【python】Kaggle入门:titanic 的特征提取与特征分析
目 录
0、概述
1、Anaconda的准备
2、导入必需包和数据集
3、数据分析
3.1 数据概览
3.2 数据初步分析
3.2.1 Pclass 客舱等级
3.2.2 Sex 性别
3.2.3 Age 年龄
3.2.4 SibSp 兄弟数量
3.2.5 Parch 父母与子女数量
3.2.6 Fare 票价
3.3 数据深入分析
3.3.1 PassengerId 乘客序号
3.3.2 Name 乘客姓名
3.3.3 Ticket 船票编号
3.3.4 Cabin 房间号
3.3.5 Embarked 上船的港口编号
3.3.6 SibSp+Parch 亲人数量
4、总结
0、概述
kaggle是一个数据挖掘网站,上面有许多各类数据挖掘问题与竞赛。对于数据挖掘专业的学生来说十分友好。
对我来说,无论是利用python进行数据分析还是pandas还是numpy都太枯燥了,因此选择用这个入门问题来学习一些有关数据挖掘的基本技能。
主要参考该网址的第二部分。对于大多数有一些pandas基础的人,直接看这个就可以了,我是初次接触这些,会把其中遇到的所有问题都写下来,供自己和大家查询。
1、Anaconda的准备
我这边有好几个虚拟环境,为了防止环境互相影响,决定对该问题新建一个环境。
参考网址使用Jupyter Notebook,所以在该环境里面要安装notebook。
安装好这些必须包以后,别忘了装nb_conda这个包,有了这个包才能随意在notebook里面切环境,否则只有一个默认环境没法切。如下:

不装nb_conda就只有第一个环境。
2、导入必需包和数据集
代码如下:
%matplotlib inline #notebook中的魔法函数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore') #无视所有代码警告
train=pd.read_csv(r'F:\kaggle\titanic\train.csv') #读取训练集
test=pd.read_csv(r'F:\kaggle\titanic\test.csv') #读取测试集
PassengerId=test['PassengerId'] #读取测试集中PassengerId这一列
all_data=pd.concat([train,test],ignore_index=True) #将训练集和测试集合在一起
train.head()
上述代码的效果如下:
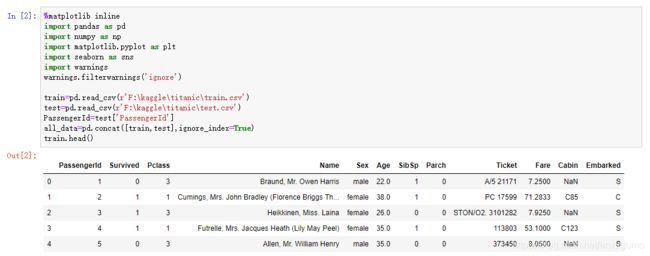
可以看到train已经成功保存了测试集中的数据。下面开始分析代码:
第一行的魔法函数的作用很简单,就是当我们使用plt.plot画一个函数之后,正常应该加一句plt.show才会显示图像,有了这句之后就不用再多写一句show了,plot之后直接显示图像。
之后是引入包,pandas和numpy不需要解释,seaborn是一个用于画图的库。
然后是warning的一句,这一句是隐藏所有的解释器的warning。
接下来进入正题:利用pandas的read_csv可以将csv文件的内容写入变量,作为一个类似二维数组的结构,称之为DataFrame。
如何对dataframe进行访问呢?
首先来看对列访问:
有三种形式,按行访问、按列访问、指定某元素访问。
对于按行访问:
比如说上面的第0行:
第一种:
test.iloc[0]等价于访问“第0行”,iloc的特点是其访问的是从前往后数第几行,当然最开始的那行列名不算。
第二种:
test.loc[0]等价于访问“序号那一列中名为0的行”,loc的特点是找左边第一列中名字与参数对得上的那一行并返回。
这俩效果都一样:

返回的都是Series。
按行访问还有一种类似切片的方式:
test[0:1]效果如下:

相当于切下第0行,返回类型为DataFrame。
对于按列访问:
比如说对上文中的passergerId来说:
第一种:
test['PassengerId']返回的效果如下:
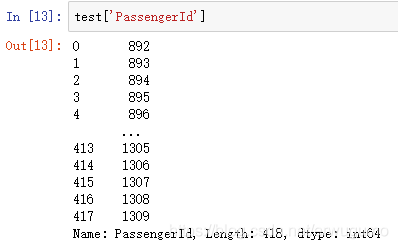
其类型为Series,pandas中的一维数据结构,可以看做是字典,是序号到元素的映射。
第二种:
test[['PassengerId']]返回的效果如下:
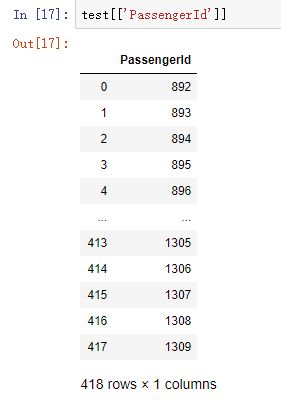
其类型为DataFrame,pandas中的二维数据结构。
访问某个指定元素:
可以混合使用上面的方法,毕竟返回的不是DataFrame就是Series,直接继续访问就好:
例如:
test.loc[0]['Name']访问第0行中名为name的列。
又如:
test['Name'][0]访问name这列中的第0个。
扯远了。接着看这里的代码。下一行就是按列访问名为PassengerId这一列,返回的是Series。
然后将测试集和训练集黏在一起,用的是concat函数。
最后访问训练集的前五行,用head,后五行则用tail。
3、数据分析
3.1 数据概览
我们既然已经将数据集导入了,那就来看看里面都是什么吧。
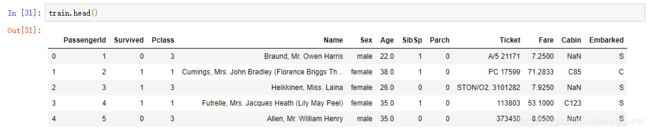
回想起我在数据挖掘课上刚学的那点三脚猫功夫:
列名就是每个人的属性咯,这样看来:
PassengerId为乘客序号,序数属性,没任何用——八成就是一个捞上来的顺序问题;
Survived为是否生还,二元属性,只有0和1,这是最重要的属性,是我们最后要预测的属性;
Pclass为客舱等级,数值属性,取值1,2,3,看上去应该挺重要的,是不是客舱等级越高就越容易生还?;
Name为乘客名字,标称属性,取值为人名,我觉得很难从中提取出什么属性,或许没名字代表必死?;
Sex为性别,二元属性,取值0,1,看来那个时候对于性别划分还没那么复杂;
Age为年龄,数值属性,取值整数,同样重要,老弱先行么;
SibSp为兄弟数量,数值属性;
Parch为父母与子女数量,数值属性,其值0,1,2,3等;
Ticket为船票编号,标称属性,和乘客名字差不多;
Fare为票价,数值属性,但是不是离散而是连续,应该和客舱等级有一定的联系,效果也差不多;
Cabin为房间号,标称属性,可能房间号有一定的规律;
Embarked上船的港口编号,标称属性。
知道了这些都是啥,下面来看看数据的缺失吧。很简单,使用如下指令:
train.info()效果如下:
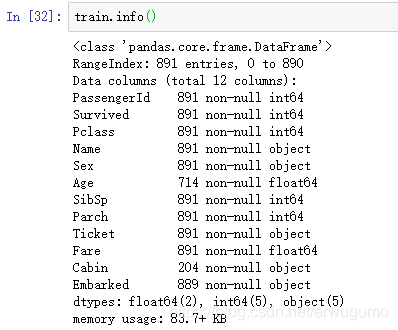
这命令主要就是看有多少非空属性,可以看出来,Age缺了一些、Cabin缺了很多。那么我们在用age建模的时候就需要好好想一想了,是自己填值还是为空的全置为0作为特殊的一类呢?
3.2 数据初步分析
这一步主要看各属性与是否生还的关系。我们先来筛出来大概率和是否生还有关的属性吧:
Pclass、Sex、Age、Sibsp、Parch、Fare。
使用命令
train['Survived'].value_counts()来查看在Survived属性中各值的数量:

八成0就是没救回来的,1就是救回来的。先在问题就变成了看其余属性中,某个属性哪些取值对应Survived中的0,哪些对应1。
3.2.1 Pclass 客舱等级
直接画柱状图来看:
sns.barplot(x="Pclass", y="Survived", data=train)对于barplot函数,Seaborn会对”Pclass“列中的数值进行归类后按照estimator参数的方法(默认为平均值)计算相应的值,计算出来的值就作为条形图所显示的值(条形图上的误差棒则表示各类的数值相对于条形图所显示的值的误差)。如下:
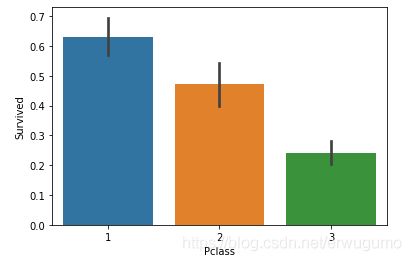
可以看出来,Pclass值越小,Survived值越高。
怎么理解这个平均值呢?举个例子吧,Pclass=1一共10个人,有6个获救,那么就有6个Survived为1,总和为6,平均值为6/10=0.6。其他也一样。看来有钱的明显更容易获救。
3.2.2 Sex 性别
柱状图走起:
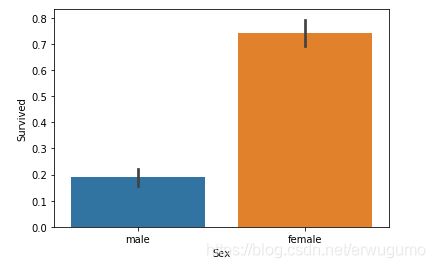
可以看出来,女性获救的比例是男性的四倍还多= =。
3.2.3 Age 年龄
额,可能这个用柱状图不太合适,不过先试试吧:
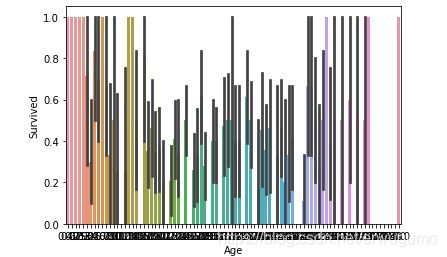
这效果太差了,什么都看不出。得换一种图。
我们来想一想我们需要什么:我们需要年龄与生还与否的关系,也就是说,给我一个年龄,我能估计出他更可能死还是被救。怎么办呢?用密度图。代码如下:
facet = sns.FacetGrid(train, hue="Survived",aspect=2)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, 100))
facet.add_legend()
plt.xlabel('Age')
plt.ylabel('density') 有点难看懂。主要使用的函数为FacetGrid,直观来讲,可以把这个函数画出来的图像看成是多个y轴的图像,最简单的2y轴图像就是左侧一个y轴,右侧一个y轴,相信大家都看过。这种图像可以很轻松点看出来在同一个条件(X的值相同)下,不同y值的大小关系;也可以看出来在一个趋势下(X由小到大,相当于由左到右)不同y值的趋势。对于本组数据,两个y轴分别为Survived取值0或1,x轴为年龄,完美。
如何画呢?
首先调用FacetGrid函数,第一个参数必须是DataFrame格式;第二个参数hue为第一个参数中的列名,官方文档中解释为“It can also represent levels of a third varaible with the ``hue``parameter”,即“多个y轴”这一功能通过hue实现;第三个参数aspect为一个比值,用于调整x轴的单位长度。这个函数会返回一个FacetGrid对象,包含数据集和用于画图的变量。对于这些变量的使用,需要函数FacetGrid.map。
正好,下面就用这个函数了,官方文档如下描述“Apply a plotting function to each facet's subset of the data”,将函数图像应用于数据的每一个子集。第一个参数为sns.kdeplot。wdnmd,这又是个啥?
这个函数就是用来实现“密度图”的。kde全称kernel density estimation,核密度估计,简而言之,就是根据离散采样估计整体的概率分布。参见该链接。对于本例,“某一年龄中Survived中取值为0或1的个数”就是一个采样,对于全部年龄,都会有一个对应的采样。我们可以想象一下这些采样画成直方图,应该就是类似上面乱七八糟的样子,但是有个问题:这个直方图的纵轴的值与“该年龄生还的概率”有直接关系,意思是这个值可能为1,但是这没啥用——我们真正想要的是“某段年龄生还的概率”,因为直方图是离散的,虽然我们一定可以得到一个值,但是由于部分值的缺失、样本数量太少等原因,直方图不能很好的反映概率。我们就需要根据直方图绘制概率密度图——我年龄在[0,max]之间,那对应我生还就有一个概率。如何求呢,就用到kde了。kde的原理有些复杂,但我们要调用就很简单了,直接sns.kdeplot即可。
那么第二个参数值为age就可以理解了,它就是kde需要的数据。第三个参数shade为True表示将函数图像与x轴部分变成实心的。
接下来的set、add、xlable、ylable用于调整图像的x轴范围、图像名称、x轴y轴名称。
效果如下:
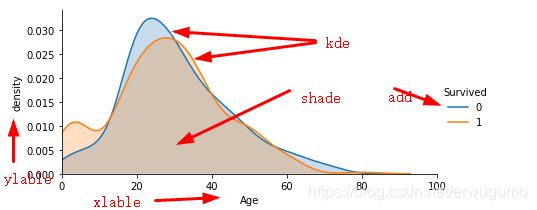
从这个图我们就能看出来,15岁以下生还的概率更高,15~30死亡概率更高,之后差不多。说明老幼优先还是有点效果的。
3.2.4 SibSp 兄弟数量
同样是数值变量,直接直方图走起。

看来亲属在1~2个的乘客生还概率最高啊。
3.2.5 Parch 父母与子女数量
Parch为数值变量,先barplot没错:

emmmmm,是值越高生还概率越低么?存疑。
3.2.6 Fare 票价
票价是连续数值属性,这就难受了,用barplot一定难看。我们用分区间数频率的方法看一下吧。
这个有一点难,我们分步来做:
①、将区间划分好
我们来看票价的最大值和最小值,用max和min函数:

最大值为512,最小值为0,差距太大了,先尝试按0~600,每100为一个区间吧。
区间储存端点,格式为list,因此代码如下:
l=list(range(0,700,100))(0,700)是左闭右开,所以是0~600,每隔100一个区间。
②、数据准备
简而言之,就是我们准备区间化的数据。我们准备区间化两组数据:第一组是被救上来的人的船票价格,第二组是没被救上来的船票价格。都需要DataFrame格式。这就用到之前对DateFrame的选择了,还用到了布尔下标:
s1=train[train['Survived']==1]['Fare']
s2=train[train['Survived']==0]['Fare']注意,布尔下标不能直接是'Survived'==1,要把train加上。
这样我们就分别得到了两组数据。
③、数据区间化
这个有点难理解,第二步我们不是已经把数据准备好了么,是两列数据,那现在我有一列数据假如说是150,250,350,那区间话之后就变成了(100,200],(200,300],(300,350],这个区间的开闭是怎么确定的呢?用函数的参数right=True控制。
也就是说,这相当于一个映射,把一个实数映射成一个空间。代码如下:
qujian1=pd.cut(s1,l1,right=True)效果如下:左边是原数据,右边是区间化后的数据。
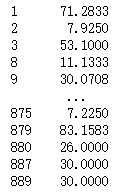

④、区间计数
我们既然已经分好区间了,那么下一步就是想要知道各区间都有多少人。使用如下代码:
pinshu1=qujian1.value_counts(sort=False)value_counts函数用于对元素出现的次数计数,默认是次数多的在前,次数少的在后,但我们不想要这个顺序,我们需要这个计数保持原来的顺序,即区间由小到大,因此要令其不排序。效果如下:

额,看起来效果不怎么样啊,大多数人都是在0~100这个区间。我们不如把区间调小,不然会丢失细节:
l1=list(range(0,100,10))
l2=list(range(100,700,100))
l1.extend(l2)现在区间就变细了。效果如下:

还不错。
⑤、计算各区间的获救概率
这个就很简单了:
s1=train[train['Survived']==1]['Fare']
l1=list(range(0,100,10))
l2=list(range(100,700,100))
l1.extend(l2)
qujian1=pd.cut(s1,l1,right=True)
pinshu1=qujian1.value_counts(sort=False)
s2=train[train['Survived']==0]['Fare']
l1=list(range(0,100,10))
l2=list(range(100,700,100))
l1.extend(l2)
qujian2=pd.cut(s2,l1,right=True)
pinshu2=qujian2.value_counts(sort=False)
pinlv1=pinshu1/(pinshu1+pinshu2)
pinlv1.plot(kind='bar')先求各区间被救人数,再求各区间没被救人数,然后就可以求出获救绿,柱状图一画ok。注意这里可以直接用Series的plot方法,参数kind选择bar即可。效果如下:

总体来说是富人得救率高啊。
3.3 数据深入分析
在3.2中,我们已经对Pclass、Sex、Age、Sibsp、Parch、Fare这六个属性进行了分析,还剩PassengerId、Name、Ticket、Cabin、Embarked这些属性没有分析。因为它们或者是序数属性或者是标称属性,难以直接看出关系。所以留到这一节。
3.3.1 PassengerId 乘客序号
打扰了,这个是真没用。
3.3.2 Name 乘客姓名
我们观察乘客姓名,发现了如下规律:
所有乘客的姓名都是按“aaa,bb.cc”格式写的,其中这个bb很有用,bb指的就是该乘客的称呼,如“Mr”、“Miss”等。
这算废物利用吧。
我们不如新建一列专门存这个称呼。代码如下:
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())好长,而且有之前没见过的apply方法。解释如下:
我们新建了一个匿名函数x,x的用途呢,是返回bb,怎么做到的?
首先,对于一个名字,先用split(,)将其分成aa和bb.cc两部分,选择第1部分,也就是bb.cc,再用split(.)将其分成bb和cc两部分,选择第0项bb,然后用strip删除前后的空格。
那为什么要用apply呢?简洁,而且对于参数在元组或字典中的函数,用apply调用可以按序将参数传入函数,这就相当于很多次循环,对all_data的Name这列的每一个元素,都传入了x这个函数作为参数,返回作为title这列的元素值。
这样我们就得到了名为title的一列。
看看都有什么吧:
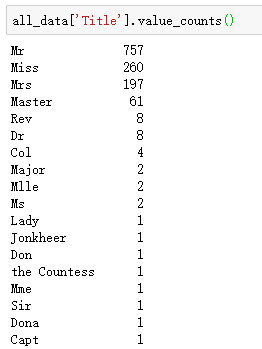
757个Mr,260个Miss......
类型不多,可以从这里入手看一看。
但还是有点多啊,能不能再缩小一点呢?比如说把Lady、Mlle、Mme全看成Miss,毕竟这几个称呼的人太少了;Sir也可以归类到Mr里。
这样看来,我需要一个多对一的字典啊。这个多对一的字典怎么生成呢?代码如下:
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))主要用了update和fromkeys两个函数。
fromkey以第一个参数作为键,第二个参数作为值生成一个新字典,由于第一个参数可以是一个list,所以这可以形成一个多对一的字典。
update的参数是一个字典,会将参数字典中的键值对更新到原字典里面。
于是我们就有了一个多个多对一的字典。
如何利用这个字典将title这一列数据归类呢?很简单,用DataFrame的map函数,传入一个字典就自动归类了:
all_data['Title'] = all_data['Title'].map(Title_Dict)效果如下:

嗯,被压缩的很少了。
然后来看一看吧,直接barplot:

。。。。。。Mr果真是最惨的,但是Royalty和Master好想获救率很高啊。这就是我们通过name额外得到的信息。
3.3.3 Ticket 船票编号
我原本以为船票是一人一张,因此编号也是一人一个——实际上不是这样,有联票的存在。也就是说,几个人共用一张票。那么,自己用一张票和一家人用一张联票,生存率会有差距么?应该有,亲人肯定优先救亲人吧。
我们来看一下一张联票都能几个人用:
all_data['Ticket'].value_counts()
返回值为Series,类似一个字典。
看得出来,买编号为CA. 2343的船票这家是个大户人家,有11个人在这船上。如下:
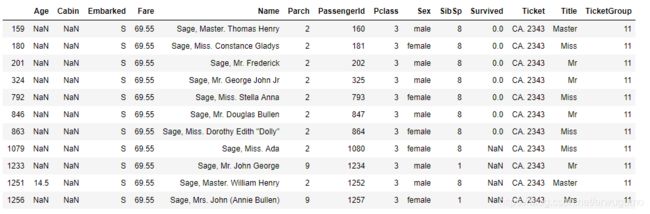
嘿,还真是一家人,都是Sage家的。训练集的全灭。
1601和CA 2144也不少,都有8个人。
现在来看一下我们想知道什么:同一张船票对应的人越多,获救率是不是越高?
这得怎么看呢?分类么?把联票中上船人数相同的归为一类,看他们的生还率高低——比如说1601和CA 2144就是一类这样。那该怎么做呢?
我们来一个映射吧,船票名字映射到联票人数——新建一列为TicketGroup,保存为联票人数,代码如下:
Ticket_Count = all_data['Ticket'].value_counts()
all_data['TicketGroup'] = all_data['Ticket'].apply(lambda x:Ticket_Count[x])
sns.barplot(x='TicketGroup', y='Survived', data=all_data)首先建立一个字典,键名为船票编号,键值为联票人数。注意Series直接可以当字典用。然后新建一列,匿名函数把键名转为键值。这里的确看出来匿名函数好用了,不用循环,十分简单。然后画图看一下:

这是人越多获救率越低啊。
3.3.4 Cabin 房间号
房间号类似船票编号,也是一个房间可能住好几个人的——所以我想到也可以用类似船票的处理方式来处理房间号。可是有一个大问题,房间号的缺失率太高了,大月只有百分之20%的人的房间号不是NaN。

对于不是NaN的值,都有一个特点,或者是一间房间,或者是多间房间,都是一个大写字母加一个数字——字母不同会不会导致获救率不同呢?可以一试:
all_data['Cabin'] = all_data['Cabin'].fillna('Z')
all_data['RoomNum']=all_data['Cabin'].apply(lambda x:x[0])先把所有的NaN全置为Z,利用fillna函数可以很轻易的完成这个。然后新建一列RoomNum,记录房间号的首字母。匿名函数太好用了。
然后出图:

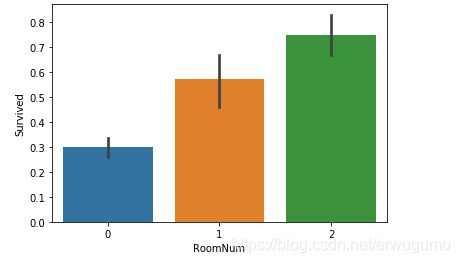
看来没有房间号记录的苦命人生还率很低啊。房间号为E、D、B的人获救概率是苦命人的二倍多。
那么我们可以将生存率相仿的分为一组,从而减少参数的取值:
all_data['Cabin'] = all_data['Cabin'].fillna('Z')
all_data['RoomNum']=all_data['Cabin'].apply(lambda x:x[0])
def Cabin_Label(x):
if ((x=='E')|(x=='D')|(x=='B')):
return 2
elif ((x=='C')|(x=='G')|(x=='A')|(x=='F')):
return 1
else:
return 0
all_data['RoomNum']=all_data['RoomNum'].apply(Cabin_Label)
sns.barplot(x='RoomNum',y='Survived',data=all_data)这样就把参数减少到三个:
3.3.5 Embarked 上船的港口编号
这个乍一看好像屁用没有。实际呢?需要我们处理一下。

嗯,所有人都从三个港口上船:S、C和Q。其中S上船的人最多。

看上去C上船的人生还率高一点。或者是这里妹子多?
3.3.6 SibSp+Parch 亲人数量
在上一节,我们分别分析了每个人的SibSp和Parch,但是实际上,这两者是可加的,和为该乘客的亲人数量。这个值比SibSp或Parch各自能更好的反映亲人数量与生还率的关系。先新建一行FamilyMem保存它们的和。
train['FamilyMem']=train['SibSp']+train['Parch']
sns.barplot(x='FamilyMem',y='Survived',data=train)效果如下:

果然,不是孤儿的,亲人越少的生还率越高。我想起来原来看烈火英雄的时候:“非独生子向前一步走”。大概是一个意思。
由此我们可以吧生存率分为三类:
1~3人的、0和4~6人的,6人以上的。这三类分别具有相似的生还率。因此可以分为一类。
可以通过这一方法减少FamilyMem的取值:
all_data['FamilyMem']=all_data['SibSp']+all_data['Parch']
def Fam_Label(x):
if (x>=1)&(x<=3):
return 2
elif (x==1)|((x>=4)&(x<=6)):
return 1
else:
return 0
all_data['FamilyMem']=all_data['FamilyMem'].apply(Fam_Label)
sns.barplot(x='FamilyMem',y='Survived',data=all_data)注意if的条件要各自用括号括起来。
效果如下:

明显标号为2的家庭生还率更高啊。
4、总结
通过学习该网址这一博客,了解了许多数据挖掘中特征处理的知识。对于数据的不同特征与最终结果的关系有了一个整体的认识,对于下一步数据的具体处理提供帮助。对于各类数据,总结如下:
| 特征类型 | 特征名称 | 处理方式 |
|---|---|---|
| 离散数值特征 | Pclass | barplot |
| Age | FacetGrid+kdeplot | |
| SibSp | barplot | |
| Parch | barplot | |
| SibSp+Parch | barplot | |
| 连续数值特征 | Fare | pd.cut |
| 二元特征 | Sex | barplot |
| 标称特征 | Name | 格式提取+barplot |
| Ticket | 数值映射+barplot | |
| Cabin | 格式提取+barplot | |
| Embarked | barplot | |
| 序数特征 | PassengerId | pass |
由此可以总结出二元分类问题的数据分析流程:
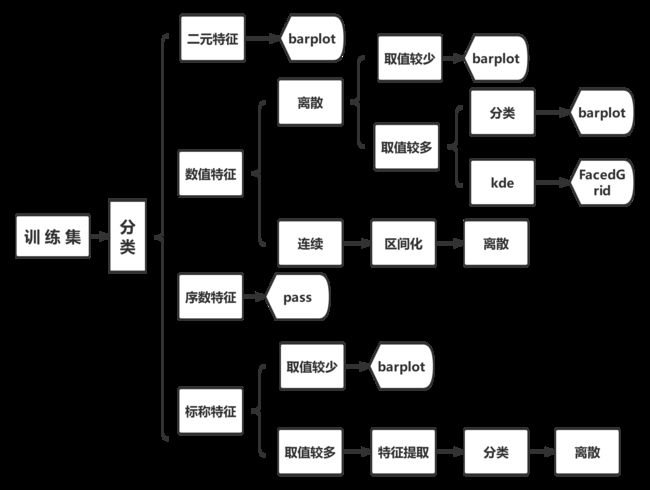
另外,对于某些具有关联的特征,可以经过处理之后合成新的特征。