基于mmrotate的旋转目标检测入门详解
一、旋转目标检测方法对比
1 当前前沿方法的对比
首先我们打开papers with code 网站
https://paperswithcode.com/
我们在搜索栏输入 oriented object detection等与旋转目标检测相关的关键字,可以看到有很多相关的方法,我们打开其中的一个方法(点击框选部分即可)。

然后我们将下拉框拉到最底端,点击compare。

然后我们可以看到各种方法在dota数据集上的MAP排名以及各方法的年份,点击方法名称可以进入查看相应的paper和开源在github上的code。这里简单介绍一下dota数据集,其是一个开源的航拍数据集,图片很大且待检测物体大多紧密排列且宽高比很大,使用传统的竖直框回归会造成很大误差,所以多用来进行旋转检测,也是所有旋转检测方法几乎必用的基准数据集之一。
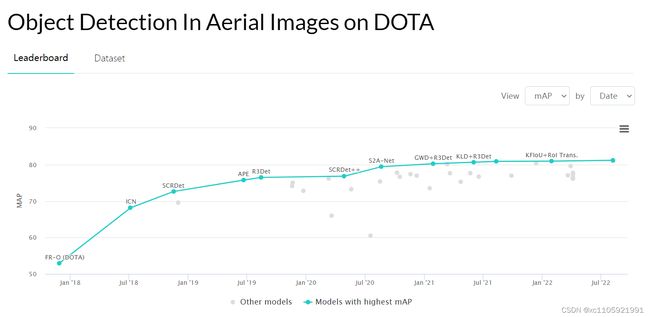

2 几种测试过的效果较好的方法
首先这里说明一下,和竖直框的目标检测方法一样,旋转目标检测大体也分为one-stage和two-stage(区别可以参考yolo和fater-rcnn的区别)两种,当然也有一些创新的anchor-free 的方法,但是没有前两种方法成熟,现在根据不同需求使用的普遍是前两种方法。
one-stage:
这里推荐S2A net 和R3 Det两种方法,优势在于检测速度快,训练成本低,当然缺陷在于回归精度会稍微低一些。
two-stage:
推荐oriented-rcnn和ReDet两种方法,精度上都很高,检测速度上也说得过去,当然训练成本较高,需要较高算力和显存的GPU。
这里特别说一下,如果需要检测密集且较小的目标可以尝试一下SCR Det、SCR Det++和 DRN方法,他们的模型结构对小目标和和密集目标效果可能会好一点。
二、基于mmrotate框架的环境搭建(windows&ubuntu)
首先到github中的mmlab中寻找mmrotate
https://github.com/open-mmlab/mmrotate
下拉可以看到README.md中介绍的Installation部分(这是作者认为最好的安装方式,我们也可以点击红色框选部分查看详细的安装步骤和其他的安装方式)

点进install guide 我们可以看到配置mmrotate环境的needs:

也就是说想要使用mmrotate需要的最低版本是Python3.7 CUDA 9.2 Pytorch 1.6
作者介绍了一种最方便的方法:
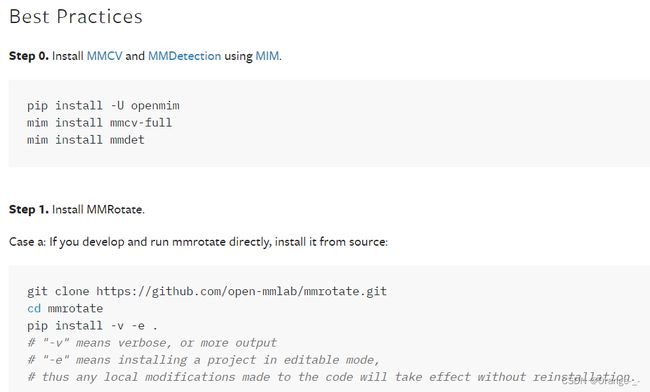
作者在这里介绍了用mim安装mmcv和mmdet的方法,其中mmcv中包含c++和CUDA的扩展,并且以一种复杂的方式依赖pytorch,如果用mim来安装的话可以自动解决这些问题,让安装变得更简单。
以下作者又介绍了一种更灵活的方法:
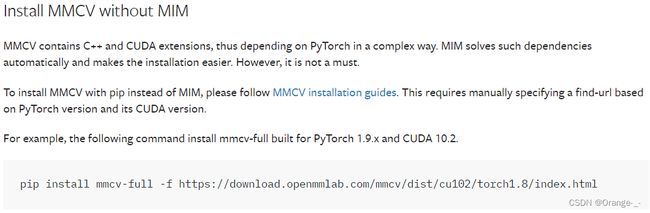
这里没有使用mim来安装mmcv
总结:虽然作者 介绍的最简单的方式看起来很简洁,但是在我们安装的时候总会有很多问题,经常会在下载mmcv的时候各种error,所以在这里我们重点介绍并且推荐使用第二种灵活的方法。
# 1 创建所需的虚拟环境并激活
conda create -n MMRotate python=3.8
conda activate MMRotate
# 2 安装 pytorch 和 cuda
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
# 3 安装对应版本的 mmcv 库
pip install mmcv-full==1.6.0 -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.10.0/index.html
# 4 安装mmdet
pip install mmdet
# 5 安装mmrotate库
#使用cd命令到mmrotate的文件夹下,然后运行
pip install -r requirements/build.txt
pip install -v -e .我们重点来说一下 3 mmcv库的安装方法,首先我们进入github搜索mmcv并进入。
https://github.com/open-mmlab/mmcv
在README.md中找到CUDA、torch和mmcv的对应关系,我们找到自己的CUDA和torch版本,在对应的地方点击install就会有相应的命令,复制到命令行执行就好了。

然后我们会得到命令pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.10.0/index.html
我们将{mmcv_version}替换成我们需要的mmcv的版本就好了。
这里直接运行命令行程序后可能因为网络等原因导致各种安装error这里补充一下如果这种方法安装失败应该如何安装:
复制对应命令的下载路径在这里我们的路径是https://download.openmmlab.com/mmcv/dist/cu102/torch1.10.0/index.html,进入网站
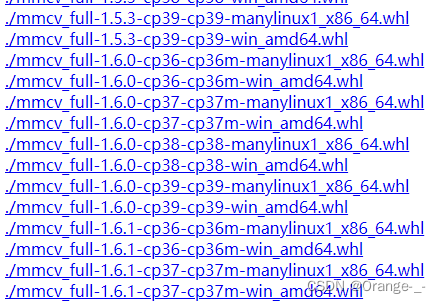
最前面的mmcv_full-x.x.x 代表mmcv的版本,推荐尽可能选择较新的版本下载,cp38代表适用于python 3.8,如果你的系统是Windows就下载win_amd64版本,如果是linux就下载manylinux1_x86_64版本,选择好我们对应版本的whl后直接单击就开始下载了。
然后我们使用cd 进入下载.whl的文件夹内,运行指令pip install xxx.whl即可完成安装。
我们再来说一下 5 mmrotate的安装:
mmrotate的安装其实有两种方式(均需要提前安装mmrotate依赖的requirements/build.txt)
1、如果你想让mmrotate作为第三方库被安装直接运行以下代码即可
pip install mmrotate2、如果你想直接用mmrotate运行和开发,运行以下代码(显然我们在这里是使用这种方式来使用mmrotate)
cd mmrotate
pip install -v -e .这里再介绍一下第二种方法的区别,第一种方法我们应该都很熟悉了,将其作为一个第三方包引入环境并调用他的各种功能,用第二种方法安装后我们的mmrotate文件夹里会多出一个叫mmrotate.egg-info名的文件,该文件作为一种link手段将我们的mmrotate文件夹链接成能被我们引用的库的形式,当我们修改文件夹内的一些代码或者结构的时候相应的在python中被我们引用的库也会随之改变,也就说我们可以动态调整这个库的一些结构和参数。也就解释了这里的-e的含义,以可编辑的模式安装。
补充:
尽可能安装较新版本的mmcv库,否则可能出现mmrotate中使用了某个算法但是mmcv中还没有更新这个算法的情况,如果你的CUDA版本较低且使用Windows环境很可能只能下载版本不高的mmcv库,这时候可以尝试降低mmrotate的版本来使它们相适应(方法如下)。
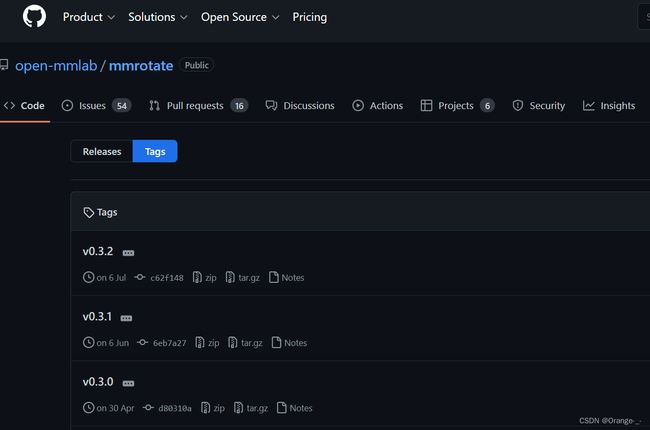
在这里我们可以选择更低版本的mmrotate进行下载。
测试
到这里我们的环境就搭建完成了,我们到mmrotate文件夹里进入demo文件夹中,找到image_demo.py
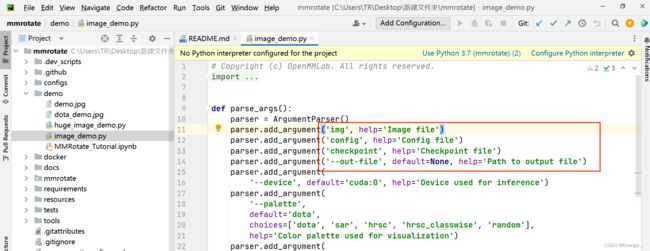
这里解释一下 参数前面没有--的是必填参数(所以没有default),带--的是选填参数,必填参数是在用命令行里必须输入的参数(如python image_demo.py 'Image file' 'Config file')。
如果我们想从pycharm里直接用需要把必填参数改成选填参数,然后加上default就好了。(注意:如果不把必填参数改成选填参数的形式即使加了default也是无效的,必填参数是不读取默认值的,运行还是会提示缺少对应参数)。
修改后如图:

现在来介绍一下各参数的意义
--img :这里就是放输入图片的路径,因为我们的demo文件夹下已经有了两张测试图片,直接使用就可以,default=demo.jpg
--config:这里放入模型结构文件(配置文件),mmrotate支持的模型结构都放在mmrotate文件夹下的configs文件夹里了
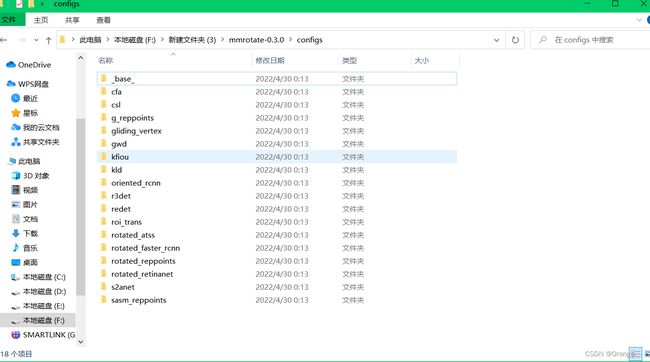
选择我们一种我们想要的方法进去后里面会有很多这种方法相关的融合了不同technique的模型结构:
--checkpoint:对应模型的预训练权重文件
在这里我们需要下载和配置文件相对应的预训练权重文件https://github.com/open-mmlab/mmrotate/blob/main/docs/en/model_zoo.md
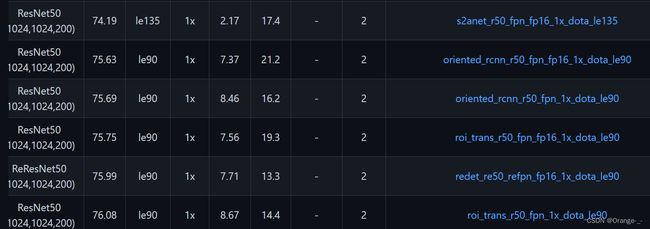
注意:大家可能注意到了这里的文件都有很长的、以_进行分割的名字,我在这里来解释一下它代表的含义,以oriented_rcnn_r50_fpn_fp16_1x_dota_le90为例,这里oriented_rcnn指该模型使用的核心方法是oriented-rcnn(需要了解具体方法的可以看看oriented-rcnn的论文原文),r50代表使用的backbone是resnet50,fpn是一种多尺度检测的方法,fp16指采用半精度(可以提高推理速度),1x指训练策略选用1x的策略,dota表示该权重是在dota数据集上训练的,le90表示该模型的输出格式(即输出头的格式)是le90。
关于旋转目标检测的几种输出格式(表示方式)有le90,le135,oc
如果不明白这里推荐可以看一下这个https://zhuanlan.zhihu.com/p/459018810,里面详细解释了各种表示方法的由来和相互转换关系。
--out-file:输出结果的保存路径,检测后的图片会被保存到这个路径下。
将以上的参数都修改完毕后我们就可以运行程序了,可以直接在pycharm上运行image_demo.py,当然也可以在命令行cd进入mmrotate文件夹中的demo文件夹中并输入指令
python image_demo.py
此时如果没有报错,程序成功运行并返回了输出的结果则说明我们的环境没有问题。
三、使用mmrotate的工具分割数据集图片
由于我们选择的模型是以dota的格式进行训练的,所以我们必须将label转换成dota数据集的格式才能使用,由于我是使用自己写的标注工具进行标注的,这里就不详细介绍得到label的过程了,简单解释一下dota数据集label代表的含义:

这里xi,yi代表旋转矩形框的第i个点,要求四个点是顺时针排列即可,category代表要检测物体的类别名称,difficult指该物体是否难检测,1代表难检测,0代表不难检测。
由于mmrotate的模型需要的输入图片格式都是1024x1024的,我们自定义的数据集可能要大于这个尺寸,这时我们需要对输入图片进行裁剪成若干1024x1024大小的图片输入模型进行训练(如果我们的图片小于1024x1024则可以采用填充的方法将图片填充成1024x1024的)。
我们首先把数据集手动划分为train、val、test(比例一般8:1:1)。
这里我们需要用到mmrotate自带的脚本:
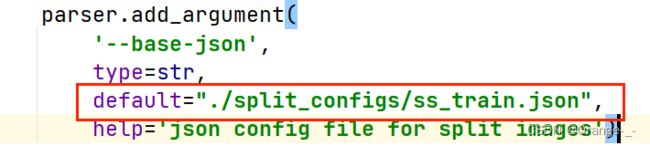
我们使用mmrotate/tools/data/dota/split/img_split.py和mmrotate/tools/data/dota/split/split_configs/ss_train.json来完成裁剪(这里以train训练集为例)

这里ss_train.json是配置文件,修改base-json参数后让其指向ss_train.json就可以使用其中的配置信息(如下图所示)。
这样我们就可以通过修改ss_train.json文件中的参数来改变裁剪的属性了,如下图。
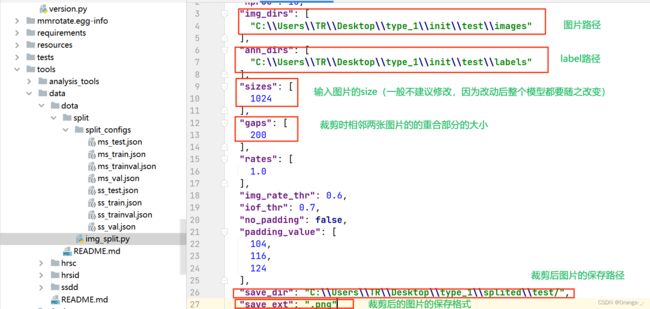
这里解释一下ss-train.json和ms_train.json的区别,ss指single scale,只是做单纯的裁剪,不对图片进行多尺度裁剪,ms指multiscale,对图片进行多尺度裁剪。
val验证集和test测试集的裁剪方法一致就不赘述了,只需要调整对应的配置文件即可,当然也可以只用一个配置文件,每次调整配置文件里的输入图片和label路径以及保存的路径就可以了。
这样我们就得到了裁剪后的images以及相应的labels,这里说明一下,有人可能发现了裁剪后的label中的difficult处有的变成了2,我们之前说过了1代表难检测,0代表容易,那么2是怎么来的?它代表什么?其实2是代表这个物体在裁剪的时候被切割了,在标注的时候会把它去掉。

到这里我们的数据集部分就已经制作完成了。
四、使用自定义数据集进行训练
以oriented_rcnn/oriented_rcnn_r50_fpn_1x_dota_le90.py的模型结构为例
首先我们进入mmrotate/configs/oriented_rcnn/oriented_rcnn_r50_fpn_1x_dota_le90.py(注意这里面我下载好的mmrotate文件夹名字就叫mmrotate,这里面还有一个mmrotate不要弄混了)找到oriented_rcnn_r50_fpn_1x_dota_le90.py文件,如下图
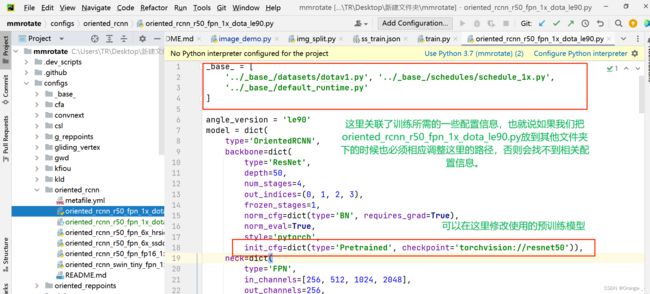
同时我们还需要将输出head的结构改成我们自己检测类的数量,如下图

注意mmcv2.0版本以后使用的都是0-base的方式,即不计背景,假如我们只有一个待检测的类别,那么我们修改num_classes=1即可。(注意:有的模型结构需要修改多个输出头的num_classes)
接下来我们修改训练所需要的配置信息
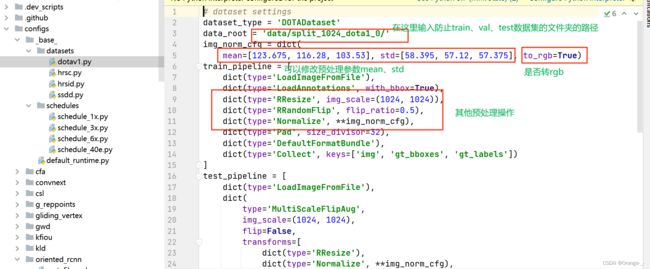
找到mmrotate/configs/_base_/datasets/dotav1.py和mmrotate/configs/_base_/schedules/schedule_1x.py
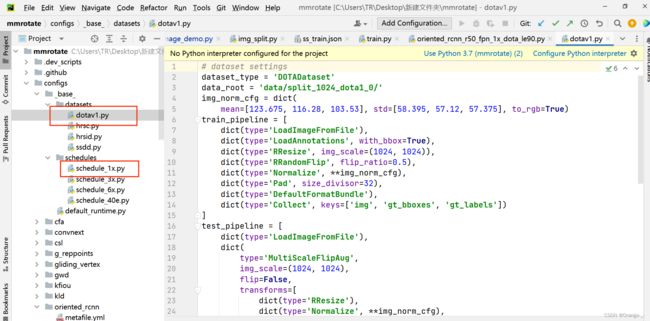
修改dotav1.py:

修改 schedule_1x.py:

我们可以根据自己的需要改变相应参数来完成自定义的检测,至此训练时的配置参数就修改完成了。
这时我们还需要在mmrotate/datasets/dota.py中更改一下自己数据集的类别名称:
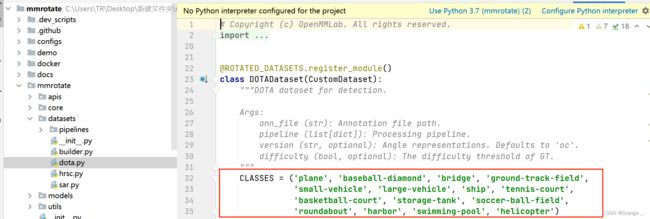
将CLASSES里面的类别改成自己的类别就好了,修改完成如下:(记得要保留,)

最后我们只需要在mmrotate/tools/train.py 修改训练模型文件和保存路径就可以了:
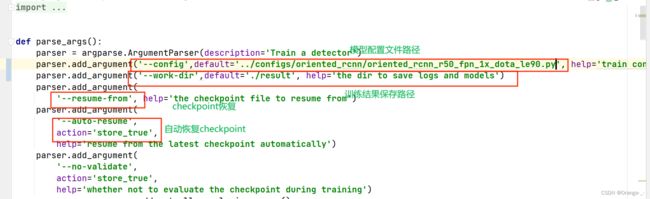
这里需要说明的是结果的保存路径是程序自动给我们创建的,训练前不能有这个文件夹,否则提示文件夹已经存在。
此外checkpoint的恢复需要输入的参数是训练第多少论的结果权重文件的路径,如epoch_40.pth的路径,再次训练的时候会继续从这里开始训练。而自动恢复会从latest开始训练。
同时训练时也可以指定GPU的数量和id:
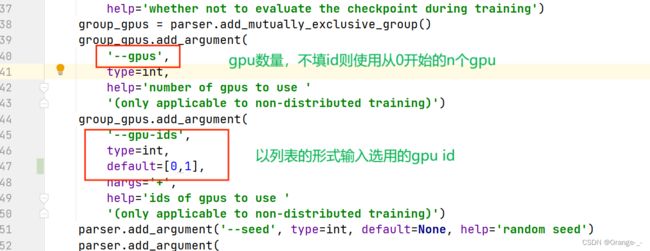
一切都就绪后就可以在pycharm中直接运行了,也可以cd进入mmrotate/tools并使用命令行:
python train.py测试训练的结果:
这里可以使用上面介绍过的image_demo.py来测试结果
也可以使用mmrotate/tools/test.py来测试:


五、总结
训练自定义数据集的方式有很多种,这里介绍一下各种方法的利弊和如何选择。
1、使用在dota数据集上训练过的预训练模型,并在数据预处理的时候使用dota的mean和std。
2、使用在dota数据集上训练过的预训练模型,在数据预处理的时候使用自己数据集的mean和std。
3、不使用在dota数据集上训练过的预训练模型,在数据预处理的时候使用自己数据集的mean和std。
如果你的数据集数量较少那么推荐使用第一种方法,效果会好很多,而且收敛快。
如果你的数据集体量庞大可以使用第三种方式训练。
不推荐使用第二种方法训练。