sklearn专题二:随机森林
目录
1 概述
1.1 集成算法概述
1.2 sklearn中的集成算法
2 RandomForestClassifier
2.1 重要参数
2.1.1 控制基评估器的参数
2.1.2 n_estimators
3 RandomForestRegressor
3.1 重要参数,属性与接口
3.2 实例:用随机森林回归填补缺失值
4 机器学习中调参的基本思想
5实例:随机森林在乳腺癌数据上的调参
1 概述
1.1 集成算法概述
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在 现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预 测疾病的风险和病患者的易感性。在现在的各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成 算法的身影也随处可见,可见其效果之好,应用之广。
集成算法的目标
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或 分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器(base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。
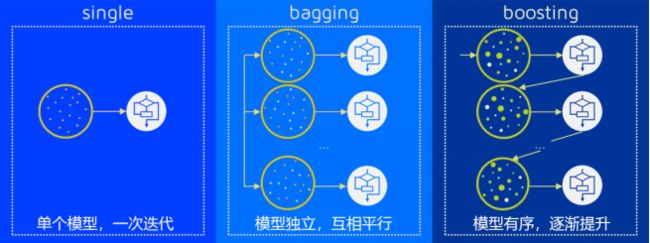
装袋法的核心思想是构建多个相互独立的评估器,然后对其预测进行平均或多数表决原则来决定集成评估器的结果。装袋法的代表模型就是随机森林。
提升法中,基评估器是相关的,是按顺序一一构建的。其核心思想是结合弱评估器的力量一次次对难以评估的样本进行预测,从而构成一个强评估器。提升法的代表模型有Adaboost和梯度提升树。
1.2 sklearn中的集成算法
sklearn中的集成算法模块ensemble
| 类 |
类的功能 |
| ensemble.AdaBoostClassifier |
AdaBoost分类 |
| ensemble.AdaBoostRegressor |
Adaboost回归 |
| ensemble.BaggingClassifier |
装袋分类器 |
| ensemble.BaggingRegressor |
装袋回归器 |
| ensemble.ExtraTreesClassifier |
Extra-trees分类(超树,极端随机树) |
| ensemble.ExtraTreesRegressor |
Extra-trees回归 |
| ensemble.GradientBoostingClassifier |
梯度提升分类 |
| ensemble.GradientBoostingRegressor |
梯度提升回归 |
| ensemble.IsolationForest |
隔离森林 |
| ensemble.RandomForestClassifier |
随机森林分类 |
| ensemble.RandomForestRegressor |
随机森林回归 |
| ensemble.RandomTreesEmbedding |
完全随机树的集成 |
| ensemble.VotingClassifier |
用于不合适估算器的软投票/多数规则分类器 |
集成算法中,有一半以上都是树的集成模型,可以想见决策树在集成中必定是有很好的效果。
2 RandomForestClassifier
class (n_estimators=’10’, criterion=’gini’, max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器。这一节主要讲解RandomForestClassifier,随机森林分类器。
2.1 重要参数
2.1.1 控制基评估器的参数
| 参数 |
含义 |
| criterion |
不纯度的衡量指标,有基尼系数和信息熵两种选择 |
| max_depth |
树的最大深度,超过最大深度的树枝都会被剪掉 |
| min_samples_leaf |
一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样 本,否则分枝就不会发生 |
| min_samples_split |
一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分 枝,否则分枝就不会发生 |
| max_features |
max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃, 默认值为总特征个数开平方取整 |
| min_impurity_decrease |
限制信息增益的大小,信息增益小于设定数值的分枝不会发生 |
2.1.2 n_estimators
这是森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越 大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的 精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越 长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
n_estimators的默认值在现有版本的sklearn中是10,但是在即将更新的0.22版本中,这个默认值会被修正为 100。这个修正显示出了使用者的调参倾向:要更大的n_estimators。
来建立一片森林吧
树模型的优点是简单易懂,可视化之后的树人人都能够看懂,可惜随机森林是无法被可视化的。所以为了更加直观 地让大家体会随机森林的效果,我们来进行一个随机森林和单个决策树效益的对比。我们依然使用红酒数据集。
1.导入我们需要的包
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine2.导入需要的数据集
wine=load_wine()
wine.data
wine.target3.复习:sklearn建模的基本流程
from sklearn.model_selection import train_test_split
Xtain,Xtest,Ytain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
clf=DecisionTreeClassifier(random_state=0)
clf=clf.fit(Xtain,Ytain)
score_c=clf.score(Xtest,Ytest)
rfc=RandomForestClassifier(random_state=0)
rfc=rfc.fit(Xtain,Ytain)
score_r=rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c)
,"Random Forest:{}".format(score_r)
)输出结果
Single Tree:0.9074074074074074 Random Forest:1.0
可以看出随机森林的效果比决策树好得多
4.画出随机森林和决策树在一组交叉验证下的效果对比
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc=RandomForestClassifier(n_estimators=25)
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10)
clf=DecisionTreeClassifier()
clf_s=cross_val_score(clf,wine.data,wine.target,cv=10)
plt.plot(range(1,11),rfc_s,label="Random Forest")
plt.plot(range(1,11),clf_s,label="Decision Tree")
plt.legend()
plt.show()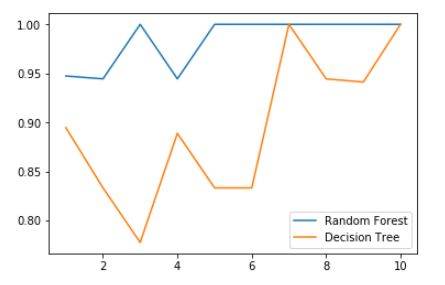
从图中可以看出,随机森林的效果比决策树的效果都是大于或者等于的。
5.画出随机森林和决策树在十组交叉验证下的效果对比
rfc_1=[]
clf_1=[]
for i in range(10):
rfc=RandomForestClassifier(n_estimators=25)
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_1.append(rfc_s)
clf=DecisionTreeClassifier()
clf_s=cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_1.append(clf_s)
plt.plot(range(1,11),rfc_1,label="Random Forest")
plt.plot(range(1,11),clf_1,label="Decision Tree")
plt.legend()
plt.show()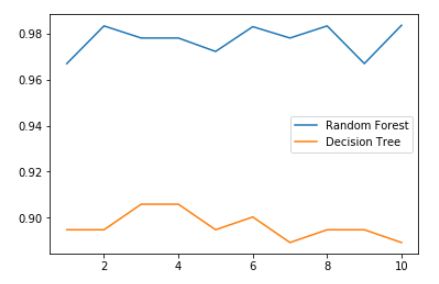
是否有注意到,单个决策树的波动轨迹和随机森林一致?
再次验证了我们之前提到的,单个决策树的准确率越高,随机森林的准确率也会越高
6.n_estimators
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()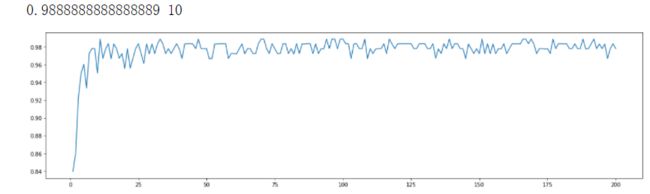
2.1.3 random_state
随机森林的本质是一种装袋集成算法(bagging),装袋集成算法是对基评估器的预测结果进行平均或用多数表决 原则来决定集成评估器的结果。在刚才的红酒例子中,我们建立了25棵树,对任何一个样本而言,平均或多数表决 原则下,当且仅当有13棵以上的树判断错误的时候,随机森林才会判断错误。单独一棵决策树对红酒数据集的分类 准确率在0.85上下浮动,假设一棵树判断错误的可能性为0.2(ε),那20棵树以上都判断错误的可能性是:
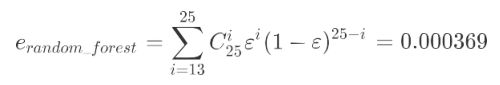
其中,i是判断错误的次数,也是判错的树的数量,ε是一棵树判断错误的概率,(1-ε)是判断正确的概率,共判对
25-i次。采用组合,是因为25棵树中,有任意i棵都判断错误。
3 RandomForestRegressor
3.1 重要参数,属性与接口
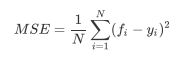
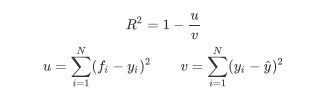
重要属性和接口
import sklearn
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
boston = load_boston()
regressor = RandomForestRegressor(n_estimators=100,random_state=0)
cross_val_score(regressor, boston.data, boston.target,cv=10,scoring = "neg_mean_squared_error")
sorted(sklearn.metrics.SCORERS.keys())返回十次交叉验证的结果,注意在这里,如果不填写scoring = "neg_mean_squared_error",交叉验证默认的模型,衡量指标是R平方,因此交叉验证的结果可能有正也可能有负。而如果写上scoring,则衡量标准是负MSE,交叉验 证的结果只可能为负。
3.2 实例:用随机森林回归填补缺失值
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston #一个标签是连续变量的数据集
from sklearn.impute import SimpleImputer #填补缺失值的类
from sklearn.ensemble import RandomForestRegressor #导入随机森林回归系
from sklearn.model_selection import cross_val_score #导入交叉验证模块dataset=load_boston()
dataset.data.shape #(506, 13)
x_full,y_full=dataset.data,dataset.target
n_samples=x_full.shape[0] #506
n_features=x_full.shape[1] #13
3.为完整数据集放入缺失值
rng=np.random.RandomState(0)
missing_rate=0.5
n_missing_samples=int(np.floor(n_samples*n_features*missing_rate))
#np.floor向下取整,返回.0格式的浮点数missing_features=rng.randint(0,n_features,n_missing_samples)
missing_samples=rng.randint(0,n_samples,n_missing_samples)missing_features=rng.randint(0,n_features,n_missing_samples)
missing_samples=rng.randint(0,n_samples,n_missing_samples)
x_missing=x_full.copy()
y_missing=y_full.copy()
x_missing[missing_samples,missing_features]=np.nan
x_missing=pd.DataFrame(x_missing)#使用均值填充
from sklearn.impute import SimpleImputer
imp_mean=SimpleImputer(missing_values=np.nan,strategy='mean')
x_missing_mean=imp_mean.fit_transform(x_missing)
#使用0填充
imp_0=SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0)
x_missing_0=imp_0.fit_transform(x_missing)5.使用随机森林填充缺失值
x_missing_reg=x_missing.copy()
#找出数据集中,缺失值从小到大排列的特征们的顺序,并且有了这些的索引
sortindex=np.argsort(x_missing_reg.isnull().sum(axis=0)).values
#np.argsort()返回的是从小到大排序的顺序所对应的索引
sortindex返回缺失值多少的从小到大的数组
array([ 6, 12, 8, 7, 9, 0, 2, 1, 5, 4, 3, 10, 11], dtype=int64)x_missing_reg.isnull().sum(axis=0)0 200
1 201
2 200
3 203
4 202
5 201
6 185
7 197
8 196
9 197
10 204
11 214
12 189
dtype: int64for i in sortindex:
#构建我们的新特征矩阵和标签
df=x_missing_reg
fillc=df.iloc[:,i]
df=pd.concat([df.iloc[:,df.columns!=i],pd.DataFrame(y_full)],axis=1)
#在新的特征矩阵中,对含有缺失值的列,进行0的填充
df_0=SimpleImputer(missing_values=np.nan,
strategy='constant',fill_value=0).fit_transform(df)
#找出我们的训练集和测试集
ytrain=fillc[fillc.notnull()]
ytest=fillc[fillc.isnull()]
xtrain=df_0[ytrain.index,:]
xtest=df_0[ytest.index,:]
#用随机森林回归填补缺失值
rfc=RandomForestRegressor(n_estimators=100)
rfc=rfc.fit(xtrain,ytrain)
ypredict=rfc.predict(xtest)
#将填补好的特征返回到我们的原始的特征矩阵中
x_missing_reg.loc[x_missing_reg.iloc[:,i].isnull(),i] =ypredict6.对填补好的数据进行建模
X=[x_full,x_missing_mean,x_missing_0,x_missing_reg]
mse=[]
std=[]
for x in X:
estimator=RandomForestRegressor(random_state=0,n_estimators=100)
scores=cross_val_score(estimator,x,y_full,scoring='neg_mean_squared_error',cv=5).mean()
mse.append(scores*-1)[*zip(["x_full","x_missing_mean","x_missing_0","x_missing_reg"],mse)][('x_full', 21.62860460743544),
('x_missing_mean', 40.84405476955929),
('x_missing_0', 49.50657028893417),
('x_missing_reg', 18.15993828660453)]可以看出,用随机森林填补确实值的mse最小
7.用所得到的结果画出条形图
x_labels=['Full data',
'Zero Imputation',
'Mean Imputation',
'Regressor Imputation']
colors=['r','g','b','orange']
plt.figure(figsize=(12,6))
ax=plt.subplot(111)
for i in np.arange(len(mse)):
ax.barh(i,mse[i],color=colors[i],alpha=0.6,align='center')
ax.set_title('Imputation Techniques with Boston Data')
ax.set_xlim(left=np.min(mse) * 0.9,
right=np.max(mse) * 1.1)#设置x轴取值范围
ax.set_yticks(np.arange(len(mse)))
ax.set_xlabel('MSE')
ax.set_yticklabels(x_labels)
plt.show()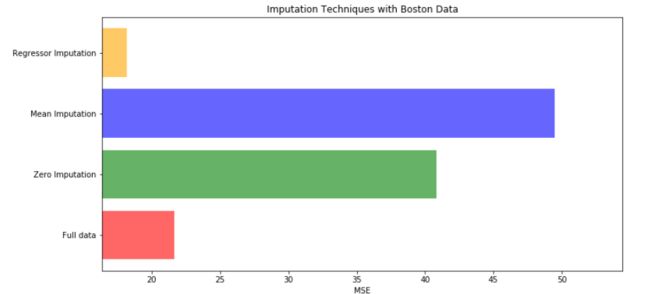
4 机器学习中调参的基本思想
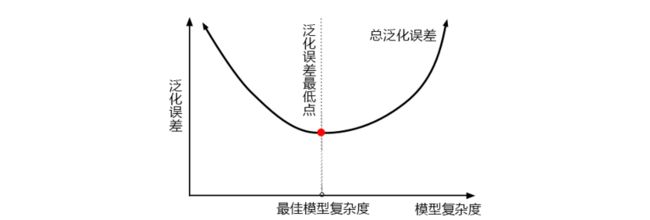
| 参数 |
对模型在未知数据上的评估性能的影响 |
影响程度 |
| n_estimators |
提升至平稳,n_estimators↑,不影响单个模型的复杂度 |
⭐⭐⭐⭐ |
| max_depth |
有增有减,默认最大深度,即最高复杂度,向复杂度降低的方向调参 max_depth↓,模型更简单,且向图像的左边移动 |
⭐⭐⭐ |
| min_samples _leaf |
有增有减,默认最小限制1,即最高复杂度,向复杂度降低的方向调参 min_samples_leaf↑,模型更简单,且向图像的左边移动 |
⭐⭐ |
| min_samples _split |
有增有减,默认最小限制2,即最高复杂度,向复杂度降低的方向调参 min_samples_split↑,模型更简单,且向图像的左边移动 |
⭐⭐ |
| max_features |
有增有减,默认auto,是特征总数的开平方,位于中间复杂度,既可以 向复杂度升高的方向,也可以向复杂度降低的方向调参max_features↓, 模 型 更 简 单 , 图 像 左 移 max_features↑,模型更复杂,图像右移 max_features是唯一的,既能够让模型更简单,也能够让模型更复杂的参数,所以在调整这个参数的时候,需要考虑我们调参的方向 |
⭐ |
| criterion |
有增有减,一般使用gini |
看具体情况 |
5实例:随机森林在乳腺癌数据上的调参
基于方差和偏差的调参方法,在乳腺癌数据上进行一次随 机森林的调参。乳腺癌数据是sklearn自带的分类数据之一
那我们接下来,就用乳腺癌数据,来看看我们的调参代码。
1.导入需要的库
from sklearn.datasets import load_breast_cancer #导入乳腺癌数据
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np2.导入数据集,探索数据
data=load_breast_cancer()
data
data.data.shape #(569, 30)
data.target #返回一个2分类集可以看到,乳腺癌数据集有569条记录,30个特征,单看维度虽然不算太高,但是样本量非常少。过拟合的情况可能存在。
3.进行一次简单的建模,看看模型本身在数据集上的效果
rfc = RandomForestClassifier(n_estimators=100,random_state=90) #实例化
score_pre = cross_val_score(rfc,data.data,data.target,cv=10).mean() #交叉验证
score_pre输出结果:0.9648809523809524
4.随机森林调整的第一步:无论如何先来调n_estimators
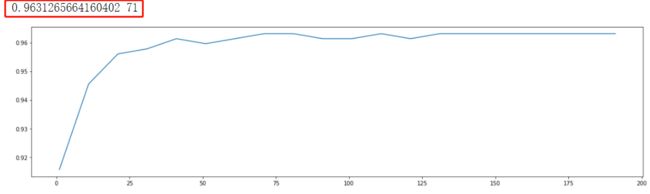
选择学习曲线来查看n_estimators的趋势
scorel = []
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1
,n_jobs=-1
,random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
#list.index([object])
#返回这个object在列表list中的索引
5.在确定好的范围内,进一步细化学习曲线
scorel = []
for i in range(65,75):
rfc = RandomForestClassifier(n_estimators=i
,n_jobs=-1
, random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
scorel.append(score)
print(max(scorel),([*range(65,75)][scorel.index(max(scorel))]))
plt.figure(figsize=[20,5])
plt.plot(range(65,75),scorel)
plt.show()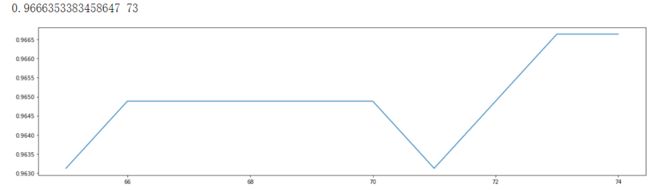
调整n_estimators的效果显著,模型的准确率立刻上升了0.003。接下来就进入网格搜索,我们将使用网格搜索对参数一个个进行调整。为什么我们不同时调整多个参数呢?原因有两个:
1)同时调整多个参数会运行非常缓慢, 在课堂上我们没有这么多的时间。
2)同时调整多个参数,会让我们无法理解参数的组合是怎么得来的,所以即便 网格搜索调出来的结果不好,我们也不知道从哪里去改。在这里,为了使用复杂度-泛化误差方法(方差-偏差方法),我们对参数进行一个个地调整。
6.为网格搜索做准备,书写网格搜索的参数
有一些参数是没有参照的,很难说清一个范围,这种情况下我们使用学习曲线,看趋势 从曲线跑出的结果中选取一个更小的区间,再跑曲线
param_grid = {'n_estimators':np.arange(0, 200, 10)}
param_grid = {'max_depth':np.arange(1, 20, 1)}
param_grid = {'max_leaf_nodes':np.arange(25,50,1)}
对于大型数据集,可以尝试从1000来构建,先输入1000,每100个叶子一个区间,再逐渐缩小范围有一些参数是可以找到一个范围的,或者说我们知道他们的取值和随着他们的取值,模型的整体准确率会如何变化,这样的参数我们就可以直接跑网格搜索
param_grid = {'criterion':['gini', 'entropy']}
param_grid = {'min_samples_split':np.arange(2, 2+20, 1)}
param_grid = {'min_samples_leaf':np.arange(1, 1+10, 1)}
param_grid = {'max_features':np.arange(5,30,1)}
7.开始按照参数对模型整体准确率的影响程度进行调参,首先调整max_depth.
#调整max_depth
param_grid = {'max_depth':np.arange(1, 20, 1)}
#一般根据数据的大小来进行一个试探,乳腺癌数据很小,所以可以采用1~10,或者1~20这样的试探
#但对于像digit recognition那样的大型数据来说,我们应该尝试30~50层深度(或许还不足够)
#更应该画出学习曲线,来观察深度对模型的影响
rfc = RandomForestClassifier(n_estimators=73 #前面的学习曲线确定的
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_输出没变化:0.9666353383458647
8.调整max_features
#调整max_features
param_grid = {'max_features':np.arange(5,30,1)}
"""
max_features是唯一一个即能够将模型往左(低方差高偏差)推,
也能够将模型往右(高方差低偏差)推的参数。
我们需要根据调参前,模型所在的位置(在泛化误差最低点的左边还是右边)
来决定我们要将max_features往哪边调。
现在模型位于图像左侧,我们需要的是更高的复杂度,
越多,模型才会越复杂。max_features的默认最小值是sqrt(n_features),
因此我们使用这个值作为调参范围的最小值。
"""
rfc = RandomForestClassifier(n_estimators=73
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
输出值:0.9666666666666668 提高了
GS.best_params_ 输出结果为:{'max_features': 24}
9.调整min_samples_leaf
# 调 整 min_samples_leaf
param_grid={'min_samples_leaf':np.arange(1, 1+10, 1)}
#对于min_samples_split和min_samples_leaf,一般是从他们的最小值开始向上增加10或20
#面对高维度高样本量数据,如果不放心,也可以直接+50,对于大型数据,可能需要200~300的范围
#如果调整的时候发现准确率无论如何都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rfc = RandomForestClassifier(n_estimators=73
,random_state=90
,max_features=24
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_输出值:0.9666666666666668保持不变了
10.不懈努力,继续尝试min_samples_split
# 调 整 min_samples_split
param_grid={'min_samples_split':np.arange(2,2+20,1)}
rfc = RandomForestClassifier(n_estimators=73
,random_state=90
,max_features=24
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_输出值:9701754385964912 提高了
GS.best_params_ 输出结果{'min_samples_split': 6}
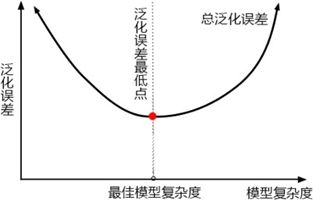
限制min_samples_split ,是让模型变得简单,把模型向左推,而模型整体的准确率下降了,即整体的泛化误差上升了,这说明模型现在位于图像左边,即泛化误差最低点的左边(偏差为主导的一边)。通常来说,随机森林应该在泛化误差最低点的右边,树模型应该倾向于过拟合,而不是拟合不足。
11.最后尝试一下criterion
#调整Criterion
param_grid = {'criterion':['gini', 'entropy']}
rfc = RandomForestClassifier(n_estimators=73
,random_state=90
,max_features=24
,min_samples_split=6
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_输出值:0.9701754385964912 没有变化
12. 调整完毕,总结出模型的最佳参数
rfc = RandomForestClassifier(n_estimators=73
,random_state=90
,max_features=24
,min_samples_split=6
)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score
score - score_pre #得出差值整体提高了0.005294486215538852
在整个调参过程之中:
1.学习曲线调整n_estimators,先10个一组,再细分,确定n_estimators=73最优
2.调整max_depth,得分没有变化,我们可以选择不调整此参数
3.调整max_features,得分提高了,max_features取值24
4.调整min_samples_leaf,得分没有变化,我们可以选择不调整此参数
5.调整min_samples_split,得分提高了,min_samples_split取值6
6.最后尝试一下criterion,得分没有变化,我们可以选择不调整此参数