_json = model.to_json()
with open('cnn_model.json','w') as json_file:
json_file.write(model_json)
# serialize weight to HDF5
model.save_weights('cnn_model.h5')
print('Save ,odel to disk')3、调用模型h5文件:
#导入h5模型进行测试
from keras.models import model_from_json
from keras.models import load_model
import keras
import numpy as np
import matplotlib.pyplot as plt
import os
import cv2
from PIL import Image
# load json and create model
json_file = open('cnn_model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights("cnn_model.h5")
print("Loaded model from disk")
loaded_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Load Image
file_name = '0.png'
img = Image.open('./testnumbers/'+file_name)
im_arr = np.array(img.convert("L"))
im_arr = im_arr.astype('float32')/255
im_arr = 1-im_arr #灰度反转
print('\n输入:'+file_name)
#resize图片大小 先将原本的(224,222,3) ---> (28,28,3)
im_arr = cv2.resize(im_arr,(28,28))
#转换np数组格式
im_arr = np.array(im_arr)
# predict
predict = loaded_model.predict(im_arr.reshape(1,28,28,1))
print('识别为:')
print(np.where(predict[0]==np.max(predict[0]))[0][0])
plt.imshow(im_arr, cmap='gray')
plt.show()
5、实验五:生成对抗式网络应用
一、实验目的
1.掌握生成式对抗网络()基本结构和功能;
2.掌握GAN网络的基本应用。
二、实验环境
1. 计算机;
2. Pytorch环境或Jupyter环境。
三、实验内容及实验步骤
1. 实验内容
(1)搭建GAN网络;
(2)采用GAN网络生成数据。
参考文章1:https://blog.csdn.net/fuxun222/article/details/126714792
参考文章2:https://blog.csdn.net/soih0718/article/details/121585655
2. 实验步骤
(1)搭建GAN网络,配置Pytorch环境或Jupyter环境;
1、导库
import torch
import torch.nn as nn
import pandas as pd
import matplotlib.pyplot as plt
import random
import numpy2、构建真实数据源
def generate_real():
real_data = torch.FloatTensor([random.uniform(0.8,1.0),
random.uniform(0.0,0.2),
random.uniform(0.8,1.0),
random.uniform(0.0,0.2),
])
return real_data3、 创建一个函数生成随机噪声模式
def generate_random(size):
random_data = torch.rand(size)
return random_data
4、构建鉴别器
class Discriminator(nn.Module):
def __init__(self):
# 初始化 PyTorch 父类
super().__init__()
# 定义神经网络各层:线性层-sigmoid函数-线性层-sigmoid函数
self.model = nn.Sequential(
nn.Linear(4, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid()
)
# 使用均方值误差作为损失函数
self.loss_function = nn.MSELoss()
# 使用随机梯度下降(SGD)创建优化器
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# 计数器和累加器,用于流程控制和显示
self.counter = 0
self.progress = []
pass
def forward(self,inputs):
return self.model(inputs)
def train(self, inputs, targets):
# 计算网络的输出
outputs = self.forward(inputs)
# 计算损失值
loss = self.loss_function(outputs, targets)
# 每运行10次,增加计数器和累加器
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
# 将梯度置零,并运行反向更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pd.DataFrame(self.progress, columns=['loss'])
fig = df.plot(ylim=(0, 1.0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
fig.figure.savefig('../root/1121_.png')
pass
5、测试鉴别器
D=Discriminator()6、训练循环10000次
for i in range(10000):
D.train(generate_real(),torch.FloatTensor([1.0]))
D.train(generate_random(4),torch.FloatTensor([0.0]))7、绘制损失值图像
D.plot_progress()输出:
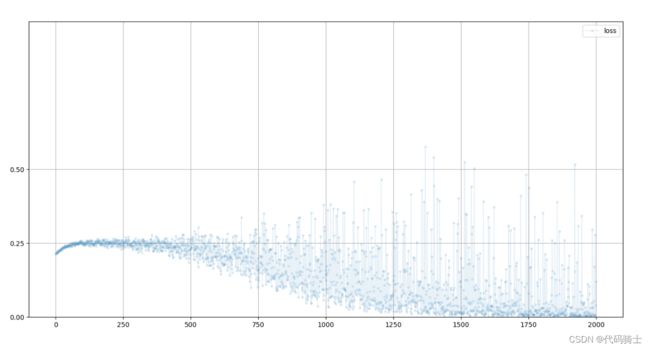
8、构建生成器
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model=nn.Sequential(
nn.Linear(1,3),
nn.Sigmoid(),
nn.Linear(3,4),
nn.Sigmoid()
)
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
self.counter=0
self.progress=[]
pass
def forward(self, inputs):
# 简单的运行模型
return self.model(inputs)
def train(self,D,inputs,targets):
g_output=self.forward(inputs)
d_output = D.forward(g_output)
loss=D.loss_function(d_output,targets)
self.counter+=1
if(self.counter%10==0):
self.progress.append(loss.item())
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
pass
9、测试生成器的输出
G=Generator()
G.forward(torch.FloatTensor([0.5]))10、训练GAN网络
通过前面的工作,就做好了使用 3 步训练循环对 GAN 进行训练的准备。
# create Discriminator and Generator
D = Discriminator()
G = Generator()
image_list = []
# train Discriminator and Generator
for i in range(10000):
# train discriminator on true
D.train(generate_real(), torch.FloatTensor([1.0]))
# train discriminator on false
# use detach() so gradients in G are not calculated
D.train(G.forward(torch.FloatTensor([0.5])).detach(), torch.FloatTensor([0.0]))
D
# train generator
G.train(D, torch.FloatTensor([0.5]), torch.FloatTensor([1.0]))
# add image to list every 1000
if (i % 1000 == 0):
image_list.append( G.forward(torch.FloatTensor([0.5])).detach().numpy() )
pass11、再次观察鉴别器的损失值图像
#使用鉴别器查看损失值
D.plot_progress()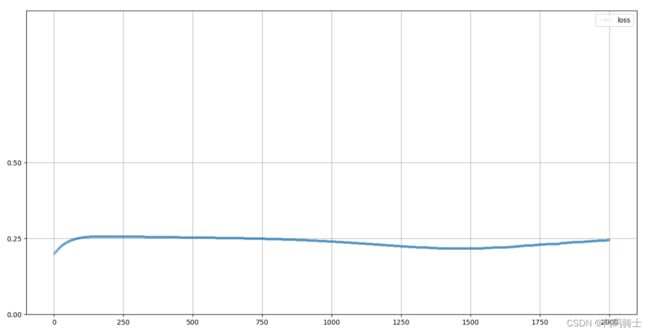
12、查看训练完第一次生成的数据
#试验训练后第一次生成的数据
G.forward(torch.FloatTensor([0.5]))13、为了查看生成器的损失值,在生成器里创建一个画图函数
def plot_progress(self):
df = pd.DataFrame(self.progress, columns=['loss'])
fig = df.plot(ylim=(0, 1.0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
fig.figure.savefig('../root/G_loss.png')
pass 14、查看生成器损失值
#使用鉴别器查看损失值
G.plot_progress()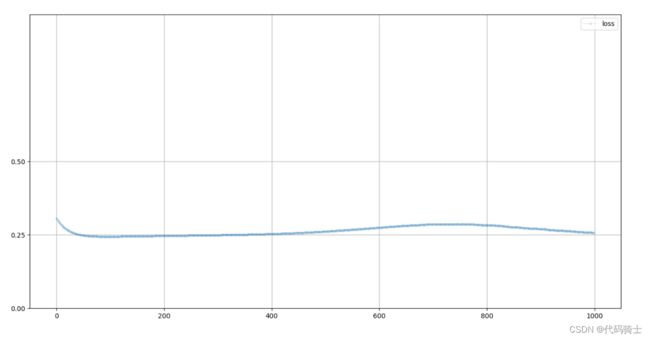
15、最后输出1010格式规律在训练过程中是如何演变的
plt.figure(figsize = (16,8))
plt.imshow(numpy.array(image_list).T, interpolation='none', cmap='Blues')
plt.savefig('../root/result.png')(2)采用GAN网络生成[1 0 1 0]结构的数据,保存实验重要过程及结果。
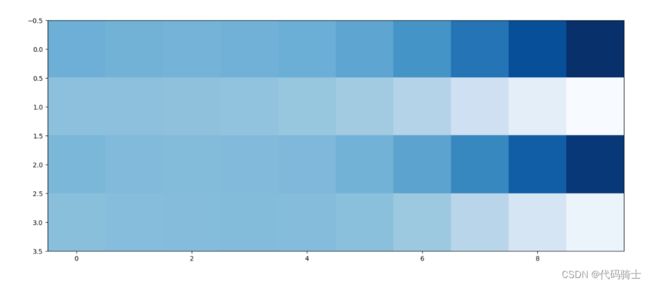
这个图表清楚地显示出随着时间改变,生成器如何改进的。
完整代码:
import torch
import torch.nn as nn
import pandas as pd
import matplotlib.pyplot as plt
import random
import numpy
def generate_real():
real_data = torch.FloatTensor([random.uniform(0.8,1.0),
random.uniform(0.0,0.2),
random.uniform(0.8,1.0),
random.uniform(0.0,0.2),
])
return real_data
def generate_random(size):
random_data = torch.rand(size)
return random_data
class Discriminator(nn.Module):
def __init__(self):
# 初始化 PyTorch 父类
super().__init__()
# 定义神经网络各层:线性层-sigmoid函数-线性层-sigmoid函数
self.model = nn.Sequential(
nn.Linear(4, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid()
)
# 使用均方值误差作为损失函数
self.loss_function = nn.MSELoss()
# 使用随机梯度下降(SGD)创建优化器
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# 计数器和累加器,用于流程控制和显示
self.counter = 0
self.progress = []
pass
def forward(self,inputs):
return self.model(inputs)
def train(self, inputs, targets):
# 计算网络的输出
outputs = self.forward(inputs)
# 计算损失值
loss = self.loss_function(outputs, targets)
# 每运行10次,增加计数器和累加器
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
# 将梯度置零,并运行反向更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pd.DataFrame(self.progress, columns=['loss'])
fig = df.plot(ylim=(0, 1.0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
fig.figure.savefig('../root/D_loss.png')
pass
D=Discriminator()
for i in range(10000):
D.train(generate_real(),torch.FloatTensor([1.0]))
D.train(generate_random(4),torch.FloatTensor([0.0]))
D.plot_progress()
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model=nn.Sequential(
nn.Linear(1,3),
nn.Sigmoid(),
nn.Linear(3,4),
nn.Sigmoid()
)
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
self.counter=0
self.progress=[]
pass
def forward(self, inputs):
# 简单的运行模型
return self.model(inputs)
def train(self,D,inputs,targets):
g_output=self.forward(inputs)
d_output = D.forward(g_output)
loss=D.loss_function(d_output,targets)
self.counter+=1
if(self.counter%10==0):
self.progress.append(loss.item())
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pd.DataFrame(self.progress, columns=['loss'])
fig = df.plot(ylim=(0, 1.0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
fig.figure.savefig('../root/G_loss.png')
pass
pass
G=Generator()
G.forward(torch.FloatTensor([0.5]))
# create Discriminator and Generator
D = Discriminator()
G = Generator()
image_list = []
# train Discriminator and Generator
for i in range(10000):
# train discriminator on true
D.train(generate_real(), torch.FloatTensor([1.0]))
# train discriminator on false
# use detach() so gradients in G are not calculated
D.train(G.forward(torch.FloatTensor([0.5])).detach(), torch.FloatTensor([0.0]))
D
# train generator
G.train(D, torch.FloatTensor([0.5]), torch.FloatTensor([1.0]))
# add image to list every 1000
if (i % 1000 == 0):
image_list.append( G.forward(torch.FloatTensor([0.5])).detach().numpy() )
pass
#使用鉴别器查看损失值
D.plot_progress()
#试验训练后第一次生成的数据
G.forward(torch.FloatTensor([0.5]))
#查看生成器的损失值
G.plot_progress()
plt.figure(figsize = (16,8))
plt.imshow(numpy.array(image_list).T, interpolation='none', cmap='Blues')
plt.savefig('../root/result.png')6、总结
个人版实验报告:
https://download.csdn.net/download/qq_51701007/87015804?spm=1001.2014.3001.5501