文献阅读二—Robsut Wrod Reocginiton via Semi-Character Recurrent Neural Network
题目:Robsut Wrod Reocginiton via Semi-Character Recurrent Neural Network
作者:Keisuke Sakaguchi Kevin Duh Matt Post Benjamin Van Durme
出处:AAAI CCF A
摘要
人类的语言处理机制通常比计算机更健壮。心理语言学文献中的Cmabridge Uinervtisy(剑桥大学)效应证明了这样一种强大的文字处理机制,在这种机制中,杂乱的单词(如Cmabrigde/Cambridge)可以以很低的成本被识别。另一方面,单词识别的计算模型(例如拼写检查器)在具有此类噪声的数据上表现不佳。受Cmabride Uinervtisy效应的发现启发,我们提出了一种基于半字符级递归神经网络(scRNN)的单词识别模型。在我们的实验中,我们证明了scRNN在单词拼写校正(即单词识别)。此外,我们通过使用我们的模型复制关于人类阅读困难的心理语言学实验,证明了该模型在认知上是合理的。
介绍
从技术上讲,我们模型的输入层由三个子向量组成:输入单词的开头(b)、内部(i)和结尾(e)字符(图1)。这种半特征级递归神经网络被称为scRNN。
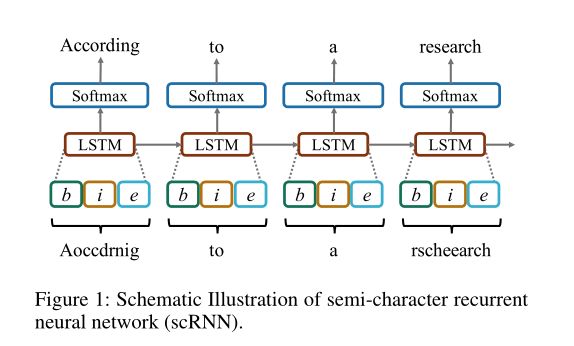
半字符递归神经网络
为了实现类人的鲁棒文字处理机制,我们提出了一种基于半字符的递归神经网络(scRNN)。该模型为给定的杂乱单词取半字符向量(x),并在每个时间步预测一个(拼写正确的)单词(y)。scRNN的结构基于标准递归经网络,其中通过在每个时间步长(t)应用具有线性变换参数(W)和偏差(b)的特定(例如,S形)函数(g),通过隐藏状态(h)连接当前输入(x)和先前信息。
虽然RNN的标准输入向量来自一个词或一个字符,但scRNN的输入向量由三个子向量( b n , i n , e n b_n, i_n, e_n bn,in,en)组成,分别对应于字符的位置。
 第一个和第三个子向量( b n , e n b_n,e_n bn,en)代表第n个字的第一个和最后一个字符。因此,这两个子向量是独热(one-hot)表示法。第二个子向量( i n i_n in)表示该词的一袋不含首尾位置的字符。例如,"University "这个词表示为 b n = U = 1 , e n = y = 1 , i n = e = 1 , i = 2 , n = 1 , s = 1 , r = 1 , t = 1 , v = 1 b_n={U=1},e_n={y=1},i_n={e=1,i=2,n=1,s=1,r=1,t=1,v=1} bn=U=1,en=y=1,in=e=1,i=2,n=1,s=1,r=1,t=1,v=1,其他元素都是零。子向量( b n , i n , e n b_n, i_n, e_n bn,in,en)的大小等于我们语言中的字符数(N),因此 x n x_n xn通过串联子向量的大小为3N。
第一个和第三个子向量( b n , e n b_n,e_n bn,en)代表第n个字的第一个和最后一个字符。因此,这两个子向量是独热(one-hot)表示法。第二个子向量( i n i_n in)表示该词的一袋不含首尾位置的字符。例如,"University "这个词表示为 b n = U = 1 , e n = y = 1 , i n = e = 1 , i = 2 , n = 1 , s = 1 , r = 1 , t = 1 , v = 1 b_n={U=1},e_n={y=1},i_n={e=1,i=2,n=1,s=1,r=1,t=1,v=1} bn=U=1,en=y=1,in=e=1,i=2,n=1,s=1,r=1,t=1,v=1,其他元素都是零。子向量( b n , i n , e n b_n, i_n, e_n bn,in,en)的大小等于我们语言中的字符数(N),因此 x n x_n xn通过串联子向量的大小为3N。
举个例子,假设字符表是26维,分别代表着a、b、c、……、z这26个字母。那么apple由三个向量来表示,分别为
a : [1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
ppl : [0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,2,0,0,0,0,0,0,0,0,0,0],
e : [0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。
将三个向量拼接起来输入到LSTM中,输出结果与正确拼写的单词做交叉熵损失,训练得到ScRNN模型
关于最终输出(即预测的单词 y n y_n yn),LSTM的隐藏状态向量( h n h_n hn)被作为输入到以下具有固定词汇量(v)的softmax函数层中
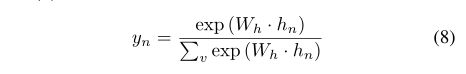 我们使用交叉熵训练标准应用于输出层,就像大多数LSTM语言建模工作一样;模型学习权重矩阵(W )以最大化训练数据的可能性。这应该与预测输出中准确的单词匹配数量最大化有密切关系。图1显示了scRNN的图解概况。
我们使用交叉熵训练标准应用于输出层,就像大多数LSTM语言建模工作一样;模型学习权重矩阵(W )以最大化训练数据的可能性。这应该与预测输出中准确的单词匹配数量最大化有密切关系。图1显示了scRNN的图解概况。
实验
scRNN的输入层由一个长度为76的向量组成(A-Z,a-z和24个符号字符)。隐层单元的大小为650,总词汇量被设定为10k
&emsp我们对每个词都施加一种噪音,但带有数字的词(如1980s)和短词(长度≤3)没有受到干扰,因此这些词在评估中被排除。我们通过运行5个epochs来训练模型,(小型)批处理量为20。我们将通过时间的反向传播(BPTT)参数设置为3:scRNN更新前两个词( x n − 2 , x n − 1 x_{n-2},x_{n-1} xn−2,xn−1 )和当前词( x n x_n xn)的权重。
注:
1、看到了另一篇文章中的有关ScRNN的代码,放在这,给大家参考
2、这个的输出应该是全连接的onehot,即词汇表如果是10000,那么全连接的输出就是10000