VScode中利用TensorFlow.js实现逻辑回归
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习中逻辑回归的基础内容,并利用TensorFlow.js实现逻辑回归算法。
一、逻辑归回归是什么?
逻辑回归也称作logistic回归分析,是一种广义的线性回归分析模型,属于机器学习中的监督学习。其推导过程与计算方式类似于回归的过程,但实际上主要是用来解决二分类问题(也可以解决多分类问题)。通过给定的n组数据(训练集)来训练模型,并在训练结束后对给定的一组或多组数据。
逻辑回归虽然名字中带有回归,但其解决的是分类问题。逻辑回归的输入是线性回归的结果,我们都知道线性回归的结果是一个数值,那如何将数值转成分类的呢?只需设置一个阈值即可,逻辑回归就是针对线性回归的结果设置一个阈值,当大于这个阈值我们就给它归为一类,当小于这个阈值的时候,我们就归为另一类。
例如:考试成绩有50、55、58、62、75、80,类别是及格和不及格,我们分别用0和1表示,我们规定只有分数达到60分才算及格,那这个60就是阈值,模型在训练的时候,通过学习可以把前三个归为不及格这一类别,后三个归为及格这一类别。当我们给一个新的成绩,模型会输出分别属于这两个类别的概率,我们取概率高的当成最终的结果。如模型预测分数70的结果为:[0:0.15,1:0.85],也即是不及格的概率为0.15,及格的概率为0.85。
二、实验步骤
1.加载二分类数据集
编写一个index.html和一个script.js文件。index.html当成项目的启动文件,主要功能代码写在script.js文件中。
index.html代码:
使用实现准备好的数据脚本生成数据。
在script.js中写如下代码。
import * as tfvis from '@tensorflow/tfjs-vis';
import {getData} from './data.js';
window.onload = () => {
// 利用数据脚本生成400个点
const data = getData(400);
console.log(data)
}生成的数据结果如图:
可以看见数据的整体情况,总共有400条数据,每条数据包括特征x和y,以及标签label。标签用0和1表示是因为我们最终输出的结果就是一个概率,这个概率在0到1之间,当这个概率大于阈值就认为属于1这一类,当这个概率小于阈值,就认为属于0这一类别。
可视化二分类数据集
// 可视化数据
tfvis.render.scatterplot(
{name: "逻辑回归训练数据"},
{
values:[
// 将0和1两类分开
data.filter(p => p.label === 0),
data.filter(p => p.label === 1),
]
}
)结果如下图所示:

2.定义模型结构
定义一个带有激活函数的单个神经元,只需单个神经元是因为我们问题比较简单,只需一个神经元拟合出一条直线就可以,激活函数的作用是帮助我们将输出结果转化成[0,1]之间的概率值。
导入TensorFlow.js
import * as tf from '@tensorflow/tfjs';初始化模型并添加全连接层
// 定义模型
const model = tf.sequential();
model.add(tf.layers.dense({
units: 1,
inputShape: [2],
activation: 'sigmoid'
}));model只add一次,说明只添加一层隐藏层。
units: 1,表示这一层的隐藏层神经元个数为1。
inputShape: [2],表示输入数据接收一维张量,每个维度的数据个数为2。
activation: 'sigmoid',表示激活函数采用sigmoid函数。 sigmoid的输出结果在[0,1]之间。
设置损失函数和优化器
损失函数采对数似然损失(交叉熵损失),优化器采用Adam优化器。
// 设置损失函数和优化器
model.compile({loss: tf.losses.logLoss, optimizer: tf.train.adam(0.1)})3、训练模型并可视化训练过程
将输入的数据和标签转成Tensor格式
因为我们这个问题是利用两个维度来分类的,分别是x和y,所以特征数据转成2维的Tensor,因为我们在上面定义模型输入数据形状的时候我们指定好输入数据的形状了。
标签就是一个用来最终判断预测结果和实际结果的偏差,用来计算损失值的,所以只需是张量的形式即可,其实这个张量是一个零维的张量。
const inputs = tf.tensor(data.map(p => [p.x, p.y]));
const labels = tf.tensor(data.map(p => p.label));训练并可视化
await model.fit(inputs, labels, {
batchSize: 32,
epochs: 50,
callbacks: tfvis.show.fitCallbacks(
{name:"训练过程"},
['loss']
)
});因为训练的过程是异步的,所以我们这边用await语法。
训练结果
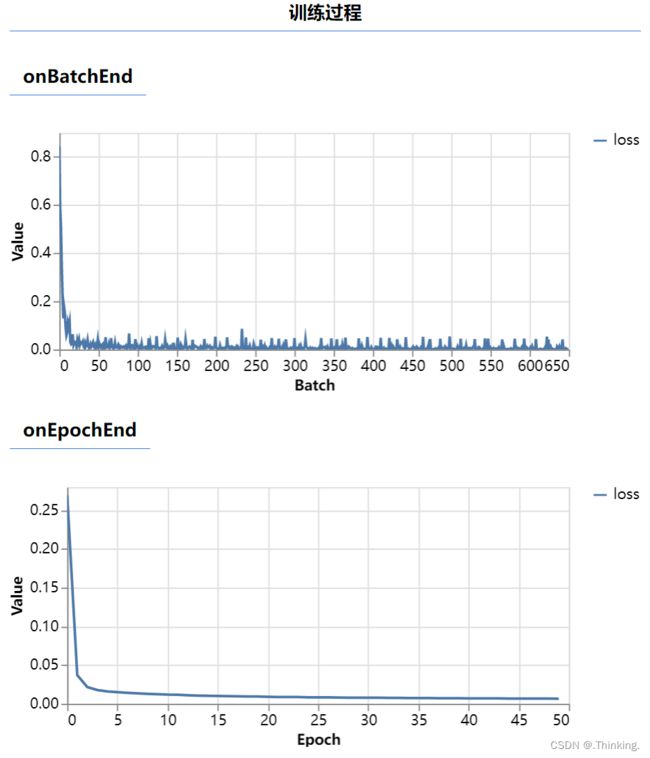
上图为每个Batch的训练结果,每次训练的数据量比较少,震荡比较厉害,下图为每个Epoch的训练结果,训练的数据量比较多,相对来说比较平滑。 (类比随机梯度下降和全批量梯度下降)
进行预测
编写前端页面输入待预测的数据,在index.html编写一个表单。
οnsubmit="predict(this):将当前这个表单当参数传入预测方法,方便取到x和y
return false:避免提交表单的时候页面发生跳转
使用训练好的模型进行预测
// 预测
window.predict = (form) => {
const pred = model.predict(tf.tensor([[form.x.value*1, form.y.value*1]]))
alert(`预测结果:${pred.dataSync()[0]}`);
} // 预测
window.predict = (form) => {
const pred = model.predict(tf.tensor([[form.x.value*1, form.y.value*1]]))
alert(`预测结果:${pred.dataSync()[0]}`);
}form.x.value*1:目的是将获取到的表单数据转成数值的格式
alert中的反单引号,并不是单引号,利用反单引号才可以在字符串中输出变量
结果如图

可以看到输入的点坐标是(2,2),预测结果非常接近1,是没问题的。
总结
项目源码:在VsCodes中利用TensorFlow.js实现逻辑回归-机器学习文档类资源-CSDN下载
以上就是今天要讲的内容,本文仅仅简单介绍了逻辑回归以及TensorFlow.js的使用。