Python中如何将多个dataframe表连接、合并成一个dataframe详解示例(如何将两个表合并行、合并列)--pandas中merge、join、concat、append的区别、用法梳理
Python中如何将多个dataframe表连接、合并成一个dataframe详解示例(如何将两个表合并行、合并列)--pandas中merge、join、concat、append的区别、用法梳理
我们在对Pandas中的DataFrame对象进行,表的连接、合并的时候,好像merge可以join也可以,哪到底他们有什么区别呢?我们使用的时候,该怎么选择哪个函数进行操作呢?本文就对merge、join、concat、append的使用方法进行梳理。文章的结构是,先说明各个函数的主要作用,最后用详细的代码,举例子演示,从而清晰的明白各个函数的功能定位。最后将各个函数的所有参数进行罗列,起到一个参考的作用。
操作的分类:包含pandas对象的数据可以通过多种方式是连接在一起,主要分为两类:
1)第一类:将两个pandas表根据一个或者多个键(列)值进行连接。这种操作类似关系数据库中sql语句的连接操作。这一类操作在使用pandas的merge、join操作来实现。
2)第二类:将两个pandas表在轴向上(水平、或者垂直方向上)进行粘合或者堆叠。这一类操作在使用pandas的concat、append操作来实现。
一、merge操作
merge函数实现sql数据库类似的各种join(连接)操作,例如内连接、外连接、左右连接等。
举例,创建两个dataframe变量df1,df2:
df1 = pd.DataFrame({'key': ['a', 'b', 'c', 'a', 'b'],
'data1': range(5)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2': range(3)})
df3 = pd.merge(df1,df2)进行merge操作:df3 = pd.merge(df1, df2)。结果如下:
df1为: ,df2为:
,df2为: ,输出结果
,输出结果
注意的是:
1)如果我们没有指定df1和df2使用哪个列进行连接。当这个时候发生的时候,merge会用两个对象中都存在的列名作为连接列。当然,最好还是清楚指定比较好,上述连接语句等效为:df3 = pd.merge(df1, df2, on='key')。这也是进行merge操作最常用的使用方式。
2)连接的方式。可以仔细看一下df3的输出结果,在结果中并没有c和d。因为merge默认是inner join(内连接)。也就是这个语句等效为:df3 = pd.merge(df1,df2,on='key',how='inner')。‘inner'连接方式,表示结果中的key是交集的结果,也就是两个表格中都有的集合。这里还有其他一些可选项,比如left, right, outer。outer join(外连接)取key的合集,其实就是left join和right join同时应用的效果。先分别看一下left、right、outer具体的输出:
left连接方式:df3 = pd.merge(df1,df2,on='key',how='left')的输出,如下:
df1为:,df2为:,left模式输出: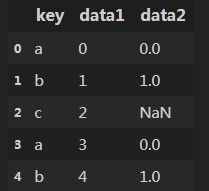 。
。
总结:left 连接模式的时候,所有在df1的key中的值,都能在结果中找到。只在df2的key中,没有在df1的key中的值,不会再结果中出现。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
right连接方式:df3 = pd.merge(df1,df2,on='key',how='right')的输出,如下:
df1为:,df2为:,right模式的输出:
结论:right连接模式的时候,所有在df2的key中的值,都能在结果中找到。只在df1的key中,没有在df2的key中的值,不会再结果中出现。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
oute连接方式:df3 = pd.merge(df1,df2,on='key',how='outer')
df1为:,df2为:,right模式的输出:
结论:outer连接模式的时候,只要在df1或者df2的key中的值,都能在结果中找到。outer连接模式相当于,left和right的合集。
好了,连接方式的说明就到这里了。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
3)当两个dataframe对象进行连接的列名不相同,这个时候需要分别指定,例如像df1的key_1,和df2的key_2进行连接操作。需要的语句df3 = pd.merge(df1, df2,left_on='key_1', right_on='key_2')
二、join操作
join操作是一个同merge相似的操作。jion操作可以直接用index来连接,但是要求两个dataframe要有一样的index但不能有重叠的列。例如:df3 = df1.join(df2, how='outer'),输出如下:
df1为: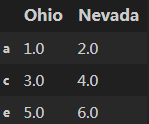 。df2为:
。df2为: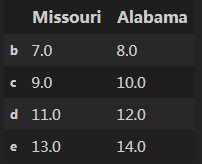 df3为:
df3为:
三、concat操作
concat操作可以将两个pandas表在轴向上(水平、或者垂直方向上)进行粘合或者堆叠。
使用方法:df3 = pd.concat([df1,df2])。看一下实现效果。
df1为: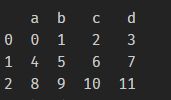 。df2为:
。df2为: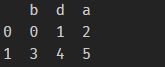 。df3为:
。df3为: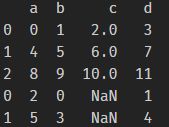
结论:concat实现了垂直方向的叠加,或者堆叠。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
水平方向的粘合,使用方法:df3 = pd.concat([df1,df2],axis = 1)。效果如下:
df1为:。df2为:。df3为: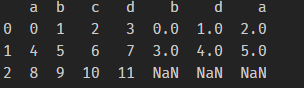
刚才进行concat垂直方向堆叠操作的时候,可以看到index是按照dataframe各自的顺序进行的。假如希望合并后的dataframe能够按照统一的index变好,可以使用ignore_index=True参数。
四、append操作
功能说明:向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加。
使用方法:df3 = df1.append(df2)
df1为:。df2为:。df3为:
发了吗,append操作的效果和concat的axis = 0 的效果是一样的。同样可以使用参数ignore_index=True,对合并后的dataframe重新编订索引。
好了,至此dataframe进行数据集合并的4个函数就说完了。如果你有更好的方式,可以留言告诉我。
五、索引参考
1.pandas.merge
pandas.merge(left, right, how: str = 'inner', on=None, left_on=None, right_on=None, left_index: bool = False, right_index: bool = False, sort: bool = False, suffixes=('_x', '_y'), copy: bool = True, indicator: bool = False, validate=None) → 'DataFrame'[source]
Merge DataFrame or named Series objects with a database-style join.
The join is done on columns or indexes. If joining columns on columns, the DataFrame indexes will be ignored. Otherwise if joining indexes on indexes or indexes on a column or columns, the index will be passed on.
Parameters
leftDataFrame
rightDataFrame or named Series
Object to merge with.
how{‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
Type of merge to be performed.
-
left: use only keys from left frame, similar to a SQL left outer join; preserve key order.
-
right: use only keys from right frame, similar to a SQL right outer join; preserve key order.
-
outer: use union of keys from both frames, similar to a SQL full outer join; sort keys lexicographically.
-
inner: use intersection of keys from both frames, similar to a SQL inner join; preserve the order of the left keys.
onlabel or list
Column or index level names to join on. These must be found in both DataFrames. If on is None and not merging on indexes then this defaults to the intersection of the columns in both DataFrames.
left_onlabel or list, or array-like
Column or index level names to join on in the left DataFrame. Can also be an array or list of arrays of the length of the left DataFrame. These arrays are treated as if they are columns.
right_onlabel or list, or array-like
Column or index level names to join on in the right DataFrame. Can also be an array or list of arrays of the length of the right DataFrame. These arrays are treated as if they are columns.
left_indexbool, default False
Use the index from the left DataFrame as the join key(s). If it is a MultiIndex, the number of keys in the other DataFrame (either the index or a number of columns) must match the number of levels.
right_indexbool, default False
Use the index from the right DataFrame as the join key. Same caveats as left_index.
sortbool, default False
Sort the join keys lexicographically in the result DataFrame. If False, the order of the join keys depends on the join type (how keyword).
suffixestuple of (str, str), default (‘_x’, ‘_y’)
Suffix to apply to overlapping column names in the left and right side, respectively. To raise an exception on overlapping columns use (False, False).
copybool, default True
If False, avoid copy if possible.
indicatorbool or str, default False
If True, adds a column to output DataFrame called “_merge” with information on the source of each row. If string, column with information on source of each row will be added to output DataFrame, and column will be named value of string. Information column is Categorical-type and takes on a value of “left_only” for observations whose merge key only appears in ‘left’ DataFrame, “right_only” for observations whose merge key only appears in ‘right’ DataFrame, and “both” if the observation’s merge key is found in both.
validatestr, optional
If specified, checks if merge is of specified type.
-
“one_to_one” or “1:1”: check if merge keys are unique in both left and right datasets.
-
“one_to_many” or “1:m”: check if merge keys are unique in left dataset.
-
“many_to_one” or “m:1”: check if merge keys are unique in right dataset.
-
“many_to_many” or “m:m”: allowed, but does not result in checks.
New in version 0.21.0.
Returns
DataFrame
A DataFrame of the two merged objects.
2.pandas.DataFrame.join
DataFrame.join(self, other, on=None, how='left', lsuffix='', rsuffix='', sort=False) → 'DataFrame'
Join columns of another DataFrame.
Join columns with other DataFrame either on index or on a key column. Efficiently join multiple DataFrame objects by index at once by passing a list.
Parameters
otherDataFrame, Series, or list of DataFrame
Index should be similar to one of the columns in this one. If a Series is passed, its name attribute must be set, and that will be used as the column name in the resulting joined DataFrame.
onstr, list of str, or array-like, optional
Column or index level name(s) in the caller to join on the index in other, otherwise joins index-on-index. If multiple values given, the other DataFrame must have a MultiIndex. Can pass an array as the join key if it is not already contained in the calling DataFrame. Like an Excel VLOOKUP operation.
how{‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘left’
How to handle the operation of the two objects.
-
left: use calling frame’s index (or column if on is specified)
-
right: use other’s index.
-
outer: form union of calling frame’s index (or column if on is specified) with other’s index, and sort it. lexicographically.
-
inner: form intersection of calling frame’s index (or column if on is specified) with other’s index, preserving the order of the calling’s one.
lsuffixstr, default ‘’
Suffix to use from left frame’s overlapping columns.
rsuffixstr, default ‘’
Suffix to use from right frame’s overlapping columns.
sortbool, default False
Order result DataFrame lexicographically by the join key. If False, the order of the join key depends on the join type (how keyword).
Returns:DataFrame
A dataframe containing columns from both the caller and other.
3.pandas.concat
pandas.concat(objs: Union[Iterable[Union[ForwardRef('DataFrame'), ForwardRef('Series')]], Mapping[Union[Hashable, NoneType], Union[ForwardRef('DataFrame'), ForwardRef('Series')]]], axis=0, join='outer', ignore_index: bool = False, keys=None, levels=None, names=None, verify_integrity: bool = False, sort: bool = False, copy: bool = True) → Union[ForwardRef('DataFrame'), ForwardRef('Series')][source]
Concatenate pandas objects along a particular axis with optional set logic along the other axes.
Can also add a layer of hierarchical indexing on the concatenation axis, which may be useful if the labels are the same (or overlapping) on the passed axis number.
Parameters
objsa sequence or mapping of Series or DataFrame objects
If a dict is passed, the sorted keys will be used as the keys argument, unless it is passed, in which case the values will be selected (see below). Any None objects will be dropped silently unless they are all None in which case a ValueError will be raised.
axis{0/’index’, 1/’columns’}, default 0
The axis to concatenate along.
join{‘inner’, ‘outer’}, default ‘outer’
How to handle indexes on other axis (or axes).
ignore_indexbool, default False
If True, do not use the index values along the concatenation axis. The resulting axis will be labeled 0, …, n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index values on the other axes are still respected in the join.
keyssequence, default None
If multiple levels passed, should contain tuples. Construct hierarchical index using the passed keys as the outermost level.
levelslist of sequences, default None
Specific levels (unique values) to use for constructing a MultiIndex. Otherwise they will be inferred from the keys.
nameslist, default None
Names for the levels in the resulting hierarchical index.
verify_integritybool, default False
Check whether the new concatenated axis contains duplicates. This can be very expensive relative to the actual data concatenation.
sortbool, default False
Sort non-concatenation axis if it is not already aligned when join is ‘outer’. This has no effect when join='inner', which already preserves the order of the non-concatenation axis.
New in version 0.23.0.
Changed in version 1.0.0: Changed to not sort by default.
copybool, default True
If False, do not copy data unnecessarily.
Returns
object, type of objs
When concatenating all Series along the index (axis=0), a Series is returned. When objs contains at least one DataFrame, a DataFrame is returned. When concatenating along the columns (axis=1), a DataFrame is returned.
4.pandas.DataFrame.append
DataFrame.append(self, other, ignore_index=False, verify_integrity=False, sort=False)
Parameters
otherDataFrame or Series/dict-like object, or list of these
The data to append.
ignore_indexbool, default False
If True, do not use the index labels.
verify_integritybool, default False
If True, raise ValueError on creating index with duplicates.
sortbool, default False
Sort columns if the columns of self and other are not aligned.
New in version 0.23.0.
Changed in version 1.0.0: Changed to not sort by default.
Returns
DataFrame