深度有趣 | 19 pix2pix图像翻译
简介
介绍基于CGAN的pix2pix模型,可用于实现多种配对图像翻译任务
原理
配对图像翻译包括很多应用场景,输入和输出都是图片且尺寸相同
- 街道标注,街道实景
- 楼房标注,楼房实景
- 黑白图片,上色图片
- 卫星地图,简易地图
- 白天,夜晚
- 边缘,实物
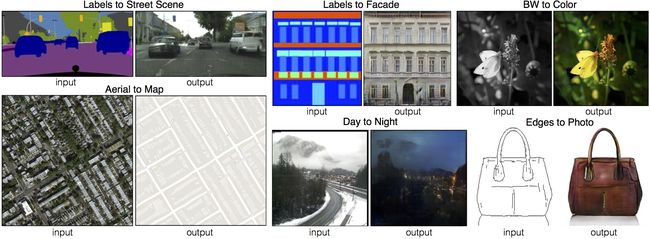
pix2pix提供了一种通用的技术框架,用于完成各种配对图像翻译任务
作者还提供了一个在线Demo,包括曾经火爆一时的edge2cat,https://affinelayer.com/pixsrv/
pix2pix原理如下,典型的CGAN结构,但G只接受一个固定的输入X,可以理解为一个条件C,即不需要随机噪音,然后输出翻译后的版本Y
D接受一个X(CGAN中的C)和一个Y(真假样本),并判断X和Y是否为配对的翻译
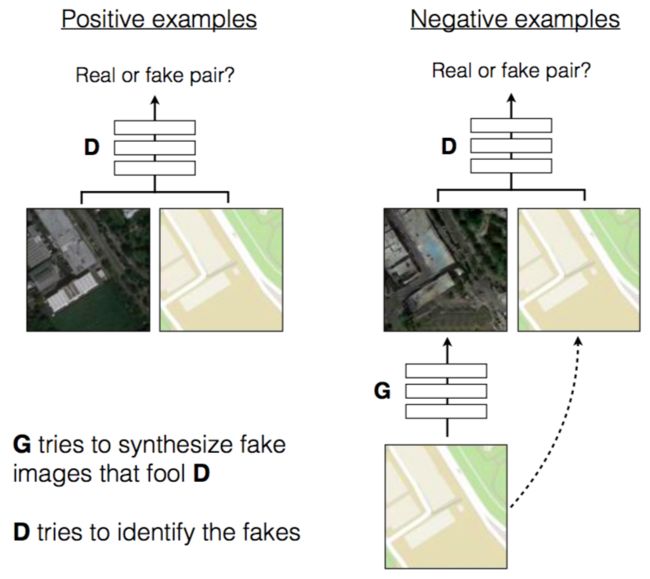
除了标准的GAN损失函数之外,pix2pix还考虑了生成样本和真实样本之间的L1距离作为损失
L L 1 ( G ) = E x ∼ p x , y ∼ p y [ ∥ y − G ( x ) ∥ 1 ] L_{L_1}(G)=\mathbb{E}_{x\sim p_x,y\sim p_y}[\left \| y-G(x) \right \|_1] LL1(G)=Ex∼px,y∼py[∥y−G(x)∥1]
GAN损失负责捕捉图像高频特征,L1损失负责捕捉低频特征,使得生成结果既真实且清晰
生成器G使用Unet实现,主要用到Skip-Connection来学习配对图像之间的映射
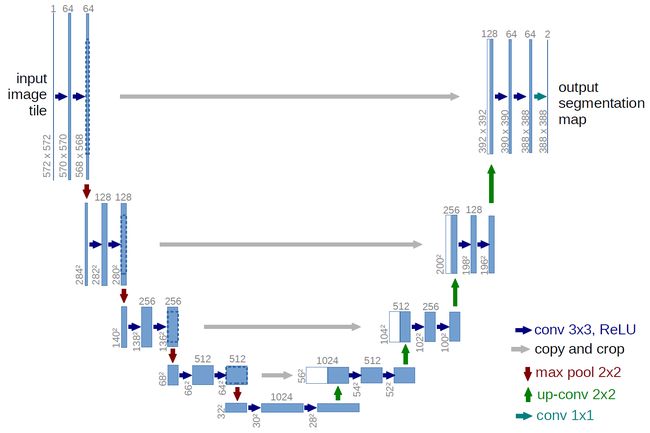
判别器D使用了PatchGAN的思想,之前是对整张图片给出一个分数,PatchGAN则是将一张图片分为很多块,对每一块都给出一个分数
实现
代码参考自以下项目,https://github.com/affinelayer/pix2pix-tensorflow,提供了很多方便好用的功能
- 多个预训练好的模型,可用于完成各种图像翻译任务
- 在自己的配对图像数据上训练图像翻译模型(两个文件夹,对应图片的名称和尺寸相同)
- 在自己的图像数据上训练上色模型(一个文件夹存放彩色图片即可,因为黑白图片可以从彩色图片中自动获取)
数据集下载链接,https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/,包括五个数据集:楼房、街景、地图、鞋子、包
以facades楼房数据为例,train、val、test分别包括400、100、106张图片,每张图片包括两部分,对应翻译前后的两个版本

加载库
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from imageio import imread, imsave, mimsave
import glob
import os
from tqdm import tqdm
加载图片,使用train和val,共500张图片
images = glob.glob('data/train/*.jpg') + glob.glob('data/val/*.jpg')
print(len(images))
整理数据,从每张图片中分离出X和Y,B2A表示从右往左
X_all = []
Y_all = []
WIDTH = 256
HEIGHT = 256
for image in images:
img = imread(image)
img = (img / 255. - 0.5) * 2
# B2A
X_all.append(img[:, WIDTH:, :])
Y_all.append(img[:, :WIDTH, :])
X_all = np.array(X_all)
Y_all = np.array(Y_all)
print(X_all.shape, Y_all.shape)
定义一些常量、网络tensor、辅助函数,这里的batch_size设为1,因此每次训练都是一对一的图像翻译
batch_size = 1
LAMBDA = 100
OUTPUT_DIR = 'samples'
if not os.path.exists(OUTPUT_DIR):
os.mkdir(OUTPUT_DIR)
X = tf.placeholder(dtype=tf.float32, shape=[None, HEIGHT, WIDTH, 3], name='X')
Y = tf.placeholder(dtype=tf.float32, shape=[None, HEIGHT, WIDTH, 3], name='Y')
k_initializer = tf.random_normal_initializer(0, 0.02)
g_initializer = tf.random_normal_initializer(1, 0.02)
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
def d_conv(inputs, filters, strides):
padded = tf.pad(inputs, [[0, 0], [1, 1], [1, 1], [0, 0]], mode='CONSTANT')
return tf.layers.conv2d(padded, kernel_size=4, filters=filters, strides=strides, padding='valid', kernel_initializer=k_initializer)
def g_conv(inputs, filters):
return tf.layers.conv2d(inputs, kernel_size=4, filters=filters, strides=2, padding='same', kernel_initializer=k_initializer)
def g_deconv(inputs, filters):
return tf.layers.conv2d_transpose(inputs, kernel_size=4, filters=filters, strides=2, padding='same', kernel_initializer=k_initializer)
def batch_norm(inputs):
return tf.layers.batch_normalization(inputs, axis=3, epsilon=1e-5, momentum=0.1, training=True, gamma_initializer=g_initializer)
def sigmoid_cross_entropy_with_logits(x, y):
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, labels=y)
判别器部分,将X和Y按通道拼接,经过多次卷积后得到30*30*1的判别图,即PatchGAN的思想,而之前是只有一个神经元的Dense
def discriminator(x, y, reuse=None):
with tf.variable_scope('discriminator', reuse=reuse):
x = tf.concat([x, y], axis=3)
h0 = lrelu(d_conv(x, 64, 2)) # 128 128 64
h0 = d_conv(h0, 128, 2)
h0 = lrelu(batch_norm(h0)) # 64 64 128
h0 = d_conv(h0, 256, 2)
h0 = lrelu(batch_norm(h0)) # 32 32 256
h0 = d_conv(h0, 512, 1)
h0 = lrelu(batch_norm(h0)) # 31 31 512
h0 = d_conv(h0, 1, 1) # 30 30 1
h0 = tf.nn.sigmoid(h0)
return h0
生成器部分,Unet前后两部分各包含8层卷积,且后半部分的前三层卷积使用Dropout,Dropout层在训练过程中以一定概率随机去掉一些神经元,起到防止过拟合的作用
def generator(x):
with tf.variable_scope('generator', reuse=None):
layers = []
h0 = g_conv(x, 64)
layers.append(h0)
for filters in [128, 256, 512, 512, 512, 512, 512]:
h0 = lrelu(layers[-1])
h0 = g_conv(h0, filters)
h0 = batch_norm(h0)
layers.append(h0)
encode_layers_num = len(layers) # 8
for i, filters in enumerate([512, 512, 512, 512, 256, 128, 64]):
skip_layer = encode_layers_num - i - 1
if i == 0:
inputs = layers[-1]
else:
inputs = tf.concat([layers[-1], layers[skip_layer]], axis=3)
h0 = tf.nn.relu(inputs)
h0 = g_deconv(h0, filters)
h0 = batch_norm(h0)
if i < 3:
h0 = tf.nn.dropout(h0, keep_prob=0.5)
layers.append(h0)
inputs = tf.concat([layers[-1], layers[0]], axis=3)
h0 = tf.nn.relu(inputs)
h0 = g_deconv(h0, 3)
h0 = tf.nn.tanh(h0, name='g')
return h0
损失函数,G加上L1损失
g = generator(X)
d_real = discriminator(X, Y)
d_fake = discriminator(X, g, reuse=True)
vars_g = [var for var in tf.trainable_variables() if var.name.startswith('generator')]
vars_d = [var for var in tf.trainable_variables() if var.name.startswith('discriminator')]
loss_d_real = tf.reduce_mean(sigmoid_cross_entropy_with_logits(d_real, tf.ones_like(d_real)))
loss_d_fake = tf.reduce_mean(sigmoid_cross_entropy_with_logits(d_fake, tf.zeros_like(d_fake)))
loss_d = loss_d_real + loss_d_fake
loss_g_gan = tf.reduce_mean(sigmoid_cross_entropy_with_logits(d_fake, tf.ones_like(d_fake)))
loss_g_l1 = tf.reduce_mean(tf.abs(Y - g))
loss_g = loss_g_gan + loss_g_l1 * LAMBDA
定义优化器
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer_d = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_d, var_list=vars_d)
optimizer_g = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_g, var_list=vars_g)
训练模型
sess = tf.Session()
sess.run(tf.global_variables_initializer())
loss = {'d': [], 'g': []}
for i in tqdm(range(100000)):
k = i % X_all.shape[0]
X_batch, Y_batch = X_all[k:k + batch_size, :, :, :], Y_all[k:k + batch_size, :, :, :]
_, d_ls = sess.run([optimizer_d, loss_d], feed_dict={X: X_batch, Y: Y_batch})
_, g_ls = sess.run([optimizer_g, loss_g], feed_dict={X: X_batch, Y: Y_batch})
loss['d'].append(d_ls)
loss['g'].append(g_ls)
if i % 1000 == 0:
print(i, d_ls, g_ls)
gen_imgs = sess.run(g, feed_dict={X: X_batch})
result = np.zeros([HEIGHT, WIDTH * 3, 3])
result[:, :WIDTH, :] = (X_batch[0] + 1) / 2
result[:, WIDTH: 2 * WIDTH, :] = (Y_batch[0] + 1) / 2
result[:, 2 * WIDTH:, :] = (gen_imgs[0] + 1) / 2
plt.axis('off')
plt.imshow(result)
imsave(os.path.join(OUTPUT_DIR, 'sample_%d.jpg' % i), result)
plt.show()
plt.plot(loss['d'], label='Discriminator')
plt.plot(loss['g'], label='Generator')
plt.legend(loc='upper right')
plt.savefig('Loss.png')
plt.show()
结果如下图所示,从左往右三张图依次为原图、真实图、生成图

保存模型,以便在单机上使用
saver = tf.train.Saver()
saver.save(sess, './pix2pix_diy', global_step=100000)
在单机上加载模型,对val中的图片进行翻译
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
from imageio import imread, imsave
import glob
images = glob.glob('data/val/*.jpg')
X_all = []
Y_all = []
WIDTH = 256
HEIGHT = 256
N = 10
images = np.random.choice(images, N, replace=False)
for image in images:
img = imread(image)
img = (img / 255. - 0.5) * 2
# B2A
X_all.append(img[:, WIDTH:, :])
Y_all.append(img[:, :WIDTH, :])
X_all = np.array(X_all)
Y_all = np.array(Y_all)
print(X_all.shape, Y_all.shape)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver = tf.train.import_meta_graph('./pix2pix_diy-100000.meta')
saver.restore(sess, tf.train.latest_checkpoint('./'))
graph = tf.get_default_graph()
g = graph.get_tensor_by_name('generator/g:0')
X = graph.get_tensor_by_name('X:0')
gen_imgs = sess.run(g, feed_dict={X: X_all})
result = np.zeros([N * HEIGHT, WIDTH * 3, 3])
for i in range(N):
result[i * HEIGHT: i * HEIGHT + HEIGHT, :WIDTH, :] = (X_all[i] + 1) / 2
result[i * HEIGHT: i * HEIGHT + HEIGHT, WIDTH: 2 * WIDTH, :] = (Y_all[i] + 1) / 2
result[i * HEIGHT: i * HEIGHT + HEIGHT, 2 * WIDTH:, :] = (gen_imgs[i] + 1) / 2
imsave('facades翻译结果.jpg', result)
造好的轮子
看一下项目提供了哪些造好的轮子,https://github.com/affinelayer/pix2pix-tensorflow
将图片处理成256*256大小,input_dir表示原始图片目录,output_dir表示大小统一处理后的图片目录
python tools/process.py --input_dir input_dir --operation resize --output_dir output_dir
准备好X和Y的配对数据(两个文件夹分别存放X和Y,对应图片的名称和尺寸相同),将图片像facades那样两两组合起来
python tools/process.py --input_dir X_dir --b_dir Y_dir --operation combine --output_dir combine_dir
得到combine_dir之后即可训练配对图像pix2pix翻译模型
python pix2pix.py --mode train --output_dir model_dir --max_epochs 200 --input_dir combine_dir --which_direction AtoB
mode:运行模式,train表示训练模型output_dir:模型输出路径max_epochs:训练的轮数(epoch和iteration的区别)input_dir:组合图片路径which_direction:翻译的方向,从左往右还是从右往左
模型训练过程中,以及模型训练完毕后,都可以使用tensorboard查看训练细节
tensorboard --logdir=model_dir
训练完模型后,在测试数据上进行翻译
python pix2pix.py --mode test --output_dir output_dir --input_dir input_dir --checkpoint model_dir
mode:运行模式,test表示测试output_dir:翻译结果输出路径input_dir:待测试的图片路径checkpoint:之前训练得到的模型路径
如果要训练上色模型,则不需要以上提到的组合图片这一步骤,只需要提供一个彩色图片文件夹即可,因为对应的灰度图可以从彩色图中自动抽取
python pix2pix.py --mode train --output_dir model_dir --max_epochs 200 --input_dir combine_dir --lab_colorization
项目还提供了一些训练好的配对图像翻译模型
- 楼房:从标注到实景
- 街景:双向
- 地图:双向
- 鞋子:从边缘到实物
- 包:从边缘到实物
风景图片上色
使用以下数据集,http://lear.inrialpes.fr/~jegou/data.php,都是一些旅游风景照片,已经处理成256*256大小,分为train和test两部分,分别包含750和62张图片
使用train中的图片训练上色模型
python pix2pix.py --mode train --output_dir photos/model --max_epochs 200 --input_dir photos/data/train --lab_colorization
使用test中的图片进行测试,模型会生成每一张彩色图对应的灰度图和上色图,并将全部上色结果写入一个网页中
python pix2pix.py --mode test --output_dir photos/test --input_dir photos/data/test --checkpoint photos/model
上色结果如下,从左往右依次为灰度图、上色图、原图

参考
- Image-to-Image Translation with Conditional Adversarial Nets:https://phillipi.github.io/pix2pix/
- pix2pix-tensorflow:https://github.com/affinelayer/pix2pix-tensorflow
视频讲解课程
深度有趣(一)