pytorch 深度学习实践 第5讲 pytorch实现线性回归
第5讲 pytorch实现线性回归 Linear Regression with PyTorch
pytorch学习视频——B站视频链接:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
以下是视频内容笔记以及小练习源码,笔记纯属个人理解,如有错误勿介或者欢迎路过的大佬指出 。
目录
1. 构造神经网络一般步骤
2. 第一步——准备数据集 prepare dataset
3. 第二步——模型设计
4. 第三步——构造损失函数和优化器
4. 第四步——训练
5. 本节代码
6. 其它优化器训练结果
1. 构造神经网络一般步骤
-
准备数据集
-
设计模型
-
计算预测值y_pred的模型
-
-
构造损失函数和优化器
-
使用pytorch封装好的API即可
-
-
训练循环
-
前馈——计算损失
-
反馈——计算梯度
-
g更新——用梯度下降算法更新权重
-

2. 第一步——准备数据集 prepare dataset
用mini-batch构造数据集,x和y必须是矩阵的形式
将数据集定义成矩阵形式(张量),如下x_data, y_data都是3X1的矩阵,权重w也被当成矩阵进行参与计算。w也是3X1矩阵,与x_data矩阵进行点乘,对应位置元素相乘(不是矩阵相乘)。

3. 第二步——模型设计
-
基本内容
设计模型也就是构造计算图的过程,需要已知x和y的维度,由此可以确定w和b的维度。计算梯度时只需要从loss处反向一步一步求出即可,不需要手动求偏导,有了这个从w和x求出loss的模型之后,用反向传播就可以自动求出这条链上的梯度。
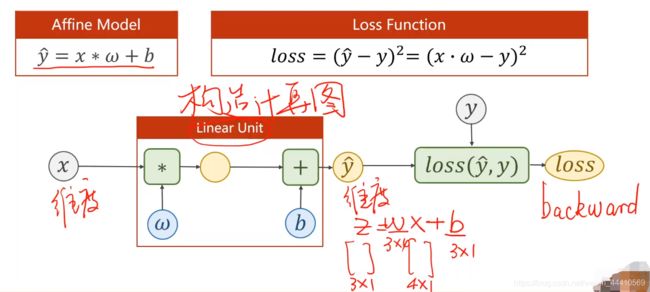
最后计算出的loss是一个标量数值???,才可以调用backward():
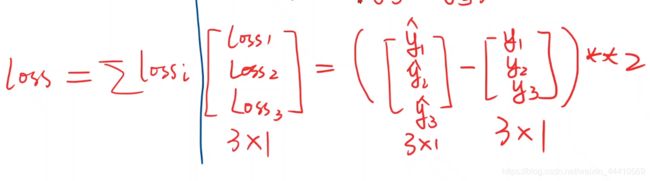
-
最基本的代码框架
-
把模型定义成一个类LinearModel,继承自torch.nn.Module。构造计算图,所有的神经网络模型都要继承Module类。
-
class LinearModel(torch.nn.Module):
# 构造函数——初始化变量
def __init__(self):
super(LinearModel, self).__init__()
# 构造对象 线性模型
self.linear = torch.nn.Linear(1, 1)
# 对module类中原forward函数的重写
def forward(self, x):
# linear——可调用对象 linear(x), __call__函数
y_pred = self.linear(x)
return y_pred
# model也是一个可调用对象
model = LinearModel()-
代码说明
torch.nn.Linear
self.linear = torch.nn.Linear(1, 1) # Linear类的格式如下图所示,in_features是输入数据的维数,y_features是输出样本的维数,bias是偏置值,默认是True # 实例化对象之后相当于进行y = xw + b的计算

-
关于w的维度问题,如图所示的两种形式
-
x是nX3矩阵,要求的y是nX2矩阵
-
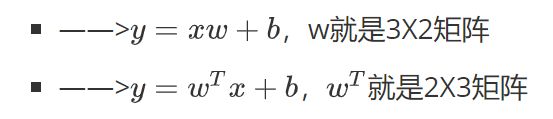
-
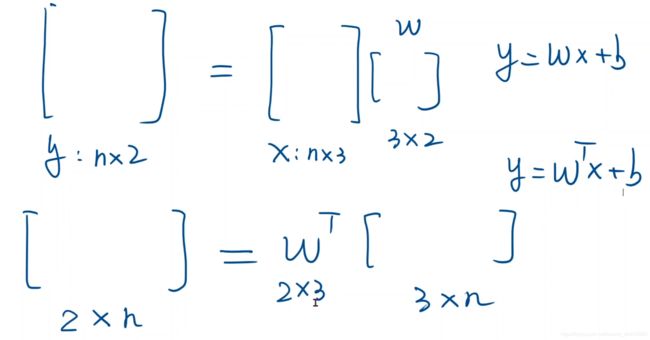
4. 第三步——构造损失函数和优化器
-
损失函数:MSE损失函数
-
优化器:SGD,优化器不需要建立计算图

# MSELoss类继承自Module,torch.nn.MSELoss,可调用,pytorch提供的MSE损失函数。 criterion = torch.nn.MSELoss(size_average=False) # 实例化一个优化器对象 optimizer = torch.optim.SGD(model.parameters(), lr=0.01)torch.nn.MSELoss 类如图所示,size_average表示损失是否求均值;reduce表示求出的损失是否降维,默认为True,在这个例子中就是将loss转换为标量。
优化器SGD如图所示,model.parameters()找出model中要训练的所有权重,在这里就是linear的权重w,lr是学习率,其它参数可参考官方文档。


4. 第四步——训练
-
训练步骤:
-
前馈——反馈——更新
-
模型;求损失——求梯度——更新权重
-
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
print(loss)
loss.backward()
optimizer.step()-
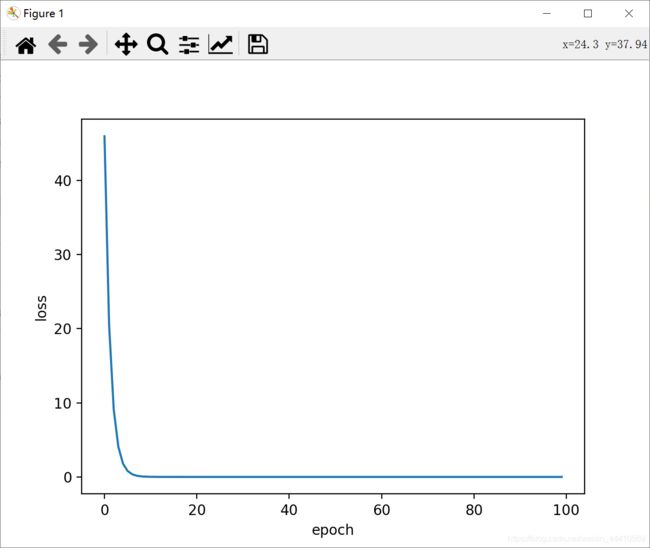
SGD训练结果:
随机梯度下降,现在一般指mini-batch gradient descent,计算一个mini-batch的损失,迭代也是以一个批次为单位来更新权重。
5. 本节代码
linear_regression.pyimport torch
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
# 构造函数——初始化变量
def __init__(self):
super(LinearModel, self).__init__()
# 构造对象 线性模型
self.linear = torch.nn.Linear(1, 1)
# 对module类中原forward函数的重写
def forward(self, x):
# linear——可调用对象 linear(x), __call__函数
y_pred = self.linear(x)
return y_pred
# model也是一个可调用对象
model = LinearModel()
# MSELoss类继承自Module,torch.nn.MSELoss,可调用,pytorch提供的MSE损失函数。
criterion = torch.nn.MSELoss(size_average=False)
# 实例化一个优化器对象,parameters是所有权重参数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
# loss计算出来是一个
print(epoch, loss.item())
# 将梯度值清0
optimizer.zero_grad()
# 反向传播求梯度
print(loss)
loss.backward()
# 优化器 更新权重
optimizer.step()
# 打印出最终的权重和偏置值
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([4.0])
y_test = model(x_test)
print('y_pred = ', y_test.data)
作业 optimizer_test_job.py
(只试了前几个优化器,效果都不是很好)
import torch
from matplotlib import pyplot as plt
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
# 构造函数——初始化变量
def __init__(self):
super(LinearModel, self).__init__()
# 构造对象 线性模型
self.linear = torch.nn.Linear(1, 1)
# 对module类中原forward函数的重写
def forward(self, x):
# linear——可调用对象 linear(x), __call__函数
y_pred = self.linear(x)
return y_pred
# model也是一个可调用对象
model = LinearModel()
# MSELoss类继承自Module,torch.nn.MSELoss,可调用,pytorch提供的MSE损失函数。
criterion = torch.nn.MSELoss(size_average=False)
# 实例化一个优化器对象,parameters是所有权重参数
optimizer = torch.optim.Adamax(model.parameters(), lr=0.01)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# optimizer = torch.optim.Adagrad(model.parameters(), lr=0.2)
# 训练
l_list = []
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
# loss计算出来是一个tensor
if epoch % 10 == 0:
print(epoch, loss.item())
l_list.append(loss.item())
# 将梯度值清0
optimizer.zero_grad()
# 反向传播求梯度
loss.backward()
# 优化器 更新权重
optimizer.step()
# 打印出最终的权重和偏置值
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([4.0])
y_test = model(x_test)
print('y_pred = ', y_test.data)
x = range(100)
plt.plot(x, l_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
(以上代码已经在pycharm上经过测试)
6. 其它优化器训练结果
-
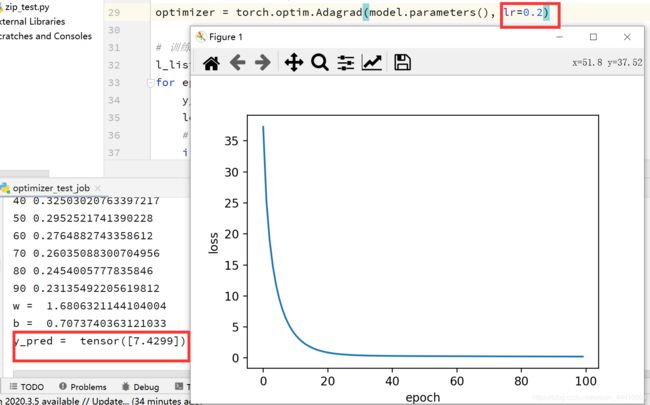
Adagrad:
结果如图所示,如果学习率设置为0.01,那结果基本不收敛,改为0.2后效果好一点,可尝试增大训练次数或者增大学习率。
-
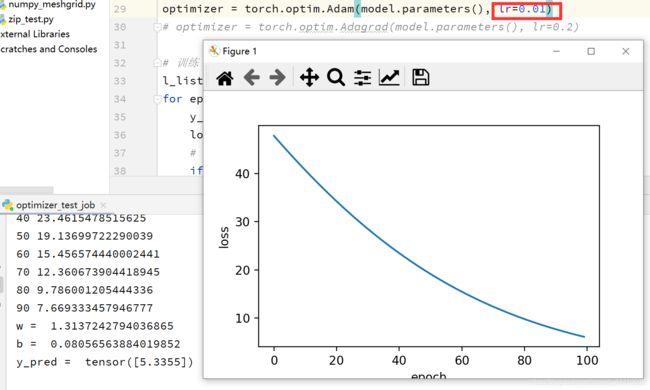
Adam
效果不好
torch中的其它优化器如图所示
深度学习几种优化器的比较

examples:
Learning PyTorch with Examples — PyTorch Tutorials 1.9.0+cu102 documentation
——pytorch官方中文文档:
torch - PyTorch中文文档 (pytorch-cn.readthedocs.io)
——未完待续……