深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])
目录
1. 概述
2. 经典Neck的回顾
2.1 FPN(特征金字塔结构)
2.2 PANet
2.2.1 创建了自下而上的路径增强
2.2.2 Adaptive Feature Pooling
2.3 Bi-FPN及FPN的演进ASFF,NAS-FPN,Recursive-FPN)
3 典型head回顾
3.1 RPN(RegionProposal Networ)
3.1.1 RPN的运作机制
3.1.2 RPN详解
3.2 无融合SSD类型的head
3.3 自上而下单向融合head
1. 概述
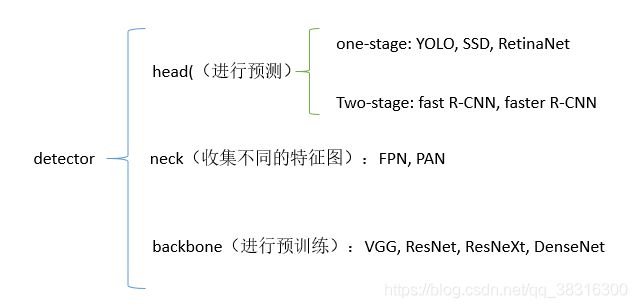
检测器通常由两部分组成:backbone和head。前者在ImageNet上进行预训练,后者用来预测类别信息和目标物体的边界框。
对于backbone部分,在GPU平台上运行的检测器,它们的backbone可能是VGG, ResNet, ResNetXt,或者是DenseNet。在CPU平台上运行的检测器,它们的backbone可能是SqueezeNet,MobileNet或者是ShuffleNet。
对于head部分,通常分为两类:one-stage和two-stage的目标检测器。Two-stage的目标检测器的代表是R-CNN系列,包括:fast R-CNN, faster R-CNN,R-FCN和Libra R-CNN. 还有基于anchor-free的Two-stage的目标检测器,比如RepPoints。One-stage目标检测器的代表模型是YOLO, SSD和RetinaNet。在最近几年,出现了基于anchor-free的one-stage的算法,比如CenterNet, CornerNet, FCOS等等。
在最近几年,目标检测器在backbone和head之间会插入一些网络层,这些网络层通常用来收集不同的特征图。我们将其称之为目标检测器的neck。通常,一个neck由多个bottom-up路径和top-down路径组成。使用这种机制的网络包括Feature Pyramid Network(FPN),Path Aggregation Network(PAN),BiFPN和NAS-FPN。
所以,现阶段的目标检测器主要由4部分组成:
Input、Backbone(提取特征训练)、Neck(整合收集特征)、Head(目标检测)。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第1张图片](http://img.e-com-net.com/image/info8/820376bee0254f2e8d2d22726c27f610.jpg)
综上所述,一个普通的目标检测器由下面四个部分组成:

物体检测性能提升,一般主要通过数据增强、改进Backbone、改进FPN、改进检测头、改进loss、改进后处理等6个常用手段。
2. 经典Neck的回顾
2.1 FPN(特征金字塔结构)
转自博文:
FPN详解_WZZ18191171661的博客-CSDN博客_fpn
特征金字塔可以在速度和准确率之间进行权衡,可以通过它获得更加鲁棒的语义信息,这是其中的一个原因。
如下图所示,我们可以看到我们的图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。图中我们在第1层(请看绿色标注)输出较大目标的实例分割结果,在第2层输出次大目标的实例检测结果,在第3层输出较小目标的实例分割结果。检测也是一样,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标。

浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以利用最后一个卷积层上的feature map来进行预测(如下图图所示)。这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类。这种方法的优点是速度快、需要内存少。它的缺点是我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第2张图片](http://img.e-com-net.com/image/info8/79621f041068475aad48c0bce0ab98c8.jpg)
最后一层特征图预测
如果关注每一层的特征图(如下图所示)这是一个特征图像金字塔,整个过程是先对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测(BB的位置)。这种方法的缺点是计算量大,需要大量的内存;优点是可以获得较好的检测精度。它通常会成为整个算法的性能瓶颈,由于这些原因,当前很少使用这种算法。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第3张图片](http://img.e-com-net.com/image/info8/848413dc2d2b4558aeba60076788571a.jpg)
为了解决上图结构的缺点,有学者提出下图的结构,减少预测的特征图。它的设计思想就是同时利用低层特征和高层特征,分别在不同的层同时进行预测,这是因为我的一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。它的优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。它的缺点是获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第4张图片](http://img.e-com-net.com/image/info8/c27c81be9c044219929d8d126c9b24cf.jpg)
FPN它的架构如下图所示,整个过程如下所示,首先我们在输入的图像上进行深度卷积,然后对Layer2上面的特征进行降维操作(即添加一层1x1的卷积层),对Layer4上面的特征就行上采样操作,使得它们具有相应的尺寸,然后对处理后的Layer2和处理后的Layer4执行加法操作(对应元素相加),将获得的结果输入到Layer5中去。其背后的思路是为了获得一个强语义信息,这样可以提高检测性能。认真的你可能观察到了,这次我们使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,我们将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,这样我们就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第5张图片](http://img.e-com-net.com/image/info8/88bc1f6b7f944cf2b8e1b1e83be69bee.jpg)
2.1.1 利用FPN构建Faster R-CNN检测器步骤
首先,选择一张需要处理的图片,然后对该图片进行预处理操作;
然后,将处理过的图片送入预训练的特征网络中(如ResNet等),即构建所谓的bottom-up网络;
接着,如下图所示,构建对应的top-down网络(即对层4进行上采样操作,先用1x1的卷积对层2进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作,最后);
接着,在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归操作;
接着,将上一步获得的候选ROI分别输入到4、5、6层上面分别进行ROI Pool操作(固定为7x7的特征);
最后,在上一步的基础上面连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层;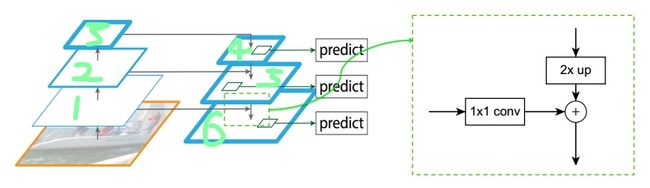
注:层1、2、3对应的支路就是bottom-up网络,就是所谓的预训练网络,文中使用了ResNet网络;由于整个流向是自底向上的,所以我们叫它bottom-up;层4、5、6对应的支路就是所谓的top-down网络,是FPN的核心部分,名字的来由也很简单。

Faster R-CNN+FPN细节图
FPN能够很好地处理小目标的主要原因是:
- FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息);
- 对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息)
FPN总结:
FPN 构架了一个可以进行端到端训练的特征金字塔;
通过CNN网络的层次结构高效的进行强特征计算;
通过结合bottom-up与top-down方法获得较强的语义特征,提高目标检测和实例分割在多个数据集上面的性能表现;
FPN这种架构可以灵活地应用在不同地任务中去,包括目标检测、实例分割等;
2.2 PANet
转自:
http://blog.leanote.com/post/lily/PANet
PANet是18年的一篇CVPR,作者来自港中文,北大,商汤与腾讯优图,PANET可看作Mask-RCNN+,是在Mask-RCNN基础上做的几处改进。
解决问题:
- 低层级的特征对于大型实例识别很有用, 最高层级特征和较低层级特征之间的路径长
- 每个建议区域都是基于 从一个特征层级池化 得到的 特征网格而预测的,此分配是启发式的。由于其它层级的丢弃信息可能对于最终的预测还有用,这个流程还有进一步优化的空间
- mask 预测仅在单个视野上执行,无法获得更加多样化的信息
改进
- 缩短信息路径和用低层级的准确定位信息增强特征金字塔,创建了自下而上的路径增强
-
为了恢复每个建议区域和所有特征层级之间被破坏的信息,作者开发了适应性特征池化(adaptive feature pooling)技术
可以将所有特征层级中的特征整合到每个建议区域中,避免了任意分配的结果。
-
全连接融合层:使用一个小型fc层用于补充mask预测
下图是 PANet的结构:
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第6张图片](http://img.e-com-net.com/image/info8/11a7977a309a47d29146fb365a203f1d.jpg)
2.2.1 创建了自下而上的路径增强
改动原因:
-
low-level的feature是很利于定位用的,虽然FPN中P5也间接得有了low-level的特征,但是信息流动路线太长了如 红色虚线 所示 (其中有 ResNet50/101很多卷积层 )
-
本文在 FPN 的 P2-P5 又加了 low-level 的特征,最底层的特征流动到 N2-N5 只需要经过很少的层如绿色需要所示 (仅仅有几个降维 [3×3 ,stride 2 ]的卷积)
注:这个线路的长短是按照卷积层来算的。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第7张图片](http://img.e-com-net.com/image/info8/d8307256cdbc4bfe8b934bf38dd072ca.jpg)
2.2.2 Adaptive Feature Pooling
在FPN中,依据候选区域的大小将候选区域分配到不同特征层次。这样小的候选区域分配到low-level,大的候选区域分配到high-level。
- high level
Semantic - low level
location
无论是high还是low的feature都有用。
对于每个候选区域,我们提出了池化来自所有层次的特征,然后融合它们做预测,这称之为adaptive feature pooling(自适应特征池化).
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第8张图片](http://img.e-com-net.com/image/info8/ff4672cf42bf4893b03bca251ef7cc07.jpg)
- 对于每个候选区域,我们将其映射到不同特征层次,如上图深灰色区域
- 使用 ROIAlign 池化来自不同层次的特征网格
- 再使用融合操作(逐像素SUM或ADD)融合不同层次的特征网格
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第9张图片](http://img.e-com-net.com/image/info8/0abe200156b3423284843f1724438f43.jpg)
金字塔上四个灰色区域对应的是同一个proposal,根据特征图相应缩放,分别取到特征后进行融合,上图只是box分支的融合图,掩码分支的论文中没有画出来,但原理是一样的,拿上图来说,四个特征图分别全连接,然后融合,融合操作或者采取max,或者sum,或者相乘。
3.全连接层融合
全连接层具有不同于CNN的结构,CNN产生的特征图上每个像素点来自同一个卷积核,也就是常说的参数共享,另外,卷积核的大小往往为3*3,5*5,7*7,也就是说采集的是局部的信息。
全连接层其实可由卷积实现,可看作感受野为整个特征图的卷积核,所以全连接层是感受野更大的卷积,另外,这里的卷积参数不共享,每个像素点拥有一个卷积核,所以区别在于感受野和参数是否共享。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第10张图片](http://img.e-com-net.com/image/info8/58ab6a80ddad478392d87dc1c0c96713.jpg)
- conv1~4 3×3,256
- deconv 上采样2倍
- 短路 从 conv3 连接 fc , conv4_fc,conv5_fc , channel 减半 (减少计算量)
- mask大小 28×28
fc 产生 784×1×1
reshape 成和 FPN 预测的mask 相同的空间尺寸 - 相加 得到最终预测
通过消融实验发现:从 conv3 开始做 SUM 操作融合效果是最好的。
2.3 Bi-FPN及FPN的演进ASFF,NAS-FPN,Recursive-FPN)
FPN自从被提出来,先后迭代了不少版本。大致迭代路径如下图:
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第11张图片](http://img.e-com-net.com/image/info8/d1168afb34a84abba973dd18e26d8285.jpg)
PANet的提出证明了双向融合的有效性,而PANet的双向融合较为简单,因此不少文章在FPN的方向上更进一步,尝试了更复杂的双向融合,如ASFF、NAS-FPN和BiFPN。
ASFF
ASFF(论文:Learning Spatial Fusion for Single-Shot Object Detection)作者在YOLOV3的FPN的基础上,研究了每一个stage再次融合三个stage特征的效果。如下图。其中不同stage特征的融合,采用了注意力机制,这样就可以控制其他stage对本stage特征的贡献度。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第12张图片](http://img.e-com-net.com/image/info8/850607e05f814105b694fc0f58c44f63.jpg)
NAS-FPN和BiFPN
NAS-FPN和BiFPN,都是google出品,思路也一脉相承,都是在FPN中寻找一个有效的block,然后重复叠加,这样就可以弹性的控制FPN的大小。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第13张图片](http://img.e-com-net.com/image/info8/6dc8adce749147ffb04c3fb89f088189.jpg)
其中BiFPN的具体细节如下图。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第14张图片](http://img.e-com-net.com/image/info8/e7204df72d364351b9875a8a7b1ebbd0.jpg)
Recursive-FPN
递归FPN是此文写作之时前两周刚刚新出炉的(原论文是DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution),效果之好令人惊讶,使用递归FPN的DetectoRS是目前物体检测(COCO mAP 54.7)、实体分割和全景分割的SOTA,太强悍了。
下图给出了FPN与Recursive-FPN的区别,并且把一个2层的递归FPN展开了,非常简单明了,不做过多介绍。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第15张图片](http://img.e-com-net.com/image/info8/a0abefaffad04667bd38a2f489c1148f.jpg)
3 典型head回顾
3.1 RPN(RegionProposal Networ)
RPN第一次出现在世人眼中是在Faster RCNN这个结构中,专门用来提取候选框。
一些名词解释:
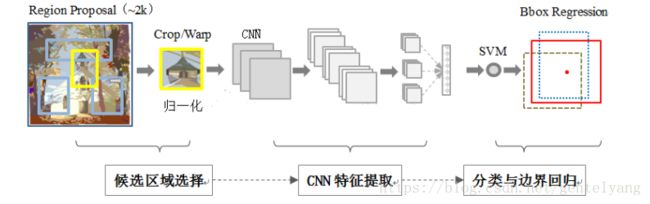
RCNN(Region with CNN feature)是卷积神经网络应用于目标检测问题的一个里程碑的飞跃。CNN具有良好的特征提取和分类性能,采用RegionProposal方法实现目标检测问题。算法可以分为三步(1)候选区域选择。(2)CNN特征提取。(3)分类与边界回归。
3.1.1 RPN的运作机制
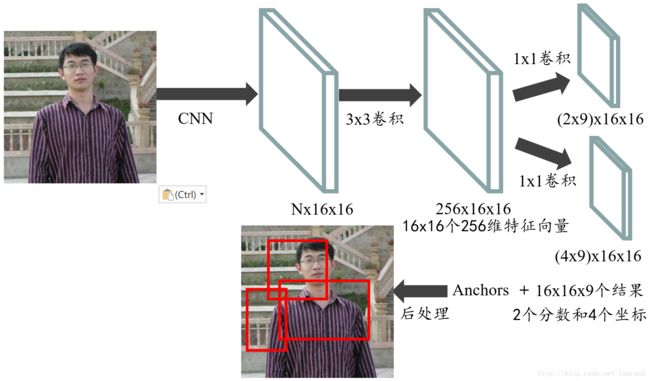
首先通过一系列卷积得到公共特征图,假设他的大小是N x 16 x 16,然后我们进入RPN阶段,首先经过一个3 x 3的卷积,得到一个256 x 16 x 16的特征图,也可以看作16 x 16个256维特征向量,然后经过两次1 x 1的卷积,分别得到一个18 x 16 x 16的特征图,和一个36 x 16 x 16的特征图,也就是16 x 16 x 9个结果,每个结果包含2个分数和4个坐标,再结合预先定义的Anchors,经过后处理,就得到候选框;整个流程如下图:
3.1.2 RPN详解
参考文章:
RPN 解析_lanran2的博客-CSDN博客_rpn
下图展示了RPN的整个过程,一个特征图经过sliding window处理,得到256维特征,然后通过两次全连接得到结果2k个分数和4k个坐标;相信大家一定有很多不懂的地方;我把相关的问题一一列举:
1.RPN的input 特征图指的是哪个特征图?
2.为什么是用sliding window?文中不是说用CNN么?
3.256维特征向量如何获得的?
4.2k和4k中的k指的是什么?
5.图右侧不同形状的矩形和Anchors又是如何得到的?
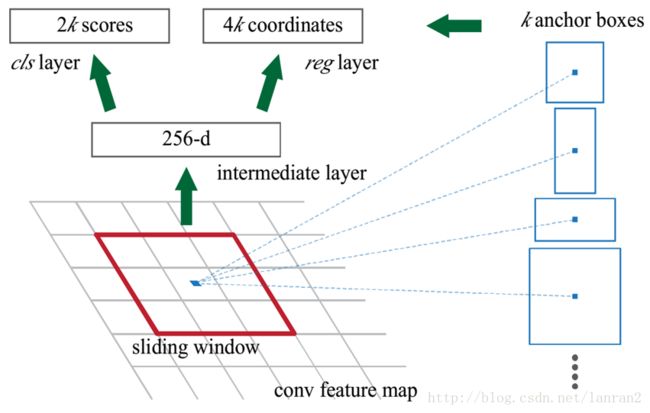
1,RPN的输入特征图就公共Feature Map,也称共享Feature Map,主要用以RPN和RoI Pooling共享;
2. 可以把3x3的sliding window看作是对特征图做了一次3x3的卷积操作,最后得到了一个channel数目是256的特征图,尺寸和公共特征图相同,我们假设是256 x (H x W)
3. 把这个特征图看作有H x W个向量,每个向量是256维,那么图中的256维指的就是其中一个向量,然后我们要对每个特征向量做两次全连接操作,一个得到2个分数,一个得到4个坐标,由于我们要对每个向量做同样的全连接操作,等同于对整个特征图做两次1 x 1的卷积,得到一个2 x H x W和一个4 x H x W大小的特征图,换句话说,有H x W个结果,每个结果包含2个分数和4个坐标;可以参考下图。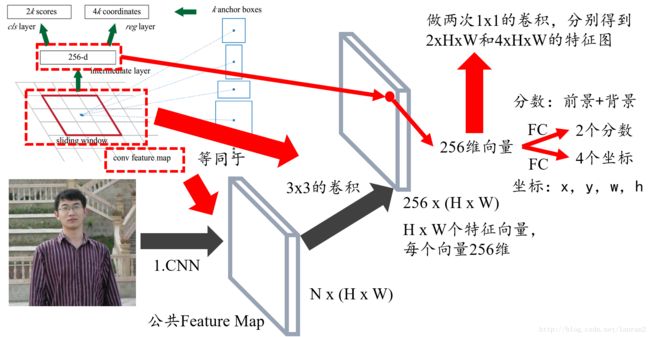
这里我们需要解释一下为何是2个分数,因为RPN是提候选框,还不用判断类别,所以只要求区分是不是物体就行,那么就有两个分数,前景(物体)的分数,和背景的分数;
我们还需要注意:4个坐标是指针对原图坐标的偏移,首先一定要记住是原图,下图说明的很清楚;
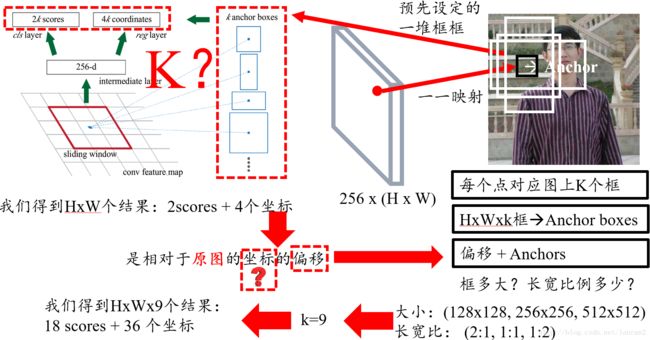
3.2 无融合SSD类型的head
无融合,又利用多尺度特征的典型代表就是2016年日出的鼎鼎有名的SSD,它直接利用不同stage的特征图分别负责不同scale大小物体的检测。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第16张图片](http://img.e-com-net.com/image/info8/9d95c5388f244410a30b9cee7f4762dd.jpg)
3.3 自上而下单向融合head
自上而下单向融合的FPN,事实上仍然是当前物体检测模型的主流融合模式。如我们常见的Faster RCNN、Mask RCNN、Yolov3、RetinaNet、Cascade RCNN等,具体各个FPN的内部细节如下图。
![深度学习笔记------现阶段的目标检测器结构解析(Neck[FPN,PANet,Bi-FPN],Head[rpn,yolo...])_第17张图片](http://img.e-com-net.com/image/info8/e9af5520a04c4352b8c80a45a977846e.jpg)