数据挖掘——航空公司客户分类与价值评估案例
1. 背景和目标
1.1 背景
- 航空公司竞争压力大,企业营销焦点由产品中心转为客户中心
- 针对不同类型的用户,进行精准营销,实现利润最大化
- 解决问题的关键是建立合理的客户价值评估模型,对客户进行分类,有针对性地进行营销。
1.2 目标
- 利用已有的航空数据,进行客户分类
- 就分类结果对不同类别的客户进行特征分析,比较不同类客户的客户价值
- 对不同价值的客户类别提供个性化服务,制定相应的营销策略
2. 技术和分析方法
2.1 RFM模型
RFM模型属于客户关系管理(CRM)的一种。该模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
客户细分模型是通过三个指标:
-
最近消费时间间隔(Recency):上一次购买的时候。理论上,上一次消费时间越近的顾客应该是比较好的顾客,对提供即时的商品或是服务也最有可能会有反应。
-
消费频率(Frequency):顾客在限定的期间内所购买的次数。
-
消费金额(Monetary)
根据三个指标,在三个维度上进行分类,得到8组用户

2.2 K-means聚类法
k-means算法知识
sk-learn官网的K-means实现
3. 数据挖掘实现
3.1 引入相关库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
import sklearn.datasets as ds
import matplotlib.colors
from sklearn.cluster import KMeans
%matplotlib inline
#设置属性,防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
3.2 读取数据
pd.read_csv() #导入数据
data.head() #查看前几行
data.shape #查看数据分布(行,列)
3.3 数据探索分析
data.info() #查看每个column特征的非空数据量、数据类型
data.describe().T # 查看每个数值类特征的总数量(包括空值)以及五值分布:平均值、最大值、最小值、标准差、四分位数
data.isnull().sum().sort_values(ascending = False) #查看缺失值情况
3.4 数据预处理
- 数据清洗:处理异常值和缺失值
- 特征提取:仅保留相关特征,删除不相关、弱相关或冗余特征
- 标准化处理
#数据清洗部分
# 丢弃票价为空的记录
data = data[data['SUM_YR_1'].notnull()&data['SUM_YR_2'].notnull()]
#保留票价非零或平均折扣率为零的值
temp1 = data['SUM_YR_1'] !=0
temp2 = data['SUM_YR_2'] != 0
temp3 = data['avg_discount'] == 0
data = data[temp1 |temp2|temp3] # 上述三个是布尔判别式
#导出清洗后的数据
result = 'C:\\Users\\Zoe Wang\\Desktop\\新建文件夹\\data_cleaned.csv' #创建数据保存位置
data.to_csv(result,sep = ',',encoding = 'utf-8')
# 特征提取部分
'''
R是最近消费时间间隔(Recency),可以用LAST_TO_END(最后一次乘机时间至观察窗口末端时长);
F是消费频率(Frequency),FLIGHT_COUNT(观测窗口内的飞行次数)
M是消费金额(Monetary),航空票价收到距离和舱位等级多种因素的影响, 舱位因素=舱位所对应的折扣系数AVG_DISCOUNT的平均值,距离因素=一定时间内累积的飞行里程SEG_KM_SUM航空公司的会员系统,用户的入会时间长短能在一定程度上影响客户价值,所以增加指标入会时间长度,即客户关系长度:会员入会时间距观测窗口结束的月数=观测窗口的结束时间-入会时间(单位:月),即LOAD_TIME-FFP_DATE
最终确定,需要五个指标:
L=LOAD_TIME-FFP_DATE(会员入会时间距观测窗口结束的月数=观测窗口的结束时间-入会时间(单位:月))
R=LAST_TO_END(客户最近一次乘坐公司距观测窗口结束的月数=最后一次。。。)
F=FLIGHT_COUNT(观测窗口内的飞行次数)
M=SEG_KM_SUM(观测窗口的总飞行里程)
C=AVG_DISCOUNT(平均折扣率)
'''
#数据筛选
df = data[['LOAD_TIME','FFP_DATE','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
#构造LRFMC特征
def STRCTURE_LRFMC(data_set):
df_LOAD_TIME = pd.to_datetime(data_set['LOAD_TIME']) #pd.to_datetime()将给定的数据按指定格式转换成日期格式
df_FFP_DATE = pd.to_datetime(data_set['FFP_DATE'])
LOAD_TIME_FFP_DATE = df_LOAD_TIME-df_FFP_DATE
df2 = data_set.copy()
df2['L'] = LOAD_TIME_FFP_DATE.map(lambda x:x/np.timedelta64(30*24*60,'m'))
df2['R'] = data_set['LAST_TO_END']
df2['F'] = data_set['FLIGHT_COUNT']
df2['M'] = data_set['SEG_KM_SUM']
df2['C'] = data_set['avg_discount']
df3 = df2[['L','R','F','M','C']]
return df3
df3 = STRCTURE_LRFMC(data)
# 标准化处理,使用的是标准差标准化
def std_normal(data):
data2 = (data - data.mean())/data.std()
data2.columns = ['Z'+ i for i in data.columns]
return data2
df4 = std_normal(df3)
3.5 K-Means聚类模型构建
- 采用K-Means算法对客户数据进行客户分群,聚成五类
- 在讨论聚几类比较合适时,除了业务需要,也可根据聚类的性能,聚类类别数和组内误方差的变化,出现“肘点”对应的类别数可以认为最优。
# 按照5类进行聚类分析
k = 5
# 调用k-means算法
model = KMeans(n_clusters=k, init= 'random',random_state=28,n_jobs=4)# n_clusters是聚类数,即k;init是初始化方法,可以是'k-means ++','random'或者自定义,default=’k-means++’
model.fit(df4) # 用于执行训练过程
# r为每个类别的数目,r3为每个样本聚类的类别,
r1 = pd.Series(model.labels_).value_counts() # model.labels_ 每个样本对应的簇类别标签,统计各类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # model.cluster_centers_ 聚类中心,找出聚类中心
r = pd.concat([r2,r1],axis = 1) # 得到聚类中心对应的类别下的数目
r.columns = list(df4.columns)+[u'聚类类别'] #重命名表头
r.to_excel('C:\\Users\\Zoe Wang\\Desktop\\新建文件夹\\KMeansNum.xls')
r3 = pd.concat([df4,pd.Series(model.labels_,index = df4.index)],axis =1)
r3.columns =list(df4.columns) +[u'聚类类别']
r3.to_excel('C:\\Users\\Zoe Wang\\Desktop\\新建文件夹\\KMean.xls')
# 进行聚类评估
distortions = []
for i in range(1,10):
km = KMeans(n_clusters= i, init = 'random',random_state= 28 )
km.fit(df4)
distortions.append(km.inertia_)
plt.plot(range(1,10),distortions,marker = 'o')
plt.xlabel("簇数量")
plt.ylabel("簇内误方差(SSE)")
plt.show()
3.6 聚类结果展示
max = r2.values.max()
min = r2.values.min()
# 绘图
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, polar=True)
# 显示在雷达图中标签
labels = ["客户关系长度","消费的时间间隔","总消费次数","总消费金额","平均折扣率"]
# 绘制的变量数
num_vars = len(labels)
# 设置雷达图的角度,用于平分切开一个圆面
angles=np.linspace(0, 2*np.pi, num_vars, endpoint=False).tolist()
# 将雷达图一圈 封闭起来,将起始值附加到结尾。
# !!!注意,标签也要进行封闭,我在练习的时候在这里卡住了。
angles += angles[:1]
labels += labels[:1]
#构造函数,绘制每个圈
def add_to_radar(feature):
values = r2.loc[feature].tolist()
values += values[:1]
# 绘制折线图
ax.plot(angles, values, 'o-', linewidth = 2, label = "第%d类客群:%d人"%(feature+1,r.loc[feature,"聚类类别"]))
# 填充颜色
ax.fill(angles, values, alpha=0.25)
for i in range(5):
add_to_radar(i)
# 固定开始轴.
ax.set_theta_offset(np.pi / 2)
ax.set_theta_direction(-1)
# 添加每个特征的标签,np.degrees()将弧度转化为角度
ax.set_thetagrids(np.degrees(angles), labels, fontsize=15)
#调整标签位置
for label, angle in zip(ax.get_xticklabels(), angles):
if angle in (0, np.pi):
label.set_horizontalalignment('center')
elif 0 < angle < np.pi:
label.set_horizontalalignment('left')
else:
label.set_horizontalalignment('right')
# 设置雷达图的范围
ax.set_ylim(min-0.1, max+0.1)
# 添加标题
plt.title('客户群特征分析图', fontsize=20)
# 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True)
# 显示图形
plt.show()
plt.savefig("客户群特征分析图.jpg",dpi=200)

3.7 模型结果分析
3.7.1 客户价值分析
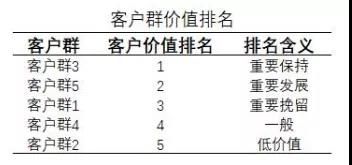
针对“客户群特征分析图”所示的聚类结果,结合业务进行特征分析。我们重点关注的是L(客户关系长度)、F(消费频率)、M(飞行里程)三个指标:
- 客户群1:在C属性上最大,可定义为重要挽留客户;
- 客户群2:在R属性上最大,在F、M属性上最小,可定义为低价值客户;
- 客户群3:在F、M属性上最大,在R属性上最小,可定义为重要保持客户;
- 客户群4:在L、C属性上最小,可定义为一般客户;
- 客户群5:在L属性上最大,可定义为重要发展客户;
3.7.2 客户群价值排名 - 重要保持客户:C(平均折扣率较高、仓位等级较高)、F(乘坐次数)、M(里程)较高,R(最近乘坐航班)低。应将资源优先投放到这类客户身上,进行差异化管理,提高客户的忠诚度和满意度。
- 重要发展客户:C较高,R、F、M较低。这类客户入会时长(L)短、当前价值低、发展潜力大,应促使客户增加在本公司和合作伙伴处的消费。
- 重要挽留客户:C、F 或 M 较高,R较高 或 L变小,客户价值变化的不确定性高。应掌握客户最新信息、维持与客户的互动。
- 一般和低价值客户:C、F、M、L低、R较高。这类客户可能在打折促销时才会选择消费。
3.8 应用
差异化管理、精准营销,提高客户忠诚度、满意度,延长客户高水平消费。
- 会员升级与保级(积分削减等):在会员升级或保级评价的时间点前,对接近但尚未达到要求的较高消费客户进行提醒或促销活动,提高客户满意度。
- 首次兑换:对接近但尚未达到标准的会员进行提醒或促销活动,提高客户满意度。
- 交叉销售:通过与非航空类企业的合作,使客户在其他消费过程中获得本公司积分,增强与公司联系,提高忠诚度
4. 小知识点补充
1.pd.to_datetime()
to_datetime()方法将给定的数据按照指定格式转换成指定的日期格式。
Timedelta在pandas中是一个*表示两个datetime值之间的差(如日,秒和微妙)*的类型,2个Datetime数据运算相减得出的结果就是一个Timedelta数据类型
例如
运行pd.to_datetime('2019-9-4') - pd.to_datetime('2018-1-1'),可得到结果Timedelta('611 days 00:00:00')
2.data.map()
语法:map(function, iterable, ...)
data.map()会以data的每个参数调用function函数,返回包含每次function函数返回值的新列表。