轻量化网络系列 | 解读MobileNet V1-V3
MobileNet V1 论文原文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNet V2 论文原文:MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNet V2 论文原文:Searching for MobileNetV3
目录
- 1. MobileNet-V1
-
- 1.1 核心思路
- 1.2 详解
- 2. MobileNet-V2
-
- 2.1 核心思路
- 2.2 详解
- 3. MobileNet-V3
-
- 3.1 核心思路
- 3.2 详解
1. MobileNet-V1
文章标题:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
作者单位:Google Inc.
网络精度:TOP-1 Accuracy 70.6%
1.1 核心思路
-
利用 Xception 提出的深度可分离卷积替换传统的标准卷积,大幅减少了模型参数量和计算量,对于相同分辨率的方形图像,深度可分离卷积的计算量仅为标准卷积的 1 N + 1 D K 2 \frac{1}{N}+\frac{1}{D_K^2} N1+DK21 ;
-
给出两个超参数 Width Multiplier 和 Resolution Multiplier,分别记为 α α α 和 ρ ρ ρ ,进一步缩小模型以用于更为特殊的场合。
1.2 详解
1. Depthwise Separable Convolution(深度可分离卷积)
深度可分离卷积的思想灵感来自于一篇博士论文《Rigid-motion scattering for image classification》,而后在 Xception 中被提出并使用(并非 MobileNet V1 首创,但都是Google所提)。
深度可分离卷积分为深度卷积(depthwise convolutions)和逐点卷积(pointwise convolutions)两部分,深度卷积导致不同通道之间的信息无法进行交互,所以设置了逐点卷积让深度卷积后的特征图进行线性的结合,也就是实现通道间的信息融合。

2. 标准卷积和深度可分离卷积的计算量比较
若假设 D K D_K DK 是卷积核的大小, M M M 是输入通道数, N N N 是输出通道数。对于一张 D F × D F × M D_F×D_F×M DF×DF×M 的方形特征图,标准卷积的计算量为: D K ⋅ D K ⋅ M ⋅ N ⋅ D F ⋅ D F D_K·D_K·M·N·D_F·D_F DK⋅DK⋅M⋅N⋅DF⋅DF,而深度可分离卷积的计算量为: D K ⋅ D K ⋅ M ⋅ D F ⋅ D F + M ⋅ N ⋅ D F ⋅ D F D_K·D_K·M·D_F·D_F+M·N·D_F·D_F DK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF 。
其中, D K ⋅ D K ⋅ M ⋅ D F ⋅ D F D_K·D_K·M·D_F·D_F DK⋅DK⋅M⋅DF⋅DF 对应于深度卷积的计算量, M ⋅ N ⋅ D F ⋅ D F M·N·D_F·D_F M⋅N⋅DF⋅DF 对应于逐点卷积的计算量。
两者计算量相除可以得到:
D K ⋅ D K ⋅ M ⋅ D F ⋅ D F + M ⋅ N ⋅ D F ⋅ D F D K ⋅ D K ⋅ M ⋅ N ⋅ D F ⋅ D F = 1 N + 1 D K 2 \frac{D_K·D_K·M·D_F·D_F+M·N·D_F·D_F}{D_K·D_K·M·N·D_F·D_F }=\frac{1}{N}+\frac{1}{D_K^2} DK⋅DK⋅M⋅N⋅DF⋅DFDK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF=N1+DK21
其中, 1 D K 2 \frac{1}{D_K^2} DK21 便是深度可分离卷积相对于标准卷积所减少的计算量比例。
若是进一步引入两个超参数 α α α 和 ρ ρ ρ,则计算量可以进一步缩减至 D K ⋅ D K ⋅ α M ⋅ ρ D F ⋅ ρ D F + α M ⋅ α N ⋅ ρ D F ⋅ ρ D F D_K·D_K·αM·ρD_F·ρD_F+αM·αN·ρD_F·ρD_F DK⋅DK⋅αM⋅ρDF⋅ρDF+αM⋅αN⋅ρDF⋅ρDF,此时与标准卷积的计算量比为:
D K ⋅ D K ⋅ α M ⋅ ρ D F ⋅ ρ D F + α M ⋅ α N ⋅ ρ D F ⋅ ρ D F D K ⋅ D K ⋅ M ⋅ N ⋅ D F ⋅ D F = α ρ 2 N + α 2 ρ 2 D K 2 \frac{D_K·D_K·αM·ρD_F·ρD_F+αM·αN·ρD_F·ρD_F}{D_K·D_K·M·N·D_F·D_F} =\frac{αρ^2}{N}+\frac{α^2 ρ^2}{D_K^2} DK⋅DK⋅M⋅N⋅DF⋅DFDK⋅DK⋅αM⋅ρDF⋅ρDF+αM⋅αN⋅ρDF⋅ρDF=Nαρ2+DK2α2ρ2
其中, α α α 和 ρ ρ ρ 的取值范围为 [0,1]。
3. 网络结构

计算时间和参数量占比情况:
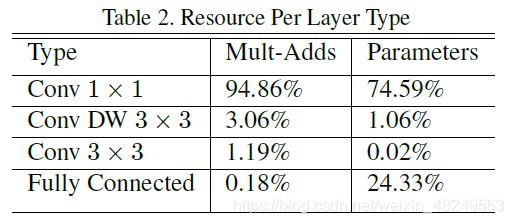
可见,MobileNet V1 中逐点卷积的计算时间和参数量都占据了绝大比重,这也是后续 ShuffleNet V1 所提出的一个观点。
4. MobileNet V1的性能表现

标准的 MobileNet V1 在 ImageNet 数据集上的 TOP-1 Accuracy 为 70.6%,高于 GoogLeNet ,但其计算时间仅为 GoogLeNet 的 1/3 左右。相较于 VGG-16 而言,虽然精度上降低了 0.9%,但在计算时间和参数量上都实现了大幅度的降低。
2. MobileNet-V2
文章标题:MobileNetV2: Inverted Residuals and Linear Bottlenecks
作者单位:Google Inc.
网络精度:TOP-1 Accuracy 72.0%(ImageNet)
2.1 核心思路
- 在卷积模块后插入 linear bottleneck 来捕获兴趣流形,防止非线性破坏太多信息;
- 在MobileNet V1所设计的深度可分离卷积前加入 expansion layer(1x1卷积),让深度卷积在更高维进行操作,称为倒置残差结构(Inverted residual block);
- 结合思路(1)和(2),设计模块:The inverted residual with linear bottleneck,也是文章的最主要贡献。即,将一个低维特征扩展至高维后,再送入深度卷积,随之再经过 1x1 卷积再压缩回至低维。
2.2 详解
1. ReLU存在的问题 / Linear Bottlenecks
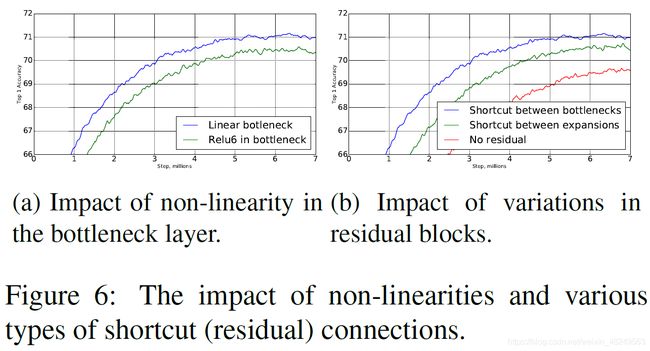
长期以来认为神经网络中的兴趣流形可以嵌入至低维子空间再进行其他操作,也就是说我们常习惯于将特征进行降维之后再进行操作,从而减少计算量,这也在 MobileNet V1 中得到了成功印证( width multiplier 的应用)。但是,文章发现低维特征经过 ReLU 激活后,会损失大量信息,而在高维时,经ReLU激活后依然可以保存绝大部分信息(如下图实验)。这也是为什么文章设计出 Inverted residual block 的重要原因。【这一结论放在实际操作中,便是通道数少的特征图之后不应该接 ReLU 激活函数,否则特征图将被严重破坏。而后的实验表明用线性激活函数可以解决这一问题(文献[9]也有这一相似结论),也就是文章标题所说的 Linear Bottlenecks。】

如果兴趣流形经过 ReLU 变换后得到非零的结果,这时 ReLU 其实就是一个线性变换;只有当输入流形可包含在输入空间的低维子空间中,ReLU 才能较完整保存输入流形的信息。
同时,文章对于什么样的维度为低维度,什么样的维度为高维度并没有给出一个明确的区分标准。
2. Inverted residual block
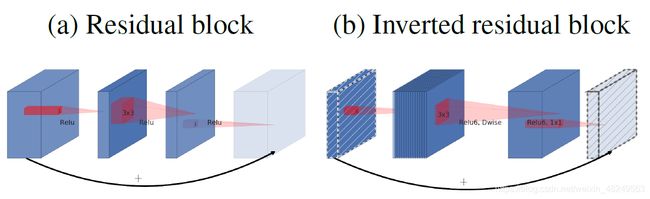
基于 ReLU 在低维空间表现不佳而在高维空间表现好的实验结论,文章想到在深度可分离卷积前增加一个 1x1 卷积用以增加特征图维度,称此 1x1 卷积为 expansion layer,对应的维度扩展倍数称之为扩展因子,记为 t t t(文章中将 t t t 设为6)。同时,借鉴 ResNet 引入 shortcut 结构,由于与 ResNet 中的 Residual block 正好相反( Residual block 是先降维卷积再升维,Inverted residual block 是先升维卷积再降维),所以称之为Inverted residual block 。另外,将 ReLU 激活函数替换为 ReLU6 (文章说低精度运算时 ReLU6 具有更强的鲁棒性)。
此外,扩展因子 t t t 取值为 0 至 1 时,便是经典的 Residual block,但 MobielNet V2 认为t取值大于 1 时效果最好,并且这种结构能够在实现上减少内存的使用。
Inverted residual block 内部具体结构:

与 MobileNet V1 的对比:
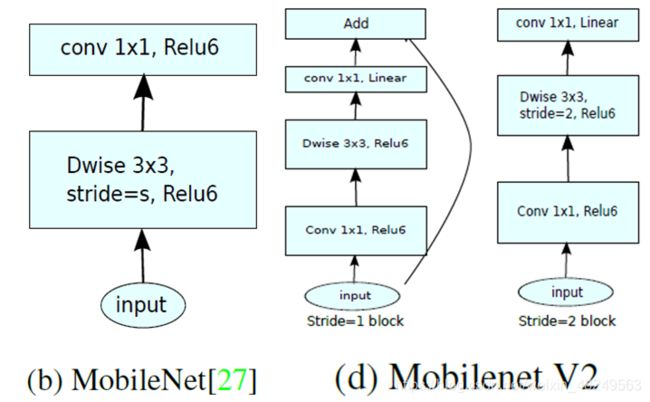
除了两者 Module 结构上的区别,MobileNet V2 在卷积步长为 1 时引入 shortcut 结构,步长为 2 则不引入 shortcut 结构(步长为 2 时 input 和 output 的图像大小已不相同,无法进行 element-wise 的相加操作)。而 MobileNet V1 无论卷积的步长为多少,均无 shortcut 结构。
文章对 shortcut 结构是否有必要及不同的连接方式,以及使用 ReLU6 和线性激活函数的不同性能表现进行了实验(纵轴为 TOP-1 Accuracy,横轴为训练步长),才得到上述所看到的 Module 结构。
3. 网络结构

其中,t 为扩展因子,c 为输出通道数,n 为相同 bottleneck 的重复次数,s 为
MobileNet V2 也同 VGG 一样对自己所设计的 bottleneck 进行堆叠操作,从而得到整个网络框架。
另外,文章还指出其所做的实验发现,若将 MobileNet V2 设计得更深更大时,更大的扩展因子会有更好的效果;设计得更小时,更小的扩展因子会有更好的效果。
4. MobileNet V2的性能表现(ImageNet Classification)
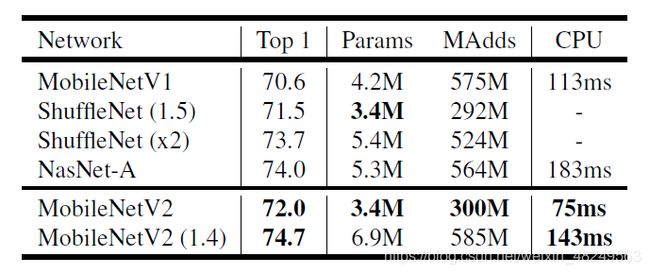
标准的 MobileNet V2 在 ImageNet 分类上的 TOP-1 Accuracy 为 72.0%,比 V1 版本高出 1.4%,同时在参数量和运算速度又有了进一步提升,在手机 CPU 上运行时间为 75ms (the Google Pixel 1 phone)。
3. MobileNet-V3
文章标题:Searching for MobileNetV3
作者单位:Google AI;Google Brain
网络精度:TOP-1 Accuracy 75.2% (Large版本) 64.7%(Small版本)
3.1 核心思路
MobileNet V3 推出 Large 版本和 Small 版本,适用于不同算力资源的情况。首先使用NAS算法优化每一个block,得到大体的网络结构,然后使用NetAdapt算法来确定每个filter的channel的数量。(在16块TPU训练好后再放在Pixel系列手机进行测试)
结构上相较于 MobileNet V2 而言:
- 引入 SE 模块( SENet 中的一个 block );
- 修改尾部结构,将平均池化层前的 1x1 卷积放置层后(和 ShuffleNet V2 一样指出 1X1 卷积占据了大量的运算时间,放在池化层后可以减少计算量从而缩短计算时间);
- 修改第一个卷积核的通道数( 32 改为 16 );
- 改用 h-swish 激活函数。
MobileNet V3 其实并没有特别惊艳的结构提出,最主要的还是应用了诸如 SE、H-Swish等 tricks,然后利用 Google 自己提出的 NAS 以及 NetAdapt 算法进行结构的自动搜索,提升了一定的精度和速度。(正对应标题 “Searching for” 一样,MobileNet V3 重点突出自动搜索网络结构的有效性)
3.2 详解
1. h-swish 激活函数
Google 此前提出 swish 激活函数替换 ReLU ,提高了网络准确性。但考虑到 sigmoid 函数(计算 swish 需要计算 sigmoid )在移动设备计算成本很高,于是考虑用 h-swish 激活函数近似 swish 函数。
swish激活函数: s w i s h ( x ) = x ⋅ σ ( x ) swish(x)=x·σ(x) swish(x)=x⋅σ(x)
h-swish激活函数: h − s w i s h [ x ] = x ( R e L U 6 ( x + 3 ) ) 6 h-swish [x] = \frac {x (ReLU6(x+3))}{6} h−swish[x]=6x(ReLU6(x+3))
实验证明,这个近似很有效(网络精度也不受影响):

2. MobileNet V3 block

3. 在尾部结构的修改

由于将原来放在平均池化层前的1x1卷积放置在了平均池化层后,这使得计算量大幅减少(49倍),也就可以进一步移除先前用于压缩计算量的bottleneck(bottleneck就没什么存在必要了),进而得到上图Efficient last stage的结构。文章还指出,这样的结构使得延迟进一步减少了7ms(11%),MAdds减少了30millions,并且没有降低网络精度。
4. Large版本网络结构

5. Small版本网络结构

6. MobileNet V3的性能表现
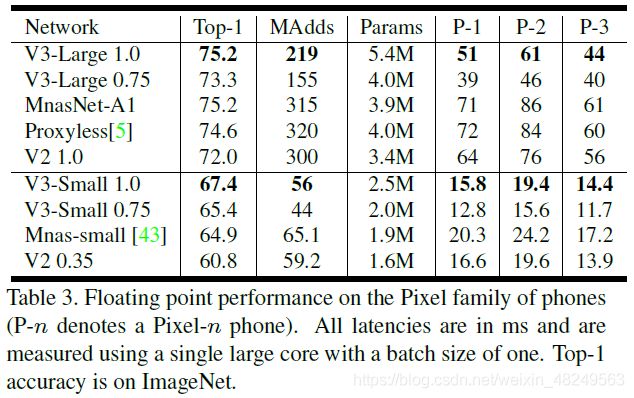
下图分别是MobileNet V3的Large版本和Small版本与其他轻量级网络在Pixel 1手机上的计算延迟与ImageNet分类精度的比较。可见MobileNet V3取得了显著的比较优势。

与MobileNet V2的性能(精度和速度)比较:
