目标检测之YOLOX: Exceeding YOLO Series in 2021
CVPR 2021
下载:https://arxiv.org/abs/2107.08430
0.摘要
有几个特点:
1.anchor-free
2.主干网络CSPDarknet和Focus
3.Decoupled Head解耦头
4.SimOTA
1.主干网络CSPDarknet
yolov3中使用的是Darknet53,CSPDarknet是在其基础上,借鉴CSPNet的经验,产生的Backbone结构,而在yolox中的CSPDarknet也使用了Focus网络。

1.1Focus
Focus和espcn操作正好相反,具体操作是在一张图片中每隔一个像素拿一个值,这个可以获得4个独立的特征层,然后将4个特征层进行堆叠,此时就将宽高维度上的信息转换到了通道维度,可以看作是一个特殊的下采样操作。输入640, 640, 3经过focus后获得 320, 320, 12的特征图,经过一次1*1卷积后获得了320, 320, 64的特征图。
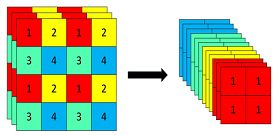
1.2CSPLayer
就是大残差套小残差的结构,将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后,最后通过concat的方式连接。因为使用的是concat而且要保证通道数不变,所以两条支路都要压缩通道到原来的二分之一。在之前的很多篇论文中有过类似的结构。
class CSPLayer(nn.Module):
def __init__(self, in_channels, out_channels, n=1, shortcut=True, expansion=0.5, depthwise=False, act="silu",):
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
module_list = [Bottleneck(hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act) for _ in range(n)]
self.m = nn.Sequential(*module_list)
def forward(self, x):
x_1 = self.conv1(x)
x_2 = self.conv2(x)
x_1 = self.m(x_1)
x = torch.cat((x_1, x_2), dim=1)
return self.conv3(x)
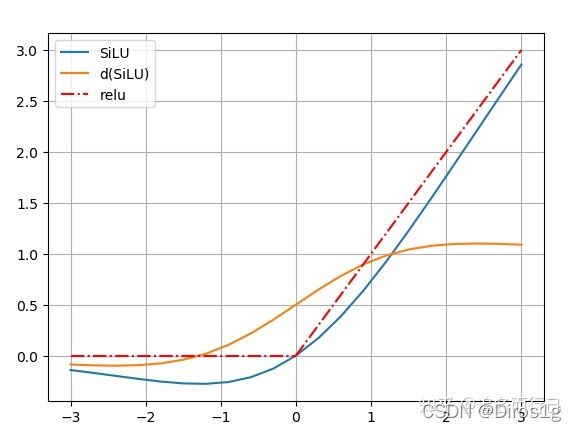
1.3SiLU激活函数
使用了全新的激活函数 S i L U : f ( x ) = x ⋅ s i g m o i d ( x ) SiLU:f(x)=x⋅sigmoid(x) SiLU:f(x)=x⋅sigmoid(x),SiLU在深层模型上的效果优于 ReLU
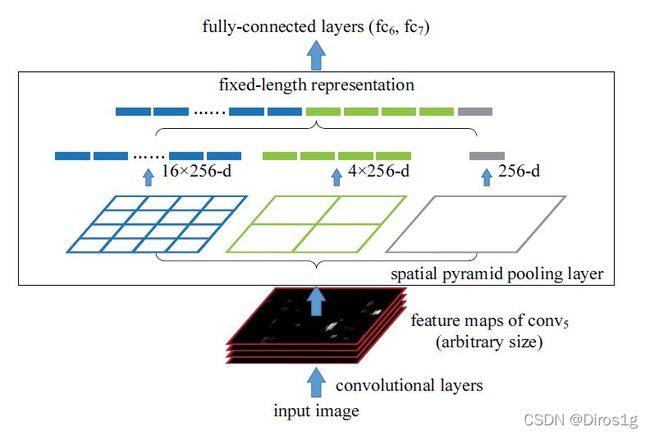
1.4SPP空间金字塔池化层
在主干网络的最后也使用spp网络,spp使用不同大小感受野的最大池化提前特征,最后都concat在一起
class SPPBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2) for ks in kernel_sizes])
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
2.FPN
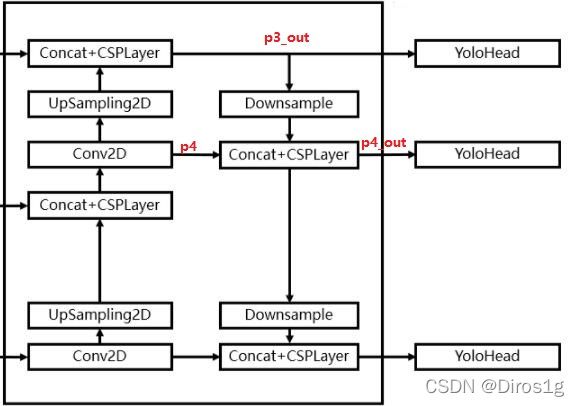
改进了fpn的结构,增加了下传和csplayer
上传:以最后一层特征特征上采样为例,(20,20,1024)的特征层进行1次1X1卷积调整通道后获得(20,20,512)的特征,再进行上采样后与倒数第二层(40,40,512)特征层进行concat后得(40,40,1024),再使用CSPLayer进行特征提取获得(40,40,512)的特征。同理再上传获得的特征层为P3_out=(80,80,256)
下传:P3_out=(80,80,256)的特征层进行一次3x3卷积进行下采样得(40, 40, 256),再与P4concat,然后使用CSPLayer进行特征提取P4_out,此时获得的特征层为(40,40,512)。
3. Yolox head
yoloxhead负责接收fpn后的特征进行预测。
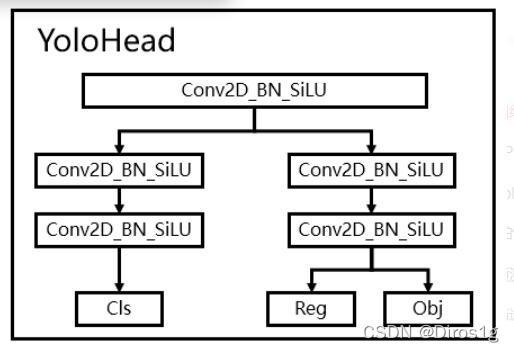
3.1Decoupled Head解耦头
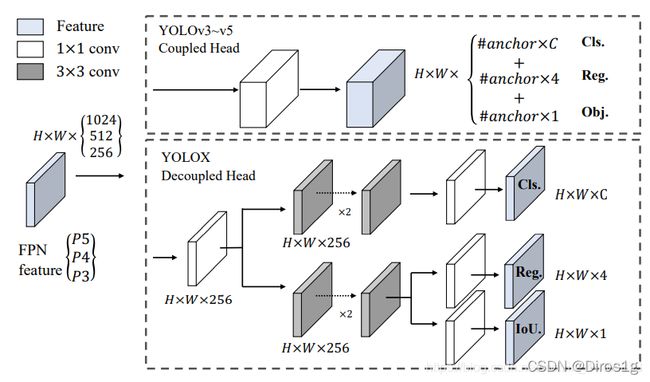
耦合的意思是,yolo之前在box回归和class预测的时候都是通过同一个1*1卷积,会相互影响产生耦合效应。在YoloX中,Yolo Head被分为了两部分,分别实现,最后预测的时候才整合在一起。
Out(h,w,4+1+num_classses)前四个参数用于回归参数调整后可以获得预测框;第五个参数用于判断每一个特征点是否包含物体;最后num_classes个参数用于判断每个像素上物体种类。通过两个卷积计算后,再concat,由于使用了fpn有不同尺度的预测所以还得把三种尺度(20,40,80)的预测再合在一起。
def forward(self, inputs):
outputs = []
for k, x in enumerate(inputs):
x = self.stems[k](x)
cls_feat = self.cls_convs[k](x)
cls_output = self.cls_preds[k](cls_feat)
reg_feat = self.reg_convs[k](x)
reg_output = self.reg_preds[k](reg_feat)
obj_output = self.obj_preds[k](reg_feat)
output = torch.cat([reg_output, obj_output, cls_output], 1)
outputs.append(output)
return outputs
3.2anchor free
anchor base的模型在训练之前就需要进行聚类分析以确定一个最优的锚框集合。这些聚类出来的锚框是特异的,不具有普适性,所以使用anchor free。
将YOLO切换为anchor-free的方式非常简单,将每个位置的预测从3个减少(基于anchor的yolo有三个尺度)到1个,并使它们直接预测4个值,即网格左上角的两个偏移量,以及预测框的高度和宽度。
4.simOTA
ota: Optimal Transport for Label Assignment,以往在正负样本匹配的时候,一般是以IOU大于0.7为正样本,IOU小于0.3为负样本。OTA是一个专门进行标签分配的优化算法,他能考虑全局信息分配正负样本。这种正负样本分配方式适合于多目标检测。
simOTA计算流程如下:
1、计算每个真实框和当前特征点预测框的重合程度。
2、计算将重合度最高的十个预测框与真实框的IOU加起来求得每个真实框的k,也就代表每个真实框有k个特征点与之对应。
3、计算每个真实框和当前特征点预测框的种类预测准确度。
4、判断真实框的中心是否落在了特征点的一定半径内。
5、计算Cost代价矩阵。
6、将Cost最低的k个点作为该真实框的正样本。
5.实验结果
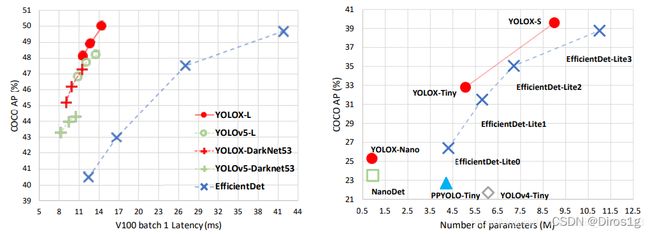
作者修改骨干网络的规模一共衍生了7种不同的网络:nano和tiny是轻量级的,其余为标准网络
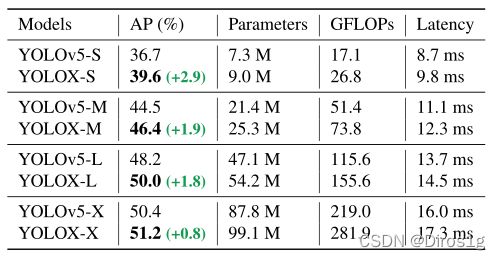
个人实验:在voc2007+2012上yolox-x的map:87.88%,yolov3with darknet53:87.16%。尝试替换yolox中fpn的上采样方式为图像超分辨率,效果并不好,map下降到79.5%。